Web-proxy server 구현하기
- web-proxy server를 직접 개발하며, client와 web-server의 사이에서의 관계이해도와 각각의 처리방식들을 이해하고 구현까지 해볼것이다.
- tiny web server 구현
- 순차적 요청 처리 방식으로 구현하기 (병렬적 요청 처리, 요청 캐시 방식도 여유 되면 구현 해보기)
키워드
-
소켓 (Socket)
더보기-
TCP/IP 의 implementation이 커널 수준에서 되어있음
-
이걸 user mode application이 접근할 수 있도록 인터페이스 제공
-
기본적인 본질은 File 이지만, 이때 프로토콜을 추상화했기 때문에 Socket이라고 한다.
-
Socket 이란??? => TCP라는 요소를 User mode application process가 접근할 수 있도록 추상화환 인터페이스
소켓 인터페이스 (Socket Interface)
The socket interface is a set of functions that are used in conjunction with the Unix I/O functions to build network applications.(소켓 인터페이스는 네트워크 응용을 만들기 위한 Unix I/O 함수들과 함께 사용되는 함수들의 집합이다.)
소켓 주소 구조체Q. 왜 소켓 주소 구조체가 정의되어 있을까?1.소켓 주소는 'IP+포트'이다.
소켓 주소 구조체(socket address structures)란?
2.즉, 목적지에 가려면 IP주소만 있어서는 안 되고 포트 정보도 필요
3.IP 주소도 IPv4는 32비트 주소 체계를 사용, IPv6는 128비트 주소 체계 사용
4.=> 어떤 프로토콜을 사용하느냐에 따라 주소 정보를 나타내는 데이터 타입이 달라짐
5.so, 이를 사용하기 편하게 주소 프로토콜 체계에 따라 사용하기 쉽게 틀을 만든 것1.네트워크 프로그램에서 필요한 주소 정보를 담고 있는 구조체
2.프로토콜 체계에 따라 주소 지정 방식이 다르기 떄문에 다양한 소켓 주소 구조체가 존재한다.1. sockaddr
sockaddr 구조체는 소켓의 주소를 담는 기본 구조체 틀의 역할을 한다.
sockaddr 사용 예시/* Generic socket address structure (for connect, bind, and accept */ struct sockaddr { uint16_t sa_family; // 주소 체계 char sa_data[14]; //해당 주소 체계에서 사용하는 주소 정보(IP정보+포트정보) }그래서 보통 connect(연결 요청)과 같은 함수들이 인자 타입으로 sockaddr을 받는다.
sockaddr_in으로 했던 sockadde_un으로 했던 sockaddr 타입으로 형변환 값이 매개변수로 들어가게 된다.
https://jhnyang.tistory.com/261
빨간색 부분을 보면 선언은 sockaddr_in으로 해줬지만, 인자로 넣을 때는 sockaddr* 타입으로 형변환을 해준다. (서버 프로그램에서 bind 함수에서도 마찬가지) 코드를 유연하게 만들기 위해 모든것을 받아주는 generic 틀이라고 생각하면 쉽다.
결론: sockaddr 구조체는 일반적인(범용적으로 사용 가능한) 구조체이다.
Q. 근데 void 타입을 사용하면 되지 sockaddr*을 사용해야만 하는가? (궁금증해결💡)여러 종류 주소 정보 구조체 포인터를 받기 위해 sockaddr 을 사용해야만 하는가? void 을 쓰면 되는거 아닌가?
=> 함수의 매개변수 데이터 타입을 void 포인터(void)로 선언하는 경우, 어떤 변수의 포인터이든지 인자 값으로 받을 수 있기 때문에 sockaddr을 선언하는 것보다 의미전달이 명확해진다. 역사적인 이유는 그 당시에 void 포인터가 표준으로 존재하지 않았다.
void 보다 sockaddr 를 사용하게 의미전달에 맞고, void* 를 쓰면 정말 아무거나 올 수 있기에 어떤 계열의 타입이 와야하는지 파악하기 쉽지 않고, 또 역참조가 불가능하다는 단점도 있다.
결론: 현재는 주소체계 인자가 필요한 경우 sockaddr*로 형변환을 맞춰서 넣어주게끔 되어 있다.
2. sockaddr_in
sockaddr_in 구조체는 IPv4를 저장하는 구조체이다.
sockaddr_in 사용 예시/* IP socket address structure */ struct sockaddr_in { uint16_t sin_family; // 주소 체계를 저장하는 필드, IPv4를 위한 주소체계이기에 AF_INET 넣어줌 uint16_t sin_port; // 포트 정보 저장 struct in_addr; // IPv4 정보 저장, 타입은 in_addr 구조체 unsigned char sin_zero[8]; // 사용하지 않는 필드, 0으로 채워줘야함 }sockaddr_in 구조체에다가 사용하려는 주소 정보를 할당해보자~
struct sockaddr_in serv_addr; memset(&serv_addr, 0, sizeof(serv_addr)); serv_addr.sin_family = AF_INET; // sockaddr_in이니깐 AF_INET을 할당해줌 serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); serv_addr.sin_port = htons(3030); // htos: host 바이트 순서 => 네트워크 바이트 순서1.inet_addr: 문자열 + 점으로 이루어진 IP 주소를 32bit 주소체계로 변환해줄뿐만 아니라 네트워크 바이트 순서에 맞게끔 변환도 해줌
2.htons: host 바이트 순서에서 네트워크 바이트 순서로 변환해주는 함수 (host to network, short형)참고 자료: https://jhnyang.tistory.com/261
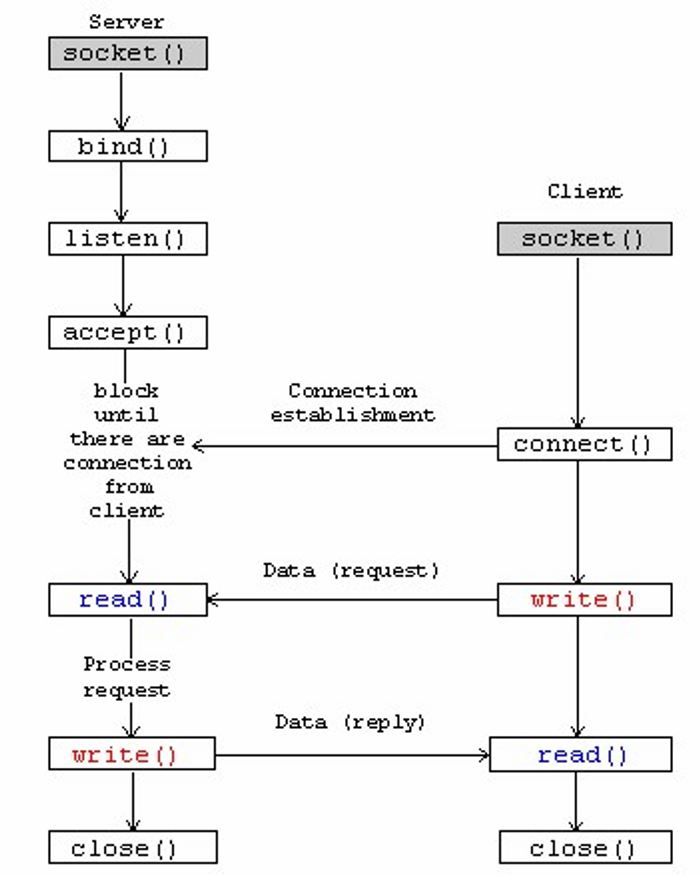
accept 함수서버는 accept 함수를 호출해서 클라이언트로부터의 연결 요청을 기다린다.
#include <sys/socket.h> int accept(int listenfd, struct sockaddr *addr, int *addrlen); // Return: nonnegative connected descriptor if OK, -1 on error1.클라이언트로부터 연결 요청이 듣기 식별자 listenfd에 도달하기를 기다리고, 그 후에 addr 내의 클라이언트의 소켓 주소를 채우고, Unix I/O 함수들을 사용해서 클라이언트와 통신하기 위해 사용될수 있는 연결 식별자 connfd 를 리턴한다.
2.듣기 식별자 listenfd
- 클라이언트 연결 요청에 대해 끝점으로서의 역할을 함
- 대개 한 번만 생성, 서버가 살아있는 동안 계속 존재3.연결 식별자 connfd
- 클라이언트와 서버 사이에 성립된 연결의 끝점
- 서버가 연결 요청을 수락할 때마다 생성되며, 서버가 클라이언트에 서비스하는 동안에만 존재함[듣기 식별자와 연결 식별자의 역할]
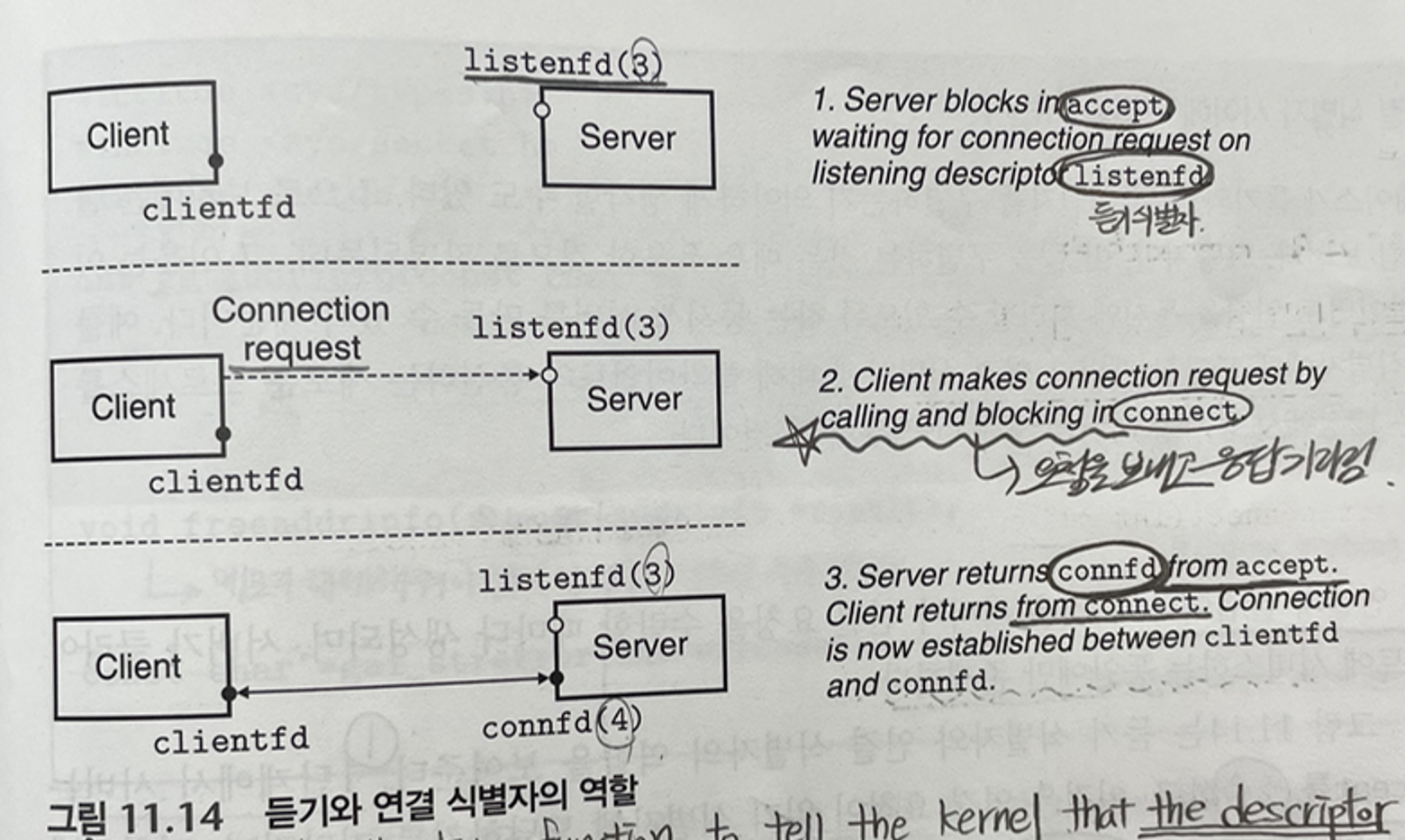
1.서버 accept 호출, 연결 요청이 listenfd에 도달하길 기다림
호스트와 서비스 변환
2.클라이언트 connect 호출 즉, listenfd로 연결 요청 보냄
3.accept 함수는 새로운 연결 식별자 connfd를 오픈하고, clientfd와 connfd 사이의 연결을 수립하고 connfd를 리턴한다.getaddrinfo 함수 => 도메인에서 IP 주소로 변환하는 기능getnameinfo 함수 => IP주소에서 도메인으로 변환하는 기능#include <sys/socket.h> #include <netdb.h> int getnameinfo(const struct sockaddr *sa, socklent_t salen, char *host, size_t hostlen, char *service, size_t servlen, int flags); // Returns: 0 if OK, nonzero error code on error
-
-
클라이언트-서버 프로그래밍 모델 (Client-Server Programming Model)
더보기호스트(Host)란?IT에서는 네트워크에 연결되어 있는 컴퓨터들을 호스트(Host)라고 부른다.
인터넷은 TCP/IP 프로토콜을 이용하여 통신을 하는데, 통신을 하려고 해도 목적지와 출발지가 없으면 어디로 데이터를 보낼지 받을지 모른다. IP라는 고유한 주소를 통해 목적지와 출발지를 구할 수 있으며 호스트는 IP 주소를 갖는다.
호스트 = IP를 가지고 있는 양방향 통신이 가능한 컴퓨터
URL VS URIURI: 자원의 위치 URL: 자원의 식별자 통상적으로 URL이라고 얘기하지만 정확하게는 URI라고 하는 것이 맞다. 조금 억지스러운 예를 들면, 아래의 두 주소는 같은 URL이고 다른 URI라고 할 수 있다. -
에코 서버 (Echo Server)
더보기에코 서버란, 클라이언트가 전송해주는 데이터를 그대로 되돌려 전송해 주는 기능을 가진 서버를 말한다. 에코 서버 클라이언트 모델의 특징은 몇 바이트를 송수신할 것인지 예상할 수 있다는 것이 큰 특징이다. 그 이유는 전송한만큼 바이트를 되돌려 받기 때문이다.

- 웹 서버 (Web Server)
더보기
웹 기초
-
HTTP(HyperText Transfer Protocal)
- HTTP는 원래 하이퍼 텍스트를 전송하는 통신 규약
- 요즘에는 HTML, 텍스트, 이미지, 음성, 영상, 파일, JSON, XML 모든 것을 HTTP 메시지로 전송함
- 과정
- 웹 클라이언트(브라우저)는 서버로의 인터넷 연결을 오픈, 컨텐츠를 요청
- 서버는 요청한 컨텐츠로 응답, 그 후에 연결 닫아줌
- 브라우저는 컨텐츠를 읽고 스크린에 보여줌
-
HTML(HyperText Markup Language)
웹 컨텐츠
HTML은 태그(명령!)을 포함하고 있어서 브라우저에게 여러가지 텍스트와 그래픽 객체를 페이지에 어떻게 표시할지를 알려줌
HTML의 진정한 강점은 페이지가 인터넷 호스트에 저장된 컨텐츠로의 포인터(하이퍼링크)를 포함할 수 있다는 것이다.
-
웹 클라이언트(브라우저)와 서버에게, 컨텐츠는 연관된 MIME(Multipurpose Internet Extensions) 타입을 갖는 바이트 배열이다.
MIME type Description text/html HTML page text/plain Unformatted text application/postscript Postscript document image/gif Binary image encoded in GIF format image/png Binary image encoded in PNG format image/jpeg Binary image encoded in JPEG format -
웹 서버는 두 가지 방법으로 클라이언트에게 컨텐츠를 제공
- 정적 컨텐츠
- 누가 언제 서버에 요청하더라도 동일하게 내용을 보여주는 것
- HTML, CSS, JS로 이미 만들어진 결과물을 사용자에게 보여주는 콘텐츠
디스크 파일을 가져와서 그 내용들 클라이언트에게 보낸다. 디스크 파일은 정적 컨텐츠라고 하며, 파일을 클라이언트에게 돌려주는 작업은 정적 컨텐츠(static content)를 처리한다고 말한다.
- 동적 컨텐츠
- 누가 언제 어떻게 서버에 요청했는지에 따라 각각 다른 내용이 보여지는 콘텐츠
- 사용자 맞춤형으로 제공
실행파일을 돌리고, 그 출력을 클라이언트에게 보낸다. 실행파일이 런타임에 만든 출력을 동적 컨텐츠(dynamic content)라고 하며, 프로그램을 실행하고 그 결과를 클라이언트에게 보내주는 과정을 동적 컨텐츠를 처리한다고 말한다.
-
웹 서버가 리턴하는 모든 내용들을 서버가 관리하는 파일에 연관됨.
-
이 파일 각각은 URI(universal Resource Locator)라고 하는 고유의 이름을 가
URI 설명 💡💡💡💡정적컨텐츠와 동적컨텐츠 구분 -
http://www.google.com:80/index.html
- 웹 서버 HTTP 포트번호 80
- 위와 같은 URI에서 port 80에서 듣고 있는 웹 서버가 관리하는 인터넷 호스트 www.google.com의 /index.html이라는 HTML 파일을 지정한다.
-
http://jungle.com:8000/cgi-bin/adder?7&3
- 실행파일을 위한 URI은 파일 이름 뒤에 프로그램 인자를 포함
- '?': 파일 이름과 인자를 구분
- '&': 각 인자 구분
- 위의 URI는 /cgi-bin/adder라는 실행파일을 식별하고, 파일은 7과 3의 인자와 함께 호출됨
=> http://www.google.com:80/index.html- 클라이언트 (http://www.google.com:80)
- 어떤 종류의 서버에 접속해야하는지 결정
- 어디에 서버가 있는지 결정
- 서버가 무슨 포트를 듣고 있는지 결정
- 서버 (/index.html)
- 자신의 파일 시스템 상의 파일 검색
- 이 요청이 정적 컨텐츠인지 동적 컨텐츠인지 결정 (계속 위에서 얘기했던 정적 컨텐츠와 동적 컴텐츠 중 어떤 것을 클라이언트에 줄 것인지)
- URI이 정적 또는 동적 컨텐츠를 참조하는지 결정하기 위한 표준 규칙 X
- 고전적 방법 => cgi-bin 같은 디렉토리 집합을 지정하는 것이며, 여기에 모든 실행파일들이 들어있어야 함(우리의 tiny server는 이 규칙을 적용할 것이다.)
- '/' => 리눅스의 루트 디렉토리 x, 어떤 종류의 컨텐츠가 요청되든 간에 홈 디렉토리
- 최소한의 URI => '/'
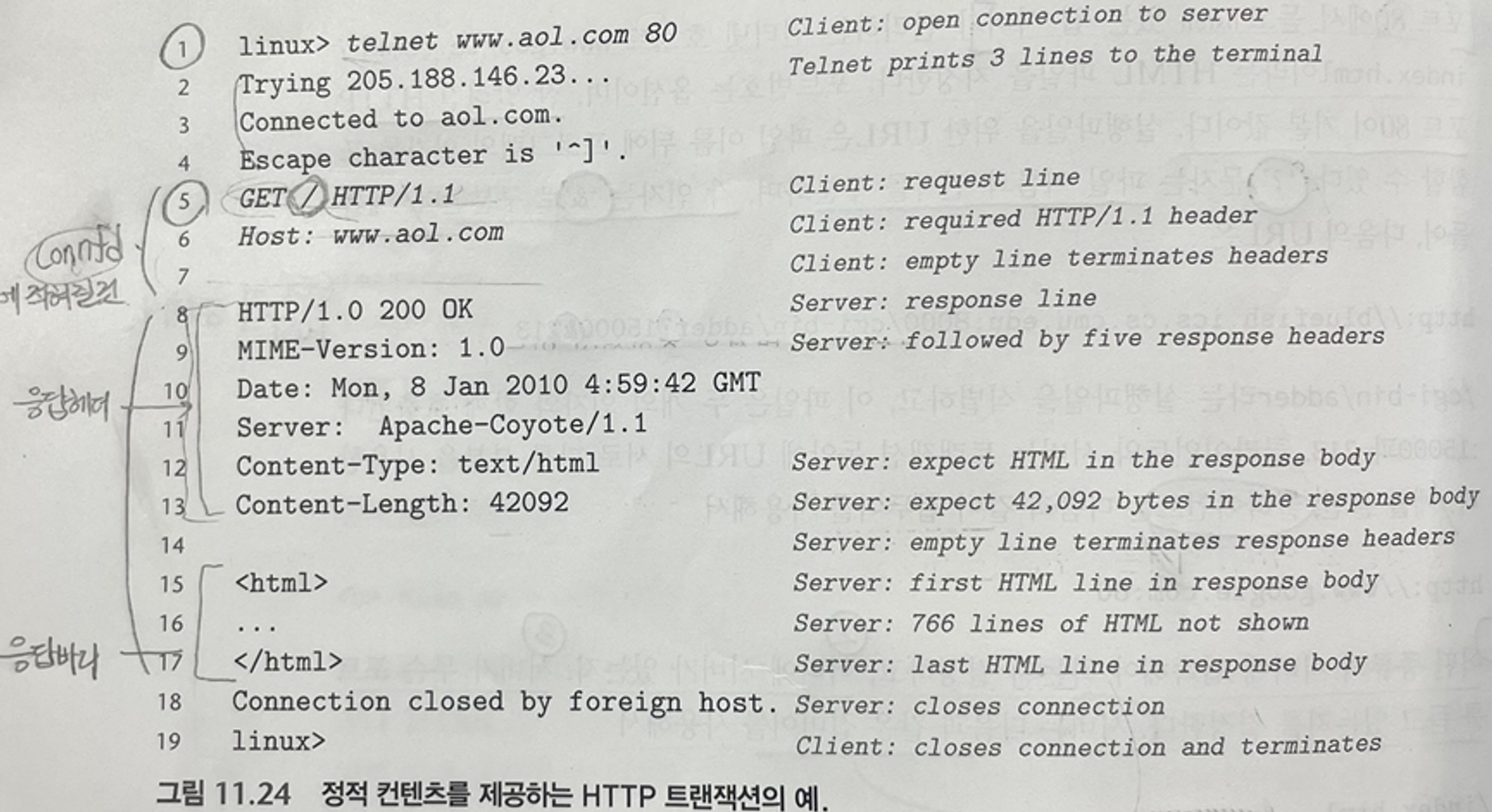
리눅스 TELNET 프로그램을 사용해서 인터넷 상의 모든 웹 서버와 트랜잭션을 실행 가능.
TELNET(텔넷)이란?- 원격지의 호스트 컴퓨터에 접속하기 위해 사용되는 인터넷 프로토콜
- 텔넷을 이용하면 네트워크에 있는 컴퓨터를 자신의 컴퓨터처럼 파일 전송, 파일 생성, 디렉토리 생성 등 자유롭게 할 수 있다.
- 단, 보안문제로 사용률이 감소하고 원격 제어를 위해 SSH로 대체되는 추세
- 텔넷은 정보를 byte 스트림 형식으로 주고 받고, SSH는 DES, RSA 등 고급 암호화를 통해 통신한다.
-
telnet을 리눅스 쉘에서 실행, aol 웹 서버와 연결 오픈 요청 ~
-
telnet은 터미널에 세 개의 출력 인쇄 & 연결 오픈, HTTP 요청 기다림
-
HTTP 요청 => GET / HTTP/1.1 우리가 HTTP 요청을 입력하고 enter 키를 누를 때마다 telnet은 이 줄을 읽고, carriage return(\r)과 line feed(\n), 이 라인을 서버로 보냄 => "\r\n"
-
HTTP 표준은 매 텍스트 라인이 "\r\n"으로 종료될 것을 요구함
[과정]
HTTP 요청
1) 트랙잭션을 개시 위해 HTTP 요청을 입력함(5~7번줄)
=> 요청 라인(5), 요청 헤더(6)
2) 서버는 HTTP 응답으로 회신하며(8~17줄)
=> 응답 라인(8), 요청 헤더(9~13), 응답 바디(15~17)
3) 연결을 닫는다.(18번줄)HTTP 요청 => 요청 라인(5번 줄), 여러개의 요청 헤더(6번 줄), 헤더리스트를 종료하는 빈 텍스트줄(7번 줄)
요청 라인요청라인은 다음과 같은 형태를 갖는다.
method URI version
-
method
- HTTP 많은 메소드 지원 => GET, POST, HEAD, PUT 등
- 우리는 여기서 GET method만 논의
-
URI
- GET method는 URI(Uniform Resource Identifier)에 의해 식별되는 내용을 리턴할 것을 지시함
- URI는 파일 이름과 옵션 인자들을 포함하는 URI의 접미어
-
version
요청 헤더
요청 라인의 version 필드 => 요청이 준수하는 HTTP 버전을 나타냄
HTTP/1.1
1. 커넥션 유지
2. 호스트 헤더
3. 강력한 인증 절차
요약: 5번 줄의 HTTP 요청 라인은 서버에게 HTML 파일 index.html을 가져와서 리턴할 것을 요구한다. 또한, 서버에게 나머지 요청들이 HTTP/1.1 포맷으로 되어있을 것이라고 알려준다.요청 헤더는 다음과 같은 형태를 갖는다.
요청 헤더는 서버에 브라우저의 이름이나 브라우저가 이해하는 MIME 타입 같은 추가적인 정보를 제공한다.
Header-name: header-data
우리의 목적을 위해서 신경을 쓰는 유일한 헤더는 Host 헤더(6번줄)로, 이것은 HTTP/1.1 요청에서 요구되었으며, HTTP/1.0 요청에서는 아니다. Host 헤더는 프록시 캐시에 의해 사용되며, 브라우저와 요청된 파일을 관리하는 본래의 서버 사이의 중간자 역할을 한다.
5번 줄의 요청 라인, 6번 줄의 요청 헤더 이후, 키보드의 엔터 키를 눌러서 만든 헤더를 종료하고, 서버에게 요청한 HTML 파일을 보낼 것을 명령한다.
HTTP 응답HTTP 응답은 HTTP 요청과 비슷하다.
HTTP 응답 => 응답 라인(8번 줄),응답 헤더들(9~13번 줄), 헤더를 종료하는 빈 줄(14번줄), 응답 본체(15~17번 줄)
응답 라인version status-code status-message
- version
- 버전 필드 => 응답이 준수해야 할 HTTP 버전
- status-code
- 상태 코드 => 3비트 양수로, 요청의 특성을 나타냄
- status-message
- 상태 메시지 => 에러 코드를 영어로 나타낸 것
9~13번줄 => 응답에 대한 추가적인 정보 제공, 두 개의 가장 중요한 헤더는 !
- Content-Type: 클라이언트에게 응답 본체 내의 컨텐츠의 MIME 타입을 알려줌. (12번 줄)
- Content-Length: 그 크기를 바이트로 나타냄. (13번 줄)
14번 줄의 응답 헤더를 종료하는 비어 있는 텍스트 라인은 응답 본체가 따라옴. => 요청한 컨텐츠를 포함하고 있음.
Q. 어떻게 클라이언트는 프로그램 인자들을 서버에 전달하는가?
Q. 어떻게 클라이언트는 프로그램 인자들을 서버에 전달하는가?
Q. 어떻게 서버가 자식에게 다른 정보를 전달하는가?
Q. 자식은 자신의 출력을 어디로 보내는가?
=> 이러한 질문들은 CGI(Common Gateway Interface)라고 부르는 사실상의 표준으로 설명할 수 있다.- GET 요청을 위한 인자들은 URI에서 전달된다.
- '?' => 파일이름과 인자를 구분
- '&' => 각 인자들을 구분
- 빈칸 허용 X => "%20" 스트링으로 표시해야함.
서버가 다음과 같은 HTTP 요청을 받은 후에
GET /cgi-bin/adder?15000&213 HTTP/1.1
fork을 호출해서 자식 프로세스를 생성하고,
Q. 자식은 자신의 출력을 어디로 보내는가?
execve를 호출해서 /cgi-bin/adder 프로그램을 자식의 컨텍스트에서 실행한다.
execve를 호출하기 전에 자식 프로세스는 CGI 환경변수 QUERY_STRING을 "15000&213"으로 설정하고, adder 프로그램은 런 타임에 리눅스 getenv 함수를 사용해서 이 값을 참조가능하다.CGI 프로그램은 자신의 동적 컨텐츠를 표준 출력으로 보낸다.
자식 프로세스가 CGI 프로그램을 로드하고 실행하기 전에 리눅스 dup2 함수를 사용해서 표준 출력을 클라이언트와 연계된 연결 식별자로 재지정한다. 이를 통해서 CGI 프로그램이 표준 출력으로 쓰는 모든 것은 클라이언트로 직접 가게 된다.
부모가 자식이 생성한 컨텐츠의 종류와 크기를 알지 못 하기 때문에 자식은 Content-type과 Content-length 응답 헤더와 헤더를 종료하는 빈줄까지 생성할 책임이 있다.
-
Tiny Web Server
더보기-
RIO: Robust I/O
=> RIO 패키지는 짧은 카운트가 발생할 수 있는 네트워크 프로그램 같은 응용에서 편리하고, 안정적이고 효율적인 I/O를 제공한다.- void rio_readinitb(rio_t *rp, int fd)
- 식별자 fd를 주소 rp에 위치한 rio_t 타입의 읽기 버퍼와 연결한다.
- 읽기 버퍼의 포맷을 초기화하는 함수 rio_readinitb 함수는 한 개의 빈 버퍼를 설정하고, 이 버퍼와 한 개의 오픈한 파일 식별자를 연결한다.
- ssize_t rio_readlineb(rio_t rp, void usrbuf, size_t maxlen)
- 다음 텍스트 줄을 파일 rp(종료 새 줄 문자를 포함해서)에서 읽고, 이걸을 메모리 위치 usrbuf로 복사하고, 텍스트 라인을 널(0) 문자로 종료시킨다.
- ssize_t rio_readnb(rio_t rp, void usrbuf, size_t n)
- 최대 n바이트 를 파일 rp로부터 메모리 위치 usrbuf로 읽는다.
- int sscanf(const char buffer, const char format,...)
- 버퍼에서 포멧을 지정하며 읽어오는 함수
- strstr()
- string1에서 string2의 첫 번째 표시 시작 위치에 대한 포인터를 리턴
- string2가 string1에 나타나지 않으면 strstr()함수는 NULL을 리턴
- strcpy()
- 끝나는 널 문자를 포함하여 string2를 string1에서 지정한 위치로 복사
- index()
- 문자열 중 특정 문자의 위치를 찾아주는 함수
- 첫번째 인자 => 검색 대상 문자열, 두번째 인자 => 검사할 문자
- 반환: 문자를 찾았으면 문자가 있는 위치를, 찾는 문자가 없다면 NULL을 반환
- strcat(uri_ptos,'/')
- => 을 했을경우 uri_ptos는 초기화되지 않았기에 '/'을 붙여버리면 쓰레기값 + / 이되니깐 strcpy(uri_ptos,"/")을 사용한다.
- strstr: 문자열의 처음 찾아지는 곳의 첫 번째 주소 반환
- void rio_readinitb(rio_t *rp, int fd)
-
rio_readinitb: read 버퍼를 초기화하는 함수
-
rio_readlineb: 파일에서 텍스트 라인을 읽어 버퍼에 담는 함수
-
rio_readnb: 파일에서 지정한 바이트 크기를 버퍼에 담는다.
-
rio_writen: 버퍼에서 파일로 지정한 바이트를 전송하는 함수
-
main: 웹 서버 메인 로직
- open_listenfd:
- doit: 한 개의 HTTP 트랜잭션을 처리하는 함수
- client_error: 에러 처리를 위한 함수
- read_requesthdrs: request header를 읽는 함수
- parse_uri: 클라이언트가 요청한 URI를 파싱하는 함수
- serve_static: 정적 콘텐츠를 제공하는 함수
- serve_dynamic: 동적 콘텐츠를 제공하는 함수
- get_filetype: 받아야하는 filetype을 명시하는 함수
-
-
프록시 서버 (Proxy Server)
더보기1. Proxy 서버란?
프록시 서버란, proxy 란 대리 혹은 중계 Agent로서의 의미이며, 프록시 서버는 클라이언트의 요청을 받아 중계하는 서버이다.
클라이언트 <-> Proxy 서버 <-> 웹 서버
즉, 클라이언트가 요청을 보냈을 때 proxy 서버에서 웹 서버에 접근하여 요청과 응답을 처리한 후 proxy서버에서 다시 클라이언트에게 응답을 한다.
2. Proxy 서버 특징
-
익명성으로 보안의 목적으로 사용
-
캐시를 이용한 요청 속도 개선
-
차단된 사이트를 우회하여 접속
-
원하지 않는 사이트를 차단
3. Proxy 서버 캐시 활용
웹 캐시(web cache) 또는 HTTP 캐시(HTTP cache)는 서버 지연을 줄이기 위해 웹 페이지, 이미지, 기타 유형의 웹 멀티미디어 등의 웹 문서들을 임시 저장한 후
동일한 요청 시 프록시 서버의 웹 캐시에 저장된 정보를 불러오므로 트래픽이나 서버의 부하를 줄여 클라이언트가 원하는 정보를 빠르게 응답할 수 있다.
4. Proxy 서버 종류
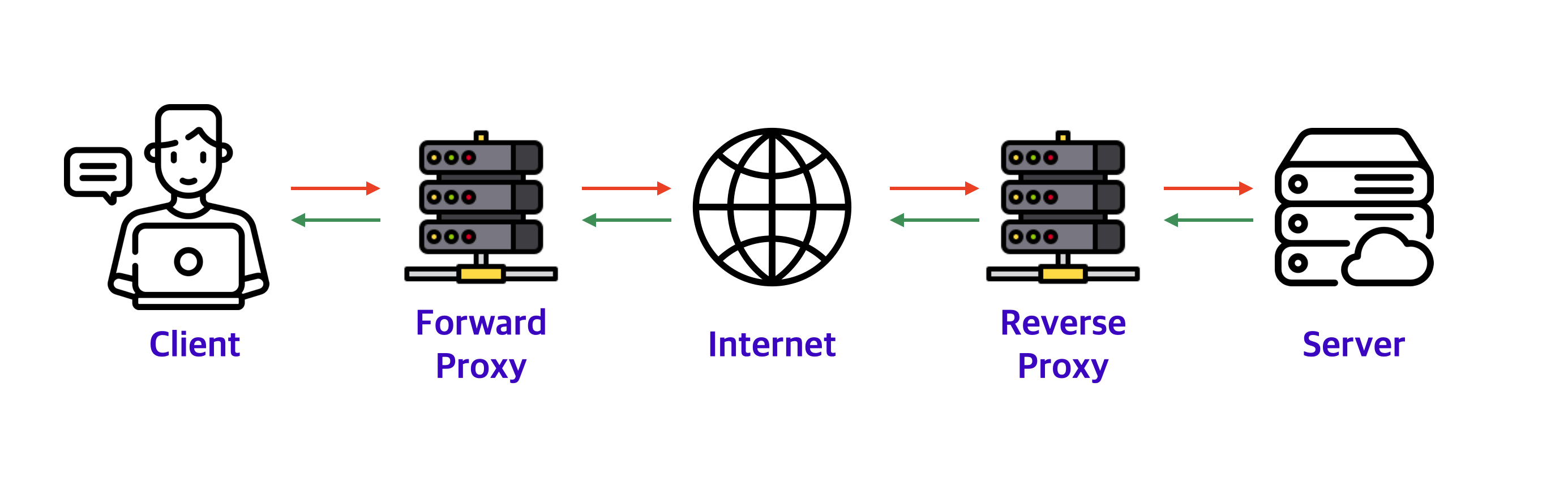
프록시 서버가 서비스 서버에 작업하는 위치와 네트워크 구성에 따라서 크게 Forward Proxy/Reverse Proxy 로 구분된다.
Forward Proxy (포워드 프록시)
일반적인 프록시 서버를 말하며, 클라이언트와 웹 서버의 중계역할로 클라이언트가 요청 시 Proxy서버는 해당 요청을 웹 서버로 중계해 자원을 가져오는 개념이다.
프록시 서버는 클라이언트가 요청하기 전까지 웹 서버의 주소를 알 수 없다.
Reverse Proxy (리버스 프록시)
클라이언트와 내부망(Private Network) 서버 사이에(앞에) 위치하여 제어 역할을 한다. 그래서 클라이언트가 요청을 하면 프록시 서버가 내부망 서버에 요청 후 응답 받은 자원을 클라이언트에게 전달해주는 개념이다.
리버스 프록시 서버는 실제 서버들에 대한 주소를 매핑하고 있어야 한다. 그리고 내부망에 서버에 대해 보안적으로나 로드밸런싱을 위해 사용되기도 한다.
5. proxy server 사용하는 이유
-
익명으로 컴퓨터를 유지할 수 있다. 프록시 서버를 통해 한 단계의 보안을 더 할 수 있기 때문에 컴퓨터 보안을 유지할 수 있다.
-
프록시 서버에 요청된 내용들을 캐시를 이용하여 저장하면 전송시간도 절약할 수 있음은 물론 동시에 불필요하게 외부와의 연결을 하지 않아도 된다는 장점을 가지게 된다.
-
네트워크 서비스나 콘텐츠로의 접근 정책을 적용하기 위해 사용한다. 또한 사용률을 기록하고 검사하기 위해 사용할 수 있다.
-
보안 및 통제를 뚫고 나가기 위해 사용할 수 있다. 또한 역으로 IP 추적을 당하지 않을 목적으로 사용한다. 역기능이긴 하지만 우회를 할 수 있도록 한다.
-
밖으로 나가는 콘텐츠를 검사하기 위해 사용한다. 중계 서버인 프록시 서버를 거치기 때문에 콘텐츠를 검사할 수 있다. 지역 제한을 우회하기 위해 사용할 수 있다.
Proxy 구현
테스팅과 디버깅
driver.sh
1.proxy 터미널 => make 후 ./driver.sh 실행
2.자동채점(autograde)이 되면서 proxy 점수 파악 가능
3.기본 기능이 문제 없이 동작: 40점 (자동채점)
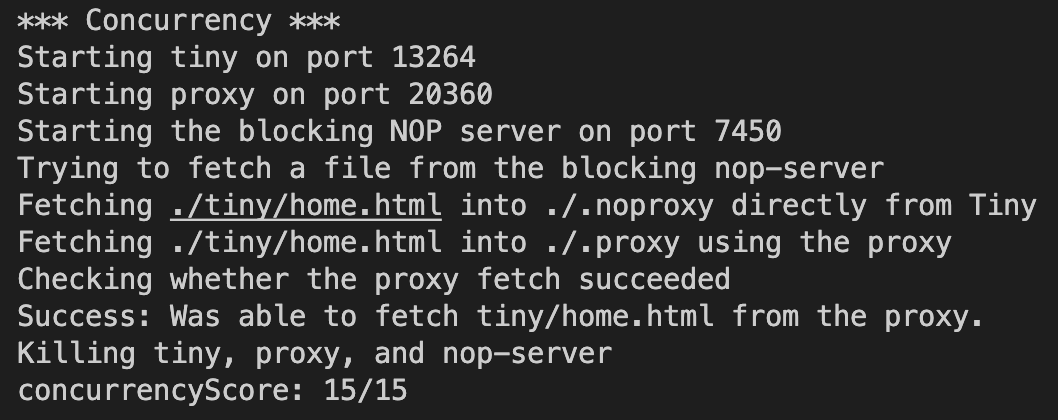
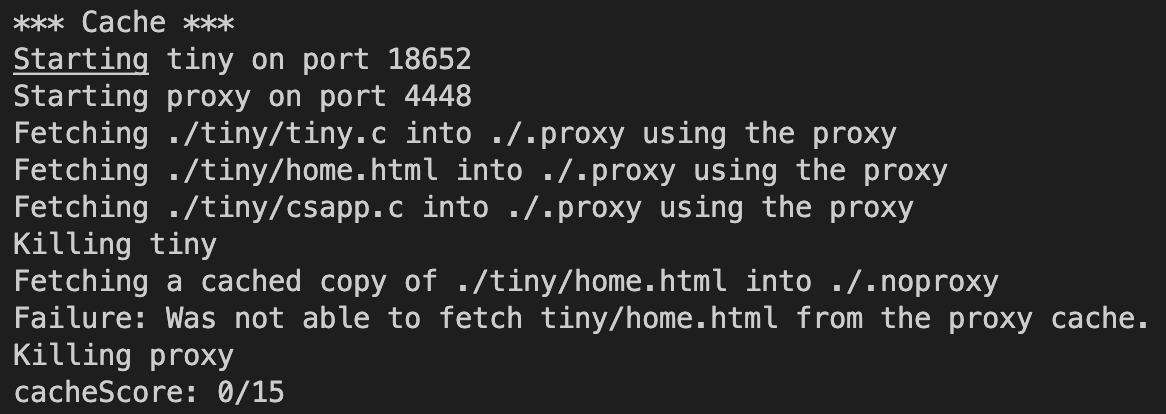
4.동시성 : 15점 (자동채점)
5.캐시 : 15점 (자동채점)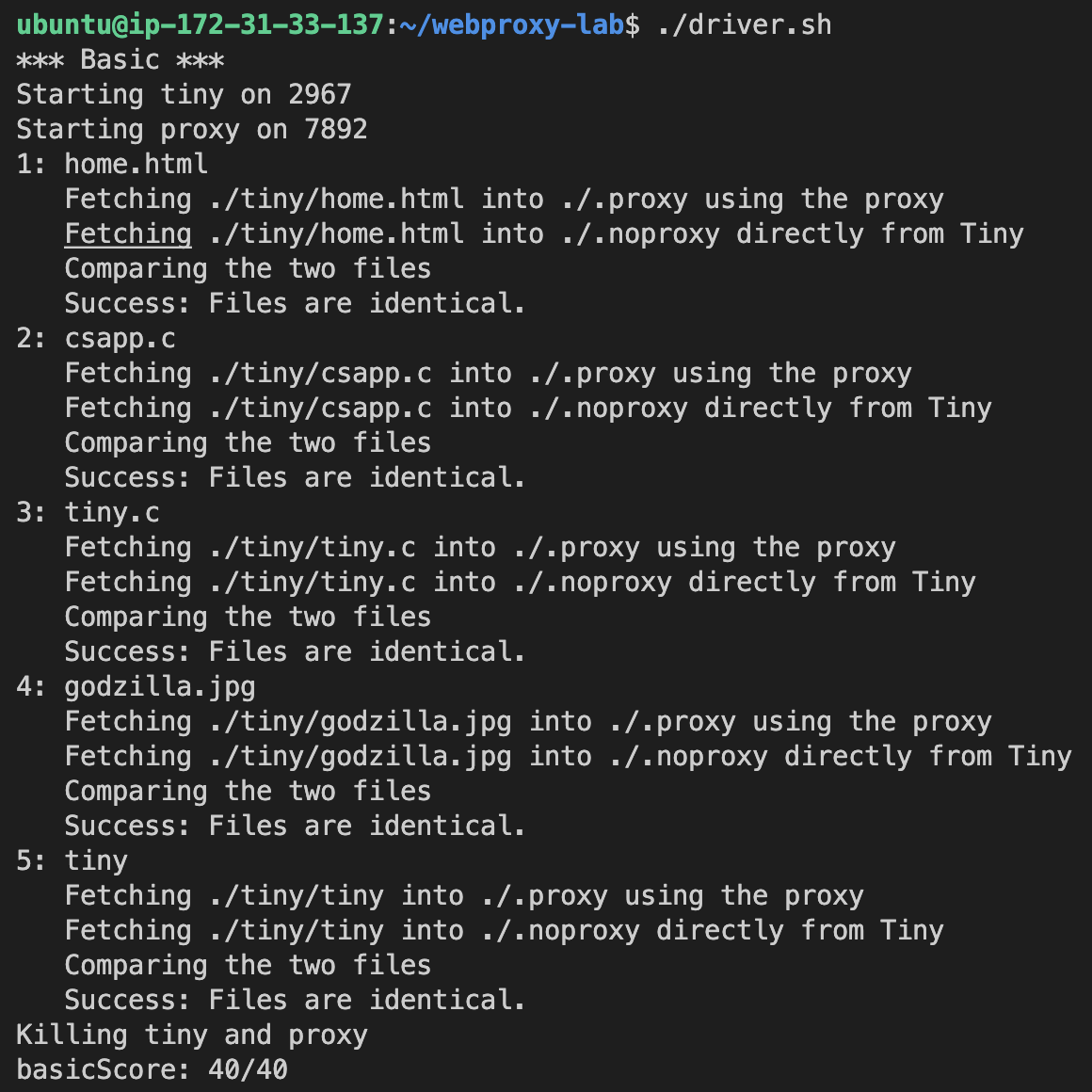

curl
1.tiny 터미널 => ./tiny 8000 실행, proxy 터미널 => ./proxy 7777 실행
2.webproxy 폴더가 있는 경로에서 mkdir testing
3.cd testing
4.tiny 터미널과 proxy 터미널이 아닌 새로운 터미널을 하나 열어줌
5.현재 위치가 testing 폴더일 때 curl --proxy http://localhost:7777 --output home.html http://localhost:8000/home.html
6.실행 후, client에서 요청된 파일이 proxy를 거쳐 서버에 요청이 잘 됨과 동시에 서버의 응답이 proxy를 거쳐 client에 왔다는 것을 testing에 home.html 파일이 만들어진 것으로 확인할 수 있다.
My Github 코드: https://github.com/kelvin3476/webproxy-lab/blob/main/proxy.c
-
