
✨ 처음부터 차근차근, 내 페이스 대로 ✨
데이터셋 출처: Pima Indians Diabetes Database | Kaggle
EDA
: 정답값인 "Outcome"(당뇨병 발병여부)을 예측하기 위해서 어떤 변수들을 어떻게 사용하면 좋을지 단서를 얻는 과정
- 인슐린 결측치 처리, 시각화 후 이상치 처리 등
One-Hot-Encoding
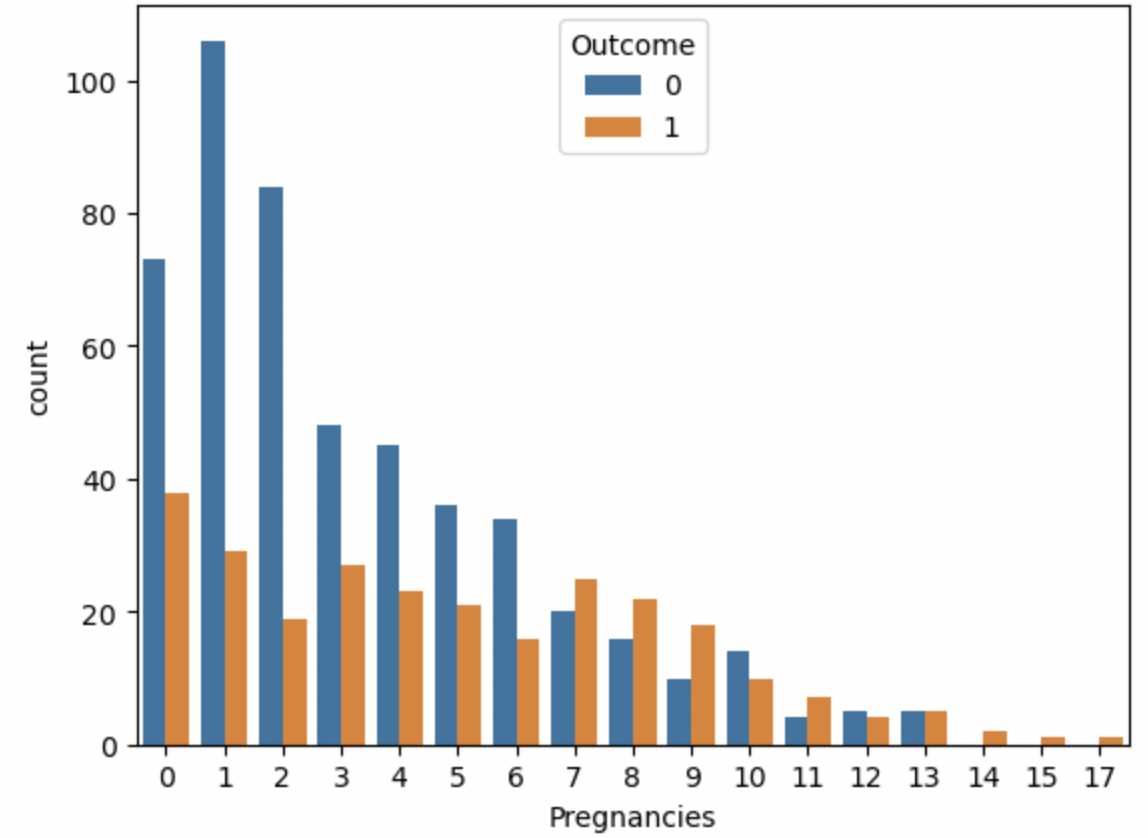
- 임신횟수는 연속된 수치데이터라고 볼 수 있는데, 조건에 따라 가지를 트는 Decision Tree에 해당 모델을 대입하게되면 조건이 많아져 케이스가 적은 건 (임신횟수 11~17)에 대해서는 Overfitting 현상이 발생할 수 있다.
👉🏻 Overfitting을 막기 위해서 특정 임신횟수를 범주화해줌.
👉🏻 위 그래프에서는 임신횟수가 7번 이상인 케이스부터 당뇨병 발병률이 높은 것을 확인 할 수 있다.
# 임신횟수가 7번 이상인 케이스에 대해 파생변수 생성
df["Pregnancies_high"] = df["Pregnancies"] > 6
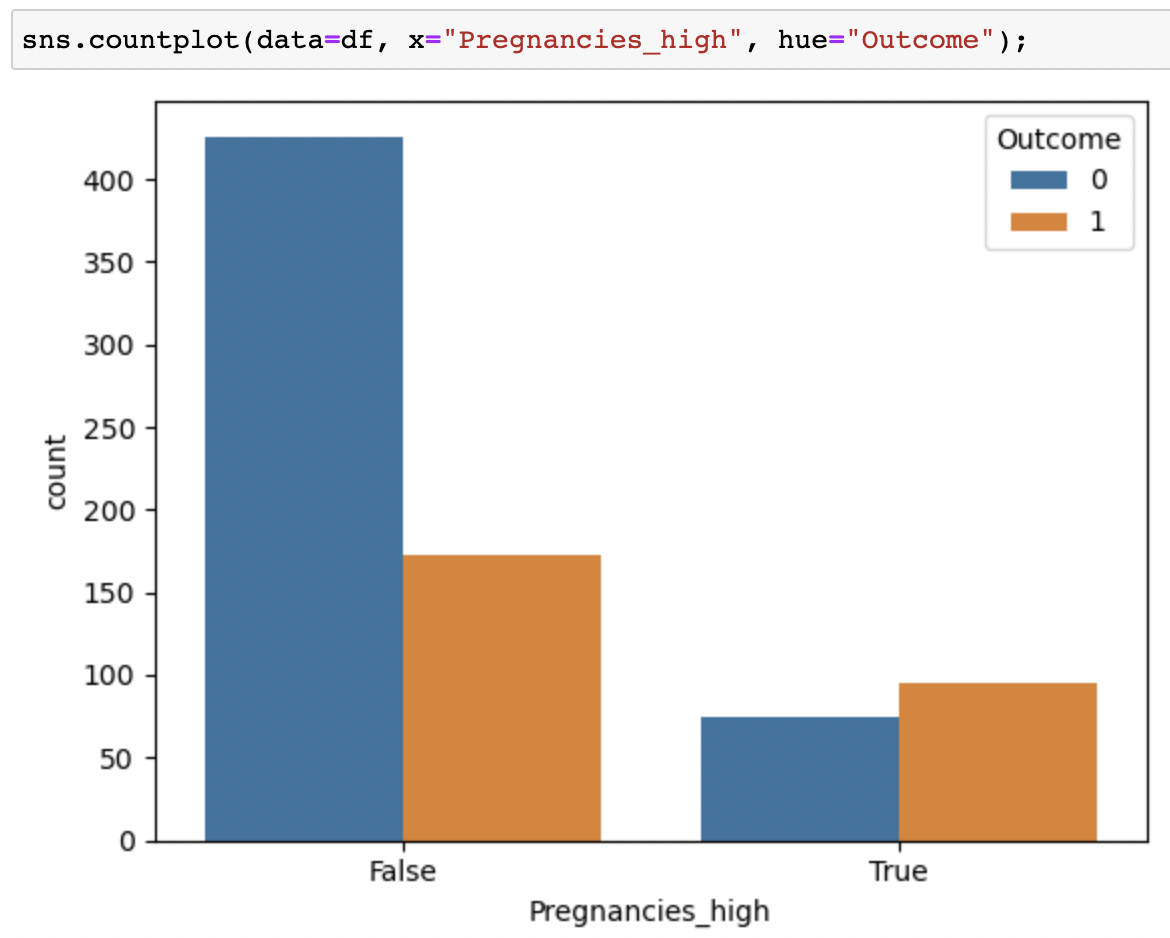
👉🏻 임신횟수가 적은 그룹에서는 발병 횟수가 더 낮고, 임신횟수가 높은 그룹에서는 발병한 횟수가 발병하지 않은 횟수보다 더 높다.
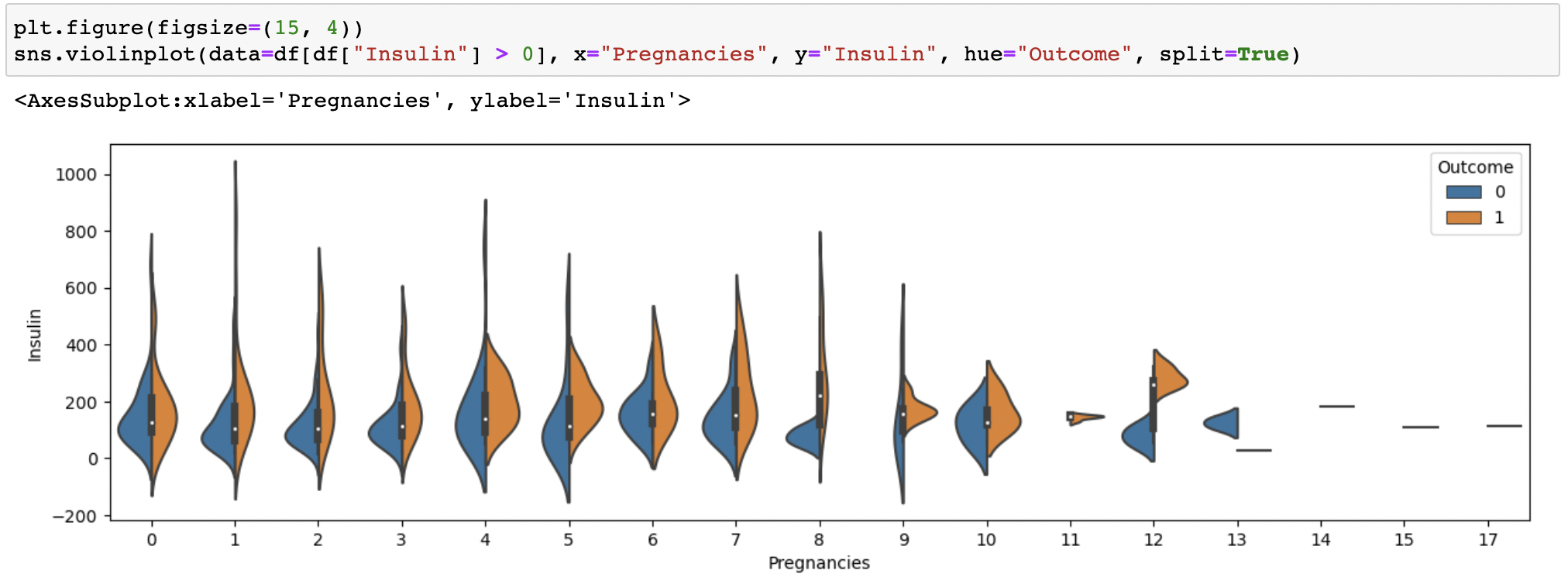
💡 Violin plot에
split=True을 입력하면 그래프를 반으로 쪼개 합쳐서 보여준다.
👉🏻 Box plot의 단점 보완
displot: 1개의 수치형 변수를 표현할 때 사용하는 시각화 그래프
countplot: 카테고리형 데이터를 시각화할 때 사용
distplot: 다른 그래프와 달리 data 옵션 없이 바로 Series 데이터 사용
# 당뇨병 발병여부에 따라 파생변수 생성
df_0 = df[df["Outcome"] == 0]
df_1 = df[df["Outcome"] == 1]
sns.distplot(df_0["Pregnancies"])
sns.distplot(df_1["Pregnancies"])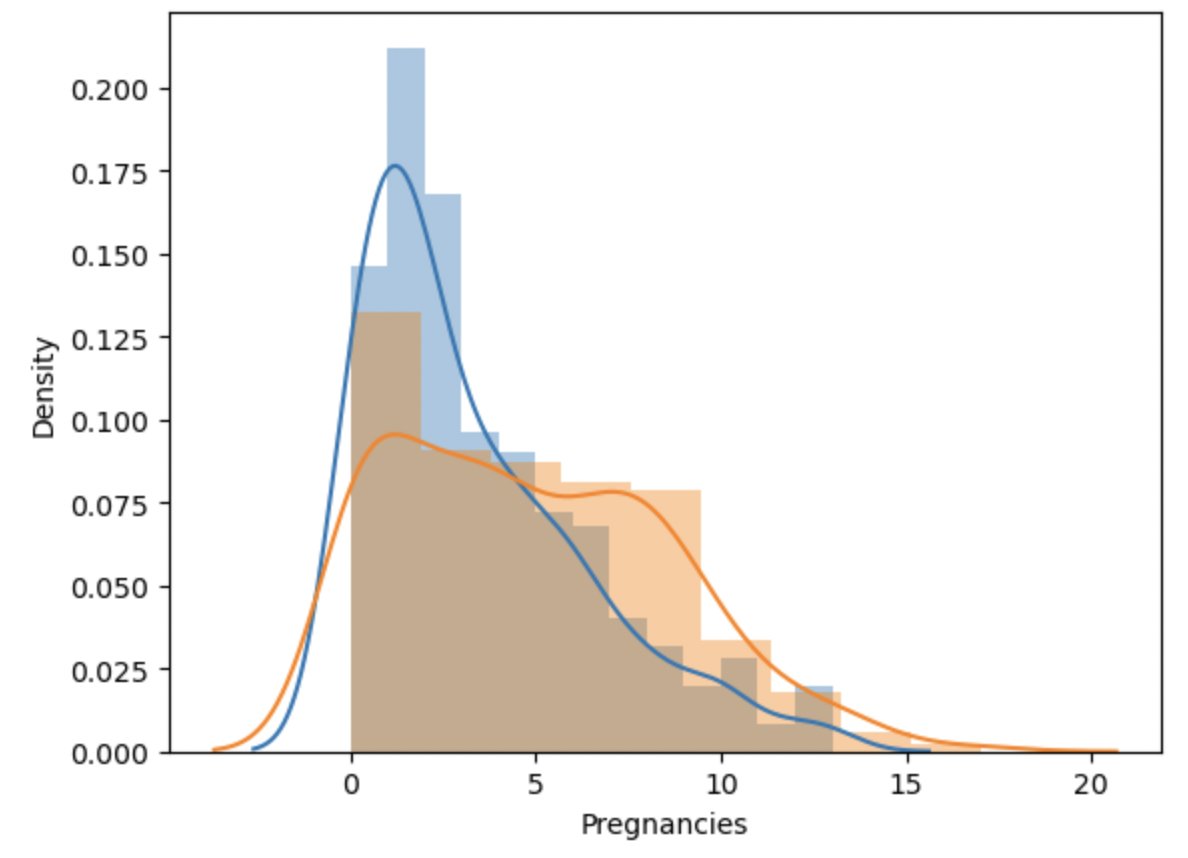
# 반복문을 활용하여 subplots 그리기
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(15, 15))
# enumerate(): index값과 value값을 같이 출력
for i, col_name in enumerate(cols):
row = i // 3
col = i % 3
sns.distplot(df[col_name], ax=axes[row][col])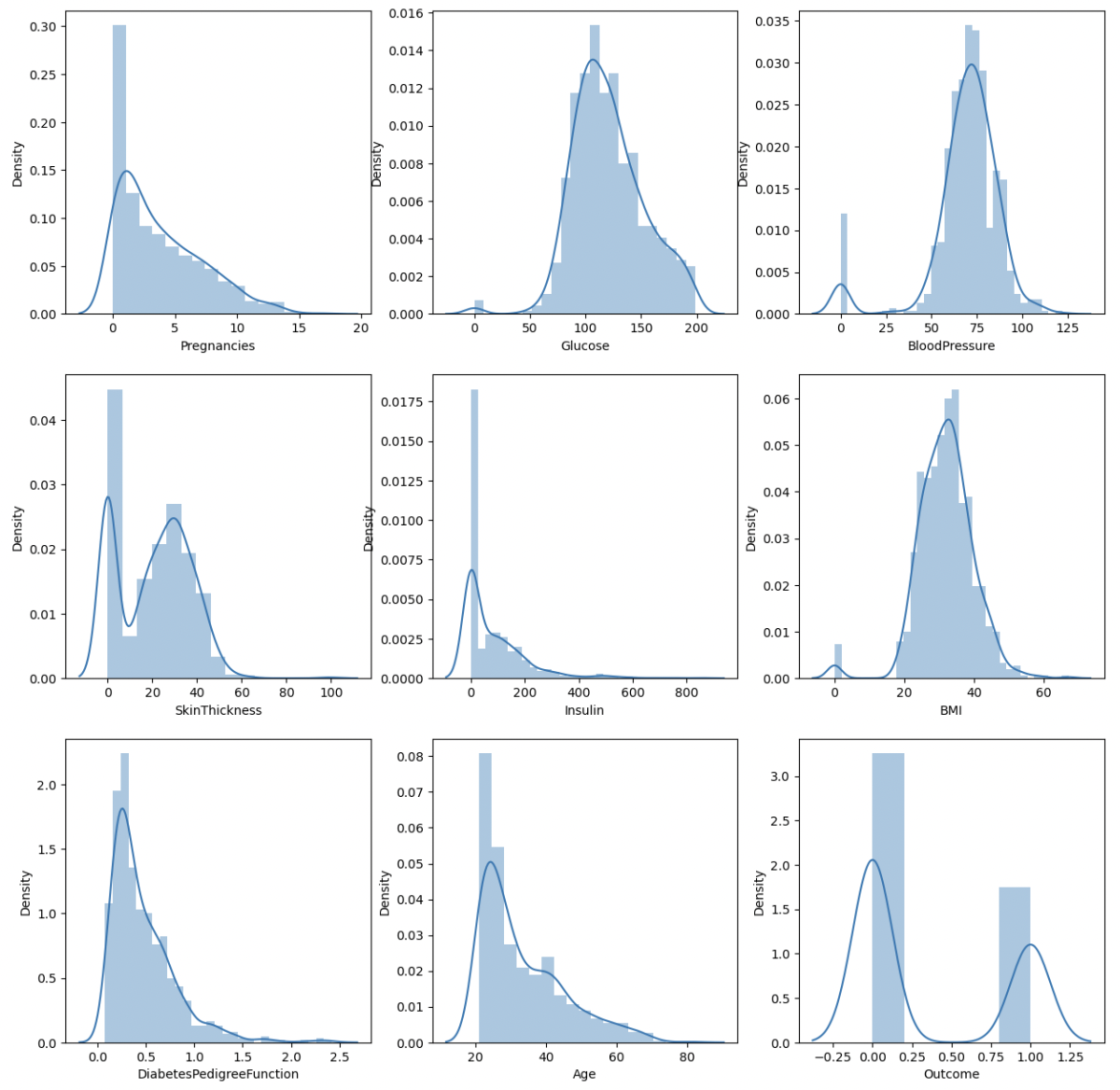
histplot으로 그리면 편하다. 하지만 histplot은 y축에 빈도수 보여주고, distplot은 y축에 value값을 적분한 값을 보여준다는 차이점이 있다.
상관계수 및 상관분석
g = sns.PairGrid(df, hue="Outcome")
g.map(plt.scatter)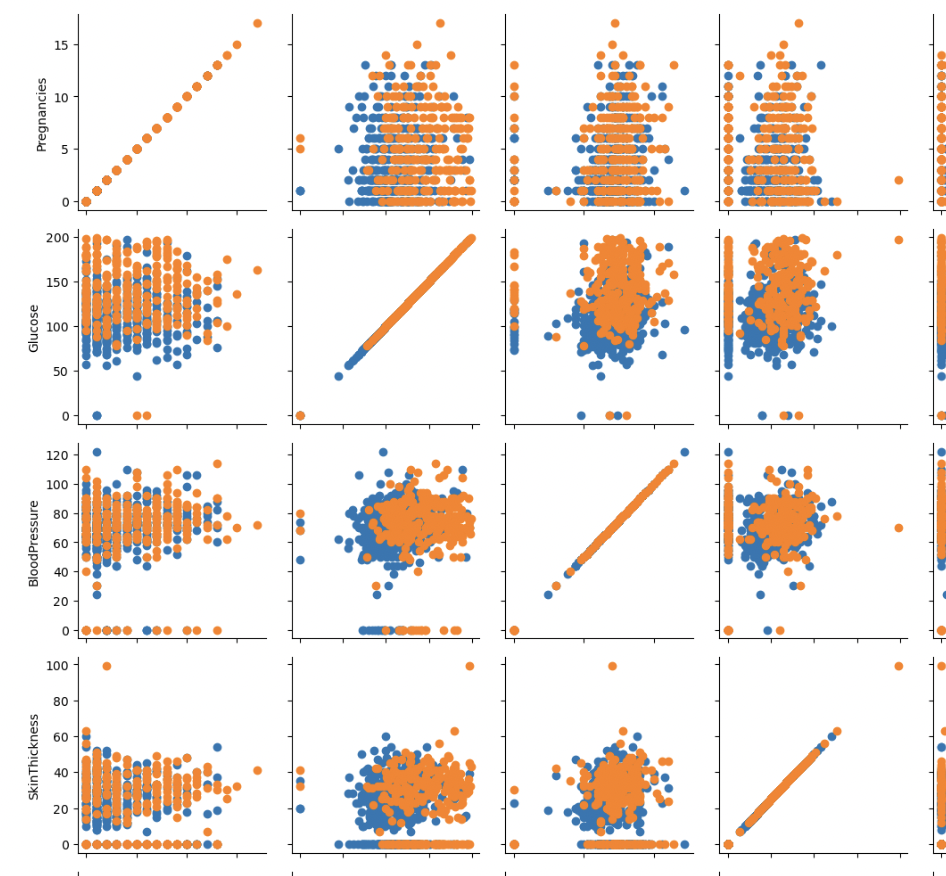
✅ 오늘까지 수강 완료한 섹션:
2. EDA를 통해 데이터 탐색하기

데이터 분석가가 되기 위한 기록 ✏️