
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
0501 실습:
# 컬럼이 너무 많을 때 train에는 있고 test에는 없는 컬럼 찾는 방법
set(train.columns) - set(test.columns)
- 정규화: 숫자 스케일의 차이가 클 때 값을 정규분포로 만들어 주거나 스케일 값을 변경해 주는것
- 이상치: 이상치를 제거하거나 대체
- 대체: 결측치를 다른 값으로 대체
- 인코딩: 호칭, 탑승지의 위치, 문자 데이터를 수치화, 너무 범위가 큰 수치 데이터를 구간화 해서 인코딩
Kaggle에 실습 파일 제출:
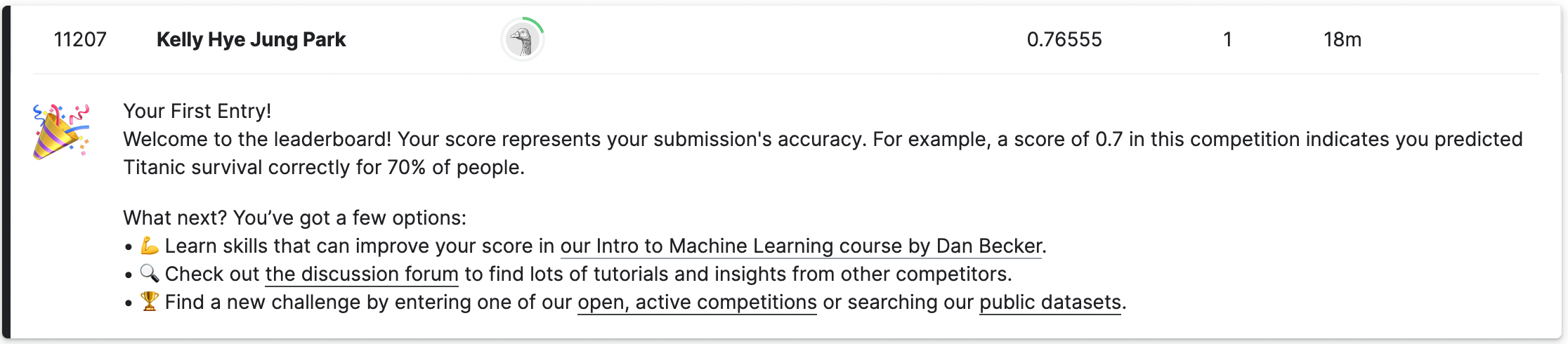
👉🏻 0.76은 100개의 전체 샘플중에 예측한 라벨 100개중 76개가 맞았다는 의미

0502 실습:
- 해당 실습파일은 y_test 값이 제공되지 않는다.
# 수치형 데이터에 대한 컬럼만 가져오기 위해
# 수치 데이터만 가져온 이유? => 머신러닝 내부에서 연산을 할 수 없기 때문
train.select_dtypes(include="number").columns
# Binary encording => 성별은 중요한 역할을 하는데 문자로 되어있으면
# 머신러닝 내부에서 연산을 할 수 없기 때문
# 수치 데이터로 변환하는 인코딩 작업을 수행 (train과 test 모두 변환해 주어야 함)
train["Gender"] = train["Sex"] == "female"
test["Gender"] = test["Sex"] == "female"
# 각각의 데이터가 제대로 인코딩이 되었는지 확인해 보기 위해
# 머신러닝 알고리즘에서 bool 값은 수치형 데이터로 취급 하기 때문에
# int 타입으로 변경하지 않아도 됨
display(train["Gender"].head(2))
display(test["Gender" ].head(2))
# feature_names 라는 변수에 학습과 예측에 사용할 컬럼명을 가져옵니다.
feature_names = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Gender']
feature_names- 결측치 대체
결측치는 의미있는 값으로 채우면 더 좋지만, 일단 모델을 실행했을 때 오류가 나지않도록 0으로 채우는 것도 하나의 방법.👀 test에 있는 데이터의 행은 삭제하면 안되는 이유:
삭제를 하면 예측해야 하는 문제인데 예측을 못 하기 때문
Kaggle에 실습 파일 제출:
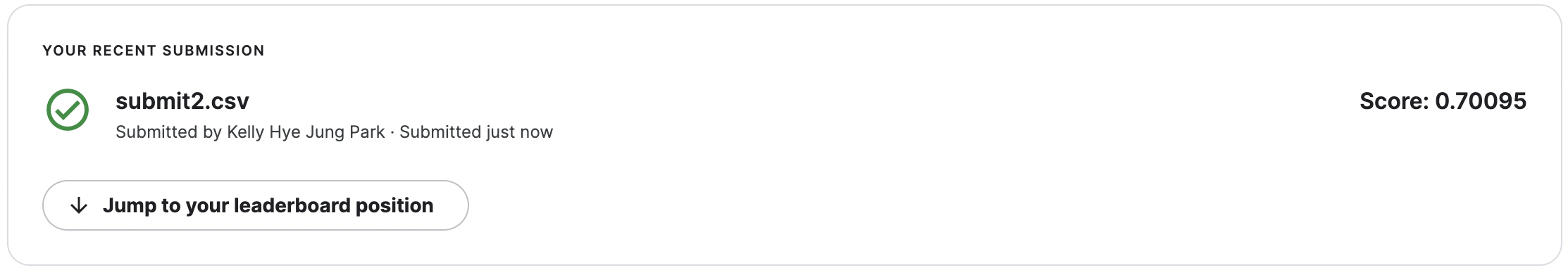
👉🏻 모델을 학습하고 예측한 결과를 추가해서 다시 제출하니 오히려 성능이 더 떨어졌다.
피처엔지니어링도 많이 할수록 꼭 점수가 오른다는 보장은 없습니다. 오히려 피처엔지니어링을 많이 했을 때 점수가 더 낮아질 수 있습니다. 피처엔지니어링을 제대로 도메인지식, EDA를 통해서 생존여부에 중요한 역할을 하는 변수를 찾아서 전처리 해주면 성능이 더 나아질 수 있습니다.
지니 불순도
- 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며 CART 알고리즘에서 사용한다. 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률을 말한다. 집합에 있는 항목이 모두 같다면 지니 불순도는 최솟값(0)을 갖게 되며 이 집합은 완전히 순수하다고 할 수 있다.
로그(log)

로그(log)는 지수 함수의 역함수이다. 어떤 수를 나타내기 위해 고정된 밑을 몇 번 곱하여야 하는지를 나타낸다고 볼 수 있다.
엔트로피 - 정보획득량
- 기술적인 관점에서 보면 정보는 발생 가능한 사건이나 메시지의 확률분포의 음의 로그로 정의할 수 있다. 각 사건의 정보량은 그 기댓값, 또는 평균이 섀넌 엔트로피인 확률변수를 형성한다. 일반적으로 정보 엔트로피는 모든 발생가능한 결과의 평균적인 정보가 된다.
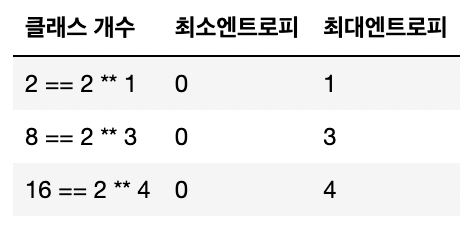
👉🏻 최대 엔트로피는 이진로그로 구할 수 있다.
# 예를 들면, 고객센터 문의가 7개라면 최대 엔트로피값은 np.log2를 적용한 값입니다.
np.log2(7)
# Outcome == 최대 엔트로피
2.807354922057604 지니 불순도는 0.5일 때 가장 값이 많이 섞여있는 상태이며, 엔트로피는 np.log2(클래스 갯수) 값과 같을 때가 가장 많이 섞여있는 상태로 보면 됩니다. 0에 가까운지를 보면 되고, 트리를 보게 되면 트리 아래로 갈 수록 0에 가까워집니다. 지니 불순도나 엔트로피가 0이 되면 트리 분할을 멈춥니다.
트리계열 알고리즘 parameters
- criterion: 가지의 분할의 품질을 측정하는 기능입니다.
- max_depth: 트리의 최대 깊이입니다.
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수입니다.
- min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수입니다.
- max_leaf_nodes: 리프 노드 숫자의 제한치입니다.
- random_state: 추정기의 무작위성을 제어합니다. 실행했을 때 같은 결과가 나오도록 합니다.
Q: train.csv 와 test.csv 파일의 차이점은 무엇일까요?
A: Survived 컬럼이 없고, test.csv는 PassengerId가 892부터 시작한다. test에 비해 train의 행의 개수가 2배 이상 많음.
Q: 왜 Survived 컬럼은 train 에만 있을까요?
A: 예측해야하는 값이기 때문
Q: 왜 당뇨병 데이터셋에 비해 타이타닉 데이터셋이 더 난이도가 있는 데이터 일까요?
A: 여러 데이터 타입이 섞여있고 결측치가 많아 전처리할 데이터가 많다. 당뇨병 데이터에 비해 크기도 조금 더 크다.
Q: Kaggle은 하루에 10번만 제출할 수 있는데 그 이유는?
A: 서버무리, 점수조작, 찍어 맞출 수도 있겠죠. 어뷰징 때문에 API등 도 제공하고 있기 때문에 너무 많이 제출하면 어뷰징(잘못된 사용). 캐글에는 상금걸거나 채용을 걸거나 상을 걸고 하는 대회에 어뷰징이 있을 수 있기 때문입니다. 그래서 하루 제출 횟수를 제한합니다. 한국 데이콘도 마찬가지 입니다.
Q: 로그 그래프에서 이진로그, 자연로그, 상용로그의 공통점?
A: x가 1일 때 y는 0이다. x는 0보다 큰 값만 있다. x가 1보다 작을 때는 마이너스 무한대로 수렴합니다.
Q: 지니불순도와 엔트로피를 사용하는 목적?
A: 분류를 했을 때 True, False 로 완전히 나뉘지 않는데 이 때 값이 얼마나 섞여있는지 수치로 확인하기 위해서이고, 0에 가까울 수록 다른 값이 섞여있지 않은 상태입니다. 분류의 분할에 대한 품질을 평가하고 싶을 때 사용합니다.
Q: 수치데이터로 인식하면 바이너리 인코딩이랑 원핫이랑 똑같다고 봐도 될까요?
A: Binary encoding은 One-hot-encoding 과 같다.
Q: feature_name에 age컬럼을 빼줘도 되나요?
A: 어떤 피쳐를 선택할 것인가에 따라서 상관이 없습니다! 피쳐를 선택하는데 있어서 정답은 없습니다. 피처가 1개여도 상관은 없고 어떤 피처를 넣어줄지는 EDA, 도메인지식 등을 활용합니다.
Q: y_train은 왜 결측치를 안채워도 되는지 잘 모르겠습니다.
A: 정답값이기 때문에 결측치가 없습니다.
Q: y_test가 없으면 accuracy score는 어떻게 구하나요?
A: hold-out-validation 이라든지 cross_validation을 사용해서 구할 수 있습니다.
hold-out-validation: valid 가 한 조각
cross_validation: valid 가 여러 조각
Q: 배운 내용 복습중에 r2_score를 언제 쓰는지 왜 쓰는지 궁금해졌습니다.
A: R2 Score는 회귀 모델이 얼마나 '설명력' 이 있느냐를 의미합니다. '실제 값의 분산 대비 예측값의 분산 비율' 로 요약 될 수 있으며, 예측 모델과 실제 모델이 얼마나 강한 상관관계(Correlated)를 가지는가로 설명력을 요약할 수도 있습니다. 회귀 모델을 평가할 때 사용하는 평가지표입니다.
특징으로는 다른 평가지표인 MAE MSE RMSE 모두 에러에 대한 값이기 때문에 작을수록 좋은 값이지만 R2 Score(결정계수)는 1에 가까울 수록 좋습니다
Q: 클래스가 많아지면 로그의 밑도 달라지나요?
A: 로그의 밑은 동일하되 엔트로피 최대값이 달라집니다.
Q: 클래스가 많아진다는 게 어떤 예시가 있는지 알 수 있나요?
A: 분류해야하는 대상의 갯수에 따라서 클래스가 나뉜다고 생각하면 됩니다.
생존여부: 2진 분류
쇼핑카테고리 19개: 19개로 분류
클래스를 예측할 때 True, False로 예측하기도 하지만 멀티클래스 일 때는 특정 클래스의 확률을 예측하기도 합니다. 그래서 예시의 측정공식은 logloss 라는 공식을 사용합니다. 엔트로피와 비슷하지만 다릅니다.
멀티클래스 분류 예제
Q: 지니계수랑 엔트로피는 분류가 잘 되어있는지를 보여주는 지표의 종류이고, 어떤걸 선택하든 모델의 성능에는 영향이 없는걸로 이해되는데 맞을까요?
A: 두가지에 큰 차이가 없지만, 엔트로피가 조금 더 엄격하게 분류하는데 사용된다.
Q: 프로젝트 등을 할 때 지니불순도 등을 참고하게 되나요?
A: 캐글이나 데이콘 등에 제출하기 전에 시각화를 해보고 그 모델이 얼마나 잘 나뉘었는지 여러가지로 평가해 볼 수 있는데 이 때 함께 참고해 볼 수 있을거 같아요. 이 때 함께 참고해 볼 수 있는 것은 피처 중요도, 교차검증(cross validation) 값 등을 참고해 볼 수 있겠습니다.
Q: 트리 모델 모델링을 할때 max depth 설정을 하면 지니 계수나 엔트로피가 0이 아닐때 멈추나요?
A: 네 맞습니다. 지니불순도나 엔트로피가 0보다 크더라도, 지정한 max_depth 값이 되면 멈춥니다.
엔트로피나 지니불순도가 0이 될 때는 보통 샘플이 [1, 0] 이나 [2, 0] 처럼 샘플의 개수가 적을 때가 많은데 이렇게 너무 자세하게 학습하면 일반화 하기 어려운 부분도 있습니다.
✏️ TIL
- 사실(Fact): Kaggle competition 문제로 실습하고 제출해봤다.
- 느낌(Feeling): 실습을 통해 예측 모델을 만들고 제출하니 내 예측 적중률이 바로 나와서 신기했다.
- 교훈(Finding): 복습 열심히해서 여러 competition 문제들에 좋은 성능을 내는 모델을 만들어 상위랭크에 올라보고 싶다.
