
0701 실습:
- 희소값에 대해 원핫인코딩을 하게되면 오버피팅이 발생할 수도 있고
너무 희소한 행렬이 생성되기 때문에 계산에 많은 자원이 필요합니다.- 희소한 값을 사용하고자 한다면
1) 아예 희소값을 결측치 처리하면 원핫인코딩 하지 않습니다.
2) 희소한 값을 "기타" 등으로 묶어줄 수도 있습니다.
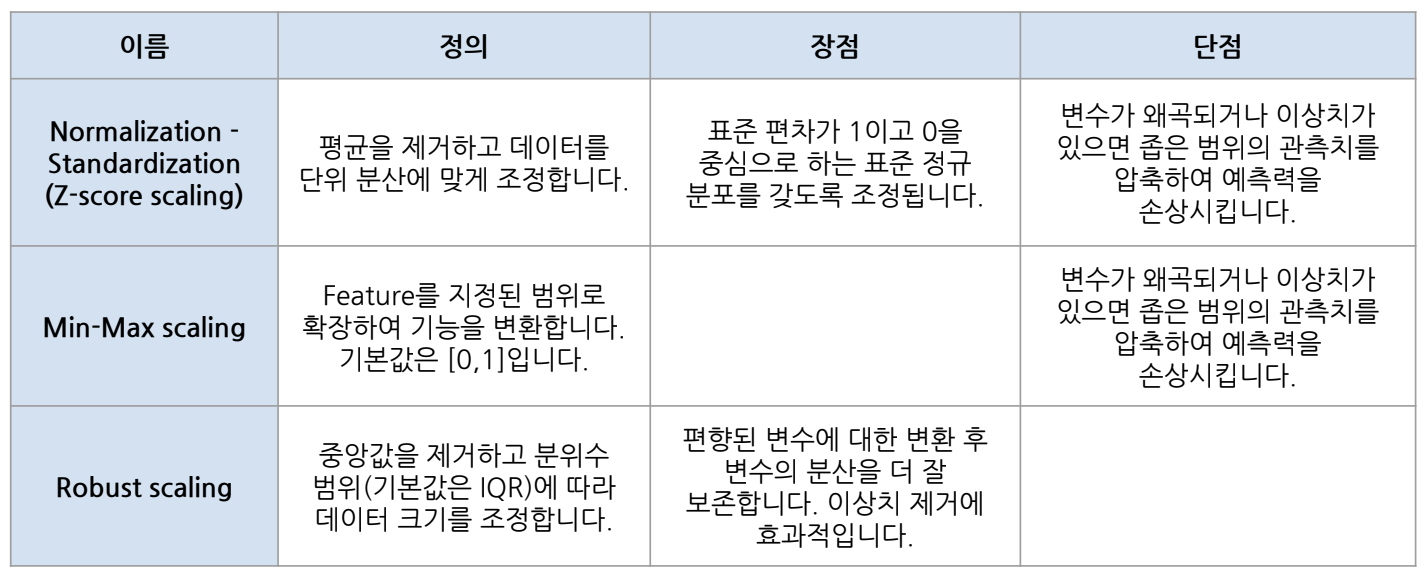
Feature Scaling
정보 균일도를 기반으로 되어 있기 때문에 트리기반 모델은 피처 스케일링이 필요 ❌
트리기반 모델은 데이터의 절대적인 크기보다 상대적인 크기에 영향을 받기 때문에 스케일링을 해도 상대적인 크기 관계는 같다(= 스케일링에 영향을 크게 받지 않는다).
💡 feature scaling: feature의 범위를 조정해서 정규화
feature의 분산과 표준편차를 조정해서 정규분포 형채를 띄게 하는 것이 목표.
💡 feature의 범위가 다르면, feature끼리 비교하기 어려워 일부 머신러닝 모델에서는 제대로 작동하지 않는다.
💡 feature scaling이 잘 되어 있으면:
1) 서로 다른 변수끼리 비교하는 것이 편리
2) feature scaling 없이 작동하는 알고리즘에서 더 빨리 작동
3) 머신러닝 성능이 상승
4) 이상치에 대한 강점이 있음.
일반적으로 쓰이는 스케일링의 3가지 기법:
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
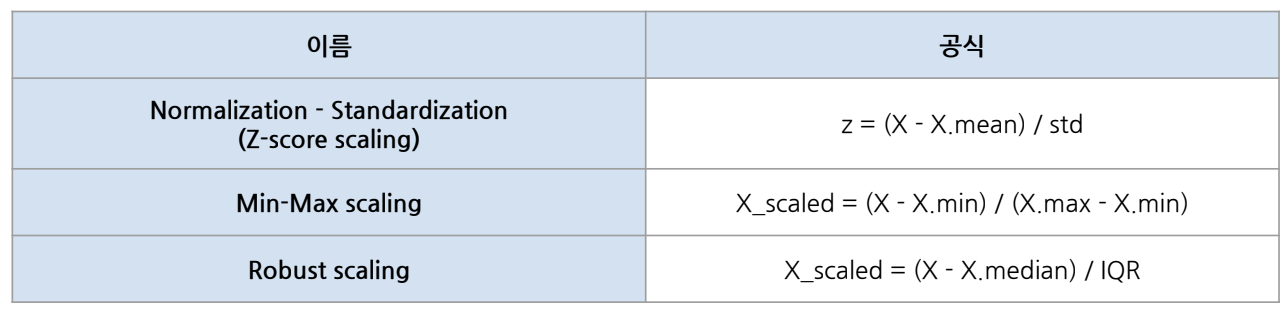
from sklearn.preprocessing import RobustScaler1) StandardScaler (Z-score scaling)
- 평균 0, 표준편차 1의 특징을 가지고 있음
- 평균을 이용하여 계산해주기 때문에 이상치에 영향을 받는다. (평균: 이상치의 값에 크게 영향을 받기 때문)
2) MinMaxScaler
- 변수 범위를 0과 1사이로 압축해주는 개념 (최솟값이 0, 최댓값이 1)
- 이상치를 포함하고 있으면 범위설정에 영향이 가기 때문에 이상치에 의해 영향을 많이 받는다.
3) RobustScaler
- 중앙값을 0으로 만들고 사분위 수(IQR)를 이용한 스케일링 기법
- StandardScaler와 다르게 중앙값(median)을 이용하기 때문에 StandardScaler, MinMaxScaler에 비해서 이상치의 영향을 덜 받는다.
fit() & transform()
- 사이킷런의 다른 기능에서는 fit => predict를 했었지만 전처리에서는 fit => transform을 사용한다.
- 스케일링을 예시로 fit은 계산하기 위한 평균, 중앙값, 표준편차가 필요하다면 해당 데이터를 기준으로 기술통계값을 구하고 그 값을 기준으로 transform에서 계산을 적용해서 값을 변환해준다.
- fit은 train에만 사용하고 transform은 train, test에 사용한다.
- 기준을 train으로 정하기 위해서 fit을 test에 사용하지 않는다.
- test에는 train을 기준으로 학습한 것을 바탕으로 transform만 한다.
fit과 transform을 하는 2가지 방법:
1) fit() & transform()
train[["SalePrice_ss"]] = ss.fit(train[["SalePrice"]]).transform(train[["SalePrice"]])
train[["SalePrice", "SalePrice_ss"]].head(2)
2) fit_transform(): 같은 컬럼을 fit하고 transform 할 때 사용하는 방법
# 주의: 피처에 fit_transform은 train에만 사용!!!
# test에도 fit을 하게 되면 trian, test의 기준이 달라지니 test에는 transform만 한다.
train[["SalePrice_ss"]] = ss.fit_transform(train[["SalePrice"]])정규분포와 트랜스포메이션
feature scaling은 편향된 분포나 이상치에 취약하기 때문에 transformation을 적용한 후 feature scaling을 하게 되면 표준정규분포가 된다.
🤔 왜 정규분포로 고르게 분포된 값이 예측에 유리할까?
중간값을 잘 예측하는 모델이 일반적으로 예측 성능이 높은 모델이기 때문에 1,4분위 보다 2,3분위가 상대적으로 더 중요하다.
🤔 만약 label이 편향되어 있다면?
label을 transform해서 예측하고 반대로 계산해서 출력하면 된다.
e.g.) log transformation된 상태로 학습하고 예측한 다음, 예측한 값에 np.exp() 적용하여 출력
log transformation만 적용해도 정규분포 형태가 되는데 여기에 standarad scaler를 적용하면 표준 편차가 1이고 0을 중심으로 하는 표준정규분포를 갖도록 조정됨.
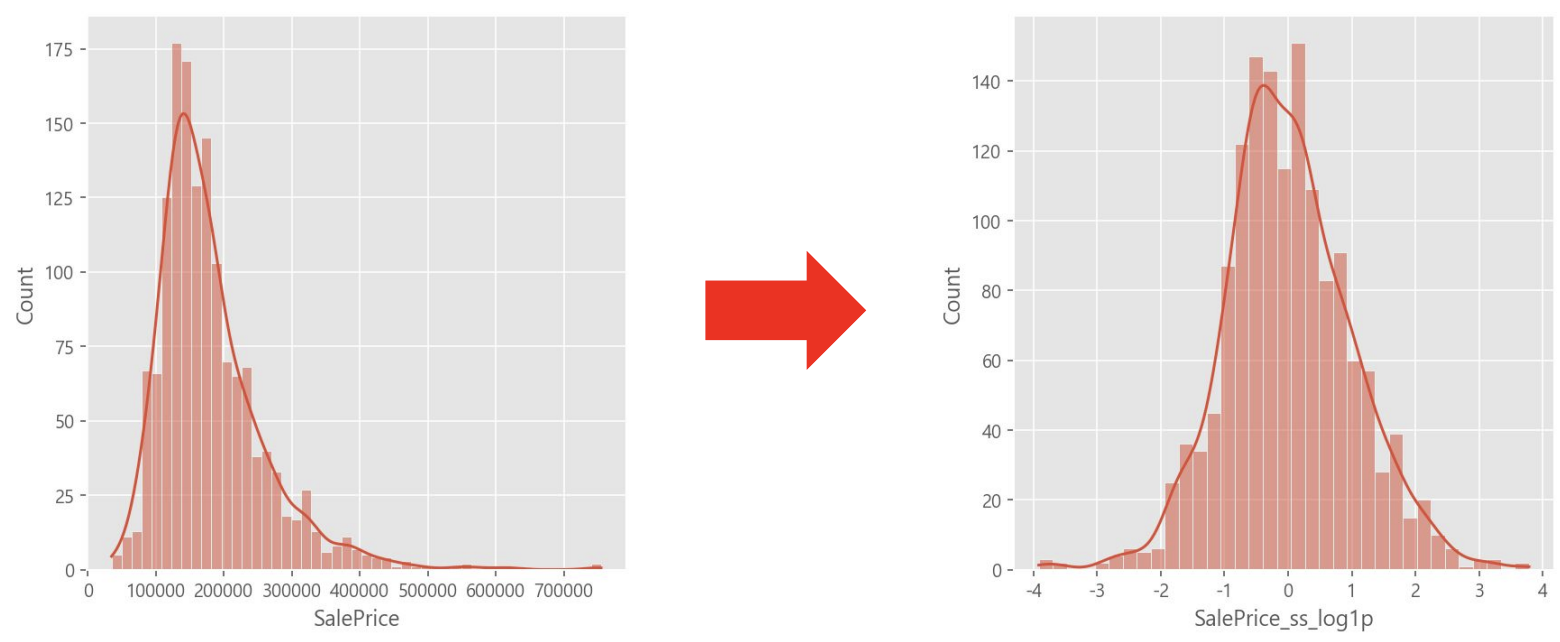
❗️ log transformation 시 주의사항:
- log함수는 x가 0에 수렴할 때, y가 마이너스 무한대로 발산하기 때문에
x>0을 만족해야 한다. (numpy에서는 음수를 NaN값으로 반환)- 그렇기 때문에 주어진 값에 +1 하는 방식으로 log transformation 해주는 것이 안전
numpy.log1p는 사용자가 직접 1을 더하는 것보다 성능이 뛰어나기 때문에 log1p 사용을 권장
이산화 (Discretisation)
수치형 feature를 일정 기준으로 나누어 그룹화하는 것
e.g.) 25세 대신, 20대, 30대, 40대와 같이 10살을 단위로 나눠 분석
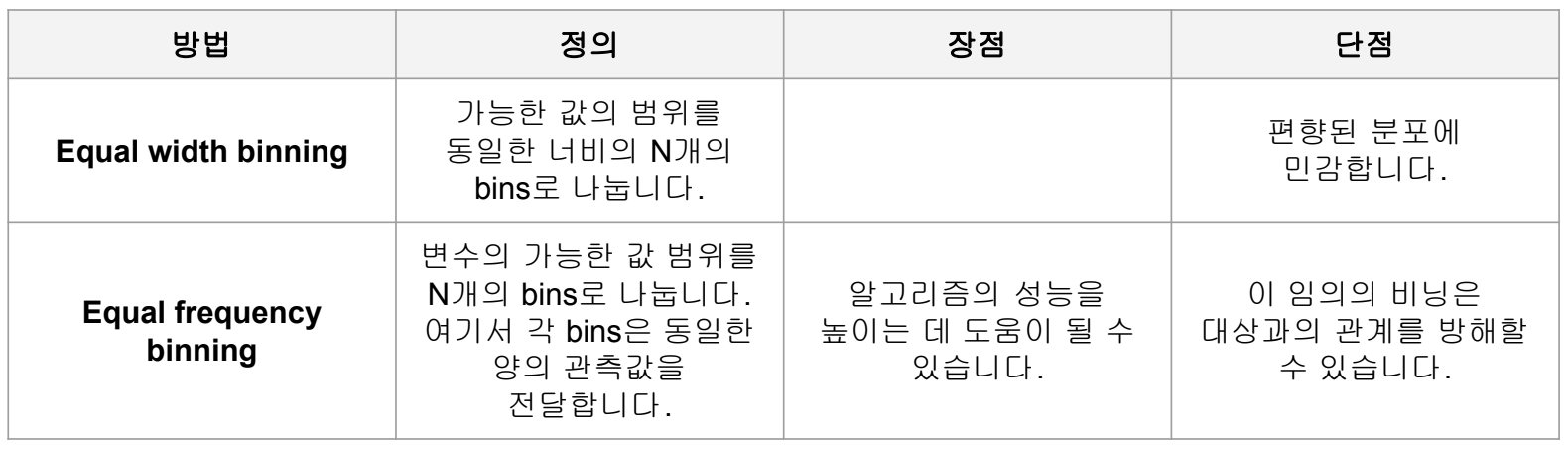
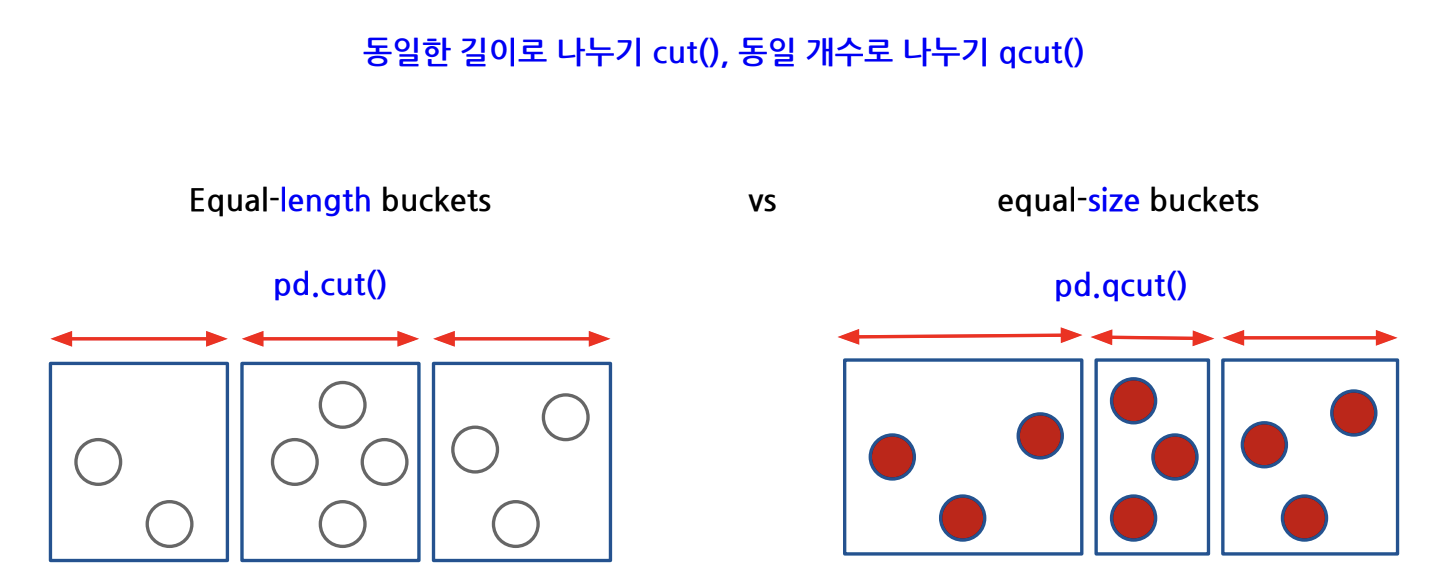
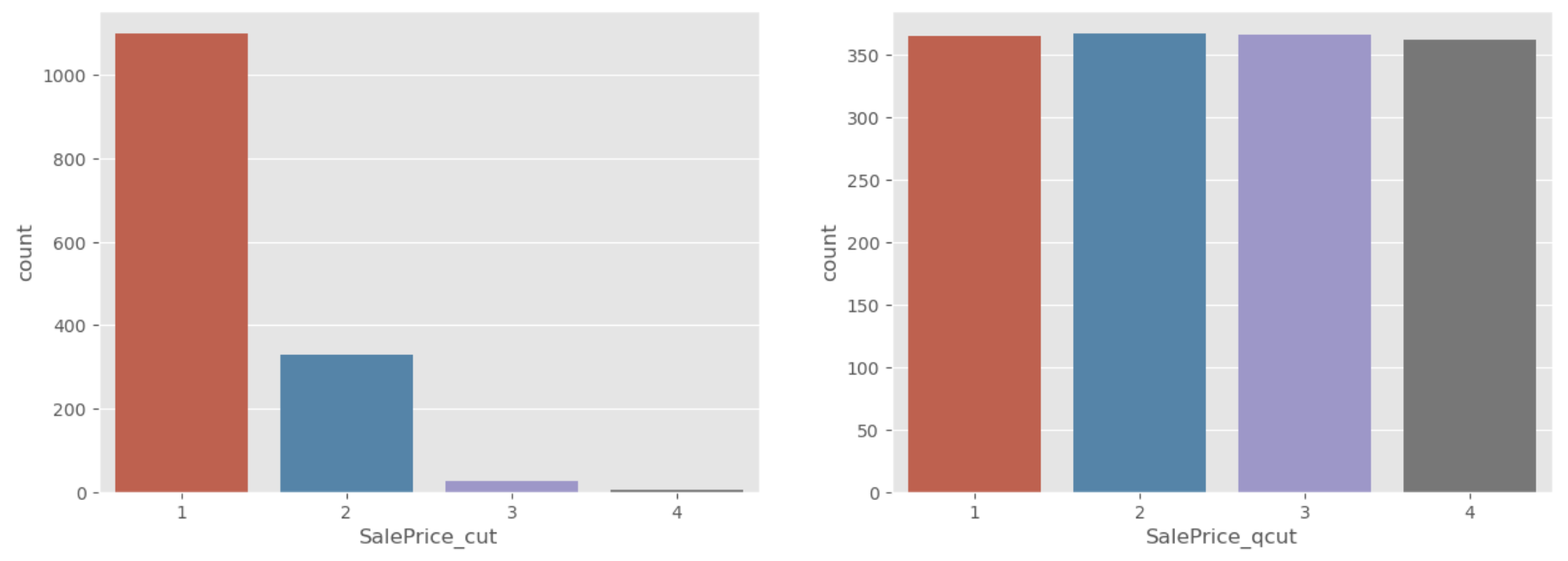
1) Equal width binning; 절대평가 pd.cut()
- 범위를 기준으로 나누는 것 (histogram과 같음). 한 분할 안에 몇개가 들어가는지와 무관하게 전체 수치 범위에 대해 n분할. e.g.) 나이대, 고객을 구매 금액 구간에 따라 나눌 때
- 사용자가 이산화를 할 수치를 직접 입력
2) Equal frequency binning; 상대평가 pd.qcut()
- 빈도를 quantile 기준으로 나누는 것. 개수를 기준으로 n분할. e.g.) 학점, 고객을 고객의 수를 기준으로 등급을 나눌 때
- 계산한 특정 분위수를 기반으로 해서 이산화를 수행
pd.qcut()은 상대평가와 유사한 개념이기 때문에pd.qcut()으로 데이터를 분할하게 되면 비슷한 비율로 나눠줌
🤔 이산화가 왜 필요할까?
직관적이기 때문에 데이터 분석과 머신러닝 모델에 유리하다.
- 수치형 feature로 인한 overfitting 방지
- 적절히 그룹화함으로써 특정 수치형 feature의 영향을 줄임
❗️ 인코딩 (Categorical feature 👉🏻 Numerical feature)
최근 부스팅3대장(Xgboost, LightGBM, CatBoost) 알고리즘 중에는 범주형 데이터를 알아서 처리해 주는 알고리즘도 있지만 사이킷런에서는 범주형 데이터를 피처로 사용하기 위해서는 별도의 변환작업이 필요하다.
부스팅은 약한 예측 모델을 여러개 연결시켜 강한 예측 모델을 만드는 앙상블 기법
1) Ordinal-Encoding
: Categorical Feature를 Numerical Feature 중 Ordinal Feature로 변환
- 직관적이다.
- 오디널 인코딩은 이름처럼 기본적으로 각 카테고리에 고유한 숫자값을 지정해주는 것은 같지만 순서에 의미가 있는 데이터 처럼 각 숫자에 의미가 필요할 경우 사용하게 됩니다. (예: 우수: 3 중간: 2 나쁨: 1)
- 값이 크고 작은게 의미가 있을 때는 상관 없지만, 순서가 없는 데이터에 적용해 주게 되면 잘못된 해석을 할 수 있으니 주의가 필요하다.
2) Label-Encoding
- 라벨 인코더는 기본적으로 딱히 순서에 의미가 없는 데이터에 사용되게 됩니다.(예: 지역코드)
💡 Ordinal / Label Encoding은 비슷한 개념이며, 숫자가 맵핑이 되기 때문에 이에 따른 순서나 연산이 가능하다는 특성이 있다. 이를 원치 않는 경우는 원핫인코딩을 사용.
3) One-Hot-Encoding
: Categorical Feature응 다른 bool변수로 대체하여 특정 레이블이 참인지 여부를 나타냄.
- 해당 컬럼에 해당하는 값을 여러가지 파생변수로 만들어줘서 없으면 0 , 있으면 1로 one-hot형태로 인코딩 해주는 방식
- 장점: 해당 feature의 모든 정보를 유지
- 단점: 해당 feature에 고유값이 너무 많으면 feature를 지나치게 많이 사용
👀 Pandas로 인코딩하기
1) ordinal-encoding
# MSZoning - .cat.codes => Ordinal Encoding, 결과가 벡터, 1차원 형태
# 순서가 있는 명목형 데이터에 사용. e.g.) 기간의 1분기, 2분기, 3분기, 4분기
train["MSZoning"].astype("category").cat.codes
2) one-hot-encoding
pd.get_dummies(train["MSZoning"])
👀 Scikit-learn으로 인코딩하기
❗️ 사이킷런을 사용했을 때 train을 기준으로 fit을 하기 때문에 test는 transform만 하면 됨.
3) ordinal-encoding
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
MSZoning_oe = oe.fit_transform(train[["MSZoning"]])
4) one-hot-encoding
# train에는 있지만 test에만 있는 값은 ohe 되지 않는다.
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
MSZoning_enc = ohe.fit_transform(train[["MSZoning"]]).toarray()
pd.DataFrame(MSZoning_enc, columns=ohe.get_feature_names_out())❗️
판다스로 인코딩했을 때 문제점은 테스트 데이터에 대한 인코딩에서 발생. 사이킷런의 원핫인코딩은 train 데이터로만 학습해서 진행하기에 test에만 존재하는 데이터를 인코딩하지 않는다. 그러나 판다스는 이 기능이 없어서 test셋과 train셋의 고유값을 비교해줘야 하는데, 현실에서 test 데이터는 미래의 데이터라 모르기 때문에 권장하지 않는다.
파생변수
다항식 전개 (Polynomial Expansion)
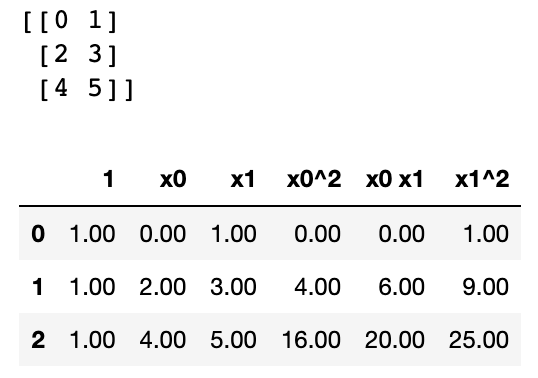
- [a, b]가 Feature로 주어질 때 다항식의 최대 차수를 2로 지정한다고 가정 했을 때 새로 생성될 수 있는 Polynomial Feature는 [1, a, b, a^2, ab, b^2]이다.
👉🏻 데이터를 임의로 뻥튀기하는 것,,ㅎ차수: degree
# np.reshape은 array의 shape값을 지정해서 shape을 변환해 준다.
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6).reshape(3, 2)
print(X)
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
pd.DataFrame(X_poly, columns=poly.get_feature_names_out())Output:
🙋🏻♀️ 질문
Q: IQR을 어디서 사용했을까요?
A: 박스플롯
Q: 스케일링 방법 중에서 표준화(Z-score), Min-Max, Robust 중 이상치에 가장 덜 민감한 스케일링 방법은 무엇일까요?
A: Robust scaling
Q: transform 기능 설명 부탁드리겠습니다.
A: fit은 해당 columns을 기준으로 받고 맞춰주는 역할을 합니다.
fit된 기준으로 해당 컬럼이나 다른 컬럼들의 값을 바꿔주기 원할 때 transform을 사용합니다.
Q: 기술 통계로 봤을 때 StandardScaling (Z-score scaling) 의 특징?
A: 평균 == 0, 표준편차 == 1로 만든다.
Q: 기술 통계로 봤을 때 Min-Max의 특징?
A: 최솟값 == 0, 최댓값 == 1로 만든다.
Q: 기술 통계로 봤을 때 Robust Scaling의 특징?
A: 중간값(중앙값, 50%, 2사분위수)가 0이다.
또, 이상치에 영향을 덜 받는다.
Q: 표준 정규분포 형태로 변환이 된 것은 어떤 것일까요?
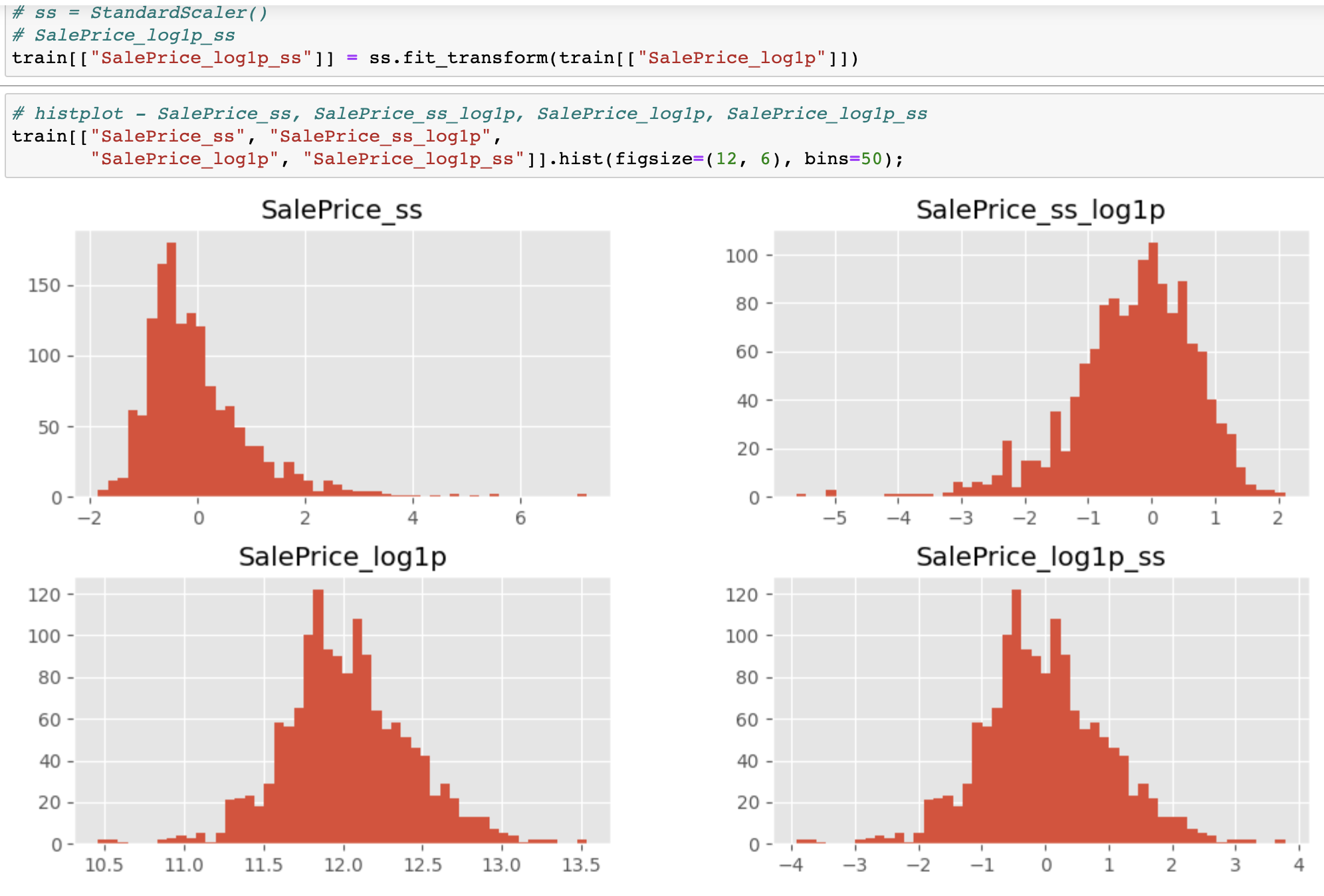
A: SalePrice_log1p_ss 가장 표준정규분포에 가깝다. SalePrice_log1p 도 정규분포에 가까운 모습이다.
Q: uniform 이란?
A: histogram을 그렸을 때 어딘가는 많고 적은 데이터가 있다면 그것도 특징이 될 수 있는데, 특징이 잘 구분되지 않는다면 power transform 등을 통해 값을 제곱 해주면 특징이 좀 더 잘 구분되어 보이기도 한다.
🦁 질문
Q: Robust Scaling에서 IQR로 나눠준다는 건 상위 75%의 값-하위25%의 값으로 나누는 것을 의미하나요?
A: 맞다.
Q: 절대적인 값보다 상대적인 값에 영향을 받는다는 것이 무슨 말인지 잘 모르겠습니다.
A: 예를 들어 1~10 인 값이 있고 어떤 값은 1 ~1000 인 값이 있다면 여기에서 절대적인 크기보다 그 값의 상대적인 값을 보게 됩니다. 1~10인 값의 중간값은 5, 1~1000인 값의 중간값은 500 이런식으로 상대적인 값을 보게 됩니다.
- 절대평가: 간격으로 나누기
- 상대평가: 개수로 나누기 e.g.) 학점
Q: 표준정규분표와 그냥 정규분포 두 개 중에는 모델에서 사용할 때 성능차이가 많이 나나요?
A: 트리계열 모델을 사용한다면 일반 정규분포를 사용해도 무관합니다. 그런데 스케일값이 영향을 미치는 모델에서는 표준정규분포로 만들어 주면 더 나은 성능을 낼 수도 있습니다. 표준정규분포로 만들 때 값이 왜곡될 수도 있기 때문에 주의가 필요합니다. 꼭 이런 변환작업을 많이 해준다고 해서 모델의 성능이 좋아진다고 보장할 수 없습니다. 상황에 맞는 변환방법을 사용하는 것을 추천합니다.
Q: 보통 스케일링을 먼저 하는 것보다는, 먼저 log를 적용한 후 스케일링으로 바꿔주는게 순서가 맞나요?
A: 데이터에 따라 다르겠지만 만약 로그를 적용해줘야겠다고 한다면 로그 적용 후 스케일링해주는 것이 분포가 정규분포에 가깝기 때문에 일단 log를 적용해줍니다.
Q: Ordinal Encoding과 Label Encoding은 같은건가요?
A: Ordinal Encoding과 Label Encoding의 방식에는 차이가 없다. 다만 Ordinal은 피처 및 다차원을 변환할 때 사용하고, Label은 타겟 및 일차원을 변환할 때 사용하는 차이가 있다.
✏️ TIL
- 사실(Fact): 피처스케일링, 이상화, 인코딩과 파생변수에 대해 배웠다.
- 느낌(Feeling): 오늘도 너무 많은 개념을 한 번에 머리에 넣어 이해하려니 쉽지않다.
- 교훈(Finding): 복습 꼭 할 것...!!!
