머리말
2024년의 시작과 함께, 2022년 1학기에 수강했던 COSE213(자료구조) 강의를 복습해보려고 한다. 강의를 수강한 이후로 PS를 꾸준히 하지 않았기에, 자료 구조에 대한 지식이 많이 휘발되어 있어 복습을 하기로 했다.
이 이후에는 꾸준히 PS 및 복습을 하며, 자료구조를 기억에 더욱 탄탄히 남겨두어야겠다.
이번 주의 자료구조
NULL
Introduction to Data Structure
1. Program, Data Structure, and Algorithm
1-1. Program
프로그램이란 무엇일까? 우리가 사용하는 컴퓨터 또는 모바일 기기에서 실행시킬 수 있는 앱일까?
엄밀히 정의하자면, 우리가 앱을 사용할 때는 program이 실행 되고 있는 것이 아니라 process가 실행 되고 있는 것이다. 하드디스크에 저장되어 있는 program이 메모리에 올라와 실행되는 것을 process 라고 하고, 운영체제에서는 job scheduling 의 단위를 뜻한다.
자세한 내용은 Operating System(운영체제) 에서 다루도록 하고, 지금은 자료구조에만 집중하자.
우선, 위키 백과에서는 프로그램을 다음과 같이 정의하였다.
프로그램이란, 컴퓨터에서 실행될 때 특정 작업(specific task)을 수행하는 일련의 '명령어들의 모음(집합체)'
- 위키백과
프로그램의 정의에 대해서는 다양한 컴퓨터 전공적 관점(운영체제 또는 컴퓨터 구조 등)에서 해석해볼 수 있지만, 자료구조가 다루는 '자료(data)'의 관점에서는 다음과 같이 해석할 수 있다.
프로그램이란, 데이터를 표현하고 처리하는 것 이다.
이 때 데이터를 표현하는 것에 자료 구조,
데이터를 처리하는 것에 알고리즘을 활용한다.
즉, 자료구조는 프로그램을 다루기 위해 필수적으로 알아야 할 내용이다.
프로그램을 통해 Problem Solving을 하는 경우를 생각해보자.
문제 해결의 과정을 순서로 정리해보면 다음과 같다.
- 문제 도출 - 문제를 명확히 정의한다.
- 문제 변환 - 처리 대상을 결정한 후 적절한 자료를 정의한다.
- 실행 - 프로그램을 번역 및 실행한 후, 실행 결과를 확인한다.
- 결과 - 결과를 통해 문제의 해답을 도출한다.
- 처리 방식을 결정한 후 적절한 알고리즘을 작성한다.
- 작성한 알고리즘 및 자료 정의를 바탕으로 프로그램을 작성한다.
1-2. Data Structure
Data란 무엇일까? '정보' 또는 '자료'라고도 불리는 data는 다음과 같이 크게 2종류로 나누어 볼 수 있다.- Atomic data(Scalar data)
: 단일 정보로 구성된 data
- A single piece of information.
- Cannot divided into other meaningful pieces of data. Ex) integer 4562 (단일 data type)
- Composite data
: 합성 정보로 구성된 data
- Can be broken out into subfields that have meaning. Ex) telephone number 02-3290-1114 (data type의 합성)
Data Type
Data type은 연산과 data 집합의 두 파트로 구성되어 있다.- A set of data : data type이 취할 수 있는 모든 가능한 values.
- The operations : data에 수행할 수 있는 연산.
따라서 Data type에 대한 정의는 다음과 같이 할 수 있다. 아래는 대표적인 data type 3종류이다.
| Type | Values | Operations |
|---|---|---|
| integer | -∞, ..., -2, -1, 0, 1, 2, ..., ∞ | *, +, -, %, /, ++, --, ... |
| floating point | -∞, ..., 0.0, ..., ∞ | *, +, -, /, ... |
| character | \0, ..., 'A', 'B', ..., 'a', 'b', ..., ~ | <, >, ... |
Data Structure
이제 우리는 데이터가 무엇인지, 데이터는 어떤 종류가 있는지 알고 있다. 그렇다면 data structure란 무엇일까?이에 앞서 Structure란, "a set of rules that hold the data together." 를 의미한다. 즉, data sturcture는 엄밀히 다음과 같이 정의할 수 있다.
Aggregation of atomic and composite data into set with defined relationships.
대표적인 data structure로는
- 동종의 데이터 sequence를 묶는 규칙, Array
- 이종의 데이터 combination을 묶는 규칙, Sequence
가 존재하며 그 정의는 아래와 같다.
| Array | Record |
|---|---|
| Homogeneous sequence of data or data types known as elements | Heterogeneous combination of data into a single struture with an identified key |
| Position association among the elements | No association |
- Most of the programming languages support several data structures.
- In addition, mordern programming languages allow programmers to create new data structures for an application.
- Data structures can be nested.
Abstract Data Type (추상 자료형)
Data type에는 '추상 자료형' 이라는 개념이 존재한다. ADT라고도 축약해서 불리는 추상 자료형이란 무엇일까?대개 어떤 것에 대해 잘 이해하기 어려울 때는, 반대 개념을 함께 생각해보면 도움이 된다. 그럼, 구체적인 자료형은 무엇일까? 구체적이라는 것은 무엇을 뜻하는 걸까?
'추상화'와 '구체화'에 대해 다음과 같이 정의해보자.
- 추상화 : "무엇(what)인가?"를 논리적(logically)으로 정의하는 것.
- 구체화 : "어떻게(how)할 것인가?"를 실제적(practically)으로 표현하는 것.
그럼 추상 자료형은 자료형(데이터와 그 연산자)의 특성 대해 논리적으로 추상화하여 정리한 자료형이라고 생각해볼 수 있다. 아직 감이 잘 오지 않을 수 있는데, 이는 ADT의 특성에 대한 정의를 통해 보충해보자.
- ADT users are NOT concerned with how the task is done but what it can do.
- An abstract data type is data declaration packaged together with the operations that are meanigful for the data type.
- We encapsulate the data and the operations on the data, and then hide them from the user.
- All referneces to and manipulation of the data in a data structure are handled through defined interfaces to the structure.
위 내용을 통해 정리해보면 추상 자료형이란 실제적인 data type의 구현 및 작동은 추상화를 통해 감추고, 데이터 타입이 가진 논리적인 기능 및 특성에 집중한 데이터 타입을 의미한다. ADT user는 내부적인 구조나 구현 방법은 몰라도, interface를 통해 해당 데이터 타입을 사용할 수 있다.
[+] 좋은 코드란 무엇인가? 라고 물어보았을 때, 2023-02학기에 수강한 프로그래밍 언어 강의에서 교수님께서 이해가 잘 되는, 즉, '추상화가 잘 되어 있는' 코드라고 하셨다. 추상화 이야기를 하다보니 갑자기 떠올랐다.
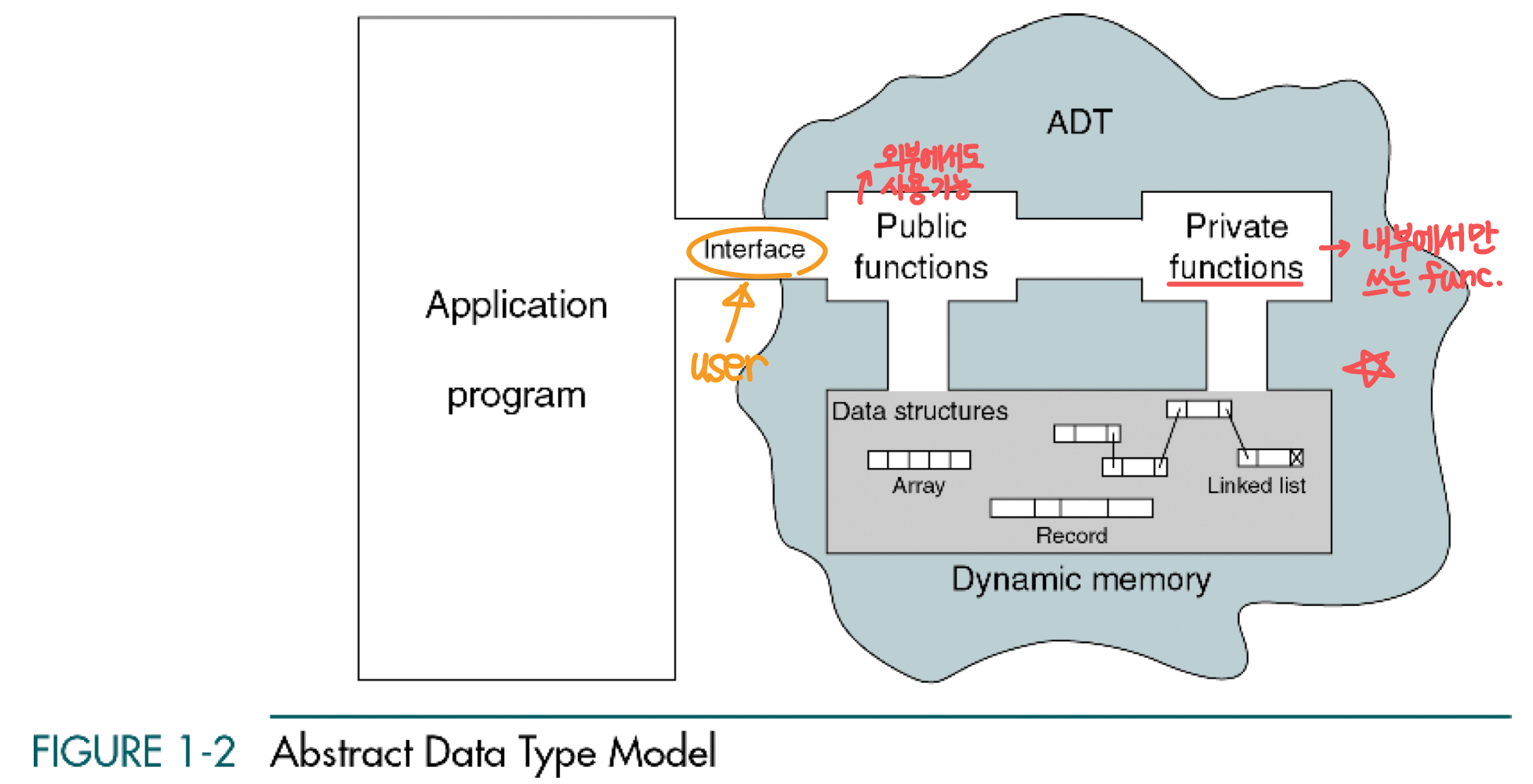
[ADT model]
Abstraction Data Type의 Model을 그림으로 나타내면 아래와 같다.
- Data는 오직 외부 인터페이스를 통해서만 다룰 수 있다.
- Only the public functions are accessible through this interface.
[Typical ADTs]
우리가 흔히 아는 자료구조인 List, Stacks, ...가 바로 ADT이다. 아래는 전형적인 ADT들의 종류이다
- Lists
- Stacks
- Queues
- Trees (Binary Search tree, AVL tree, B-tree, ...)
- Heaps
- Graphs
[ADT Implementations]
앞서 ADT는 자료형의 특성에 대해 논리적으로 추상화 하여 정리한 자료형으로, 내부 구현이나 구조에 신경을 쓰지 않는 부분이라고 설명했다.
결국 ADT를 사용하기 위해선 구현이 필요할텐데, Implementaion은 어떻게 이루어지는 것일까?
ADT list를 대표로 알아보자. ADT list는 array와 linked list를 통해 구현할 수 있는 추상 자료형이다.
There are two basic structures we can use to implement an ADT list : arrays and linked lists
-
Array Implementaion
배열 자체의 특성을 알아보자. 배열은 순차성으로 인해 삽입 및 삭제 시 shif를 수행해야 하므로 연산이 복잡하고 비용이 높다. 따라서 리스트가 frequently changes할 때는 seldom하게 사용된다. 그러나, 탐색에 있어서는 O(1)의 복잡도를 가져 용이하다.- In an array, the sequentiality of a list is maintained by the order structure of elements in the array (indexes).
- Although searching an array for an individual element can be very efficient,
- Insertion and deletion of elements are complex and inefficient process.
-
Linked list case
연결 리스트 자체의 특성을 알아보자. 연결 리스트는 data를 담고 있는 부분과, data와의 연결 관계를 담고 있는 n개의 link 부분으로 구성되어 있다. 각 element는 다음 element(s)의 위치를 pointing하고 있다. 데이터의 조회에 있어서는 O(n)의 복잡도를 가지지만, 삽입 및 삭제에 있어서는 O(1)의 복잡도를 가진다.- A Linked List is an ordered collection of data in which each element contains the location of the next element or elements.
- In a linked list, each element contains two parts : data and one or more links.
- The data part holds the application data - the data to be processed.
- Linkes are used to chain the data together. They contain pointers that identify the next element or elements in the list.
- In linear linked lists, each element has onlt zero or one succesor.
- In non-linear linked lists, each element can have zero, one or more successors. Ex) Trees, Graphs, ...
그럼 Linked list와 Array 중에 어떤 것으로 ADT를 Implementation하는 것이 좋을까? 각각의 장단점을 비교해보면 아래와 같다.
- Linked list의 major advantage(over the array)는 data의 insert와 delete가 간편하다는 것이다.
: 즉, 새로운 데이터를 삽입하거나 삭제 후의 공간을 위해 element들을 shif하는 과정이 불필요하다는 큰 장점이 존재한다. - 다만, Linked list에서는 element들이 더 이상 physically sequenced되어 있지 않기에, 탐색 방법이 순차 탐색(sequential search)으로 한정된다는 한계가 있다.
Nodes
자료 구조나 알고리즘 등, Computer Science 전공을 듣다 보면 'Node' 라는 용어가 자주 등장한다. 자료 구조 관점에서의 node는 다음과 같이 정의된다.A node is a structure that has two parts : the data and one or more links.
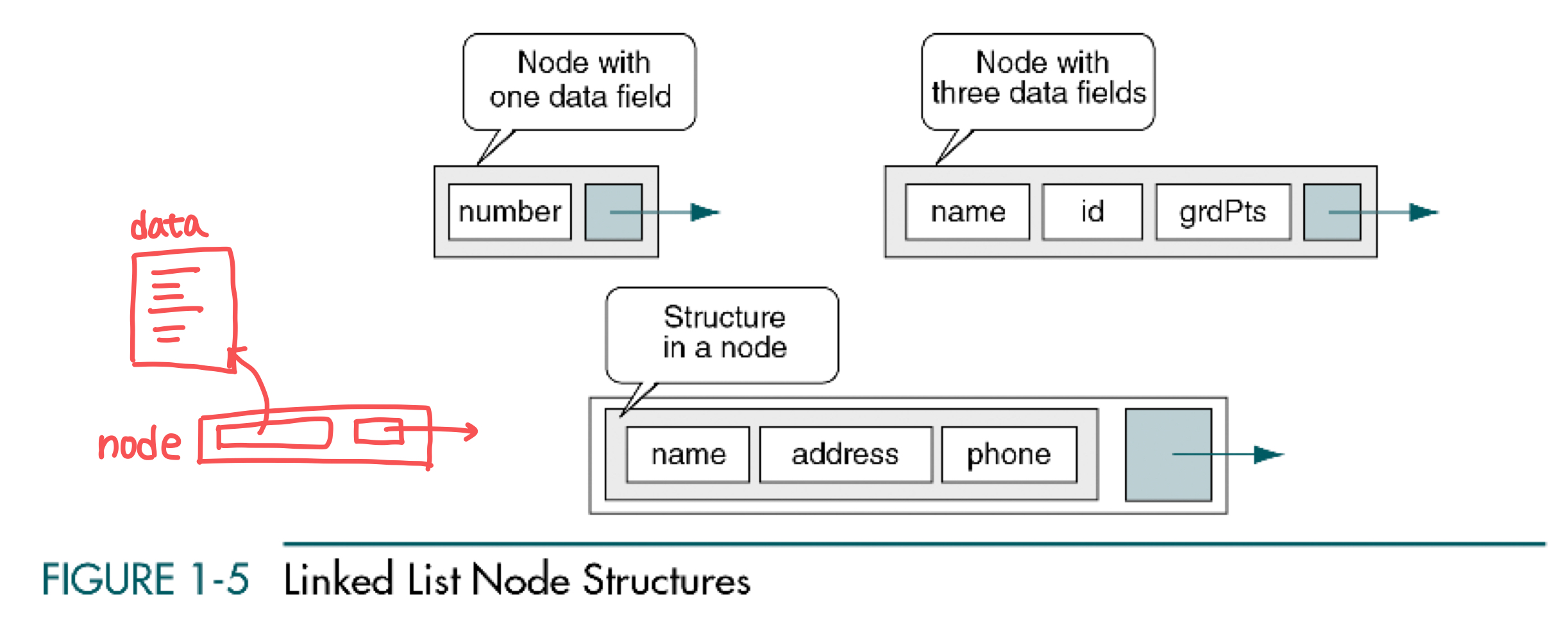
Node의 data part는 single field일 수도, multiple field일 수도, 여러 field를 가지고 있는 structure일 수도 있다. 다만 이들은 단일 field인 것처럼 act한다.
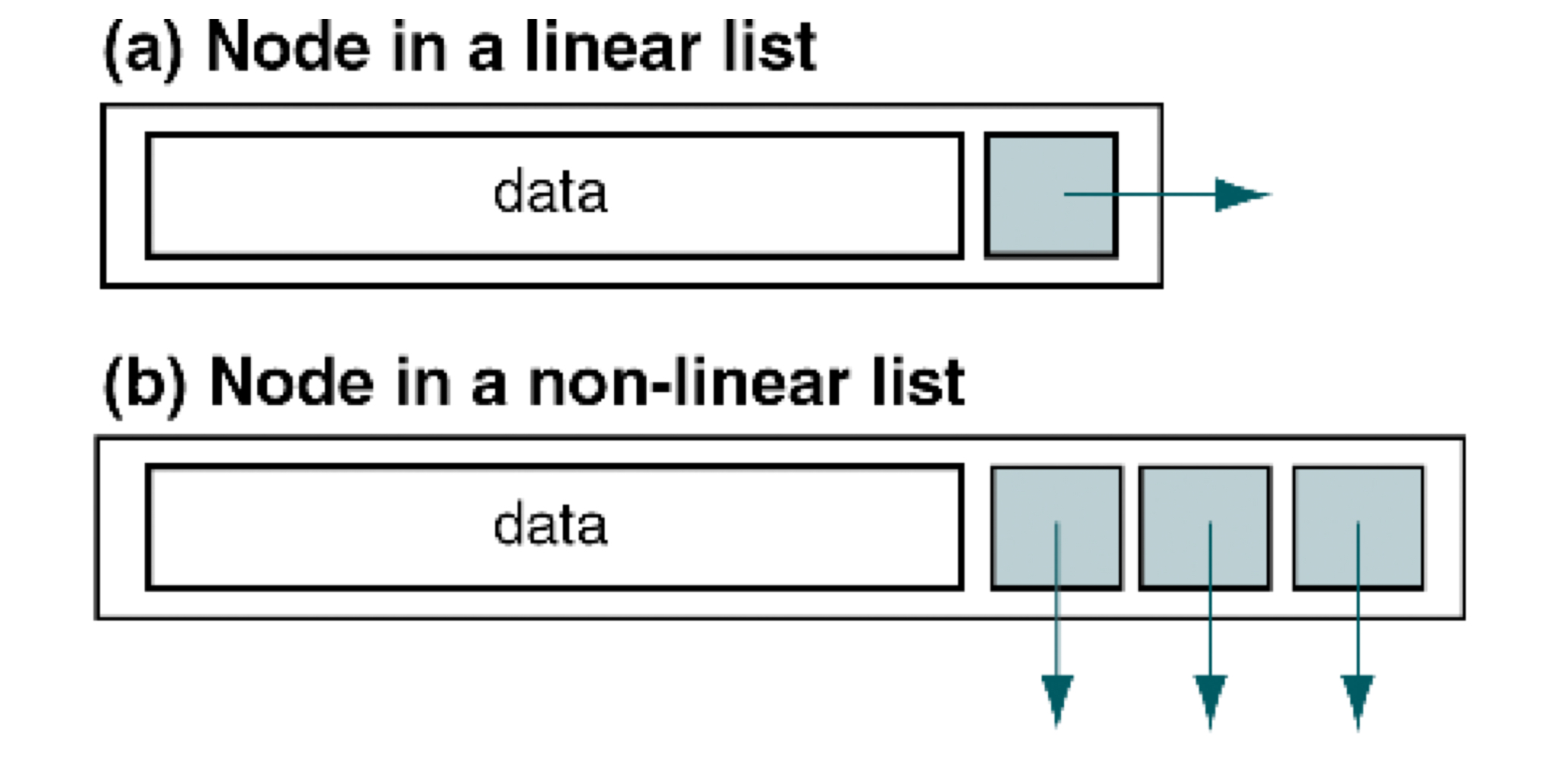
Linked list에서의 nodes는 self-referential structure(자기 참조 구조)라고 불린다. 이는 structure의 각 instance가 같은 structural type을 가지는 다른 instance에 대한 하나 이상의 포인터를 가짐을 의미한다.
1-3. Algorithm
'자료(data)'의 관점에서 Algorithm이란 무엇일까?1-1. Program 에서도 정의했듯, 데이터를 처리하는 '방식'을 의미한다.
Problem Solving에서는 주어진 문제에 대해 적절한 알고리즘의 선정이 중요하다. 이는 어떤 알고리즘을 적용하냐에 따라 Space Complexity, Time Complexity가 달라지기 때문이고, 효율적이고 체계적인 프로그래밍을 위해서는 알고리즘을 잘 설계하고 구현하는 능력이 중요하다.
그러나 이 게시물은 Data Structure(자료구조) 가 주가 되는 글이므로, 다양한 알고리즘의 종류 등 자세한 내용은 Algorithm(알고리즘) 에서 다루도록 하고, 지금은 자료구조에 대한 내용에 집중하자.
알고리즘 표현 방법
알고리즘의 표현 방법은 크게 4가지가 존재한다.- 자연어 (natural language) : 인간의 언어로 표현하며, 자연어가 가진 중의성 등으로 인해 일관성이나 명확성을 유지하기 어렵다.
- 순서도 (flow chart) : 시각적으로 효과적인 이해가 가능하나, 복잡한 알고리즘을 표현하는 데 한계가 있다.
- 프로그래밍 언어 (programming language) : 특정 프로그래밍 언어로 작성되어, 다른 언어로 변환 시 비효율적이다.
- 의사 코드 (pseudo-code) : 프로그래밍 언어의 형태를 갖춘 가상 코드를 사용하며, 특정 프로그래밍 언어로 구체화하기 쉽다.
Pseudo-code
Algorithm logic의 English-like representation으로, English part와 Code part로 구성되어 있다.-
English Part
: 무엇이 되어야 하는지(what must be done)에 관한 완화된 구문(relaxed syntex)을 제공한다. -
Code Part
: basic algorithmic constructs(sequence, selection, and iteration)의 extended version으로 구성되어 있다.
예시는 아래와 같다.
Algorithm sample (pageNumber)
/* This algorithm reads a file and prints a report
Pre pageNumber passed by reference
Post Report Printed
PageNumber contains number of pages in report
Return Number of lines printed */
1 loop(not end of file)
1 read file
2 if (full page)
1 increment page number
2 write page heading
3 end if
4 write report line
5 increment line count
2 end loop
3 return line count
end sample- 첫 줄에는 알고리즘의 이름과 parameter를 작성한다.
- 그 다음 주석에 Algorithm header를 작성한다.
Algorithm header에는 purpose, precondition(Pre), postcondition(Post), return condition(Return)을 작성한다. - 그 아래 pseudo code(code part)를 작성하고, statement numer를 표시하여 계층을 구분해준다.
Data Structure와 Code 모두를 나타낼 때 pseudo-code를 사용하는데, 필수로 들어가야 할 사항은 아래와 같다.
- Variables : 변수의 데이터는 처음 사용할 때 자동으로 선언하는 것으로 간주하여, 데이터를 미리 선언 할 필요는 없다. 타입 역시 문맥에 따라 자동 결정된다. 다만, Data의 Structure(데이터 구조와 member로 구성)는 선언되어야 한다.
- Statement constructs : 함수 호출 등 순차 실행되는 Sequence, 조건을 evaluate하여 분기하는 Selection, 조건 등에 따라 block of code를 iterates하는 Loop로 명령문을 구성할 수 있다.
Any algorithm could be written using only three programming construcus.
- by Dijkstra
요약
이번 시간에는 Data Structure에 대해 공부하고 구현해 보기 전에 필요한 basic concept에 대해 알아보았다. program이 무엇인지, data structure와 algorithm이 무엇인지에 대해 알아보았다. 특히 data structure 중 ADT에 대해 새롭게 알아보았다.
다음 시간에는 ADT를 구현 관점에서 가볍게 살펴보도록 하자.
-2024.01.02 ~ 2024.01.03 이참 작성 -
복습 계획
- 기간 : 2024.01 ~ 2024.02
- 주기 : 1주에 한 챕터씩 복습(공부 및 구현) 및 기록하기.
- 방법 : 학기 중 공부했던 자료 및 검색을 통해 공부한다. 자료구조 구현은 해당 주가 끝나는 날 진행하며, C언어 외에 JS 등 원하는 언어를 활용해 공부한다.
- 목적 : PS 능력 향상 및 전공 지식의 복습, 면접 대비를 위해.
참고 자료
- COSE213 Lecture Note
