PintOS란? Pint OS의 줄임말로 즉, 작은 운영체제라는 뜻을 가지고 있다. pintOS를 앞으로 약 5~6주간 만들어나갈 예정 이며 이번주는 그 시작이 될 첫 주차 이자 project 1 을 진행할 예정이다.
키워드
-
Thread
-
Synchronization
-
Interrupt (Disabling Interrupts)
-
Semaphore
-
Lock
-
Monitors (Condition Variables)
-
-
Alarm Clock
- Sleep / Awake implementation
-
Priority Scheduling
-
Basic Priority Scheduling
-
Sema Priority Scheduling
-
Donate Priority Scheduling
-
Thread
Thread 란? 스레드(thread)는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이러한 실행 방식을 멀티스레드(multithread)라고 한다.
Thread 의 종류
스레드를 지원하는 주체에 따라 2가지로 나눌 수 있다.
사용자 레벨 스레드 (User-Level Thread)
사용자 스레드는 커널 영역의 상위에서 지원되며 일반적으로 사용자 레벨의 라이브러리를 통해 구현되며, 라이브러리는 스레드의 생성 및 스케줄링 등에 관한 관리 기능을 제공한다. 동일한 메모리 영역에서 스레드가 생성 및 관리되므로 속도가 빠른 장점이 있는 반면, 여러 개의 사용자 스레드 중 하나의 스레드가 시스템 호출 등으로 중단되면 나머지 모든 스레드 역시 중단되는 단점이 있다. 이는 커널이 프로세스 내부의 스레드를 인식하지 못하며 해당 프로세스를 대기 상태로 전환시키기 때문이다.
커널 레벨 스레드 (Kernel-Level Thread)
커널 스레드는 운영체제가 지원하는 스레드 기능으로 구현되며, 커널이 스레드의 생성 및 스케줄링 등을 관리한다. 스레드가 시스템 호출 등으로 중단되더라도, 커널은 프로세스 내의 다른 스레드를 중단시키지 않고 계속 실행시켜준다. 다중처리기 환경에서 커널은 여러 개의 스레드를 각각 다른 처리기에 할당할 수 있다. 다만, 사용자 스레드에 비해 생성 및 관리하는 것이 느리다.

Thread 진행흐름
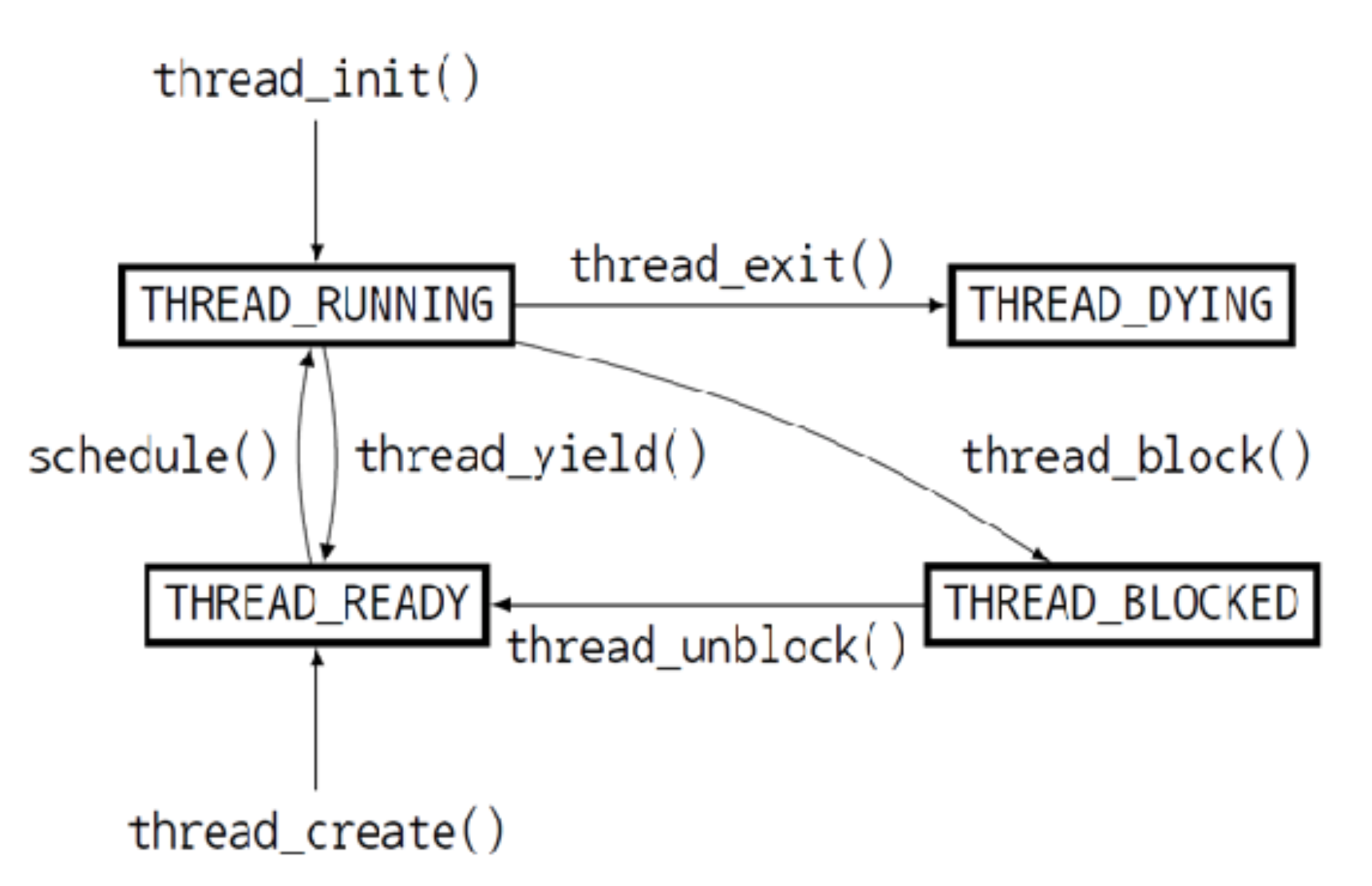
Thread 는 Running, Ready, Blocked, Dying 의 4가지 상태를 가진다.
-
THREAD_RUNNING : 현재 실행중인 스레드를 말하고 한 번에 하나의 스레드만 running 상태를 가질 수 있다.
-
THREAD_READY : 실행될 준비가 되어 실행을 기다리는 상태이며, 현재 실행중인 스레드가 실행을 멈추면 이 상태에 있는 스레드 중 하나가 실행 상태로 들어간다. 이 상태에 있는 스레드들은 READY QUEUE 에 들어가 관리된다.
-
THREAD_BLOCKED : 말 그대로 멈춰서 아직 실행 불가능한 상태이며, thread_unblock() 을 통해 실행 가능한 상태가 되면 THREAD_READY 상태가 되어 ready queue 에 들어간다.
-
THREAD_DYING : 스레드의 실행이 모두 끝나고 종료된 상태이다.
위의 흐름에서 ready queue 에 스레드들을 넣고 뺄 때의 순서를 정하는 것이 scheduling 의 주된 작업이라고 할 수 있다. 현재 pintos 는 round-robin 방식으로 구현되어 있고, 이는 어떤 스레드가 THREAD_READY 상태가 되어 ready queue 에 들어갈 때 queue 의 맨 뒤로 들어가고 next_thread_to_run() 에서 다음 running 상태가 될 스레드를 고를 때는 queue 의 맨 앞의 스레드를 골라서 queue 에 들어온 순서대로 실행되는 방식이다.
Thread의 개념 참고: https://ko.wikipedia.org/wiki/%EC%8A%A4%EB%A0%88%EB%93%9C_(%EC%BB%B4%ED%93%A8%ED%8C%85)
Thread의 Background 참고: https://poalim.tistory.com/26
Synchronization
-
Interrupt (Disabling Interrupts)
-
커널의 스케쥴링 방식에 따라 커널 스레드가 CPU 를 사용하고 있을 때 다른 스레드에 의해 CPU 의 사용을 선점(preemption) 당할 수 있는지의 여부가 달라진다. Pintos 는 커널 스레드가 언제든 선점당할 수 있는 Preemptible kernel 이다.(Non-preemtible kernel 에서는 스레드가 CPU 의 사용권을 다른 스레드에게 이양한 후에야 다른 스레드가 그 CPU 를 사용할 수 있다.)
-
Interrupt 를 비활성화 하는 것만으로 synchronization 을 실현할 수 있다. thread preemption 은 timer interrupt 에 의해 일어나기 때문에 interrupt 자체를 막아버리는 것이다. 이 방법은 external interrupt handlers 를 동기화시키기 위해 주로 사용되는데, external interrupt 는 프로그램 내부에서 발생하는 interrupt 와 다르게 외부에서 발생하는 interrupt 로, sleep 이 불가하기 때문에 다른 동기화 도구가 사용될 수 없고 가장 우선적으로 처리되어야 하기 때문에 외부 인터럽트가 실행되는 동안은 다른 모든 interrupt 를 비활성화한다.
-
-
Semaphore
-
멀티 스레드 프로그램에서는 여러 스레드가 메모리 등의 자원을 공유하게 되고 여러 스레드에 의해 공유되어 사용되는 자원을 공유자원이라고 한다. 각 스레드에서 이 공유자원을 엑세스 하는 코드구역을 임계구역(Critical Section) 이라고 하며, 같은 공유 데이터를 여러 스레드에서 동시에 접근하면 시간차이로 인한 잘못된 결과로 이어질 수 있기 때문에 하나의 스레드가 임계구역에 들어가 있다면 다른 스레드들은 임계구역에 접근하는 것을 제한하여야 한다.
-
세마포(Semaphores) 는 공유자원을 여러 스레드가 동시에 접근하지 못하도록 하는 도구로 하나의 nonnegative integer 와 두 개의 operators 로 이루어진다. nonnegative integer 는 사용 가능한 공유자원의 개수를 의미한다. 이 값이 2 라면 2개의 스레드가 동시에 접근 가능하고, 이 값이 0 이라면 사용 가능한 공유자원이 없음을 의미한다. 이 수는 다른 방식으로는 조작할 수 없고 오직 아래 두 개의 operator 로만 조작이 가능하다.
-
"Down"(or "P") : 어떤 스레드가 임계구역으로 들어와서 공유자원을 사용하고자 요청할 때 실행되고, 현재 사용 가능한 공유자원의 개수가 1개 이상이면(양수개이면) 이 수를 1 줄이고 임계구역을 실행한다.(공유자원을 사용한다.) 만약 현재 사용 가능한 공유자원의 개수가 0 이하면 이 값이 양수가 될 때까지 임계구역을 실행하지 않고 기다린다.
-
"Up"(or "V") : 스레드가 임계구역의 실행을 모두 마치고 공유자원을 반납할 때 실행된다. 사용 가능한 공유자원의 개수를 1 늘린다.
-
-
세마포는 초기화 값에 따라 그 용도가 달라질 수 있다. 우선, 특정 스레드가 단 한번 일어나는 다른 event 가 끝나길 기다려야 하는 경우 0 으로 초기화 된 세마포를 사용한다. 예를 들어, 스레드 A 가 진행 중에 스레드 B 를 시작하고 A 는 B 가 특정 작업을 끝내길 기다려야 하는 경우가 있다.
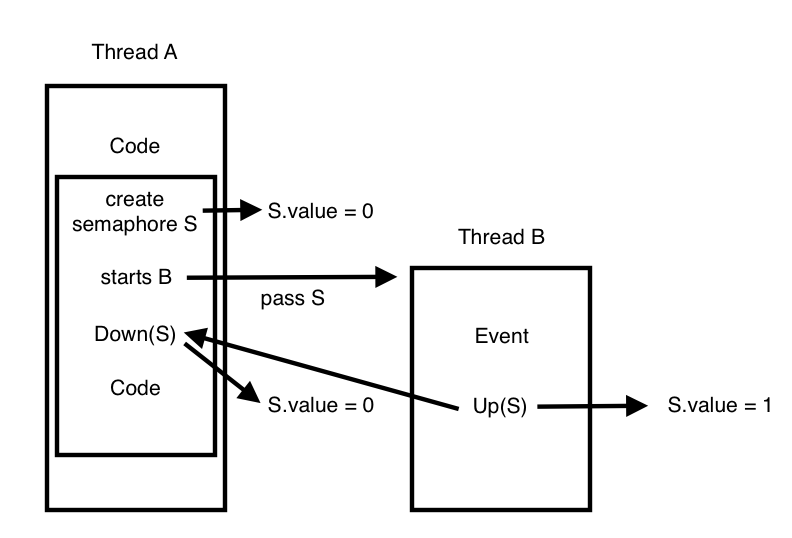
-
스레드 A 에서는 0 으로 초기화 한 세마포 S 를 만든 후 스레드 B 를 시작하면서 이 세마포를 함께 넘겨준 후 Down(S) 을 한다. 이 때, 현재 S.value 값이 0 이므로 스레드 A 는 block() 되어 기다리고, 스레드 B 는 특정 Event 를 수행한다. 이후 B 가 Event 를 끝내고 Up(S) 을 호출하면 S.value 값이 1이 되어 스레드 A 의 block() 이 풀리고, A 의 Down 으로 인해 바로 다시 S.value 값은 0 으로 되고 A 의 작업을 이어간다. 이 경우 스레드 A 의 start B 후 Down(S) 가 실행되기 전에 B 의 작업이 모두 끝나고 Up(S) 이 먼저 실행될 수 있지만, Down 에서 A 가 block 되지 않고 바로 진행된다는 점만 다를 뿐 세마포는 의도한 대로 작동한다.
-
하나의 공유자원에 접근을 제어할 때는 1 로 초기화된 세마포를 사용한다. 스레드 A 가 공유자원을 사용하기 전에 "Down" 을 하면 A 가 우선 실행되고 도중에 공유자원에 접근하는 다른 스레드들은 A 가 "Up" 을 호출하기 전까지 대기한다.
-
1 이상으로 초기화된 세마포는 여러 개의 공유자원을 사용하는 경우를 나타내지만 거의 사용되지 않는다.
-
세마포의 값이 0 으로 초기화 된 경우와 1 로 초기화 되는 경우가 헷갈리는 경우 다음과 같이 생각하면 될 것 같다.
- 0 으로 초기화 되는 경우 : 스레드 A 가 우선 기다림 -> 스레드 B 의 작업이 끝나면 A 가 실행
- 1 로 초기화 되는 경우 : 스레드 A 가 우선 실행됨 -> A 의 작업이 끝나면 기다리던 B 가 실행
-
세마포의 구조는 <threads/synch.h> 에 구현되어 있다. 세마포는 공유자원이 반환되기를 기다리며 block 되어 있는 waiting threads 의 list 를 <lib/kernel/list.c> 에 구현되어 있는 linked list 를 사용하여 저장한다. 아래는 pintos 에 구현되어 있는 세마포의 코드를 간단히 나타낸 것이다.
void down(S){ if(S.value == 0){ add this thread to S.list block(); } S.value--; } void up(S){ if(S.list is not empty){ remove this thread to S.list wakeUp(P) } S.value++; }
-
-
Lock
-
lock 도 마찬가지로 공유자원을 관리하는 동기화도구 중 하나로, 위에서 설명한 초기화 값이 1 인 세마포와 거의 비슷하게 동작한다. lock 에서는 "Up" 대신 "release", "Down" 대신 "acquire" 라는 이름의 operator 로 동작한다. lock 에는 세마포에는 없는 하나의 제약이 있는데, acquire 를 호출한 스레드만이 해당 lock 을 release 할 수 있다는 것이다. 0 으로 초기화 된 세마포의 설명에서 세마포는 스레드 A 에서 Down 을 하고 B 에서 Up 이 가능하였지만 lock 은 이러한 동작이 불가능하다. 이러한 제약으로 인해 문제가 발생한다면, 세마포를 사용하도록 하자.
-
Lock 의 구조 및 코드 역시 <threads/synch.h> 에 구현되어 있다.
-
-
Monitors (Condition Variables)
-
모니터는 동기화 문제를 해결하는 세마포나 락보다 활용도가 높고 사용이 쉬운 도구이다. 모니터는 공유자원, 모니터 락, 조건변수로 이루어진다. 모니터 락은 위에서 설명한 락과 유사하게 동작한다. lock 을 acquire 하면 이 스레드는 release 되기 전까지 "in the monitor" 상태가 된다. 이 상태에 여러 개의 스레드들이 있을 수 있고, 여기에 있는 스레드들은 서로 Mutual Exclusion(상호배타), 즉 공유자원을 하나의 스레드만 사용할 수 있는 상태가 된다. 별다른 조건이 없다면 여기에 있는 스레드들은 하나씩 차례로 실행되고 release 를 통해 빠져나간다. 모니터에는 여기에 추가로 Condition variables(조건 변수) 를 추가할 수 있다. 임계구역을 실행중이던 스레드는 wait(condition) 명령을 통해 실행을 멈추고 대기 상태로 들어갈 수 있고, 이후 다른 대기중이던 스레드가 임계구역을 실행시킨다. 대기 상태의 스레드는 condition 이 true 가 될 때까지 대기하게 되는데, 실행중인 스레드에서 signal(condition) 명령을 통해 wait 되어 있는 스레드 중 하나의 condition 을 true 로 만들어 깨울 수 있다. broadcast(condition) 명령어는 현재 wait 중인 모든 condition 을 모두 true 로 만들어 깨운다.
void put (char ch) { lock_acquire (&lock); while (n == BUF_SIZE) cond_wait (¬_full, &lock); buf[head++ % BUF_SIZE] = ch; n++; cond_signal (¬_empty, &lock); lock_release (&lock); } char get (void) { char ch; lock_acquire (&lock); while (n == 0) cond_wait (¬_empty, &lock); ch = buf[tail++ % BUF_SIZE]; n--; cond_signal (¬_full, &lock); lock_release (&lock); } -
이 예제에서 producer 스레드들은 put 함수를 통해 글자를 입력하고, consumer 스레드들은 get 함수를 통하여 글자들을 읽어온다. 버퍼의 크기는 한정적이므로 BUF_SIZE 가 가득 찬 경우에는 put 을 block 하여야 하고, 더 이상 읽어 올 글자가 버퍼에 남아 있지 않은 경우에는 get 을 block 하여야 한다.

- 처음에는 버퍼에 아무 글자도 없을 것이기 때문에 get 은 cond_wait(¬_empty) 에 의해 not_empty 가 true 가 될 때까지 대기 상태가 된다. 이와 동시에 put 함수에서는 하나의 글자를 버퍼에 쓰고 cond_signal(¬_empty) 를 하여 ¬_empty 라는 조건을 true 로 만들어주고, 이는 get 함수가 대기상태에서 깨어나 다시 진행되게 만들며 버퍼에 쓰여진 글자가 있기 때문에 정상적으로 글자를 읽어낸다. 반대의 경우도 마찬가지로 put 함수가 반복되어 버퍼가 가득 차게 되면 put 함수에서는 cond_wait(¬_full) 로 put 함수가 더 이상 실행될 수 없도록 대기 상태로 만들고 get 함수가 글자를 읽어 버퍼를 비워준 후에 cond_signal(¬_full) 을 통해 not_full 조건을 true 로 만들어 준 후에 다시 실행된다.
-
Alarm Clock
-
운영체제에는 실행중인 스레드를 잠시 재웠다가 일정 시간이 지나면 다시 깨우도록 하는 기능이 있는데, 이 기능을 Alarm Clock 이라고 한다. 현재 핀토스에 구현되어 있는 Alarm Clock 기능은 busy-waiting 방식으로 구현되어 있는데 이는 매우 비효율적으로 많은 CPU 시간을 낭비하게 한다. busy-waiting 방식에서 sleep 명령을 받은 스레드의 진행 흐름은 아래와 같이 진행된다.
잠이듬 -> 깨어남 -> 시간확인 -> 다시잠 -> 깨어남 -> 시간확인 -> ... -> 깨어남 -> 시간확인(일어날시간) -> 깨어남
-
이러한 문제가 발생하는 내면을 살펴보면 스레드의 상태가 running state 와 ready state 를 반복함을 볼 수 있다. running state 에서 sleep 명령을 받은 스레드는 ready state 가 되어 ready queue 에 추가되고 ready queue 에 있는 스레드들은 자신의 차례가 되면 일어날 시간이 되었는지에 상관없이 깨워져 running state 가 된다. 이렇게 running state 가 된 스레드는 자신이 일어날 시간이 되었는지 확인하고 아직 일어날 시간이 안 됐다면 다시 ready state 로 전환한다.
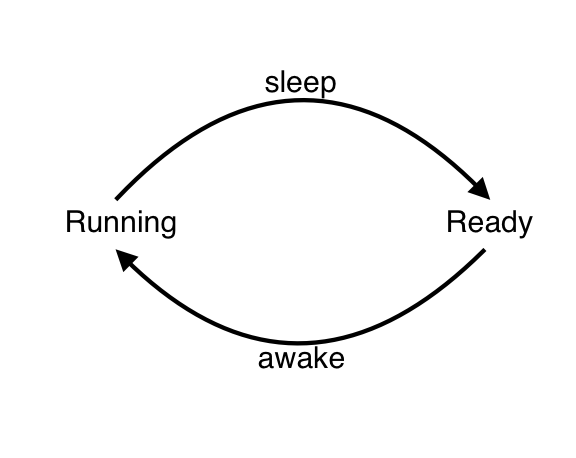
- 이러한 비효율을 해결하려면 잠이 든 스레드를 ready state 가 아닌 block state 로 두어서 깨어날 시간이 되기 전까지는 스케줄링에 포함되지 않도록 하고, 깨어날 시간이 되었을 때 ready state 로 바꾸어 주면 된다.
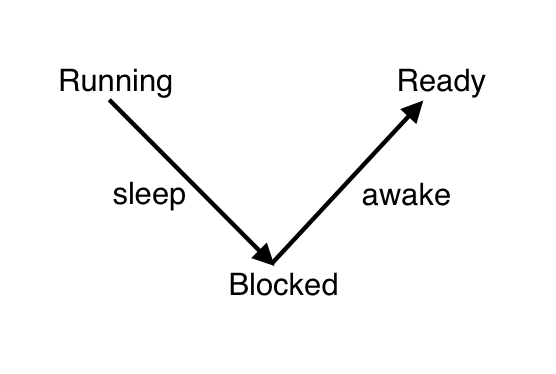
-
Sleep / Awake Implementation
-
Alarm clock 을 개선하는 기본적인 아이디어는 위에서 언급한대로 잠이 들 때 ready state 가 아니라 block state 로 보내고 깨어날 시간이 되면 깨워서 ready state 로 보내는 것이다. 이를 구현해보자.
-
우선, block state 에서는 스레드가 일어날 시간이 되었는지 주기적으로 확인하지 않기 때문에 스레드마다 일어나야 하는 시간에 대한 정보를 저장하고 있어야 한다. wakeup 이라는 변수를 만들어 thread 구조체에 추가하겠다.
/* thread/thread.h */ struct thread{ ... int64_t wakeup; // 깨어나야 하는 ticks 값 ... } -
현재 핀토스에서 스레드들을 관리하는 리스트는 ready list 와 all list 두 개만 존재한다. 잠이 들어 block 상태가 된 스레드들은 all list 에 존재하지만, sleep 상태의 스레드들로만 이루어진 리스트를 만들어 관리하면 훨씬 편해진다. sleep_list 를 추가하고 초기화까지 시켜준다.
/* thread/thread.c */ static struct list sleep_list; void thread_init (void) { ... list_init (&ready_list); list_init (&all_list); list_init (&sleep_list); ... } -
이제 스레드를 재우는 작업이 필요하다. 일어날 시간을 저장한 다음에 재워야 할 스레드를 sleep_list 에 추가하고, 스레드 상태를 block state 로 만들어주는 것으로 충분할 것 같다. 한 가지 주의할 점은 CPU 가 항상 실행 상태를 유지하게 하기 위해 idle 스레드는 sleep 되지 않아야 한다는 것이다.
/* thread/thread.c */ void thread_sleep (int64_t ticks) { struct thread *cur; enum intr_level old_level; old_level = intr_disable (); // 인터럽트 off cur = thread_current (); ASSERT (cur != idle_thread); cur->wakeup = ticks; // 일어날 시간을 저장 list_push_back (&sleep_list, &cur->elem); // sleep_list 에 추가 thread_block (); // block 상태로 변경 intr_set_level (old_level); // 인터럽트 on } -
스레드를 재우는 함수를 만들었으니 timer_sleep() 함수의 while 문을 새로운 함수로 바꾸어 주자.
/* devices/timer.c */ void timer_sleep (int64_t ticks) { int64_t start = timer_ticks (); thread_sleep (start + ticks); } -
이제 timer_sleep() 함수가 호출되면 스레드가 block 상태로 들어가게 되었다. 이렇게 block 된 스레드들은 일어날 시간이 되었을 때 awake 되어야 한다. sleep_list 를 돌면서 일어날 시간이 지난 스레드들을 찾아서 ready list 로 옮겨주고, 스레드 상태를 ready state 로 변경시켜주도록 하자.
/* thread/thread.c */ void thread_awake (int64_t ticks) { struct list_elem *e = list_begin (&sleep_list); while (e != list_end (&sleep_list)){ struct thread *t = list_entry (e, struct thread, elem); if (t->wakeup <= ticks){ // 스레드가 일어날 시간이 되었는지 확인 e = list_remove (e); // sleep list 에서 제거 thread_unblock (t); // 스레드 unblock } else e = list_next (e); } }
※ 새롭게 sleep, awake 함수를 추가하였으므로 thread.h 에 프로토타입을 선언해주어야 한다.
/* thread/thread.h */ ... void thread_sleep(int64_t ticks); void thread_awake(int64_t ticks); ...-
위에서 1 tick 이 경과할 때마다 timer 인터럽트가 실행된다고 하였다. 이 timer interrupt 작업에 awake 작업을 포함시키면 ticks 가 증가할때마다 깨워야 할 스레드가 있는지 찾고, 깨워줄 수 있다. timer_interrupt handler 함수는 devices/timer.c 에 구현되어 있다.
/* devices/timer.c */ static void timer_interrupt (struct intr_frame *args UNUSED) { ticks++; thread_tick (); thread_awake (ticks); // ticks 가 증가할때마다 awake 작업 수행 }
-
결과
-
pintos/src/thread 폴더에서 make 명령으로 컴파일을 하고, pintos -q run alarm-multiple 명령을 실행하면 아래와 같은 결과를 확인할 수 있다.
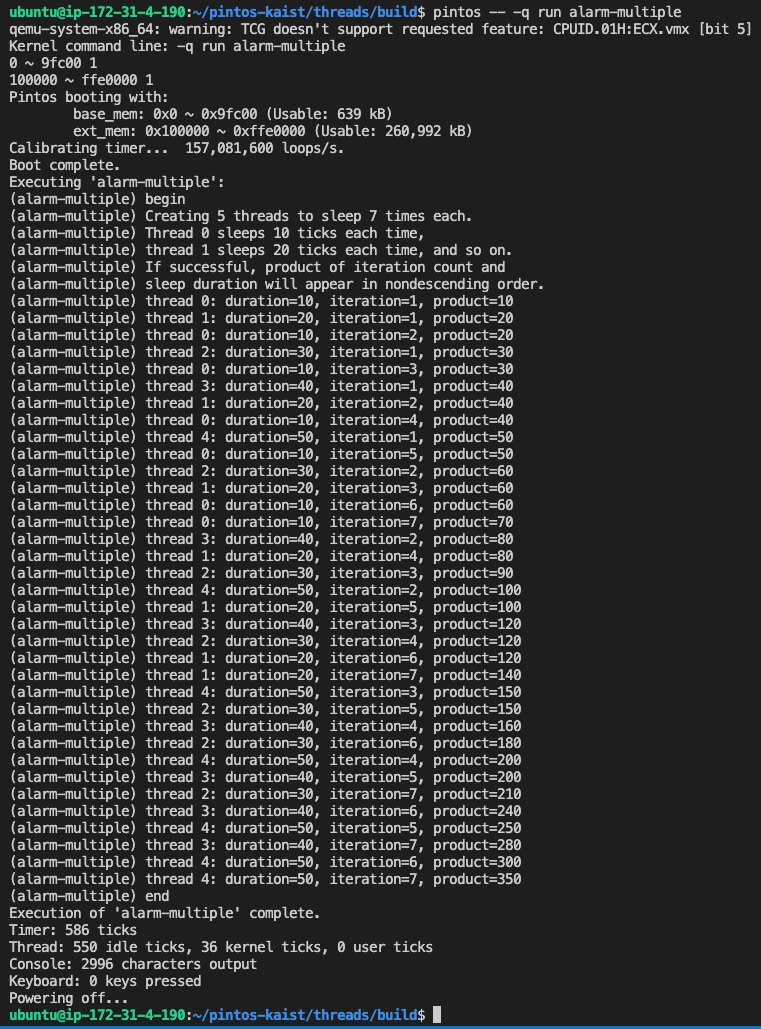
-
처음에 구현되어 있던 busy-waiting 방식으로 실행 시 Thread: 0 idle ticks 로 나오던 부분이 550 idle ticks 로 바뀌었다. 이것은 idle 스레드가 550 ticks 동안 실행되었다는 것이고, idle 스레드는 다른 어떤 스레드도 실행되지 않는 상태일 때 실행되는 스레드로 550 ticks 동안의 쉬는 시간이 발생했다는 뜻과 같습니다. busy-waiting 방식일 때 ready list 가 비어있는 순간이 없기 때문에 idle 스레드가 실행될 일이 없어 0 idle ticks 로 출력된 것과 달리 sleep/awake 방식에서 시스템 자원의 낭비가 줄어든 것을 볼 수 있다.
Priority Scheduling
-
Basic Priority Scheduling
- 스케쥴링은 ready 상태에 있는 스레드들의 순서를 관리하여 가장 높은 priority 를 가진 스레드가 running 상태가 될 수 있도록 만들어주는 것이다.
현재상태
-
우선 현재 pintos 가 스케쥴링을 어떻게 관리하고 있는지 살펴보자. ready_list 에 새로운 스레드가 push 되는 순간을 찾아보면 될 것 같다.
/* thread/thread.c */ void thread_unblock (struct thread *t) { enum intr_level old_level; ASSERT (is_thread (t)); old_level = intr_disable (); ASSERT (t->status == THREAD_BLOCKED); list_push_back (&ready_list, &t->elem); // ready_list 에 스레드 추가 t->status = THREAD_READY; intr_set_level (old_level); } void thread_yield (void) { struct thread *cur = thread_current (); enum intr_level old_level; ASSERT (!intr_context ()); old_level = intr_disable (); if (cur != idle_thread) list_push_back (&ready_list, &cur->elem); // ready_list 에 스레드 추가 cur->status = THREAD_READY; schedule (); intr_set_level (old_level); } -
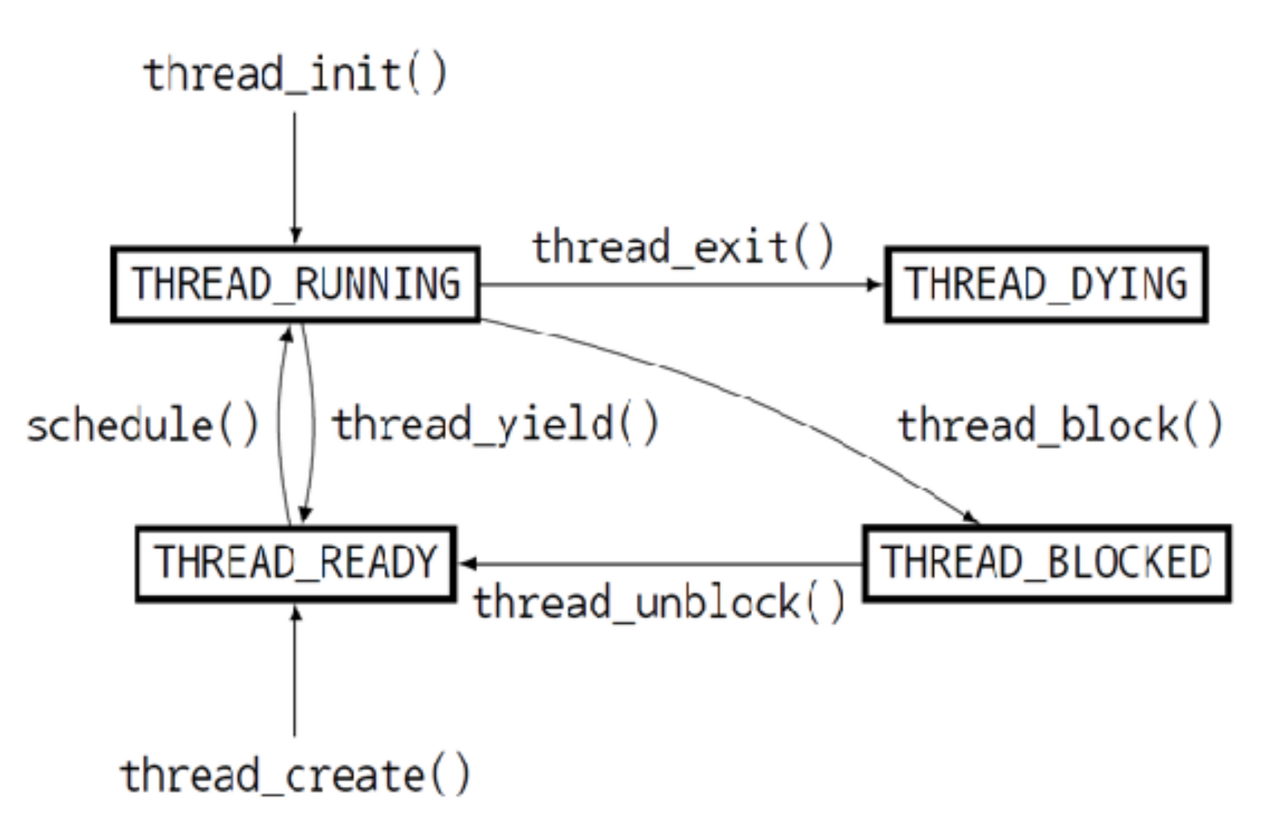
ready_list 에 새로운 스레드가 추가되는 두 함수를 찾아냈다. 공통적으로 list_push_back (&ready_list, ... ) 함수가 사용되었고 이 함수는 <lib/kernel/list.c> 에서 찾아볼 수 있는데, 이름에서 알 수 있듯이 새로운 elem 을 리스트의 맨 뒤에 push 하는 함수이다. 즉 현재 pintos 는 새로운 스레드를 ready_list 에 넣을 때 항상 맨 뒤에 넣는다는 것을 볼 수 있다. 그럼 ready_list 에서 스레드를 꺼낼 때는 어떻게 진행되는지도 찾아보자. ready_list 에서 스레드를 꺼내는 순간은 현재 running thread 가 CPU 를 양보하여 새로운 running thread 를 고르는 순간이다. 아래 그림을 보자.

-
위 그림에서 보면 THREAD_RUNNING 에서 나가는 화살표가 running thread 가 CPU 를 양보하는 순간이다. thread_exit(), thread_yield(), thread_block() 세 경우가 있는 것을 볼 수 있다. 이 세 함수들은 <thread/thread.c> 에 있고, 하나하나 살펴보면 함수의 마지막부분에 schedule() 함수를 호출하고 CPU 소유권을 내려놓는다. 그럼 이 schedule() 를 살펴보아야 한다.
/* thread/thread.c */ static void schedule (void) { struct thread *cur = running_thread (); struct thread *next = next_thread_to_run (); struct thread *prev = NULL; ASSERT (intr_get_level () == INTR_OFF); ASSERT (cur->status != THREAD_RUNNING); ASSERT (is_thread (next)); if (cur != next) prev = switch_threads (cur, next); thread_schedule_tail (prev); }-
schedule() 함수는 switch_threads (cur, next) 함수를 실행하여 CPU 점유권을 cur 에서 next 스레드로 넘긴다. 그럼 여기서 다음으로 CPU 의 점유권을 받는 함수는 next_thread_to_run() 에 의해 결정된다는 것을 알 수 있다. 이 함수 역시 thread.c 에서 찾아볼 수 있다.
static void schedule (void) { struct thread *curr = running_thread (); struct thread *next = next_thread_to_run (); ASSERT (intr_get_level () == INTR_OFF); ASSERT (curr->status != THREAD_RUNNING); ASSERT (is_thread (next)); /* Mark us as running. */ next->status = THREAD_RUNNING; /* Start new time slice. */ thread_ticks = 0; #ifdef USERPROG /* Activate the new address space. */ process_activate (next); #endif if (curr != next) { /* If the thread we switched from is dying, destroy its struct thread. This must happen late so that thread_exit() doesn't pull out the rug under itself. We just queuing the page free reqeust here because the page is currently used by the stack. The real destruction logic will be called at the beginning of the schedule(). */ if (curr && curr->status == THREAD_DYING && curr != initial_thread) { ASSERT (curr != next); list_push_back (&destruction_req, &curr->elem); } /* Before switching the thread, we first save the information * of current running. */ thread_launch (next); } } -
반환값을 보면 list_pop_front (&ready_list), 즉 ready_list 의 맨 앞의 항목을 반환한다는 것을 알 수 있다.
-
즉, 현재 pintos 는 ready_list 에 push 는 맨 뒤에, pop 은 맨 앞에서 하는 round-robin 방식을 채택하고 있다는 것을 알 수 있다. 이러한 방식은 스레드간의 우선순위 없이 ready_list 에 들어온 순서대로 실행하여 가장 간단하지만 제대로 된 우선순위 스케쥴링이 이루어지고 있지 않다고 할 수 있다.
-
Priority Scheduling 구현
-
pintos 가 제대로 우선순위 스케쥴링을 하도록 만들어보자. 두 가지 방법이 가능할 것 같다.
- ready_list 에 push 할 때 priority 순서에 맞추어 push 하는 방법
- ready_list 에서 pop 할 때 priority 가 가장 높은 스레드를 찾아 pop 하는 방법
-
전자는 항상 ready_list 가 정렬된 상태를 유지하기 때문에 새로운 스레드를 push 할 때 list 의 끝까지 모두 확인할 필요가 없지만, 후자는 ready_list 가 정렬된 상태를 유지하지 않으므로 pop 할 때마다 list 의 처음부터 끝까지 모두 훑어야 하기 때문에 전자가 더 효율적이기 때문에 전자의 방법을 사용하기로 한다.
-
push 할 때 순서에 맞추어 넣기 때문에 꺼낼때는 리스트의 맨 앞에서 꺼내는 현재 방식을 유지하고 정렬 방식을 내림차순으로 설정하면 되기 때문에 next_thread_to_run() 함수는 건드리지 않아도 될 것 같다. 바꾸어야 하는 것은 위에서 살펴본 list_push_back 이 실행되는 thread_unblock(), thread_yield() 함수이다. thread_create() 함수에서도 새로운 스레드가 ready_list 에 추가되지만 thread_create() 함수 자체에서 thread_unblock() 함수를 포함하고 있기 때문에 thread_unblock() 함수를 수정함으로써 동시에 처리된다. 그럼 list_push_back 함수를 내림차순으로 정렬하여 push 하는 함수로 대체하여 보자. <lib/kernel/list.c> 에는 list 를 다루는 여러 함수들이 구현되어 있는데 아주 유용해 보이는 함수를 찾아볼 수 있다.
/* lib/kernel/list.c */ void list_insert_ordered (struct list *list, struct list_elem *elem, list_less_func *less, void *aux) { struct list_elem *e; ASSERT (list != NULL); ASSERT (elem != NULL); ASSERT (less != NULL); for (e = list_begin (list); e != list_end (list); e = list_next (e)) if (less (elem, e, aux)) break; return list_insert (e, elem); }-
이름에서 볼 수 있듯이 정렬하여 리스트에 insert 하는 함수이다. parameter 는 insert 할 list 와 element 를 받고 비교함수를 받는다. 내용을 보면 for 반복문으로 list 의 첫 e 부터 진행하면서 입력받은 elem 이 less 함수를 통과하는 순간의 e 위치에 해당 element 를 삽입한다. e 위치에 삽입하는 list_insert (e, elem) 함수가 elem 을 e 의 앞에 삽입하는지 뒤에 삽입하는지도 확인해야 한다.
/* lib/kernel/list.c */ void list_insert (struct list_elem *before, struct list_elem *elem) { ASSERT (is_interior (before) || is_tail (before)); ASSERT (elem != NULL); elem->prev = before->prev; elem->next = before; before->prev->next = elem; before->prev = elem; } -
elem->next = before 이므로 elem 은 e 의 앞에 삽입된다는 것을 확인했다. 우리는 ready_list 에서 스레드를 pop 할 때 가장 앞에서 꺼내기로 하였기 때문에 가장 앞에 priority 가 가장 높은 스레드가 와야 한다. 즉, ready_list 는 내림차순으로 정렬되어야 한다. list_insert 가 일어나는 순간 elem 은 e 의 앞으로 들어가기 때문에 내림차순으로 정렬되기 위해서는 if (less (elem, e, aux)) 가 elem > e 인 순간에 break; 를 실행해주어야 한다. 즉, 우리가 만들어야 하는 함수 less (elem, e, aux) 는 elem > e 일 때 true 를 반환하는 함수이다.
/* thread/thread.c */ bool thread_compare_priority (struct list_elem *l, struct list_elem *s, void *aux UNUSED) { return list_entry (l, struct thread, elem)->priority > list_entry (s, struct thread, elem)->priority; } -
위와 같이 비교 함수를 만들어 주었다. 이제 이 함수를 적용하여 list_push_back 을 list_insert_ordered 로 바꾸어주면 된다!
/* thread/thread.c */ void thread_unblock (struct thread *t) { enum intr_level old_level; ASSERT (is_thread (t)); old_level = intr_disable (); ASSERT (t->status == THREAD_BLOCKED); //list_push_back (&ready_list, &t->elem); list_insert_ordered (&ready_list, &t->elem, thread_compare_priority, 0); t->status = THREAD_READY; intr_set_level (old_level); } void thread_yield (void) { struct thread *cur = thread_current (); enum intr_level old_level; ASSERT (!intr_context ()); old_level = intr_disable (); if (cur != idle_thread) //list_push_back (&ready_list, &cur->elem); list_insert_ordered (&ready_list, &cur->elem, thread_compare_priority, 0); cur->status = THREAD_READY; schedule (); intr_set_level (old_level); } -
thread_unblock, thread_yield 에서 list_push_back 을 주석처리하고 list_insert_ordered 를 넣어주었다. 세 번째 인자에 위에서 만든 thread_compare_priority 함수를 넣어서 처리해주면 된다.
-
자, 아직 한 가지가 남았다. 현재 실행중인 running 스레드의 priority 가 바뀌는 순간이 있다. 이 때 바뀐 priority 가 ready_list 의 가장 높은 priority 보다 낮다면 CPU 점유를 넘겨주어야 한다. 현재 실행중인 스레드의 priority 가 바뀌는 순간은 두 가지 경우이다.
- thread_create()
- thread_set_priority()
-
위 두 경우의 마지막에 running thread 와 ready_list 의 가장 앞의 thread 의 priority 를 비교하는 코드를 넣어주어야 한다.
/* thread/thread.c */ void thread_test_preemption (void) { if (!list_empty (&ready_list) && thread_current ()->priority < list_entry (list_front (&ready_list), struct thread, elem)->priority) thread_yield (); } -
running thread 와 ready_list 의 가장 앞 thread 의 priority 를 비교하고, 만약 ready_list 의 스레드가 더 높은 priority 를 가진다면 thread_yield () 를 실행하여 CPU 점유권을 넘겨주는 함수를 만들었다. 이 함수를 thread_create() 와 thread_set_priority() 에 추가하여 준다.
/* thread/thread.c */ tid_t thread_create (const char *name, int priority, thread_func *function, void *aux) { ... thread_unblock (t); thread_test_preemption (); return tid; } void thread_set_priority (int new_priority) { thread_current ()->priority = new_priority; thread_test_preemption (); }
-
결과
이제 기본적인 priority scheduling 을 구현하였으니 테스트를 해보자.

무려 4개의 테스트를 더 통과했다!! 아직 통과하지 못한 테스트를 보면 priority-donate, priority-sema 등의 항목이 눈에 띈다. pintos 도큐먼트에서도 명시되어 있듯이 priority scheduling 은 priority donate 와 priority sema 까지 구현해야 한다. 이것은 다음 포스트에서 살펴보도록 한다.
-
Sema Priority Scheduling
-
이번에는 동기화 도구들의 스케쥴링 방식을 살펴보자. 스케쥴링 도구들의 코드는 thread 폴더의 synch.h, synch.c 에 구현되어 있다. 우리가 다루어야 할 동기화 도구는 lock, semaphore, condition variable 3가지이다. 하나씩 살펴보자.
/* thread/synch.h */ struct semaphore { unsigned value; /* Current value. */ struct list waiters; /* List of waiting threads. */ }; struct lock { struct thread *holder; /* Thread holding lock (for debugging). */ struct semaphore semaphore; /* Binary semaphore controlling access. */ }; struct condition { struct list waiters; /* List of waiting threads. */ }; -
semaphore 은 공유 자원의 개수를 나타내는 value 와 공유 자원을 사용하기 위해 대기하는 waiters 의 리스트를 가진다. lock 은 value = 1인 특별한 semaphore 로 구현되어 있고, 현재 lock 을 가지고 있는 thread 정보와 semaphore 를 멤버로 가진다. condition 은 condition variables 가 만족하기를 기다리는 waiters 의 리스트를 가진다.
-
Semaphore
-
semaphore 를 예로 들면, 하나의 공유자원을 사용하기 위해 여러 스레드가 sema_down 되어 대기하고 있다고 할 때, 이 공유자원을 사용하던 스레드가 공유자원의 사용을 마치고 sema_up 할 때 어떤 스레드가 가장 먼저 이 공유자원을 차지할 것인가에 대한 문제가 스케쥴링에서 해결해야 하는 것이다. 그럼 현재 어떻게 이루어져 있는지 코드를 살펴보자.
/* thread/synch.c */ void sema_down (struct semaphore *sema) { enum intr_level old_level; ASSERT (sema != NULL); ASSERT (!intr_context ()); old_level = intr_disable (); while (sema->value == 0) { list_push_back (&sema->waiters, &thread_current ()->elem); thread_block (); } sema->value--; intr_set_level (old_level); } void sema_up (struct semaphore *sema) { enum intr_level old_level; ASSERT (sema != NULL); old_level = intr_disable (); if (!list_empty (&sema->waiters)) { thread_unblock (list_entry (list_pop_front (&sema->waiters), struct thread, elem)); } sema->value++; intr_set_level (old_level); }-
semaphore 를 다루는 함수는 sema_down, sema_up 두 가지이다. 공유 자원을 사용하고자 하는 스레드는 sema_down 을 실행하고, 사용 가능한 공유자원이 없다면 sema->waiters 리스트에 list_push_back 함수로 맨 뒤에 추가된다. 공유자원의 사용을 마친 스레드가 sema_up 을 하면 thread_unblock 을 하는데, list_pop_front 함수로 sema->waiters 리스트의 맨 앞에서 꺼내는 것을 볼 수 있다. 이전 포스트에서 봤던 ready_list 와 똑같이 리스트에 들어온 순서대로 차례로 실행되는 방식을 따르는 것을 알 수 있다. ready_list 에서 했던 것처럼 이번에도 priority 에 따라 자원을 할당받도록 만들어보자. 추가할 때는 priority 에 내림차순으로 리스트에 추가하고 꺼낼 때는 그대로 맨 앞에서 꺼내면 된다.
void sema_down (struct semaphore *sema) { enum intr_level old_level; ASSERT (sema != NULL); ASSERT (!intr_context ()); old_level = intr_disable (); while (sema->value == 0) { list_insert_ordered (&sema->waiters, &thread_current ()->elem, thread_compare_priority, 0); thread_block (); } sema->value--; intr_set_level (old_level); } -
while 문장 안에 있던 list_push_back 을 list_insert_ordered 을 사용하여 내림차순으로 정렬되도록 추가하였다. semaphore 에 추가되는 element 들은 스레드이므로 스레드에서 사용하였던 thread_compare_priority 함수를 그대로 사용하면 된다.
void sema_up (struct semaphore *sema) { enum intr_level old_level; ASSERT (sema != NULL); old_level = intr_disable (); if (!list_empty (&sema->waiters)) { list_sort (&sema->waiters, thread_compare_priority, 0); thread_unblock (list_entry (list_pop_front (&sema->waiters), struct thread, elem)); } sema->value++; thread_test_preemption (); intr_set_level (old_level); } -
sema_up 에서는 waiters 리스트에 있던 동안 우선순위에 변경이 생겼을 수도 있으므로 waiters 리스트를 내림차순으로 정렬하여 준다. <lib/kernel/list.c> 에 있는 list_sort 함수를 사용하면 간단하게 가능하다. 그 후 unblock 된 스레드가 running 스레드보다 우선순위가 높을 수 있으므로 thread_test_preemption () 함수를 실행하여 CPU 선점이 일어나게 해준다.
-
이렇게 하면 semaphore 에 대한 작업은 끝이났다. 다음은 lock 의 구조를 살펴보자.
/* thread/synch.c */ void lock_acquire (struct lock *lock) { ASSERT (lock != NULL); ASSERT (!intr_context ()); ASSERT (!lock_held_by_current_thread (lock)); sema_down (&lock->semaphore); lock->holder = thread_current (); } void lock_release (struct lock *lock) { ASSERT (lock != NULL); ASSERT (lock_held_by_current_thread (lock)); lock->holder = NULL; sema_up (&lock->semaphore); } -
lock 을 다루는 두 함수를 살펴보면 알 수 있듯이 마지막이 sema_down, sema_up 으로 끝난다. 즉 lock 은 value = 1 이고, holder 정보를 가지고 있다는 것을 제외하고는 semaphore 와 동일하게 동작하기 때문에 sema_down, sema_up 을 이미 처리해주었으므로 lock 은 따로 처리해 줄 필요가 없다는 것을 알 수 있다.
-
결과
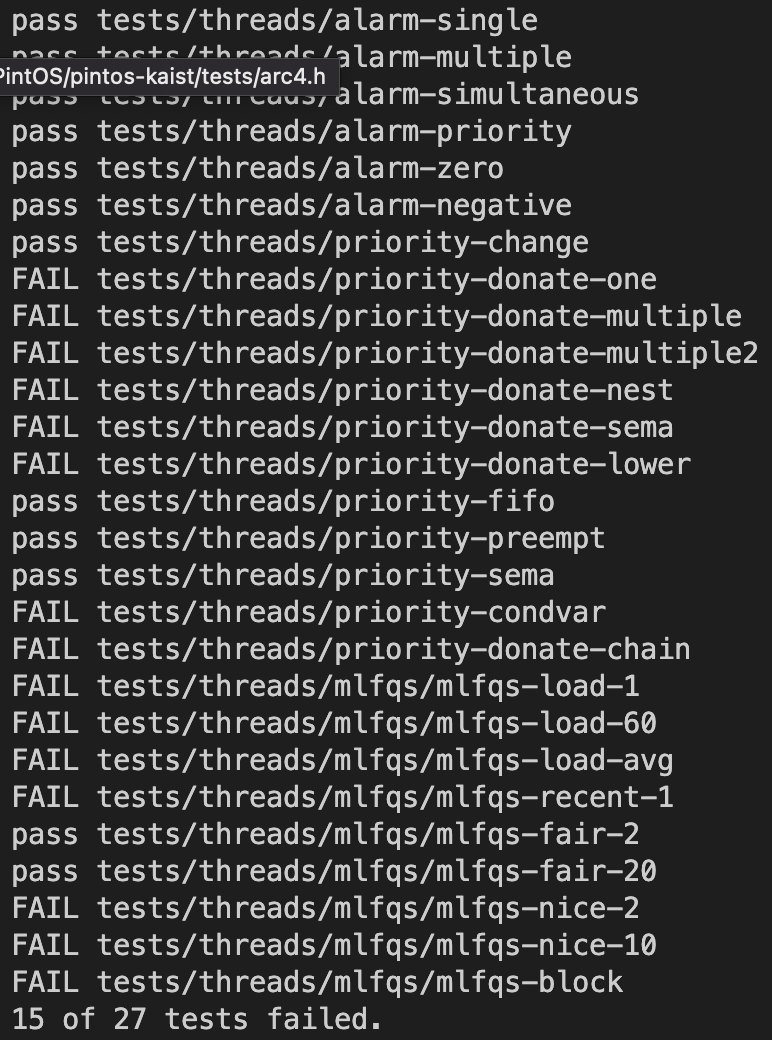
1개의 테스트를 더 통과한 것을 볼 수 있다. 방금 우리가 구현한 priority-sema 가 pass 가 나왔다. FAIL 의 숫자가 점점 줄어가는 것이 보기 좋다. 다음 시간에는 priority-donate 문제를 풀어보도록 한다.
-
Donate Priority Scheduling
- 드디어 Priority Scheduling 의 마지막 파트인 Priority Inversion 까지 왔다. 이전에 다루었던 문제들보다 꽤 많이 복잡해서 생각보다 시간이 오래 걸렸다
Priority Inversion
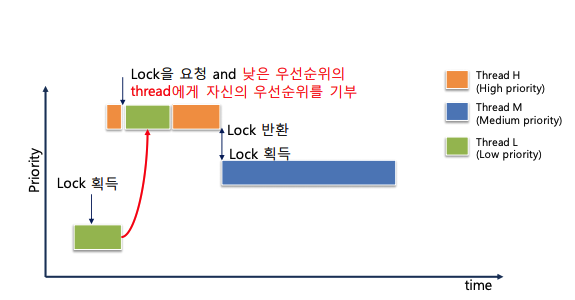
- 핀토스 Documents 에 나와있는 설명을 해석해보자. 우선 priority inversion 이란 다음과 같은 상황에서 발생한다. H (high), M (medium), L (low) 라는 세 개의 스레드가 있고 각각의 우선순위는 H > M > L 일 때, H 가 L 을 기다려야 하는 상황(예를 들어, H 가 lock 을 요청했는데 이 lock 을 L 이 점유하고 있는 경우)이 생긴다면 H 가 L 에게 CPU 점유를 넘겨주면 M 이 L 보다 우선순위가 높으므로 점유권을 선점하여 실행되어서 스레드가 마무리 되는 순서가 M->L->H 가 되어서 M 이 더 높은 우선순위를 가진 H 보다 우선하여 실행되는 문제가 발생한다. 이를 잘 나타낸 그림이 있어서 가져와 보았다.

- 이러한 문제를 해결하기 위한 방법으로 priority donation 을 구현하여야 한다. priority donation 이란 위의 상황에서 H 가 자신이 가진 priority 를 L 에게 일시적으로 양도하여서 H 자신의 실행을 위해 L 이 자신과 동일한 우선순위를 가져서 우선적으로 실행될 수 있도록 만드는 방법이다. priority donation 이 작동하면 실행 순서는 아래와 같이 바뀐다.
- 핀토스 documents 에서는 priority donation 이 일어난 수 있는 모든 상황을 고려해야 한다고 하면서 Multiple donation, Nested donation 두 가지를 언급한다.
Multiple donation
- 단어에서 알 수 있듯이 여러번의 donation 이 일어난 상황이라고 볼 수 있다. 위의 예시에서 L 가 lock A, lock B 라는 두 가지 lock 을 점유하고 있다고 해보자. H 가 lock A 를, M 이 lock B 를 각각 요청하였을 때, L 은 자신이 가지고 있는 lock 을 요청한 모든 스레드에게 priority 를 양도받고, 이 중 가장 높은 priority 를 일시적으로 자신의 priority 로 갖는다. 그림으로 보면 아래와 같다.

- 이 경우에 L 이 lock B 를 release 해도 아직 M 에게 양도받은 priority 가 있기 때문에 31 이 아닌 32의 priority 를 가지게 된다.
Nested donation
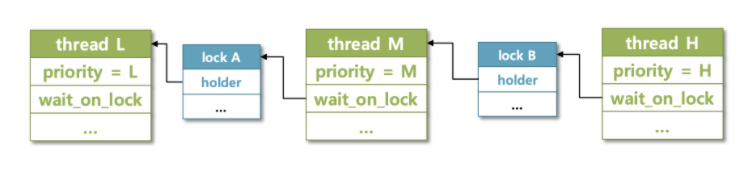
- 그림에서 볼 수 있듯이 H 가 lock B 를 얻기 위해 M 에게 priority donation 을 행하고 M 은 lock A 를 얻기 위해 L 에게 priority donation 을 행하는 것 처럼, 여러번의 단계적 donation 이 일어나는 상황이다.
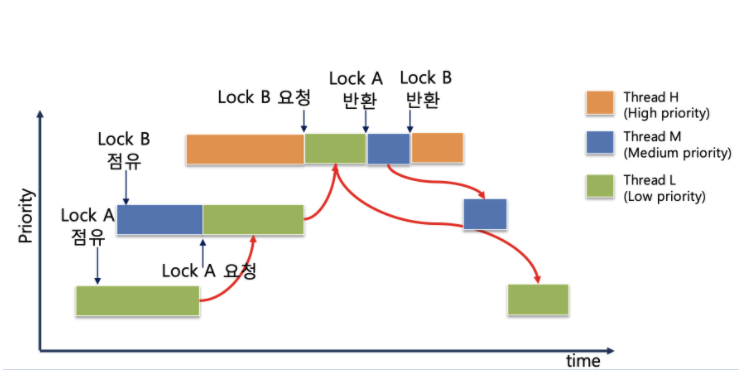
-
시간에 따라 스레드의 진행 순서는 위와 같다.
-
그럼 이제 구현을 시작해보자.
struct thread
-
우선 각 스레드가 양도받은 내역을 관리할 수 있게 thread 의 구조체를 변경해줄 필요가 있다.
struct thread { ... int init_priority; struct lock *wait_on_lock; struct list donations; struct list_elem donation_elem; ... }; -
4개 정도의 항목을 추가해주었다. init_priority 는 스레드가 priority 를 양도받았다가 다시 반납할 때 원래의 priority 를 복원할 수 있도록 고유의 priority 값을 저장하는 변수이다. wait_on_lock 은 스레드가 현재 얻기 위해 기다리고 있는 lock 으로 스레드는 이 lock 이 release 되기를 기다린다. donations 는 자신에게 priority 를 나누어준 스레드들의 리스트이고 donation_elem 은 이 리스트를 관리하기 위한 element 로 thread 구조체의 그냥 elem 과 구분하여 사용하도록 한다.
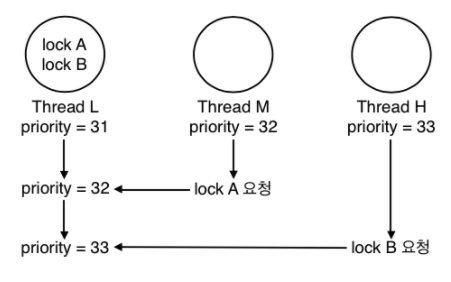
-
multiple donation 에서 사용했던 그림으로 예시를 들면, L->donations = [M, H], M->wait_on_lock = A, H->wait_on_lock = B 이고, L->init_priority = 31 이다.
-
새로운 요소를 추가하였으면 언제나 초기화는 기본이다. init_thread 에서 초기화 코드를 추가해준다.
/* thread/thread.c */ static void init_thread (struct thread *t, const char *name, int priority) { ... t->init_priority = priority; t->wait_on_lock = NULL; list_init (&t->donations); ... }
lock_acquire (struct lock *lock)
-
lock_acquire() 함수는 스레드가 lock 을 요청할 때 실행된다. lock 을 현재 점유하고 있는 스레드가 없으면 상관 없지만, 누군가 점유하고 있다면 자신의 priority 를 양도하여 lock 을 점유하고 있는 스레드가 우선적으로 lock 을 반환하도록 해야한다. 우선 현재 lock_acquire() 가 어떻게 구현되어 있는지 보자.
/* thread/synch.c */ void lock_acquire (struct lock *lock) { ASSERT (lock != NULL); ASSERT (!intr_context ()); ASSERT (!lock_held_by_current_thread (lock)); sema_down (&lock->semaphore); lock->holder = thread_current (); } -
lock 에대한 요청이 들어오면 sema_down 에서 멈췄다가 lock 이 사용가능하게 되면 자신이 lock 을 선점하는 것을 볼 수 있다. sema_down 을 기점으로 이전은 lock 을 얻기 전, 이후는 lock 을 얻은 후이다. sema_down 에 들어가기 전에 lock 을 가지고 있는 스레드에게 priority 를 양도하는 작업이 필요하다.
/* thread/synch.c */ void lock_acquire (struct lock *lock) { ASSERT (lock != NULL); ASSERT (!intr_context ()); ASSERT (!lock_held_by_current_thread (lock)); struct thread *cur = thread_current (); if (lock->holder) { cur->wait_on_lock = lock; list_insert_ordered (&lock->holder->donations, &cur->donation_elem, thread_compare_donate_priority, 0); donate_priority (); } sema_down (&lock->semaphore); cur->wait_on_lock = NULL; lock->holder = cur; } -
lock->holder 는 현재 lock 을 소유하고 있는 스레드를 가르킨다. 현재 lock 을 소유하고 있는 스레드가 없다면 바로 해당 lock 을 차지하고 lock 을 누군가 소유하고 있다면 그 스레드에게 priority 를 넘겨주어야 한다. 여기서 한 가지 알아야 할 점은, 현재 lock_acquire() 를 요청하는 스레드가 실행되고 있다는 자체로 lock 을 가지고 있는 스레드보다 우선순위가 높다는 뜻이기 때문에 if (cur->priority > lock->holder->priority) 등의 비교 조건은 필요하지 않다.
-
lock 을 점유하고 있는 스레드(holder) 가 있다면 현재 스레드의 wait_on_lock 에 lock 을 추가하고 holder 의 donations 리스트에 현재 스레드를 추가하고 priority donation 을 실행한다. thread_compare_donate_priority 함수는 thread_compare_priority 의 역할을 donation_elem 에 대하여 하는 함수이다.
/* thread/thread.c */ bool thread_compare_donate_priority (const struct list_elem *l, const struct list_elem *s, void *aux UNUSED) { return list_entry (l, struct thread, donation_elem)->priority > list_entry (s, struct thread, donation_elem)->priority; } -
donate_priority () 함수는 뒤에서 살펴보기로 하고, sema_down 이후에는 현재 스레드가 lock 을 차지한 상태이므로 wait_on_lock 을 NULL 로 만들어주고 lock->holder 를 현재 스레드로 만들어준다.
donate_priority ()
- 이 함수는 자신의 priority 를 필요한 lock 을 점유하고 있는 스레드에게 빌려주는 함수이다. 한 가지 주의할 점은, nested donation 에서 살펴본 것처럼 하위에 연결된 모든 스레드에 donation 이 일어난다는 것이다.
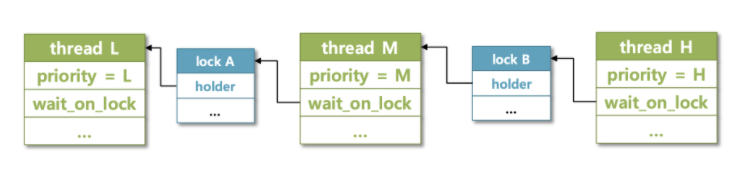
-
위에서 살펴본 위와 같은 상황에서 H 는 M 에게 전달하고 M 은 이 priority 를 다시 L 에게 전달하여서 L 이 우선적으로 실행될 수 있도록 한다.
/* thread/thread.c */ void donate_priority (void) { int depth; struct thread *cur = thread_current (); for (depth = 0; depth < 8; depth++){ if (!cur->wait_on_lock) break; struct thread *holder = cur->wait_on_lock->holder; holder->priority = cur->priority; cur = holder; } } -
구현은 간단하게 가능하다. depth 는 nested 의 최대 깊이를 지정해주기 위해 사용했다(max_depth = 8). 스레드의 wait_on_lock 이 NULL 이 아니라면 스레드가 lock 에 걸려있다는 소리이므로 그 lock 을 점유하고 있는 holder 스레드에게 priority 를 넘겨주는 방식을 깊이 8의 스레드까지 반복한다. wait_on_lock == NULL 이라면 더 이상 donation 을 진해할 필요가 없으므로 break 해준다. 여기까지 구현이 됐다면 priority 의 양도는 성공적으로 수행된다.
lock_release (struct lock *lock)
-
다음은 스레드가 priority 를 양도받아 critical section 을 마치고 lock 을 반환할 때의 경우를 만들어주어야 한다. 우선 현재 lock_release() 함수가 어떻게 생겼는지 확인해보자.
/* thread/synch.c */ void lock_release (struct lock *lock) { ASSERT (lock != NULL); ASSERT (lock_held_by_current_thread (lock)); lock->holder = NULL; sema_up (&lock->semaphore); } -
현재는 그냥 lock 이 가진 holder 를 비워주고 sema_up 하여주는 게 전부이다. sema_up 하여 lock 의 점유를 반환하기 전에 현재 이 lock 을 사용하기 위해 나에게 priority 를 빌려준 스레드들을 donations 리스트에서 제거하고, priority 를 재설정 해주는 작업이 필요하다.
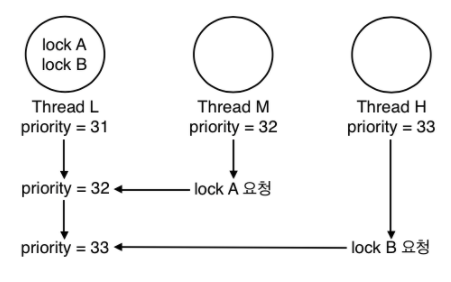
-
다시 한 번 위 그림을 예로 들어보면, thread L 에서 lock_release(lock B) 를 실행하면 lock B 를 사용하기 위해서 priority 를 나누어 주었던 Thread H 는 이제 priority 를 빌려줘야 할 이유가 없으므로 donations 리스트에서 Thread H 를 지워주어야 한다. 그 후 Thread H 가 빌려주던 33 이라는 priority 를 지우고 Thread L 의 priority 를 다시 정해주어야 하는데, 이 때 남아있는 donations 리스트에서 가장 높은 priority 를 가지고 있는 스레드의 priority 를 받아서 Thread L 의 priority 로 설정해준다. 만약 더 이상 donations 리스트에 남아있는 스레드가 없다면 원래 값인 init_priority 로 priority 를 설정해주면 된다. 우선 donations 리스트에서 스레드들을 지우는 함수를 만들어보자.
/* thread/thread.c */ void remove_with_lock (struct lock *lock) { struct list_elem *e; struct thread *cur = thread_current (); for (e = list_begin (&cur->donations); e != list_end (&cur->donations); e = list_next (e)){ struct thread *t = list_entry (e, struct thread, donation_elem); if (t->wait_on_lock == lock) list_remove (&t->donation_elem); } } -
cur->donations 리스트를 처음부터 끝까지 돌면서 리스트에 있는 스레드가 priority 를 빌려준 이유, 즉 wait_on_lock 이 이번에 release 하는 lock 이라면 해당하는 스레드를 리스트에서 지워준다. 이 때 <list/kernel/list.c> 에 구현되어 있는 list_remove 함수를 사용하였다. 모든 donations 리스트와 관련된 작업에서는 elem 이 아니라 donation_elem 을 사용하여야 함을 명심하자. 다음은 priority 를 재설정하는 함수를 보자.
/* thread/thread.c */ void refresh_priority (void) { struct thread *cur = thread_current (); cur->priority = cur->init_priority; if (!list_empty (&cur->donations)) { list_sort (&cur->donations, thread_compare_donate_priority, 0); struct thread *front = list_entry (list_front (&cur->donations), struct thread, donation_elem); if (front->priority > cur->priority) cur->priority = front->priority; } } -
donations 리스트가 비어있다면 init_priority 로 설정되고 donations 리스트에 스레드가 남아있다면 남아있는 스레드 중에서 가장 높은 priority 를 가져와야 한다. priority 가 가장 높은 스레드를 고르기 위해 list_sort 를 사용하여 donations 리스트의 원소들을 priority 순으로 내림차순 정렬한다. 그 후 맨 앞의 스레드(priority 가 가장 큰 스레드)를 뽑아서 init_priority 와 비교하여 둘 중 더 큰 priority 를 적용한다. 이제 새로 만든 함수들로 lock_release() 함수를 완성하여 보자.
/* thread/synch.c */ void lock_release (struct lock *lock) { ASSERT (lock != NULL); ASSERT (lock_held_by_current_thread (lock)); remove_with_lock (lock); refresh_priority (); lock->holder = NULL; sema_up (&lock->semaphore); } -
단순히 두 함수를 추가하기만 하면 된다.
-
한 가지 생각하여야 하는 상황이 더 있다. 만약 현재 진행중인 running thread 의 priority 변경이 일어났을 때 (이 경우 init_priority 의 변경을 의미한다.) donations 리스트들에 있는 스레드들보다 priority 가 높아지는 경우가 생길 수 있다. 이 경우 priority 는 donations 리스트 중 가장 높은 priority 가 아니라 새로 바뀐 priority 가 적용될 수 있게 해야 한다. 이는 thread_set_priority 에 refresh_priority() 함수를 추가하는 것으로 간단하게 가능하다.
/* thread/thread.c */ void thread_set_priority (int new_priority) { thread_current ()->init_priority = new_priority; refresh_priority (); thread_test_preemption (); }
결과

저번에 fail 을 받았던 priority 관련 테스트들을 순식간에 모두 통과하였다! (condition variable 제외) 생각보다 많이 복잡하고 시간도 오래 걸렸지만 그만큼 뿌듯한 마음도 크다. 앞으로도 화이팅!
