
✨ 다음주부터 딥러닝을 배우게 되는데 그 전에 딥러닝 맛보기!
📌 함수의 정의
손실함수(Loss function)
: 한 개의 데이터 포인트에서 나온 오차를 최소화하기 위해 정의되는 함수
비용함수(Cost function)
: 모든 오차를 일반적으로 최소화하기 위해 정의되는 함수
목적함수(Objective function)
: 어떤 값을 최대화 혹은 최소화 시키기 위해 정의되는 함수
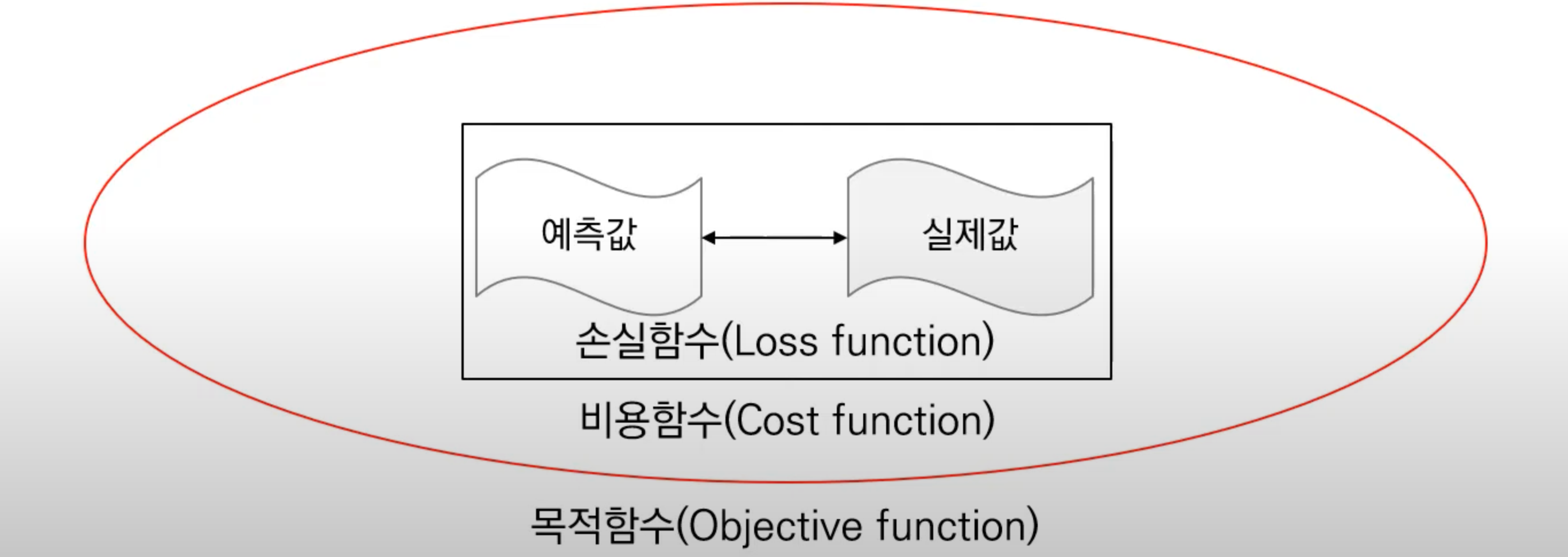
✅ 손실함수, 비용함수, 목적함수는 분명 다르게 정의되지만 일반적으로 혼용해서 사용됨.
🤔 손실함수란?
: 오차(예측값과 실제값의 차이)를 도출하기 위한 식
📌 딥러닝 모델 학습 프로세스
💡 목표: 반복을 통해 오차를 최소한으로 줄이는 매개변수를 찾는 것
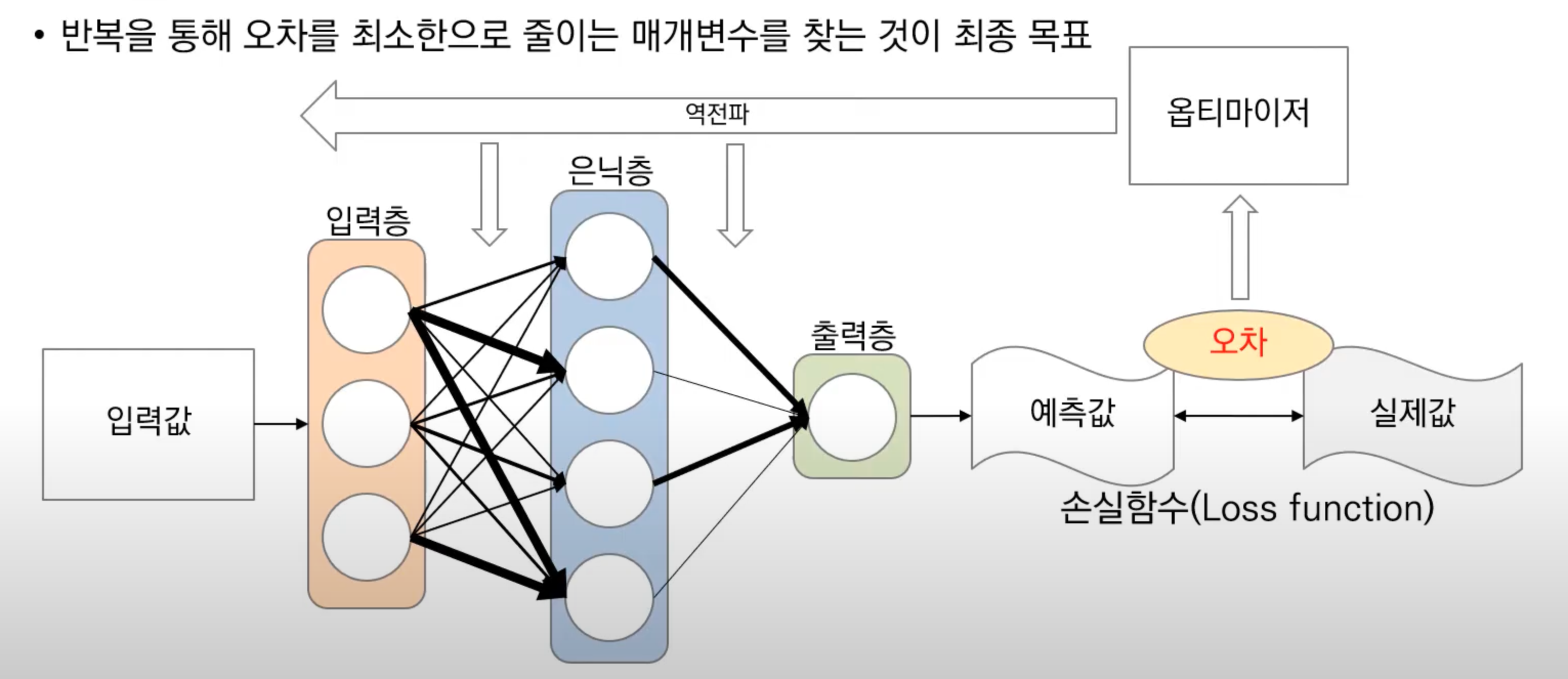
1) 신경망 구조의 딥러닝 모델(입력층, 은닉층, 출력층)을 정의
2) 임의의 데이터에서 전처리를 수행한 입력값 정의
3) 입력값을 딥러닝 모델에 넣고 임의의 매개변수를 지정하여 각 층 별로 연결
4) 딥러닝 모델에서 임의로 지정된 매개변수 값에 따라 순전파를 이용하여 예측값 생성
5) 생성된 예측값을 실제값과 비교 (=손실함수)
5) 예측값을 실제값과 손실함수를 통해 오차 생성
6) 오차를 옵티마이저를 통해 역전파를 진행하여 매개변수를 업데이트
📌 데이터 형식에 따른 손실함수
회귀 모델에서의 손실함수
: 회귀는 성능 x에 따른 가격 y를 예측해 선 ŷ를 구하는 문제
- 손실함수를 이용하여 예측값 ŷ과 실제값 y의 오차를 구함
(오차는 음수 또는 양수로 나올 수 있기 때문에 절대값을 씌움) - 전체 데이터에 대한 오차를 더하고 평균으로 나눈 MAE 도출
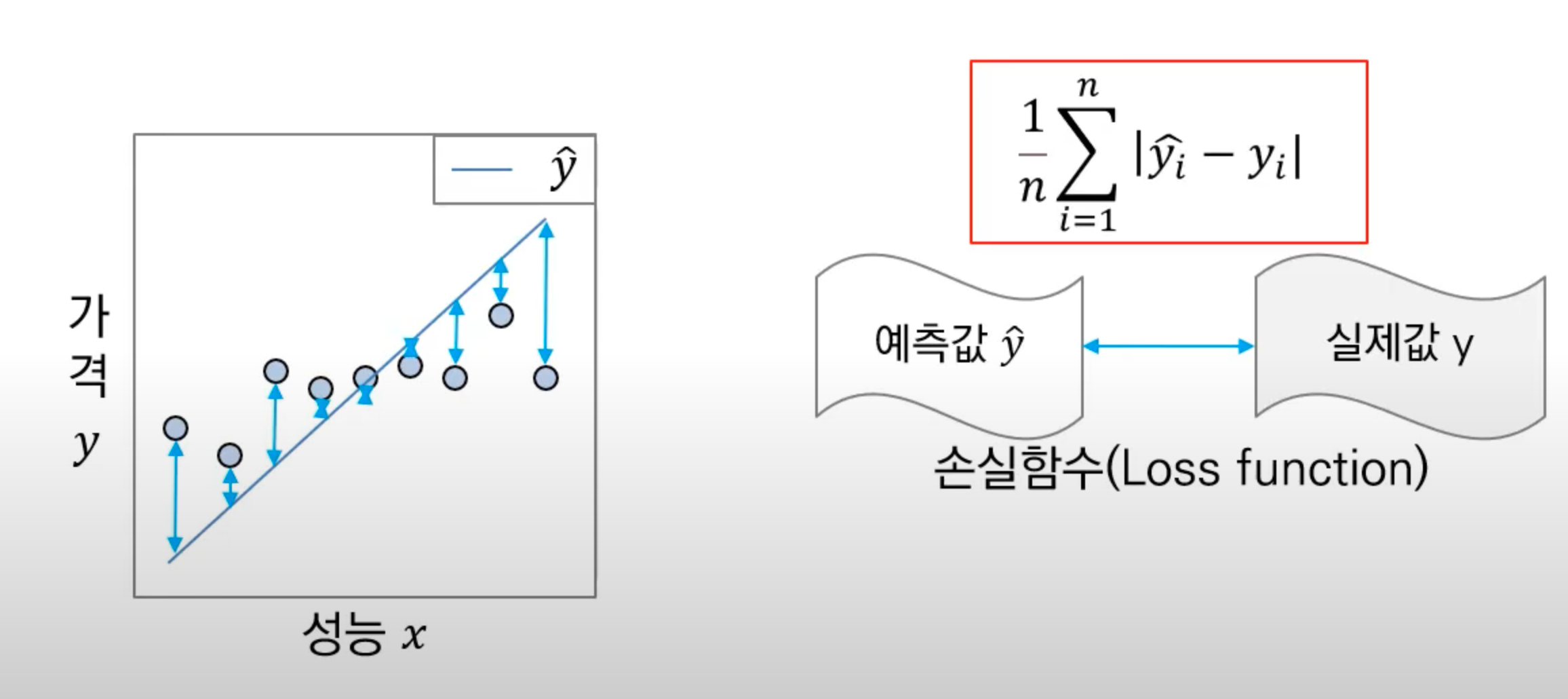
평균절대오차(MAE) : 미분이 불가능하다는 단점이 있음
평균제곱오차(MSE) : MAE의 단점을 보완
분류 모델에서의 손실함수
예시) 짱구의 이름을 분류하는 모델
: 예측값과 원핫벡터로 이루어진 실제값의 차이를 교차엔트로피 손실함수 (Cross entropy)를 통해 오차 도출
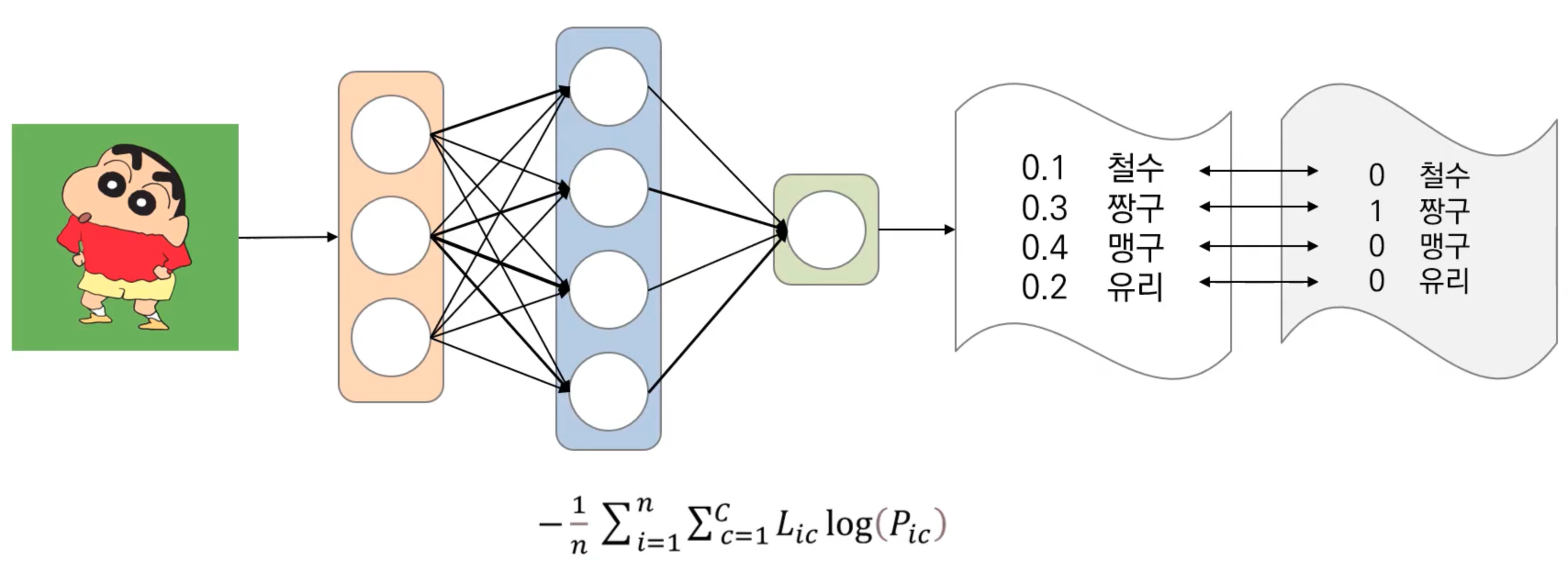
분류 문제에서 데이터의 라벨(실제값)은 one-hot-encoding을 통해 표현된다.
L: 예측값, P: 실제값
👀
cross entropy는 실제 entropy 보다 항상 크다. entropy는 고정이기 때문에, cross-entropy를 최소화 시키는 것이 예측 모형을 최적화 시키는 것이라고 할 수 있다. 이것이 불확실성을 제어하고자하는 예측모형의 실질적인 목적이라고 볼 수 있다.
📌 최고의 손실함수 탐색
- 저해상도 이미지를 고해상도 이미지로 변환하는 분야 (Super Resolution)에서 MSE를 주로 이용했는데 최근엔 다양한 손실함수를 이용함.
✏️ TIL
- 사실(Finding): 목요일마다 있는 인사이트 데이에서 팀 별로 키워드를 정해 복습하는 시간을 가졌다. 우리팀은 r2 score에 대해 정리했는데, 손실함수에 대해 정리한 팀의 자료로 딥러닝을 미리 접해봐야겠다 생각했다.
- 느낌(Feeling): IT 업계에서 일하려면 꾸준히 공부해야 한다는 말이 이제서야 실감난다. 세상엔 너무 많은 알고리즘들이 있고 지금 이 순간에도 새롭게 생겨나고 있을 지도 모른다.
- 교훈(Finding): 배워야 할 것이 많은 만큼 지치지말고 꾸준하게 공부하자!
