
포인터
포인터의 개념
포인터(pointer) - 특정 변수의 주소를 가리키는 변수
인터넷에서 쇼핑을 할 때 배송지에 집의 주소를 적으면 그 곳으로 물건을 배달한다. 이렇듯 주소는 특정 위치를 정확히 알려주는 지표다.
컴퓨터에서도 주솟값은 방대한 메모리에서 해당 변수가 저장되어 있는 위치를 정확히 알려주는 역할을 한다.
즉, 포인터 변수는 저장된 주솟값을 통해 언제든지 해당 변수에 접근할 수 있게 된다.
포인터의 선언과 초기화
- 문법
타입* 포인터이름 = &변수이름;- 예제
int main()
{
int a = 10;
int* pa = &a;
std::cout << "a의 값: " << a << std::endl;
std::cout << "pa의 값: " << pa << std::endl;
std::cout << "주소연산자 &a 결과: " << &a << std::endl;
std::cout << "참조연산자 *pa 결과: " << *pa << std::endl;
std::cout << "주소연산자와 참조연산자 *&a 동시 사용 결과" << *&a << std::endl;
}- 실행 결과
a의 값: 10
pa의 값: 004FFA64
주소연산자 결과: 004FFA64
참조연산자 결과: 10
주소연산자와 참조연산자 동시 사용 결과10[&]: 주소연산자 - 변수의 이름 앞에 사용하여, '해당 변수의 주소값'을 반환
'&'기호는 앰퍼샌드(ampersand)라고 읽으며, 번지 연산자라고도 불림[*]: 참조연산자 - 이름이나 주소 앞에 사용하여, 해당 주소를 참조하여 '주소에 저장되어 있는 값'을 반환한다
'*'기호는 역참조 연산자로 에스크리터(asterisk operator)라고도 불립
포인터의 참조
- 예제
int x = 7; // 변수의 선언
int *ptr = &x; // 포인터의 선언
int **pptr = &ptr; // 포인터의 참조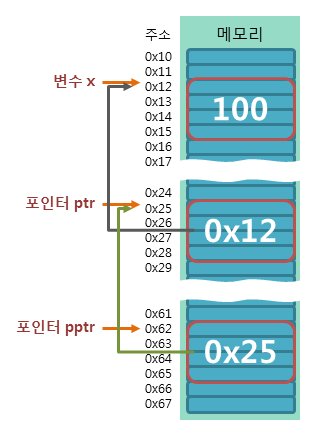
주소값의 이해
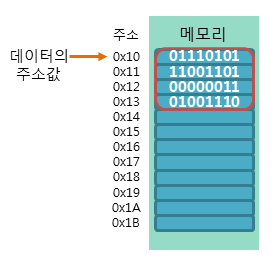
데이터의 주소값이란 해당 데이터가 저장된 메모리의 시작 주소를 의미한다.
C++에서는 이러한 주소값을 1바이트 크기의 메모리 공간으로 나누어 이해할 수 있다.
예를 들어, int형 데이터는 4바이트의 크기를 가지지만, int형 데이터의 주소값은 시작 주소 1바이트만을 가리키게 된다.
- 예제
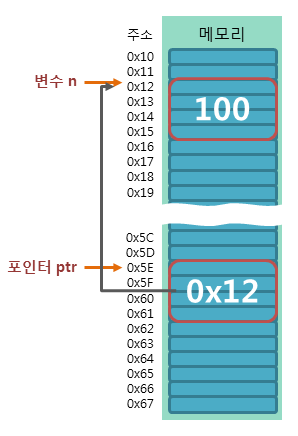
int n = 100; // 변수의 선언
int *ptr = &n; // 포인터의 선언위의 예제에서 사용된 변수와 포인터가 메모리에서 어떻게 저장되는지를 보여주는 예제이다.
포인터의 동시 선언
- 잘못된 예제
int* ptr1, ptr2;- 맞는 예제
int *ptr1, *ptr2;포인터를 사용하는 이유
어떠한 변수이든지 어떠한 버퍼를 할당 받아서 사용하는데, 모든 변수의 저장과 참조는 변수가 저장될 혹은 저장된 주소를 알아야 가능하다. 그래서 컴퓨터는 변수를 참조할 때 그 변수가 저장되어 있는 주소를 먼저 찾아내고 그 주소가 가리키는 내용을 참조하게 된다. 이렇게 변수의 주소를 저장하거나 사용하기 위한 변수가 포인터이다.
포인터를 사용하면 간결하고 효율적인 표현과 처리가 가능하고 더 빠른 기계어 코드를 생성할 수 있으며, 복잡한 자료 구조(배열, 구조체 등)와 함수의 쉬운 접근이 가능하다. 또한 포인터를 사용하지 않았을 때 코드로 표현할 수 없는 경우가 생길 수 있다.
포인터의 장점
메모리 주소를 참조하여 배열과 같은 연속된 데이터에 접근과 조작 용이
동적 할당된 메모리 영역(힙 영역)에 접근과 조작 용이
한 함수에서 다른 함수로 배열이나 문자열을 편리하게 보낼 수 있음
복잡한 자료구조를 효율적으로 처리
배열로 생성할 수 없는 데이터를 생성
메모리 공간을 효율적 사용
call by reference에 의한 전역 변수의 사용을 억제
포인터의 단점
포인터 변수는 주소를 직접적으로 컨트롤하기 때문에 예외 처리가 확실하지 않을 경우 예상치 못한 문제가 많이 발생. ( 널 포인트 같은 경우에 바로 접근할 경우 예외 발생)
선언만 하고 초기화를 하지않을 경우 쓰레기 주소를 가리키고 있기 때문에 사용에 주의해야 함.
포인터 변수는 주소를 직접 참조하기 때문에 의도하지않게 원본의 값이 수정 될 수 있다.
오류를 범하기 쉽고 기교적인 프로그램이 되기 쉽다.
프로그램의 이해와 버그 찾기가 어렵다.
메모리 절대 번지 접근 시 시스템 오류를 초래한다.
하지만 단점 보다는 장점이 더 많아서 ‘포인터’를 사용한다고 한다.
포인터는 할당하려면, 변수의 자료형과 같아야 함
포인터의 크기
- 포인터 변수의 크기는 4바이트로 고정된 것이 아니다.
- 운영체제의 bit수가 포인터 변수의 크기에 영향을 미치는 것은 아니다.
- 포인터 변수의 크기
(double* , char* , int*)의 크기는 컴파일러의 상황에 따라 다르다
-32bit로 컴파일 시, 4바이트로 모두 같고
-64bit로 컴파일 시, 8바이트로 모두 같다.- 64bit의 운영체제에서 32bit로 컴파일 시 포인터변수의 크기가 4바이트로 나타난다.
- 64bit의 운영체제에서 64bit로 컴파일 시 포인터변수의 크기가 8바이트로 나타난다.
<-운영체제에 따라 포인터변수의 크기가 정해지는 것이 아님
- 예제
int main()
{
int p = 10;
int* pt = &p;
// int: 4byte, char: 1byte, double: 8byte
char alpha = 'A';
char* palpha = α
double db = 1.23;
double* pdb = &db;
std::cout << "int형 p는: " << p << std::endl;
std::cout << "int형 pt 크기 값은: " << sizeof(pt) << std::endl;
std::cout << "char형 alpha는: " << alpha << std::endl;
std::cout << "char형 palpha 크기 값은: " << sizeof(palpha) << std::endl;
std::cout << "double형 db는: " << db << std::endl;
std::cout << "double형 pdb 크기 값은: " << sizeof(pdb) << std::endl;
}- 실행 결과 (64bit 운영체제에서 32bit로 컴파일 시)
int형 p는: 10
int형 pt 크기 값은: 4
char형 alpha는: A
char형 palpha 크기 값은: 4
double형 db는: 1.23
double형 pdb 크기 값은: 4포인터의 연산
- 포인터는 주소 값을 저장하는 변수 -> 포인터끼리 사칙연산 중 뺄셈을 제외하고 무의미
- 뺄셈 -> 두 포인터 사이의 거리를 나타냄
- 포인터에 정수 값을 더하거나 빼는건 가능, 하지만 실수는 안됨
- 포인터끼리 대입하거나 비교할 수 있습니다.
- 예제
int main()
{
int a = 1;
int* pa = &a;
double db = 0.1;
double* pdb = &db;
std::cout << "pa의 값: " << pa << std::endl;
std::cout << "pa + 1의 값: " << pa + 1 << std::endl;
std::cout << "db의 값: " << pdb << std::endl;
std::cout << "db + 1의 값: " << pdb + 1 << std::endl;
}- 실행 결과
pa의 값: 0055FB54
pa + 1의 값: 0055FB58
db의 값: 0055FB38
db + 1의 값: 0055FB40*주소는 아스키코드로 표현됨
데이터 타입별로 연산 후, 주소가 int는 4만큼, double은 8만큼 증가
이 법칙은 포인터의 뺄셈에서도 똑같이 적용됨.

포인터와 배열
포인터에 배열의 이름을 대입한 후, 해당 포인터를 배열의 이름처럼 사용할 수 있다.
즉, C++에서는 배열의 이름이 주소로 해석되며, 해당 배열의 첫 번째 요소의 주소와 같게 된다.
- 예제
int main()
{
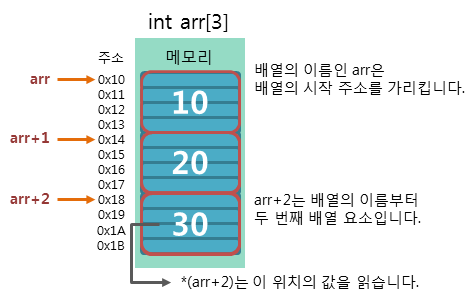
int arr[3] = { 10, 20, 30 };
int* pt_arr = arr;
std::cout << "배열 이름으로 배열의 요소 출력 : " << arr[0] << ", " << arr[1] << ", " << arr[2] << std::endl;
std::cout << "포인터로 배열의 요소 출력: " << pt_arr[0] << ", " << pt_arr[1] << ", " << pt_arr[2] << std::endl;
std::cout <<"배열 이름에 정수를 더해서 출력" << *(arr) << ", " << *(arr + 1) << ", " << *(arr + 2) << std::endl;
}- 실행 결과
배열 이름으로 배열의 요소 출력 : 10, 20, 30
포인터로 배열의 요소 출력: 10, 20, 30
배열 이름에 정수를 더해서 출력: 10, 20, 30배열의 이름과 포인터 사이에는 다음과 같은 공식이 성립함을 알 수 있습니다.
- 공식
arr이 배열의 이름이거나 포인터이고 n이 정수일 때, arr[n] == *(arr + n)
포인터의 연산 시 주의할 점
배열에 관계된 연산을 할 때는 언제나 배열의 크기를 넘어서는 접근을 하지 않도록 주의해야 합니다.
포인터 연산을 이용하여 계산하다가 배열의 크기를 넘어서는 접근을 하는 경우, C++ 컴파일러는 어떠한 오류도 발생시키지 않습니다.
다만 잘못된 결과만을 반환하므로 C++로 프로그래밍할 때에는 언제나 배열의 크기에 주의해야 합니다.
이중 포인터
int main()
{
int a = 10;
int* pa = &a;
int** ppa = &pa;
std::cout << "a==" << a << std::endl;
std::cout << "&a==" << &a << std::endl;
std::cout << "pa==" << pa << std::endl;
std::cout << "*pa==" << *pa << std::endl;
std::cout << "&pa==" << &pa << std::endl;
std::cout << "ppa==" << ppa << std::endl;
std::cout << "&ppa==" << &ppa << std::endl;
std::cout << "*ppa==" << *ppa << std::endl;
std::cout << "**ppa==" << **ppa << std::endl;
}a==10 (a의 값)
&a==002AFD28 (a의 주소 -> 주소1)
pa==002AFD28 (pa=&a=주소1)
*pa==10 (pa=&a=주소1 에 저장된 값 반환)
&pa==002AFD1C (pa=&a=주소1 의 주소 -> 주소2)
ppa==002AFD1C (ppa=&pa=주소2)
&ppa==002AFD10 (ppa=&pa=주소2 의 주소 -> 주소3)
*ppa==002AFD28 (ppa=&pa=주소2에 저장된 값=주소1 반환)
**ppa==10 (*ppa=주소1 에 저장된 값=10 반환)이중 포인터 그림으로 이해하기
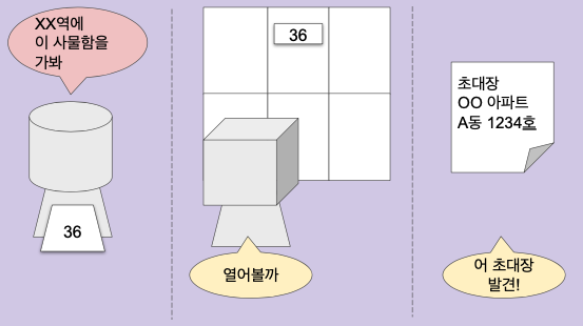
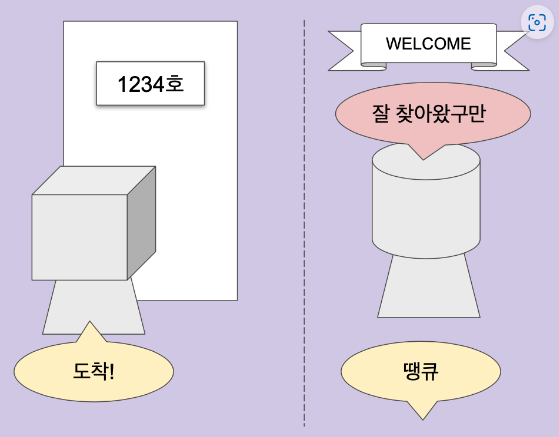
이중 포인터 사용 이유
간단하게만 말씀드리자면, 만일 배열에 10개의 원소를 저장한다고 하면,
메모리 주소를 1칸(변수가 차지하는 사이즈, ex. int -> 4 byte)씩 옮겨서
순서대로 10칸에 원소를 저장하여 접근하는 방식이다.
swap 함수에서 두 변수를 실제로 바꾸려면 메모리 주소를 바꿔주는 원리를 이용한다면
포인터를 사용하는 것이 편리하게 된다.그렇다면, 만일 두 변수에 저장된 배열을 통째로 바꾸고 싶다면?
이런 경우에 이중 포인터를 사용하는 것이 필요하게 되는 것이다.물론, 3중 포인터 등도 구상은 해볼 수 있으나, 실제로는 거의 사용할 일이 없어
이중 포인터 정도까지만 예제를 잘 이해하면 좋을 것 같다.
포인터 사용 실습 예제
- 실습 예제 1
p1과 p2의 값을 서로 바꾸는 실습
// swap: 어떤것을 주고 그 대신 다른 것으로 바꾸다
void SwapIC(int num1, int num2)
// main{ }와는 다른 동네 p1, p2라는 애를 모른다(값을 모른다)
// 값을 복사를 하기 때문에 메모리 사용량이 늘어난다
{
int temp = num1;
num1 = num2;
num2 = temp;
}
void Swap1(int* num1, int* num2) // 주소에 의한 호출
{
int temp = *num1;
*num1 = *num2;
*num2 = temp;
}
void Swap2(int& num1, int& num2) // 참조에 의한 호출
// 빠르다, 직접 참조를 하기에 원래 값이 영향을 받는다
{
int temp = num1;
num1 = num2;
num2 = temp;
}
int main()
{
int p1 = 20;
int p2 = 5;
SwapIC(p1, p2); // p1, p2는 main 함수에 있는 변수라 SwapIC가 순서상 위에 있어서 값이 제대로 배송이 되지 않는다
std::cout << "p1의 값은?: " << p1 << std::endl;
std::cout << "p2의 값은?: " << p2 << std::endl;
Swap1(&p1, &p2); // 주소에 의한 호출
std::cout << "p1의 값은?: " << p1 << std::endl;
std::cout << "p2의 값은?: " << p2 << std::endl;
Swap2(p1, p2); // 참조에 의한 호출
std::cout << "p1의 값은?: " << p1 << std::endl;
std::cout << "p2의 값은?: " << p2 << std::endl;
}p1의 값은?: 20
p2의 값은?: 5
p1의 값은?: 5
p2의 값은?: 20
p1의 값은?: 20 (한번 바뀐 값을 다시 바꿈)
p2의 값은?: 5- 실습 예제 2
출력될 i는?
int main()
{
int i = 1;
int k = 2;
int* p1 = &i; // p1에는 i의 주소가 저장
int* p2 = &k; // p2에는 k의 주소가 저장
//p1 = p2; // p1에 p2 주소를 저장
*p1 = 3; // p1에 저장된 주소값을 불러오면 3
std::cout << "출력될 i는?: " << i << std::endl;
std::cout << "출력될 k는?: " << k << std::endl;
*p2 = 4; // p2에 저장된 주소값을 불러오면 4
std::cout << "출력될 i는?: " << i << std::endl;
std::cout << "출력될 k는?: " << k << std::endl;
}- 실행 결과
출력될 i는?: 3
출력될 k는?: 2
출력될 i는?: 3
출력될 k는?: 4※참고
http://www.tcpschool.com/
https://bite-sized-learning.tistory.com/269
