
✨ 처음부터 차근차근, 내 페이스 대로 ✨
강의: 부스트코스 - 프로젝트로 배우는 데이터사이언스
데이터셋 출처: Pima Indians Diabetes Database | Kaggle
3. Feature Engineering
🤔 모수가 적은 데이터로 학습을 한것을 일반화해도 될까?
👉🏻 샘플의 수가 적은 데이터로 학습과 예측을 하면 train 데이터셋이 overfitting 되는 현상이 발생한다.
Overfitting: 모의고사는 98점을 받았는데 실전시험에서는 70점을 받은 경우
👉🏻 모의고사에 overfitting 된 경우.
Underfitting: 학습을 적게 해서 모의고사와 실전시험 모두 못 본 경우
연속된 수치형 데이터를 범주형으로 변환시켜 overfitting 방지
3.1 One-Hot-Encoding
: 범주형 데이터를 수치형으로 변환할 때 사용
💡 booltype == one-hot-encoding
- Pregnancies
# 임신횟수가 7번 이상인 케이스에 대해 파생변수 생성
df["Pregnancies_high"] = df["Pregnancies"] > 6💡 전처리를 전혀 하지 않은 initial 데이터를 학습 시켰을 때보다 성능이 더 좋아진 것을 확인.
- Age
특정 연령대를 기준으로 변수 나누기
(변수를 어떻게 나누냐에 따라 성능이 달라질 수 있음)
1. 25세 미만
2. 25세 ~ 60세
3. 60세 이상
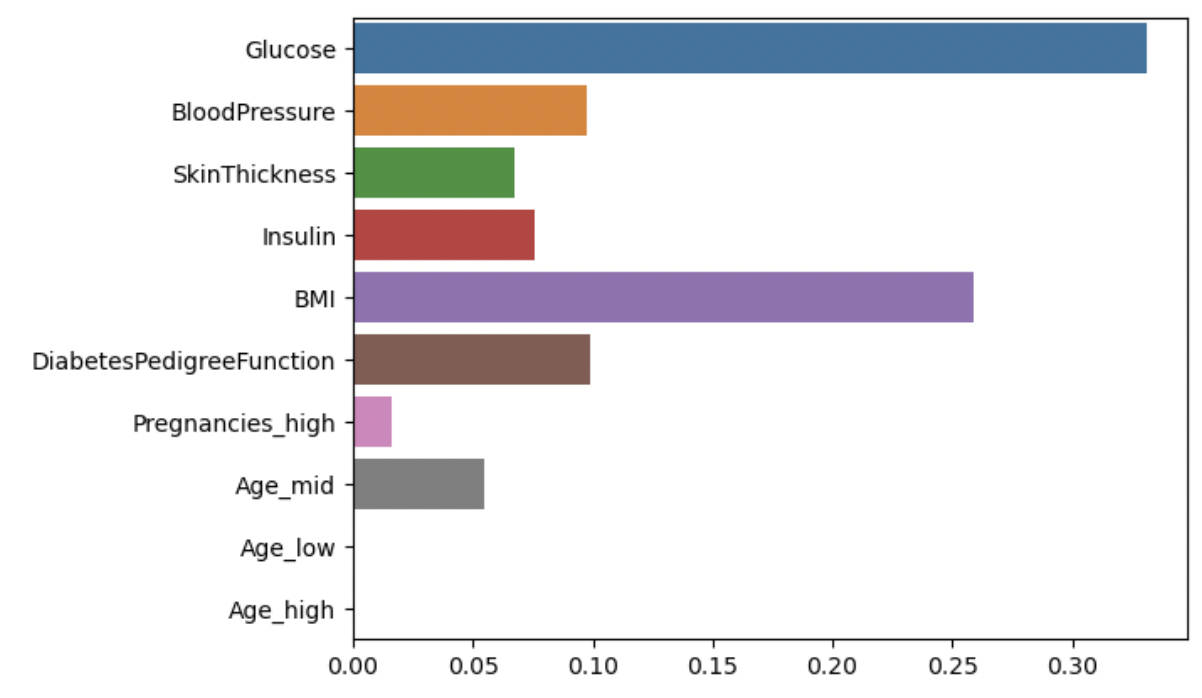
Age_low와 Age_high는 모수 (sample size) 가 적어서 중요도가 낮게 나옴.
👉🏻 Age 파생변수를 포함한 모델을 학습 및 예측한 결과 정확도가 더 낮아진 것을 확인.
💡 전처리를 해줬을 때 확연한 구분이 되지 않으면 정확도가 떨어질 수 있음.
✅ 오늘까지 수강 완료한 섹션:
3.1.2 범주형 변수를 수치형 변수로 변환하기 - 원핫인코딩

데이터 분석가가 되기 위한 기록 ✏️