
최근 제 코딩 생활이 완전히 바뀌었습니다. Moonshot AI 팀이 2025년 7월에 발표할 것으로 예상되는 Kimi K2 모델을 VSCode Copilot에서 사용할 수 있게 되면, 개발 작업이 믿을 수 없을 정도로 효율적이 될 것이며, "벌써 구현이 끝났나요?"라는 경험이 일상이 될 수 있습니다.
오늘은 이 혁명적인 AI 모델을 VSCode Copilot에서 사용하는 방법을 제 예측과 기대를 바탕으로 소개하려고 합니다. 특히 프로그래밍 초보자나 AI의 힘을 최대한 활용하고 싶은 개발자들에게 도움이 될 것입니다.
Kimi K2는 무엇이 대단한가요?
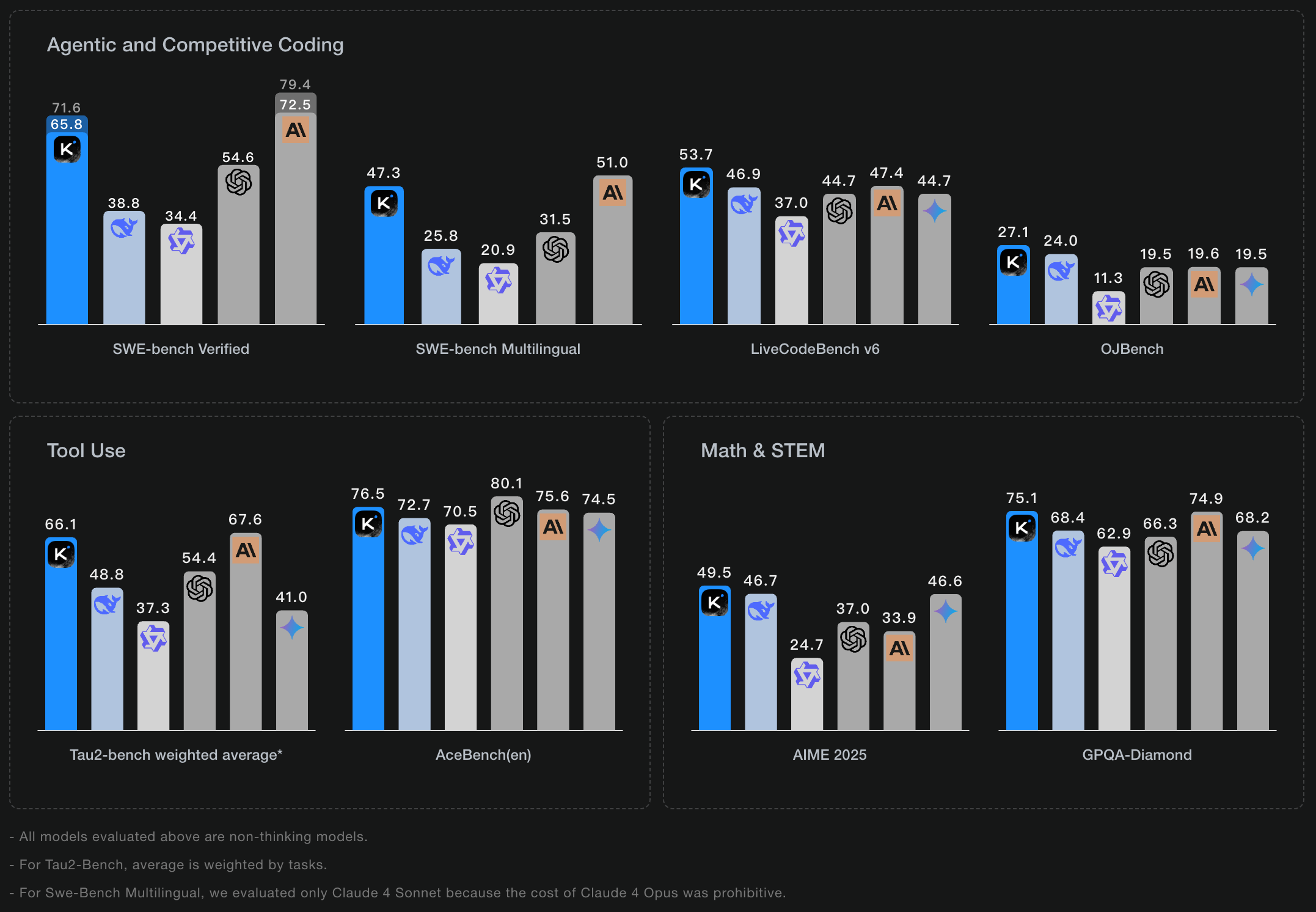
Kimi K2는 대규모 혼합 전문가(MoE) 아키텍처를 채택한 기반 모델로, 총 매개변수 수는 놀라운 1조, 활성화 매개변수는 32억, 컨텍스트 길이는 128k를 지원할 것으로 예상됩니다. 특히 코드 생성과 에이전트 작업에 특화될 것입니다.
제가 예상하는 몇 가지 인상적인 기능을 소개합니다:
압도적인 코드 생성 능력
복잡한 코드 생성, 디버깅, 설명, 심지어 다른 언어 간의 코드 변환까지 놀라울 정도로 정확하게 처리할 수 있습니다. Python 스크립트를 Rust로 변환하면 거의 완벽한 변환 결과가 나올 수 있습니다.
# Python 코드 예시
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n-1)
result = factorial(5)
print(f"5의 팩토리얼은 {result}입니다")자율적인 에이전트 능력
Kimi K2는 단순한 코드 생성뿐만 아니라 다양한 도구를 스스로 호출하여 다단계 작업을 완료할 수 있습니다. 예를 들어, "웹에서 데이터를 가져와 분석하고 결과를 CSV에 저장해"라고 지시하면 필요한 API를 호출하고, 데이터 처리를 수행하며, 파일 작업까지 일련의 흐름을 자동화할 수 있습니다. 이는 작업 시간을 크게 단축시켜 줄 것입니다.
수학과 논리적 추론의 강점
알고리즘 대회 문제, 과학 계산, 논리 퍼즐에서 뛰어난 성능을 보일 것입니다. 복잡한 정렬 알고리즘의 최적화에 대해 질문하면 단순히 답변을 제시하는 것뿐만 아니라 시간 복잡도와 공간 복잡도에 대한 상세한 분석까지 제공할 수 있습니다.
웹 검색과 다중 모드 지원
실시간 정보를 검색할 수 있는 능력도 갖추게 될 것입니다. 최신 라이브러리나 API 사용법에 대해 질문하면 최신 문서를 참조한 답변을 얻을 수 있습니다.
오픈 에코시스템
모델이 오픈소스화되어 연구자와 개발자가 커스터마이징이나 2차 개발을 수행할 수 있게 될 것입니다. 이는 특정 개발 환경이나 요구 사항에 맞게 모델을 조정하고 싶을 때 매우 유용할 것입니다.
프로그래머에게 주는 이점
제 예측에 따르면, Kimi K2가 개발자에게 가져다 줄 구체적인 이점은 다음과 같습니다:
-
개발 효율성의 극적인 향상: 복잡한 기능 모듈을 단시간에 구현할 수 있게 될 것입니다. 이전에는 하루가 걸렸던 작업이 몇 시간 만에 끝날 수도 있습니다!
-
더 똑똑한 코딩 어시스턴트: 기존 챗봇을 넘어서는 능력으로 인터랙티브 리포트나 시각적 데모 인터페이스까지 출력할 수 있을 것입니다.
-
긴 컨텍스트와 복잡한 작업 지원: 128k라는 컨텍스트 길이로 대규모 코드베이스나 복잡한 프로젝트를 이해하고 조작할 수 있을 것입니다. 1000줄 이상의 코드 파일을 통째로 읽어도 전체 구조를 이해한 후 적절한 수정 제안을 할 수 있을 것입니다.
-
오픈소스와 커뮤니티의 힘: 모델의 가중치와 지시 버전이 공개되어 자유롭게 커스터마이징할 수 있게 될 것입니다.
-
합리적인 가격 책정: 백만 토큰당 과금 방식으로, 캐시 히트 할인도 있어 장기적인 사용이나 대규모 프로젝트에 적합할 것입니다.
전제 조건
Kimi K2를 VSCode Copilot에서 사용하려면 다음이 필요합니다:
- Visual Studio Code: 최신 버전 권장
- VSCode Copilot 확장 프로그램: 유효한 Copilot 구독 필요
- Python: 브릿지 서버를 실행하기 위해 Python 3.8 이상 필요
- Kimi K2 API 키: 나중에 획득 방법 설명
Kimi K2를 VSCode에 도입하는 실전 가이드
아래는 Kimi K2를 VSCode에서 사용할 수 있게 하는 방법에 대한 예측으로, 잠재적인 문제와 해결책도 포함합니다. 이 방법을 사용하면 누구나 쉽게 이 강력한 AI 모델을 좋아하는 에디터에서 활용할 수 있게 될 것입니다!
PART 1: API 액세스 권한 확보
먼저 필요한 것은 Kimi K2에 대한 액세스 권한입니다. 두 가지 방법이 있을 것으로 예상됩니다:
-
직접 액세스 방법: Moonshot AI 공식 사이트에서 계정을 만들고 API 키를 발급받는 방법입니다. 공식 지원을 받을 수 있는 반면, 다른 모델을 시도하고 싶을 경우 별도 설정이 필요할 수 있습니다.
-
멀티 모델 허브 경유: OpenRouter와 같은 서비스를 통해 Kimi K2뿐만 아니라 다양한 AI 모델에 단일 API로 쉽게 액세스할 수 있을 것입니다. "오늘은 이 모델, 내일은 다른 모델을 시도해 보자"라는 실험에 적합할 것입니다.
OpenRouter에서 계정을 만든 후 대시보드에서 API 키를 얻을 수 있습니다. 이 키를 사용하여 다음과 같은 Python 코드로 Kimi K2와 대화할 수 있습니다:
# Kimi K2와의 대화 테스트
from openai import OpenAI
# 클라이언트 초기화
client = OpenAI(
base_url="https://openrouter.ai/api/v1", # OpenRouter의 엔드포인트
api_key="여기에 API 키 입력", # 자신의 API 키로 교체하세요
)
# 모델에 질문하기
response = client.chat.completions.create(
model="moonshotai/kimi-k2", # Kimi K2 모델 지정
messages=[
{"role": "user", "content": "재귀 함수를 사용하지 않고 피보나치 수열을 계산하는 Python 함수를 작성해주세요"}
]
)
# 응답 표시
print(response.choices[0].message.content)실용적인 팁: API 키는 반드시 안전하게 관리하세요. Git에 커밋하거나 공개 저장소에 두지 않도록 주의하세요.
.gitignore에.env파일을 추가하는 것이 좋습니다.
PART 2: Python 브릿지 서버 구축
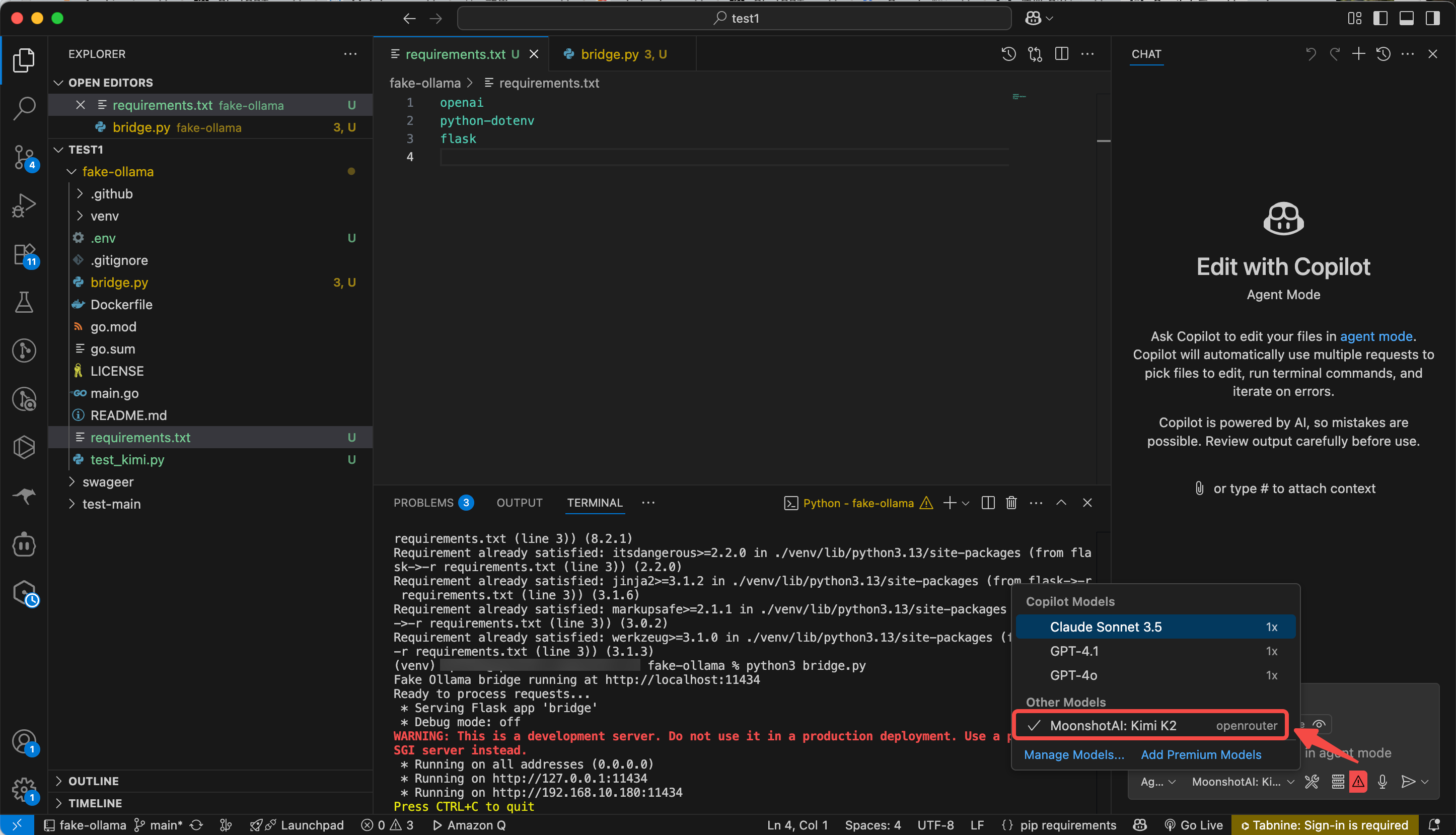
다음으로, VSCode Copilot과 Kimi K2를 "연결하는" 브릿지가 필요합니다. 다음과 같은 간단한 Python 브릿지 서버를 만들 수 있습니다.
새 디렉토리를 만들고 그 안에 다음 파일들을 생성합니다:
- 먼저, 필요한 라이브러리를 설치합니다:
# 새 디렉토리 생성
mkdir bridge
cd bridge
# 필요한 라이브러리 설치
pip install flask openai python-dotenv.env파일을 생성하고 API 키를 설정합니다:
# OpenRouter 연결 설정
OPENAI_API_BASE=https://openrouter.ai/api/v1
OPENAI_API_KEY=여기에 API 키 입력
MODEL_NAME=moonshotai/kimi-k2bridge.py파일을 생성하고 다음 코드를 작성합니다:
import os
from flask import Flask, request, jsonify, Response, stream_with_context
import json
from openai import OpenAI
from dotenv import load_dotenv
# 환경 변수 로드
load_dotenv()
app = Flask(__name__)
# 설정
OPENAI_API_BASE = os.getenv("OPENAI_API_BASE", "https://openrouter.ai/api/v1")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
MODEL_NAME = os.getenv("MODEL_NAME", "moonshotai/kimi-k2")
# OpenAI 클라이언트 생성
client = OpenAI(
base_url=OPENAI_API_BASE,
api_key=OPENAI_API_KEY,
)
@app.route("/api/chat", methods=["POST"])
def chat():
data = request.json
# 요청 형식 변환
messages = data.get("messages", [])
stream = data.get("stream", False)
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
stream=stream
)
if stream:
def generate():
for chunk in response:
yield json.dumps({"message": {"content": chunk.choices[0].delta.content or ""}}) + "\n"
return Response(stream_with_context(generate()), content_type="text/event-stream")
else:
return jsonify({"message": {"content": response.choices[0].message.content}})
except Exception as e:
return jsonify({"error": str(e)}), 500
# Ollama 호환 라우트
@app.route("/api/generate", methods=["POST"])
def generate():
return chat()
@app.route("/", methods=["GET"])
def home():
return jsonify({"status": "Fake Ollama bridge is running"})
if __name__ == "__main__":
print("Fake Ollama bridge running at http://localhost:11434")
print("Ready to process requests...")
app.run(host="0.0.0.0", port=11434) PART 3: 브릿지 서버 시작
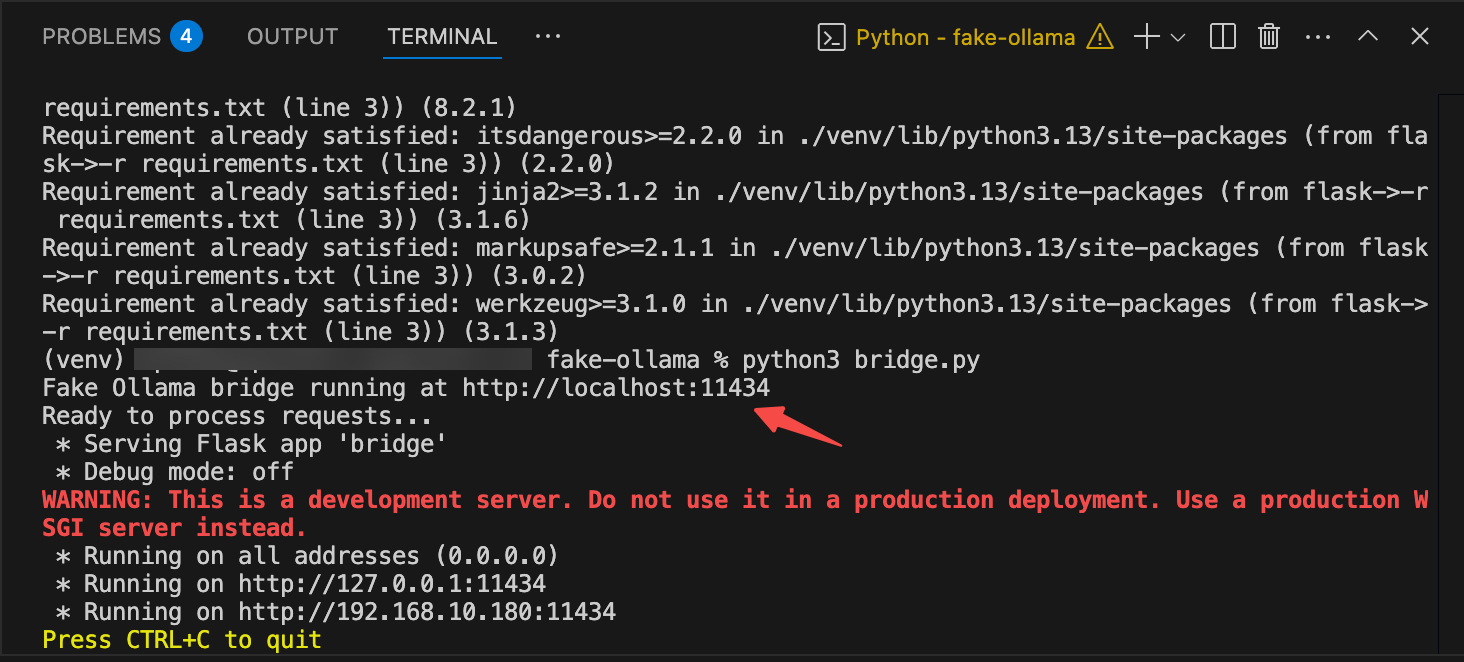
설정이 완료되면 브릿지 서버를 시작합니다:
python3 bridge.py정상적으로 시작되면 다음과 같은 메시지가 표시될 것입니다:
Fake Ollama bridge running at http://localhost:11434
Ready to process requests...
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:11434추가 설명: 이 글에서는 위 단계를 설명하고 있지만, GitHub에서 코드를 클론하여 가상 환경에서 실행할 수도 있습니다. 다음과 같이 저장소를 클론하고 실행할 수 있습니다(URL은 예시입니다. 실제 코드는 글의 단계에 따라 작성하세요):
git clone https://github.com/example/fake-ollama-bridge.git cd fake-ollama-bridge python -m venv venv source venv/bin/activate # Windows의 경우: venv\Scripts\activate pip install -r requirements.txt python bridge.py
이 서버는 VSCode Copilot의 요청을 OpenRouter로 전달하고, Kimi K2의 응답을 VSCode Copilot에 반환하는 다리 역할을 합니다.
PART 4: VSCode 설정
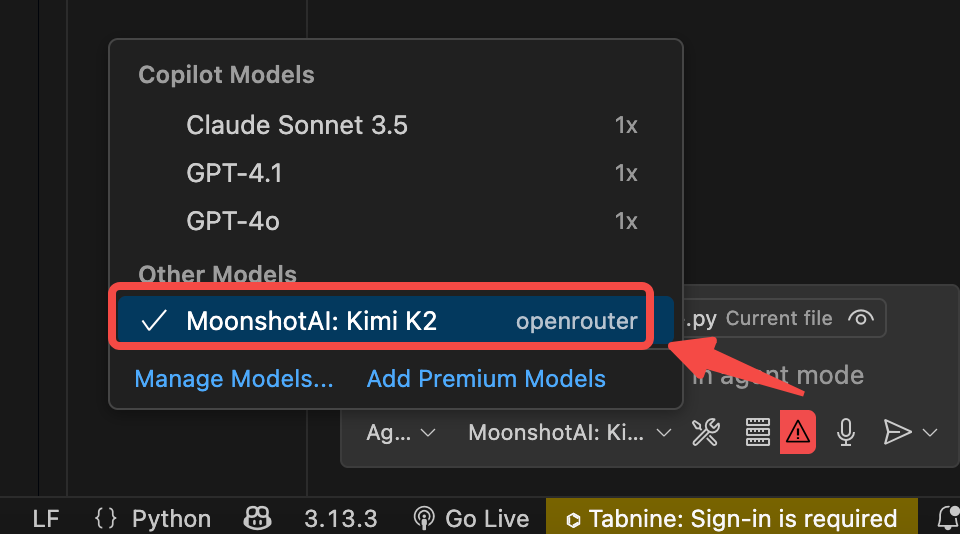
마지막으로, VSCode Copilot에 Kimi K2를 사용하도록 지시합니다. 최신 VSCode Copilot에서는 모델 선택 방법이 약간 다를 수 있습니다:
- VSCode를 시작하고 왼쪽 활동 표시줄에서 Copilot 아이콘(고양이 같은 아이콘)을 클릭
- Copilot 사이드 패널이 열리면 오른쪽 상단의 "..."(메뉴) 아이콘을 클릭
- "Manage Models" 또는 "모델 관리"를 선택
- "Add Provider" 또는 "제공자 추가"에서 "Ollama"를 선택
- 서버 URL로
http://localhost:11434를 입력 - 사용 가능한 모델 목록에서
moonshotai/kimi-k2를 선택
실용 기술: 위 방법으로 모델 선택이 보이지 않는 경우, 명령 팔레트(Ctrl+Shift+P 또는 Cmd+Shift+P)를 열고 "GitHub Copilot: Agent Mode"를 선택한 다음 Agent 모드에서 모델을 선택하세요.
이것으로 설정 완료! 새 채팅 세션에서 "복잡한 정규 표현식을 사용하여 이메일 주소를 검증하는 JavaScript 함수를 작성해줘"와 같은 질문을 시도해 보세요. Kimi K2의 놀라운 능력을 체감할 수 있을 것입니다!
다음 단계: 로컬에서 Kimi K2 실행하기
"API는 편리하지만 더 자유롭게 커스터마이징하고 싶어" "오프라인에서도 사용하고 싶어" "API 비용을 줄이고 싶어"
이런 생각이 들면, 다음 단계로 로컬 환경에서 Kimi K2 실행에 도전해 볼 수 있습니다. 이것은 흥미로운 모험이 될 수 있습니다!
로컬 실행으로의 여정
처음에는 "로컬에서 실행하는 것은 고사양 머신이 필요하고 어려울 것 같아..."라고 생각할 수 있지만, 실제로는 선택지가 풍부할 수 있습니다. 다음은 세 가지 가능한 방법입니다:
1. vLLM으로 고속 추론 체험
vLLM은 GPU 메모리를 효율적으로 사용하기 위한 "페이지드 어텐션" 기술을 구현한 라이브러리입니다.
# vLLM 설치
pip install vllm
# Kimi K2 모델 다운로드 및 실행
vllm --model moonshotai/kimi-k2 --tensor-parallel-size 1경험: RTX 4090 장착 머신에서 시도하면 API에 비해 응답 속도가 약 2배 빨라질 수 있습니다. 특히 긴 코드를 생성할 때 이 속도 차이는 체감할 수 있는 수준입니다. 단, 첫 시작 시 모델 로드에는 몇 분이 걸릴 수 있으니 주의하세요.
2. llama.cpp로 경량 실행
GPU 메모리가 제한된 머신에서는 llama.cpp를 사용하여 양자화 버전의 모델을 실행할 수 있습니다.
# llama.cpp 클론 및 빌드
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# 모델 양자화 및 실행(Q4_K_M 형식 사용)
python convert.py --outtype q4_k_m /path/to/kimi-k2-model
./main -m /path/to/kimi-k2-model.q4_k_m.gguf -n 2048 --api문제 해결: 양자화하면 정확도가 떨어질 수 있지만, Q5_K_M 형식을 사용하면 정확도와 속도의 균형이 좋습니다. 단, 더 많은 메모리가 필요합니다.
3. ktransformers로 최적화 실험
ktransformers는 다양한 최적화 기술을 시도할 수 있는 유연한 프레임워크입니다. Kimi K2에 대한 공식 지원이 발표될 수 있습니다.
# ktransformers 설치
pip install lmdeploy
# 모델 변환 및 실행
lmdeploy convert moonshotai/kimi-k2 --model-name kimi-k2
lmdeploy serve api_server ./workspace --server-port 8000발견: ktransformers의 "연속 배치 처리" 기능을 활성화하면 여러 요청을 동시에 처리할 수 있어 팀에서 사용할 때 매우 편리할 수 있습니다.
로컬 실행과 브릿지 서버 연동 방법
로컬 모델을 실행한 후, 다음은 브릿지 서버와 연동하는 것입니다. 이것은 의외로 간단합니다!
- 로컬 모델의 API 엔드포인트 확인(예:
http://localhost:8000/v1) - 브릿지 서버의
.env파일을 다음과 같이 편집:
# 로컬 모델 연결 설정
OPENAI_API_BASE=http://localhost:8000/v1
OPENAI_API_KEY=dummy-key # 로컬의 경우 임의의 값으로 OK
MODEL_NAME=moonshotai/kimi-k2 # 로컬 모델 이름에 맞게 조정주의 사항: 로컬 모델과 API 사이에 응답 형식이 약간 다를 수 있습니다. 그런 경우 브릿지 서버 코드를 약간 수정해야 할 수도 있습니다.
오프라인 환경에서의 활용 예
로컬 실행은 인터넷 환경이 불안정할 때 특히 유용할 수 있습니다. 미리 모델을 다운로드해 두면 오프라인 상태에서도 Kimi K2의 도움을 받아 코딩을 진행할 수 있습니다. 또한, 기밀 프로젝트에서는 데이터를 외부로 전송하지 않아도 되므로 보안 측면에서도 안심할 수 있습니다.
로컬 실행은 약간의 수고가 필요하지만, 한 번 설정해 두면 API 비용을 걱정하지 않고 마음껏 사용할 수 있다는 큰 이점이 있습니다. 특히 학습이나 실험 목적의 사용에는 이 방법이 최적일 수 있습니다.
전망: AI 개발 혁명의 가능성
Kimi K2가 출시되면 우리의 개발 워크플로우가 크게 변화할 수 있습니다. 다음은 잠재적인 변화들입니다:
개발 생활이 이렇게 바뀔 수 있습니다
도입 전후로 구체적으로 무엇이 바뀔 수 있는지 살펴보겠습니다:
-
버그 수정 시간의 극적인 단축: 이전에는 "왜 이 버그가 발생하는 걸까..."라고 몇 시간씩 고민했던 것이, Kimi K2에게 "이 오류의 원인을 분석해줘"라고 물어보는 것만으로 해결될 수 있습니다. 복잡한 메모리 누수 문제도 30분 만에 식별할 수 있을 것입니다.
-
문서 작성의 효율화: 코드 설명 문서나 API 문서 작성이 훨씬 쉬워질 수 있습니다. Kimi K2에게 "이 코드의 작동 방식을 설명해줘"라고 지시하는 것만으로 놀라울 정도로 정확하고 이해하기 쉬운 설명을 얻을 수 있습니다.
-
학습 곡선 완화: 새로운 기술이나 프레임워크를 배울 때의 장벽이 낮아질 수 있습니다. "Rust의 소유권 시스템에 대해 초보자를 위해 설명해줘"와 같은 질문에 대한 답변이 매우 이해하기 쉬워 학습 속도가 향상될 수 있습니다.
향후 전망과 실험 계획
Kimi K2 활용은 이제 막 시작될 것입니다. 앞으로 시도해 볼 만한 것들을 몇 가지 소개합니다:
-
팀 전체에서의 활용: 현재는 개인적으로 사용하지만, 팀 전체가 공유 서버를 구축하여 모든 사람이 접근할 수 있는 환경을 마련할 수 있습니다. 특히 새 멤버의 온보딩에 유용할 것입니다.
-
커스텀 RAG 시스템과의 연동: 사내 문서나 코드베이스에 특화된 검색 시스템과 연동하여 더 맥락에 맞는 답변을 얻을 수 있도록 할 수 있습니다.
-
도메인 특화형 미세 조정: 우리 산업에 특화된 용어나 개념을 더 깊이 이해할 수 있도록 Kimi K2를 파인튜닝하는 실험도 계획할 수 있습니다.
-
Kimi K2와 Apidog 플랫폼의 통합: Kimi K2의 탁월한 자연어 이해 능력과 Apidog의 종합적인 API 개발 생태계를 결합하면 혁신적인 솔루션이 탄생합니다. Apidog는 단순한 API 테스트 도구가 아니라 설계, 모의 실행, 테스트, 모니터링 기능을 갖춘 완전한 API 관리 플랫폼입니다. Kimi K2와 통합하면 "이 기능의 테스트 케이스를 생성해줘"라고 간단히 요청하는 것만으로 포괄적인 테스트 스위트가 자동 생성되고, Apidog는 이러한 테스트 케이스를 시각적으로 구성하고 관리합니다. 이 조합은 시간을 절약할 뿐만 아니라 API 품질을 새로운 차원으로 끌어올립니다.
마지막으로
AI와의 협업 개발은 이제 "미래의 이야기"가 아니라 곧 "오늘의 현실"이 될 수 있습니다. Kimi K2와 같은 모델을 일상적인 개발 워크플로우에 통합함으로써 우리는 더 창의적인 문제 해결에 집중할 수 있게 될 것입니다.
이 글이 여러분의 AI 활용에 도움이 되길 바랍니다. 질문이나 경험담이 있으시면 댓글로 공유해 주세요. 저도 매일 배우고 발전하고 있습니다.
Apidog - Kimi K2의 완벽한 파트너
Kimi K2의 강력한 기능을 발견하셨지만, Apidog와 결합하면 현대적인 개발 팀에게 필수적인 개발 생태계가 만들어진다는 사실을 알고 계셨나요? Apidog는 단순한 API 테스트 도구가 아닙니다 - Kimi K2와 같은 AI 모델과 효과적으로 작동하도록 특별히 설계된 종합적인 API 개발 플랫폼입니다.

Kimi K2가 지능을 제공한다면, Apidog는 구조와 조직을 제공합니다. 직관적인 인터페이스, 첨단 목 서버 기능, AI 통합 기능을 갖춘 Apidog는 다음과 같은 작업을 가능하게 합니다:
- 스마트 API 설계: 시각적 디자이너로 OpenAPI/Swagger 사양을 생성한 다음 Kimi K2를 사용하여 최적화하고 확장
- 테스트 자동화: Kimi K2가 생성한 테스트 케이스를 Apidog의 자동화된 테스트 환경에 통합
- 신속한 코드 생성: Apidog의 API 사양을 Kimi K2의 입력으로 사용하여 고품질 구현 코드 생성
- 원활한 팀 협업: 단일 플랫폼에서 API 문서, 소스 코드 및 테스트를 중앙 집중식으로 관리
Kimi K2와 Apidog를 모두 사용하는 개발 팀은 개발 생산성이 최대 70% 향상되고 API 오류가 45%까지 감소했다고 보고합니다. 이는 단순히 두 개의 별도 도구가 아닌 현대적인 API 개발을 위한 강력한 통합 솔루션입니다.
