
INNOPOLIS AI SPACE-S 인공지능 세미나 - 정형 데이터를 다루는 머신러닝 문제해결 패턴
0. 머신러닝 문제해결 프로세스
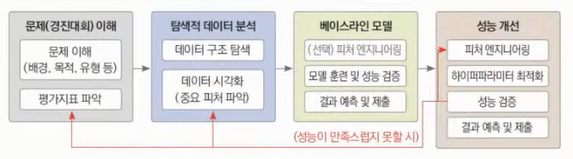
1. 문제 이해
이 부분을 잘 이해하지 못하고 넘어가면 모델링을 처음부터 다시 해야하는 일이 생길 수도 있기 때문에 문제와 데이터를 확실하게 이해하는 것이 중요하다.
- 문제 배경과 목적
- 문제 유형 확인
- 데이터 확인
- 문제 접근 방법 (어떻게 접근해서 문제를 풀어야 하는지)
2. 탐색적 데이터 분석(EDA)
: 주어진 데이터의 구조를 간단히 훑어보거나 몇가지 통계값을 구해봄.
1. 제공된 파일별 용도 파악
2. feature 이해(feature 요약표 활용)
신백균 발표자님은 feature 요약표를 만들어 확인 하셨음.
👉 feature 개수가 많을 때 유용; 개별 feature로 파악하지 못했던 정보를 feature 요약표를 보면 한 눈에 확인 가능
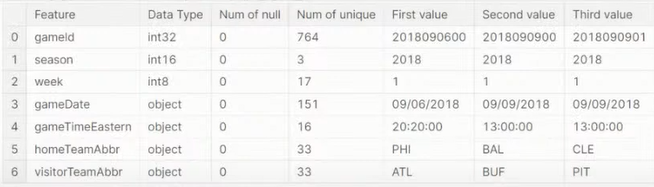
- train과 test 데이터의 차이(분포 확인)
- 타깃값 파악
2-1 시각화: 다양한 시각화를 통해 데이터 전반을 깊이 있게 살펴봄.
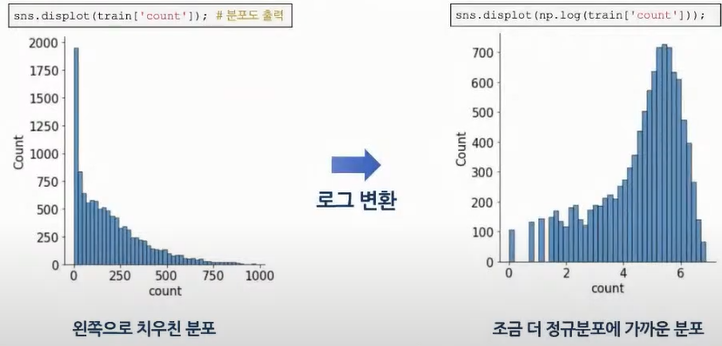
👉 왼쪽으로 치우친 데이터는 예측 분석 성능이 떨어질 수 있어서 로그 변환으로 정규분포에 가깝게 타깃값을 변환
2-2 피처파악
상관관계를 정대적인 지표로 보긴 어려운 이유:
- 상관관계가 높은 feature 두개가 있어 두개 중 하나를 제거했는데 오히려 성능이 떨어진 경우
- 상관관계가 낮은 feature를 제거했을 때 성능이 좋아진 경우
2-2-1 피처별 인코딩 전략
레이블 인코딩: 가까운 숫자끼리 비슷한 데이터로 판단
👉 데이터간의 대소관계, 크기의 차이가 유의미한 경우에 사용
원핫인코딩: 고윳값별로 독립적인 데이터로 판단
2-3 이상치, 결측값 파악
EDA 과정에서 어떤 feature가 중요한지, 어떤 조합으로 새로운 feature를 만들지, 어떤 점을 주의해서 모델링 할지 등의 인사이트를 얻게 됨.
3. 베이스라인 모델 설계 (뼈대 만들기)
깡통 모델이라도 베이스라인 모델 먼저 만들고 시작하는 것을 추천.
- 아주 간단한 기본 모델을 생성 및 훈련해 성능 확인
- 추후 모델링을 진행하면서 여기에 살을 덧붙여 성능을 끌어올림
Note: Scikit-learn은 기본적인 평가지표를 제공하고 있다.
4. 모델 성능 개선 방안
4-1 피처 엔지니어링 (파생 피처 생성 및 전처리)
4-1-1 시계열 데이터 한정 시차피처 생성가능
: 과거 시점의 타겟값을 현재 시점의 피처로 사용할 수 있음
👉 시계열문제에서 트렌드와 유사성을 반영할 수 있기 때문에 성능향상에 큰 도움
4-1-2 데이터 인코딩
4-1-3 데이터 다운 캐스팅
4-1-4 피처 스케일링
데이터의 대소관계를 비교하기 때문에 XGBoost와 같은 트리계열 모델에서는 굳이 사용 할 필요 없음.
4-2 하이퍼 파라미터 최적화
발표자님은 베이지안 최적화 (Bayesian optimization)이 성능이 좋기 때문에 추천
시각화는 brightics AI 사용하면 시간을 절약 할 수 있다.
✍🏻 TIL
- 사실(Fact): 이번주에 배웠던 데일리 키워드 중 하나를 골라 팀원들과 자료를 정리하고 발표하는 시간을 가졌다. 이번주 우리팀의 키워드는 Ensemble.
- 느낌(Feeling): 좋은 팀원들과 좋은 자료를 만들어 발표자로 발표까지 하게 되었다. 발표 재밌었고, 재잘재잘팀원들 한 달만에 만나게 되어 너무 반가웠다!
- 교훈(Finding): 다른팀들의 자료도 참고해서 수업 이해도를 높여야겠다.
