
0503 실습:
"PassengetId"는 unique한 값이고, feature로 사용하지 않을거라 index로 지정 (Index로 지정하면 feature에서 자동으로 걸러짐).
현실세계에서 test는 아직 모르는 데이터이기 때문에 데이터 전처리를 할 때는 train을 기준으로 합니다. 전처리를 통해 train과 test의 feature의 개수를 같게 만들어 줍니다.
👉🏻 train과 test의 feature 개수가 다르면 오류가 발생합니다.
👉🏻 One-hot-encoding을 할 때 train과 test feature의 개수와 종류가 같은지 확인 합니다.
- 예를 들어 train feature는 수학인데 test feature는 국어라고 하면 feature의 개수가 같더라도 다른 종류 값이기 때문에 제대로 학습할 수 없습니다.
👉🏻 feature를 컬럼명으로 만들 때도 제대로 만들어지지 않습니다.- train에만 등장하는 호칭은 학습을 해도 test에 없기 때문에 예측에 큰 도움이 되지 않습니다.
- train에만 등장하는 호칭을 feature로 만들어 주게되면 feature의 개수가 늘어나는데 불필요한 feature가 생기기도 하고 데이터의 크기도 커지기 때문에 학습에도 시간이 걸립니다.
👉🏻 너무 적게 등장하는 값을 feature로 만들었을 때 해당 값에 대한 오버피팅 문제도 있을 수 있습니다.
💡 단축기 ESC + F: 해당 셀에서 일괄적으로 단어를 변경할 수 있다.
전처리
- 현실세계에서 분석하는 데이터는 함부로 결측치를 채우는것을 꼭 주의해야 함.
- 머신러닝 알고리즘에서 오류가 발생하지 않게 하기 위해 결측치를 채운 것이라 분석할 때도 채운다고 오해하면 안 됨.
One-Hot-Encoding
모델이 학습할 때 문자는 인식을 하지 못해서 학습할 때 에러가 뜹니다. 따라서 문자에서 숫자로 바꿔주는 인코딩이 필요한데 그 인코딩 방식 중 하나가 One-Hot-Encoding 입니다.
Ordinal-Encoding: 순서가 있는 데이터에 사용.
One-Hot-Encoding: 순서가 없는 데이터에 사용.
get_dummies(): 수치형 데이터와 범주형 데이터를 함께 넣어주어도 수치형 데이터는 그대로 두고 범주형 데이터에 대해서만 인코딩 합니다.
학습, 예측 데이터 셋 만들기
❗️
# 학습, 예측 데이터셋 만들고 같은 컬럼을 가지고 있는지 확인하는 과정 필수!!
set(X_train.columns) == set(X_test.columns)머신러닝 알고리즘 가져오기
Cross validation
- cross_validate : Evaluate metric(s) by cross-validation and also record fit/score times.
학습결과에 대한 점수와 시간 출력. 점수를 보고자 할 때는 편리하지만 지정한 metric에 의해서만 점수가 계산된다.- cross_val_score : Evaluate a score by cross-validation.
점수 출력.- cross_val_predict : Generate cross-validated estimates for each input data point.
에측 값이 그대로 나와서 직접 계산해 볼 수 있다. 직접 다양한 측정 공식으로 결과값을 비교해 볼 수 있다.
# 랜덤포레스트를 사용해도 되지만, decision tree를 사용하고 cross validation을 하게되면
# 여러번 학습하기 때문에 빠르게 학습시켜 결과를 볼 수 있다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = 6, random_state=42)
# cross validation
from sklearn.model_selection import cross_val_predict
y_predict = cross_val_predict(model, X_train, y_train,
cv=5, n_jobs=-1, verbose = 2)
# Accuracy 측정하기
(y_train == y_predict).mean()
# 학습
model.fit(X_train, y_train)
# 피처의 중요도 시각화 하기
sns.barplot(x = model.feature_importances_, y = model.feature_names_in_);
# 예측
y_predict = model.predict(X_test)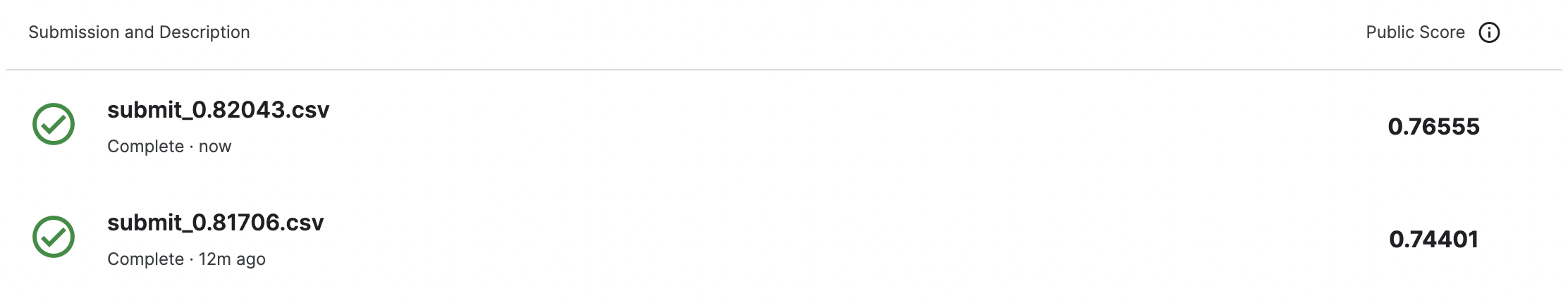
" 200위 근처의 점수를 보면 0.81~0.82 정도가 있는데 이정도가 머신러닝의 다양한 기법을 사용해서 풀어볼 수 있는 현실적인 스코어 구간이라고 볼 수 있습니다. "
🤔 내 점수는 어떻게 해야 오를까..?
💡 캐글에서 좋은 솔루션 찾는 법
1) Top 키워드로 검색
2) 솔루션에 대한 투표수가 많은 것
3) 프로필 메달의 색상
0504 실습:
전처리
결측치 채우기
fillna()대신interpolate()로 결측치 채우기
# 이전 값이나 다음 값으로 채울 수 있는데 이런 방법은 대부분 시계열데이터에서
# 데이터가 순서대로 있을 때 사용합니다.
# 예를 들어 일자별 주가 데이터가 있다고 가정할 때
# 중간에 빠진 날짜에 대한 데이터를 채울 때 사용하거나
# 예를 들어 순서가 있는 센서 데이터에서 수집이 누락되었거나
# 앞, 뒤 값에 영향을 받는 데이터를 채울 때 사용합니다.
# 여기에서는 데이터가 순서대로 있다는 보장은 없지만 이렇게 채울수도 있다는 방법을 알아보겠습니다.
# fillna
# method : {'backfill', 'bfill', 'pad', 'ffill', None},
# Method to use for filling holes in reindexed Series
# pad / ffill: propagate last valid observation forward to next valid
# backfill / bfill: use next valid observation to fill gap.
# interpolate (보간법)
# limit_direction : {{'forward', 'backward', 'both'}}
# both 로 지정하면 위 아래 결측치를 모두 채워주고 나머지는 채울 방향을 설정합니다.
train["Age_ffill"] = train["Age"].fillna(method="ffill") # 앞의 값을 채움
train["Age_bfill"] = train["Age"].fillna(method="bfill") # 뒤의 값을 채움
# train["Age_interpolate"] = train["Age"]
train["Age_interpolate"] = train["Age"].interpolate(method='linear',
limit_direction='both') # 앞, 뒤 값의 평균을 채움
train[["Age", "Age_ffill", "Age_bfill", "Age_interpolate"]].tail()🙋🏻♀️ 질문
Q: train과 test 한쪽에만 있는 호칭은 어떻게 처리하면 좋을까요?
A: 빈도수가 적다면 기타로 묶어주면 됨.
Q: 왜 valid 점수와 실제 캐글 점수가 다를까요?
A: vaild는 train 데이터셋에서 검증한것이고, 캐글에 있는 정답셋과 다시 비교하기 때문입니다.
Q: train으로 측정한 validation 점수는 0.80 인데 캐글 스코어가 0.73 이라면 어떤 상황이라고 볼 수 있을까요?
A: train 데이터에 과대적합(오버피팅)되어서 test 데이터셋으로 예측했을 때는 스코어가 낮게 나왔습니다.
🦁 질문
Q: title_count > 2와 title_count <= 2 의 차이도 있다고 하셨었나요?
A: 2개보다 큰 값만 가져오도록 했는데 2개보다 작은 값에 대해서만 예외처리를 하게 되면 앞으로 다른 train, test에 없는 값이 들어왔을 때 다시 전처리 해주어야 합니다. 예외에 추가가 필요합니다.
Q: 적은 값들을 etc로 묶어주면 그로 인한 결과값도 달라지지 않나요?
A: 범주형 데이터의 경우에는 결측치 처리를 하면 원핫인코딩을 했을 때 해당 값이 만들어지지 않습니다. 의미를 부여하고자 하지 않는다면 따로 결측치 처리를 할 필요가 없습니다. 하지만 특이한 값도 고려를 하기 원한다면 예외값이라고 만들어주면 예외값이라는 힌트를 머신러닝 알고리즘에 알려주는 효과가 있습니다.
Q: 피처 중요도를 통해 피처들을 걸러내도 되나요?
A: 그렇게 해도 된다.
✏️ TIL
- 사실(Fact): 어제에 이어서 오늘도 타이타닉 데이터셋 전처리하고 캐글에 제출하는 실습을 했다.
- 느낌(Feeling): 왜 이 코드를 쓰고 어떻게 동작하는지를 알고 실습하는 것과 모르고 하는 것은 정말 다른 것 같다.
- 교훈(Finding): 흐름을 파악하는게 중요하다.
