
머신러닝 분류 알고리즘
앙상블이랑 비슷한 개념으로는 stacking이 있다.
신경망을 쓰면 머신러닝, 신경망을 안 쓰면 딥러닝
딥러닝은 비정형데이터를 사용할 때 성능이 더 좋다.
정형데이터와 비정형데이터
정형데이터: 판다스로 불러와서 전처리가 가능한 데이터
비정형데이터: 이미지, 오디오; 음성데이터 (데시벨, 주파수와 같은 특징값들을 추출해서 학습)
bagging vs boosting
bagging: 랜덤포레스트
boosting: gradient boosting, XGBM
ensemble vs stacking
ensemble: 다른 모델들을 여러개 합치는 것
stacking: 같은 모델들을 여러개 합치는 것
일반화가 잘된 모델이 test 데이터 (현실세계)에서는 더 좋은 성능을 낸다.
ensemble
1) Voting 과 2) Bagging
보팅과 배깅은 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
- hard voting: 최종 모델을 다수결로 결정
- soft voting: 모든 예측값의 평균을 결정
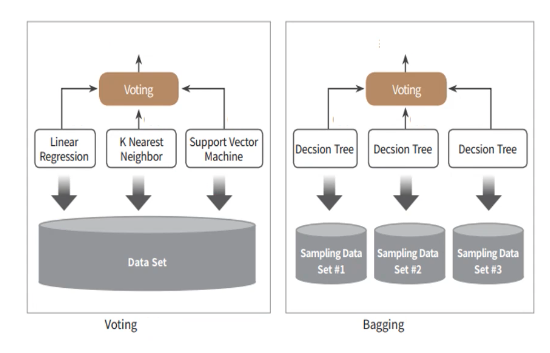
=> 보팅은 각각의 분류기가 다르고, 배깅은 각각의 분류기가 같은 알고리즘을 사용함
=> 사진 속 bagging은 RandomForest
3) Boosting
: 여러 개의 분류기가 순차적으로 학습을 수행하지만, 앞의 분류기에서 틀린 문제를 다음 분류기에서 맞출 수 있도록
가중치(weight)를 부여하는 방식. == 틀린 문제에 가중치를 더 부여해서 더 잘 예측할 수 있도록 학습
4) Stacking
: 여러개의 다른 모델의 예측 결과를 다시 학습 데이터로 만들어 다른 모델로 재학습시켜 결과를 예측하는 방식
GBM (Gradinet Boosting Machine)
- 부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해 나감
- 이런 학습 방법은 AdaBoost(Adaptive boosting)가 대표적이지만, GBM은 가중치를 주는 방식이 경사 하강법(Gradient Descent)임
XGBoost (eXtra Gradient Boost)
트리 기반의 앙상블 알고리즘 모델
분류에 있어서, 일반적으로 가장 좋은 성능을 가짐
GBM 대비 빠른 수행 시간
규제(Regularization): 규제를 적용해 과적합을 방지 가능
가지 치기(Tree Prunung): 이득이 없는 분할을 없애, 분할 수를 줄임
교차 검증 내장: 최적화된 반복 횟수를 가질 수 있음, 조기 중단(early stopping) 지원
결측치 제거
❗️Note!!!! 과적합 문제가 발생했다면 뛰어난 알고리즘일수록 파라미터 튜닝을 할 필요가 적어짐 -> 튜닝의 영향이 크지 않기때문
- eta 값을 낮추고 n_estimators값을 올려줌
- max_depth 값을 낮춤
- min_child_weight 값을 높임
- gamma 값을 높임
- sub_sample과 colsample_bytree 조정
조기 종료 (Early Stopping) (딥러닝에서 많이 사용)
반복된 횟수만큼 학습을 진행하면서, 지정된 횟수만큼 성능 개선이 일어나지 않으면 학습을 종료하는 기법
- 성능 개선 없이 계속 학습을 하면 오버피팅현상이 일어날 수 있기 때문에 조기 종료가 중요하다.
LightGBM(채현님 픽)
XGBoost와 같은 부스팅 알고리즘으로, XGBoost에 비해 빠르고 리소스를 적게 사용하며, 카테고리형 특성을 자동으로 변경해준다는 장점이 있음
반면, 데이터 양이 적은 경우 오버피팅 발생 가능성이 높다는 단점이 있음(일반적으로 10k개 이하)
리프 중심 트리 분할(Leaf Wise) 방식을 사용함 -> 기존 트리 기반 알고리즘들은 깊이를 효과적으로 줄이기 위해 균형 트리 분할(Level Wise) 방식을 사용했음
LightGBM은 트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 계속 분할하는 방식
단점: 다중분류나 다중회귀를 할 수 없음.
CatBoost
: 범주형 데이터를 수치형으로 바꿔줄 필요 없다. (전처리 ❌)
주요 평가 지표
정확도 (Accuracy)
: 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
- 직관적으로 모델의 성능을 평가 할 수 있지만, 성능을 왜곡할 가능성도 있음
👉🏻 데이터가 지나치게 잘 구성되어 있는 경우 - 데이터가 불균형한 경우
오차행렬 (Confusion Matrix)
: 이진 분류에서 성능 지표로 사용 됨. 예측을 수행하면서 얼마나 헷갈리고 있는지도 함께 보여줌
- True/False Positive/Negative를 이용한 방식
정밀도와 재현율 (Precision and Recall)
Positive 데이터 세트의 예측 성능에 좀 더 초첨을 맞춘 평가 지표
정밀도 (Precision)
: 양성 예측도라고도 불림.
- 실제 음성인 값을 양성으로 판단하면 안되는 경우 중요 (스팸 메일 분류 등)
$ Precision = {TP \over (FP + TP)} $
재현율 (Recall)
: 민감도(sensitivity) 또는 TRP(True Positive Rate)라고도 불림.
- 실제 양성인 값을 음성으로 판단하면 안되는 경우 중요 (암 판단 모델 등)
$ Recall = {TP \over (FN + TP)} $
F1 score
: 정밀도와 재현율을 결합한 지표로, 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가짐
회귀
: 정답값과 예측값의 차이(=오차)가 얼마나 적은지를 기준으로, 내가 만든 모델이 예측을 잘 했는지 평가한다.
그리고 그 오차를 평가하는 지표로 MAE, MAPE, MSE, RMSE 등등이 있다.
대표적인 회귀 모델
1) 일반 선형 회귀
2) 릿지(Ridge): 선형 회귀에 L2 규제를 추가한 회귀 모델
3) 라쏘(Lasso): 선형 회귀에 L1 규제를 추가한 회귀 모델
4) ElasticNet: L1과 L2 규제를 결합한 회귀 모델
💡 보통 뒤에 net이 붙으면 딥러닝 모델
경사 하강법(Gradient Descent)
- 실제 값과 회귀 모델의 차이에 따른 오류 값을 잔차라하며, 최적의 회귀 모델을 만든다는 것은 잔차(오류 값)를 최소화하는 모델을 만드는 것
- 보통 오류 합을 계산할 때는 절댓값을 취해 더하거나(MAS), 오류 값의 제곱을 더하는 방식(RSS, Residual Sum of Square)을 취함
- 회귀에서 RSS는 비용(cost)이며, 이를 비용 함수(cost func.)라고 함
