
머신러닝 기본적인 절차
- 데이터 전처리
- 데이터 세트 분리 (train, validation, test)
- 모델 학습
- 예측 수행
- 평가
Estimator 알고리즘 분류
- Classification
- DecisionTree == white box (설명이 가능하다)
- RandomForest (DecisionTree의 앙상블 버전)
- SVC
- Regressor
- Linear
- Ridge
- RandomForest
현업에서는 XGBoost나 LightGBM을 많이 사용함.
🤔 Validation set을 만들어서 cross validation을 하는 이유?
- 수능을 보기 위해 기출문제를 풀어보는 것 == train set
- 결과를 내기 위해 보기 위해 문제를 푸는 것 == test set
- 수능 보기 직전에 모의고사를 풀었을 때 기출문제에서 풀었던 문제가 나온다면 한 번이라도 봤던 문제가 나온것 == 이걸 위해 cross validation을 함.
하이퍼파라미터와 파라미터의 차이
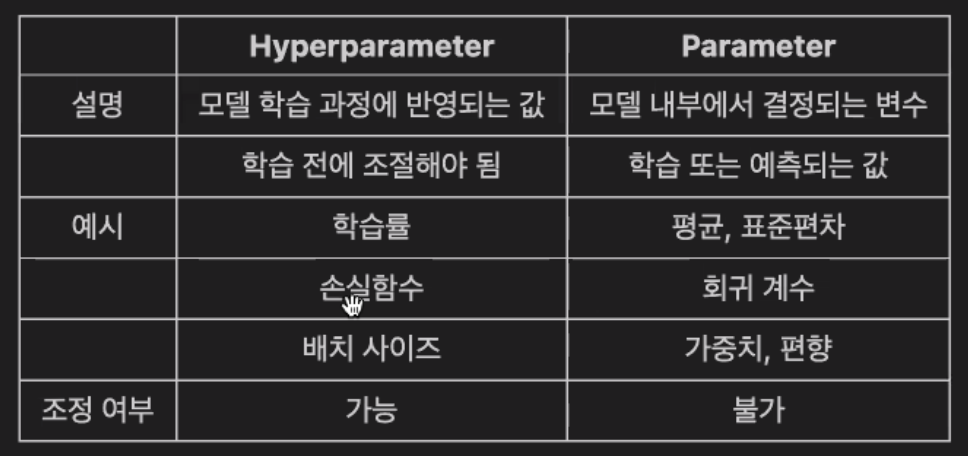
- 하이퍼파라미터: 사람이 직접 입력해 줘야하는 값
- 파라미터: 모델이 스스로 학습하면서 결정하는 값 (사람이 조정 할 수 없음)
Underfitting / Overfitting
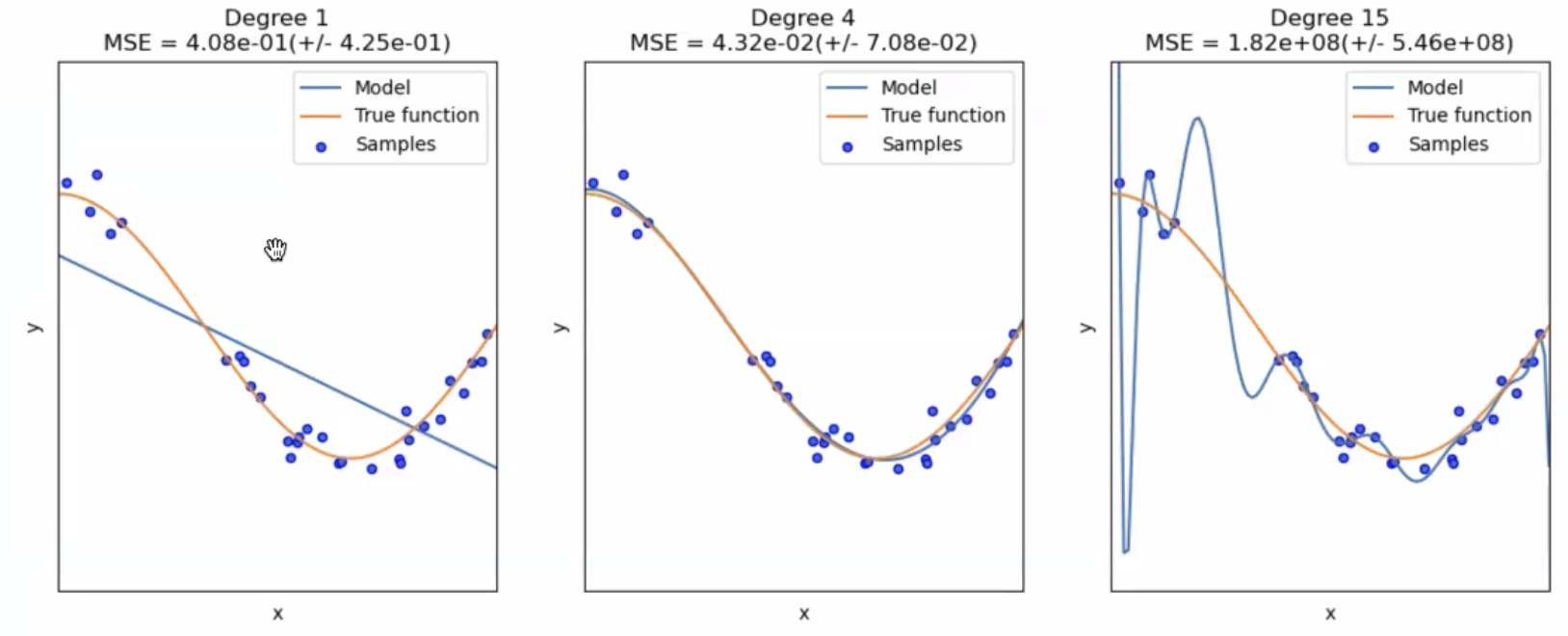
1번 그래프: Underfitting
👉🏻 모델이 학습을 하기위한 데이터가 부족한 경우
2번 그래프: Ideal model
3번 그래프: Overfitting
👉🏻 실제 데이터를 완벽하게 트래킹하고 있지만 그래프를 과하게 그리고 있음
👉🏻 학습 시킨 데이터에 대한 성능은 아주 좋지만 새로운 데이터를 넣었을 땐 좋은 성능을 내지 못함.

데이터 분석가가 되기 위한 기록 ✏️