
0403 실습: 회귀
결측치를 다른 피처의 중간값이나 중앙값으로 채워줄 수도 있지만 결측치를 예측하는 방법도 있다.
-
cross validation;
cross_val_predict(): 오차 구하기 -
MAE(Mean Absolute Error): 평균 절대 오차
mae = abs(y_train - y_predict).mean()- MAPE(Mean Absolute Percentage Error): 실제값 대비 오차값의 평균;
(실제값 - 예측값 / 실제값)의 절대값에 대한 평균
mape = (abs(y_train - y_predict) / y_train).mean()- MSE(Mean Squared Error): 분산과 유사한 공식. 실제값 - 예측값의 차이의 제곱의 평균. (이차함수를 사용하기 때문에) 오차가 크면 클수록 패널티를 더 많이 부여.
mse = ((y_train - y_predict) ** 2).mean()MSE != 분산
- RMSE(Root Mean Squared Error): 표준편차와 유사한 공식.오차가 점점 커져 스케일 차이가 난다면 루트를 씌우는 것도 방법. 가장 많이 사용하는 측정 방식
rmse = np.sqrt(mse)👀
지금 배우는 MSE와 MAE 같은 지표는 "내가 만든 모델이 잘 예측했나?"라는 질문에서 시작합니다. 그럼 잘 예측했다라고 표현하고 싶은데 어떻게 표현할 수 있을까요?!
1. 분류
분류의 경우에는 잘 정답값과 비교해서 많이 맞으면 잘 예측했다라고 말할 수 있겠죠. 이게 accuracy입니다.
2. 회귀
회귀는 잘 예측했다! 라고 말하기에는 정답값에 딱 맞출 수가 없습니다. 그래서 오차가 적을수록 모델이 잘 예측했다! 라는 가정을 하고 그 오차를 MAE, MSE, RMSE와 같은 지표들이 나온겁니다.
분산은 주어진 데이터의 분포를 확인하기 위한 수치이고, MSE나 MAE는 내가 예측한 지표와 정답값의 오차를 파악하기 위한 지표입니다.
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
실제값:

예측값:

👉🏻 예측한 모델의 평균값이 더 높다 => 잘 예측한 모델이라고 볼 수 없다.
0403 실습 Summary
인슐린 값 예측하는 것이 목적. RandomForestRegressor() 사용.
n_estimator : 트리를 여러개 만들기 때문에 과적합을 방지할 수 있다.
해당 실습에는 정답이 없다. 👉🏻 기존에 있는 정보를 가지고 cross validation (교차 검증) 진행 (조각을 여러개로 나눈다 => 모든 조각이 학습에 예측이 되도록 사용하는 것, 조각은 많이 나눌 수록 신뢰도가 높아짐).
분류를 측정했을 때처럼 accuracy를 사용하면 맞는게 하나도 없어 오차값을 사용하여 알아보았다.
r2 score 회귀선의 기울기를 구하며, 1에 가까울 수록 잘 예측한 측정 공식.
0404 실습:
- 데이터를 무작위로 나누는 실습
- 하이퍼 파라미터 튜닝
- 어떤 estimator가 가장 좋은 모델인지 찾기
from sklearn.model_selection import train_test_split
# shuffle: 데이터를 골고루 섞는 기능
# 예시
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify = y, random_state=42)비교할 두 그래프를 한 번에 출력하기:
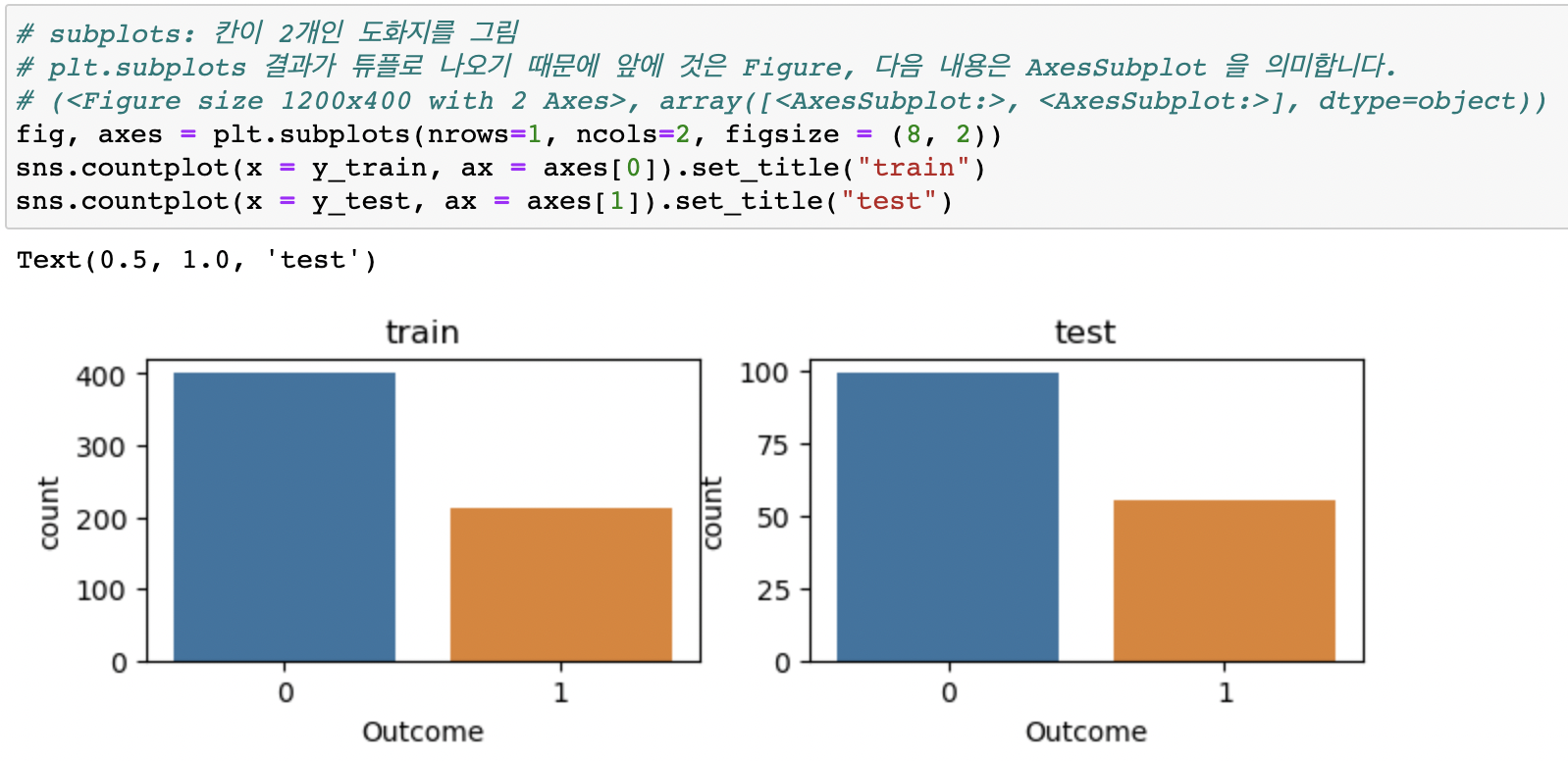
하이퍼파라미터 튜닝
- 하이퍼파라미터 (Hyper Parameter)
- 머신러닝 모델을 생성할 때 사용자가 직접 설정하는 값으로, 이를 어떻게 설정하느냐에 따라 모델의 성능이 달라집니다.
- 수동튜닝
- 만족할만한 하이퍼파라미터들의 조합을 찾을 때까지 수동으로 조정
- GridSearchCV()
- 시도할 하이퍼파라미터들을 지정하면, 모든 조합에 대해 교차검증 후 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾음
- 단점: 후보군의 개수가 많으면 시간이 오래 걸리며 후보군들을 정확하게 설정하는 것이 필요 => 격자 외의 값은 포함하지 않음.
- GridSearchCV: 조합의 수 만큼 실행
- RandomizedSearchCV()
- GridSearch 와 동일한 방식으로 사용하지만 모든 조합을 다 시도하지는 않고, 각 반복마다 임의의 값만 대입해 지정한 횟수(n_iter)만큼 평가
- RandomizedSearchCV: k-fold 수 * n_iter 수 만큼 실행
GridSearchCV()
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state = 42)
max_depth = list(range(3, 20, 2))
max_features = [0.3, 0.5, 0.7, 0.8, 0.9]
parameters = {"max_depth" : max_depth, "max_features" : max_features}
from sklearn.model_selection import GridSearchCV
# 분류 모델 (accuracy) 과 회귀 모델의 scoring 방법이 다르다.
# verbose: 자세한 로그를 출력하는 기능
clf = GridSearchCV(model, parameters, n_jobs = -1, cv = 5, scoring = "accuracy", verbose = 3)
clf.fit(X_train, y_train)
# 어떤 조합이 가장 좋은 성능을 내는지 확인 해 볼 수 있다.
clf.best_estimator_RandomSearchCV()
RandomSearchCV()는GridSearchCV()와 거의 유사하다.
# random.randint: start, stop 값에 대한 랜덤 int 값 추출
np.random.randint(3, 20, 10)
# max_features 에는 0에서 1사이 값을 넣어줄 수 있도록 랜덤하게 생성
np.random.uniform(0.5, 1, 10)
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {"max_depth" : np.random.randint(3, 20, 10),
"max_features" : np.random.uniform(0.5, 1, 10)}
clfr = RandomizedSearchCV(model,
param_distributions = param_distributions,
n_iter = 10,
cv = 5,
scoring = "accuracy",
n_jobs = -1,
verbose = 3,
random_state = 42)
clfr.fit(X_train, y_train)🙋🏻♀️ 질문
Q: error.describe() 에서 MAE 값을 찾는다면?
A: mean값
Q: 왜 오차에 절대값을 적용해 줄까요?
A: 오차의 산포도를 양수, 음수 동일하게 비교하기 위해
Q: MAPE의 값은 작을수록 잘 예측한걸까?
A: 그렇다. 오차값이기 때문에 값이 작을수록 잘 예측한 것이다.
Q: 사용했던 측정 공식 중에 1에 가까울 수록 좋은 모델이고 0에 가까울 수록 잘못 예측한 측정공식은 무엇일까요?
A: r2 score. 이 모델을 제외한 나머지는 0에 가까울수록 잘 예측한 측정공식.
Q: MSE; 오차값에 square 를 해주는 이유?
A: 절댓값을 씌우는 것과 마찬가지로, 부호를 무시할 수 있다.
Q: 분산은 어떨때 사용할까?
A: 관측값에서 평균을 뺀 값을 제곱하고 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 관측값에서 평균을 뺀 값인 편차를 모두 더하면 0이 나오므로 제곱해서 더한다. 분산 = 차이값의 제곱의 평균
Q: mse는 분산과 유사한 공식이다. rmse 는 어떤 공식과 유사할까요?
A: 표준편차 (분산의 제곱근)
Q: 분산과 MSE의 차이?
A: 분산은 관측값에서 평균을 뺀 값을 제곱, MSE는 실제값에서 예측값을 뺀 값을 제곱
분산은 주어진 데이터 내에서 구하는거라면, MSE는 주어진 데이터 + 예측한 데이터로 구합니다. 분산이 주어진 데이터 내에서 평균과의 오차를 기반으로 데이터의 분포 정도를 구한다면, MSE가 예측한 데이터와 주어진 데이터간의 오차를 기반으로 구합니다
Q: 1 억짜리 집을 2억으로 예측=>1, 100억짜리 집을 110억으로 예측 =>2 어떤 모델이 더 잘 예측한 모델일까?
MAE: 1억을 2억으로 예측 => 1 억 차이, 100억을 110억으로 예측하면 => 10억 차이
MSE: 오차 1억의 제곱, 오차 10억의 제곱
이 상황에서는 어떤 측정 지표를 사용하는게 좀 더 잘 측정할까요?
A: 1번은 2배 잘못 예측, 2번은 10% 잘못 예측. 두 예측 비율을 %로 동일시 보면 1번은 100% 잘못 예측이고 2번은 10%이기 때문
Q: MAE 로 측정하면 어떤 모델이 더 잘 예측한 모델일까요?
A: 1번 모델
Q: 회귀에서 Accuracy를 사용하지 않는 이유?
A: Accuracy는 데이터의 일치여부를 판단하는 것인데, 타깃값 하나하나를 소수점 단위까지 동일하게 예측하기는 어렵기 때문. 연속적인 값을 예측하는 것이기 때문에 값을 구한다고 해도 무의미 할 수 있다.
Q: 배달업체다. 5분 걸린다고 예측했는데 10분 걸림 => 1, 25분 걸린다고 예측했는데 50분 걸림 => 2. MAE로 평가했을 때 잘 예측한 모델 / MSE로 평가했을 때 잘 예측한 모델 / MAPE로 평가했을 때 잘 예측한 모델
A: MAE로 평가했을 때 잘 예측한 모델 => 1번 (1일때는 5분, 2일때는 25분)
Q: 왜 MAE를 사용했을 때 제대로 오차를 구하기 어려울까?
A: 기울기의 차이가 없다. 기울기가 0이 되는 지점이 가장 오차가 작은 지점. 기울기를 사용할 수 있기 때문에 보통 MSE를 사용한다.
Q: train_test_split는 언제 사용하나?
A: train set과 test set를 분리할 때, class 비율을 동일하게 하는 것 같습니다.
Q: class 비율이 동일하게 나뉘었는지 어떻게 확인해 볼까요?
A: countplot으로 시각화
Q: 부호의 제거를 절댓값과 제곱으로 다르게 하는 이유가 있을까요?
A: 제곱은 오차가 큰 값을 부각시키기 위해
Q: 데이터의 크기와 오차가 클수록 MAE로는 판단에 오류가 있을 수 있다는건가요?
A: 값에 오류는 없지만, 잘못된 예측으로 현실세계에 적용하기 어려울 수 있다.
Q: MSE가 절댓값에 비해 오차가 큰 값에 대해 패널티를 더 많이 줄 수는 있지만 예측비율 (부동산 가격 예시처럼 2배의 오차인지 10%의 오차인지)에 대해서는 파악할 수 없는 건가요?
A: 오차값에 제곱을 하기 때문에 몇퍼센트의 오차인지를 파악할 때는 MAPE를 사용하는 것을 추천. MAPE를 사용하면 오차의 비율을 구해볼 수 있다.
Q: 100억을 110억으로 예측한 모델 =>1, 100억을 105억으로 예측한 모델 =>2
두 모델이 있을때 어떤 모델이 더 잘 예측한 모델인가요?
A: MAE와 MSE 모두 2번이 더 잘 예측했다고 볼 수 있다.
데일리 퀴즈 오답노트
Q: 최적의 매개변수 값을 찾기 위해 하이퍼파라미터 값을 바꾸는 동시에 교차검증까지 진행하는 방법은 무엇일까요?
A: Grid Search
✏️ TIL
- 사실(Fact): MAE, MAPE, MSE와 RMSE의 개념에 대해 배웠고, 데이터를 무작위로 나누고 하이퍼 파라미터를 튜닝하는 방법(GridSearchCV, RandomSearchCV)에 대해서 배웠다.
- 느낌(Feeling): 오늘은 새로운 개념을 많이 배워 바로 이해하는게 쉽지 않았다.
- 교훈(Finding): 오늘 배운 부분은 오늘 모두 이해하고 넘어가자.
