1. 자료형
🔖예문
int i = 0;📃 설명
int = 자료형, i = 변수, 0 = 변수값
- 변수 명은 비교적 자유롭게 정할 수 있다.
- 변수의 이름은 해당 변수에 저장될 데이터의 의미를 잘 나타내도록 짓는 것이 좋다.
🔍참고
C++에서 변수의 이름을 생성할 때 반드시 지켜야 하는 규칙
- 변수의 이름은
영문자(대소문자),숫자,언더스코어(_)로만 구성된다. - 변수의 이름은
숫자로 시작될 수 없다. - 변수의 이름 사이에는
공백을 포함할 수 없다. - 변수의 이름으로 C++에서
미리 정의된 키워드(keyword)는 사용할 수 없다. - 변수 이름의
길이에는 제한이 없다.
1-1. 자료형(Data Type)의 역할
- Byte의 크기 결정, 정수인지 실수인지 등을 결정
- 자료형 그 자체로써는 어떠한 실체도 없다.
- 자료형은 내가 선언할 메모리 공간에 이름을 부여하고(변수이름)
그 공간이 얼마의 크기가 되고 어떠한 데이터를 표현할 것인지 설명해주는 역할이다.
위 예문에서 int i는 4Byte의 크기를 가지고 정수를 표현한다.
1-2. 자료형의 종류
🔖예문
// 자료형이름(단위(Byte))
정수형 : char(1), short(2), int(4), long(4), longlong(8)
실수형 : float(4), double(8)정수타입과 실수타입을 처리하는 방식이 완전히 다르기 때문에 구별함.
🔍참고
컴퓨터 Data의 단위
Bit(비트) - Data의 최소단위 0 또는 1 / 참 또는 거짓
Byte(바이트) - 8bit - 알파벳과 숫자 한 개
KB(킬로바이트) - 1024Byte - 몇개의 문단
MB(메가바이트) - 1024KB - 1분 길이의 MP3노래
GB(기가바이트) - 1024MB - 30분 길이의 HD영화
TB(테라바이트) - 1024GB - 약 200편의 FHD영화정수형 자료형
- 정수형 : char(1), short(2), int(4), long(4), longlong(8)
- 컴퓨터는 1Byte로 256()가지의 정수 상태를 표현할 수 있다.
- 양의 정수만 표현하고 싶을 때 정수형 앞에 unsigned를 붙힌다.
🔖예문
char c = 0; // -128 ~ 0 ~ 127 까지 표현
unsigned char c = 0; // 0 ~ 255 까지 표현- 표현할 수 있는 수의 크기는 자료형의 Byte 크기 값에 따라 달라진다.
🔍참고
최상위비트(MSB)
컴퓨터는 우리가 1을 입력해도 곧이곧대로 1로써 받아들이는 게 아닌, 1이라는 숫자의 Bit 값으로 해석한다.
예) 1을 Bit 값으로 표현한다면 ('0','0','0','0','0','0','0','1') 이다.
양수는 비트값 앞에 자리가 0이고 숫자 0의 비트는 ('0','0','0','0','0','0','0','0')이다.
음수를 표현하는 비트값은 앞에 자리가 1이다.
예) ('1','1','1','1','1','1','1','1') 는 -1의 Bit이다.
가장 앞에 있는 비트값이 0과 1에 따라 양수와 음수가 정해진다.
Bit 가장 앞에 있는 숫자를 최상위비트(MSB(Most Significant Bit))라고 한다.🤔❔ 만약
char에 255를 대입하면 어떻게 될까?
char c = 255;
// 컴파일러는 문제로 잡아주지 않는다.📃 설명
c 값에는 8bit에 255에 해당하는
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
값이 들어가기 때문에 결과적으로 c에는 -1이 대입된다.
반대로 unsigned char에 -1을 대입하면 어떻게 될까?
unsigned char = -1;이 역시도 c값에 8bit에 -1에 해당하는
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
값이 들어가기 때문에 결과적으로 c에는 255가 대입된다.
🔍참고
음수 비트 구하는 방법 (2의 보수법)
예)10의 보수법 (4의 보수는 6, 3의 보수는 7이다.) ※4+(6)=10, 3+(7)=10
2의 보수법 (0의 보수는 1, 1의 보수는 0이다.)
어떤양수비트에 특정음수비트를 더했을 때 0이 되는게 해당 음수비트다.
대응되는 양수의 비트들을 반전 후, 1을 더한다
예) ('0','0','0','0','0','0','1','0') <- 2의 비트이다.
+('1','1','1','1','1','1','1','0') <- -2의 비트이다.
=('0','0','0','0','0','0','0','0')
char자료형에서는 8Bit까지밖에 없기 때문에 승격된 9번째 Bit는 사라진다.실수형 자료형
- 실수형 : float(4), double(8)
0~1만 따져봐도 실수로 무한대로 표현할 수 있다.
그런데 어떻게 한정적인 메모리로 실수라는 것을 표현할 수 있을까?
정수타입에서의 4와 실수타입의 4를 표현하는 방식은 완전히 다르다.
🔖예문
int a = 4 + 4.0;- 연산방식을 정수방식으로 갈건지 실수방식으로 갈건지 정의해 줘야함.
a의 자료형이int이기 때문에4.0은 정수타입으로 형변환 과정을 거치게 된다.- 낭비이기 때문에 의도가 아닌 경우 가급적 정수는 정수끼리, 실수는 실수끼리 연산하도록 해야 한다.
- 의도된 바라면 아래처럼 명시적으로 변환을 해줘야 한다.
float f = 10.2355f + (float)20;부동소수점 방식
https://ko.wikipedia.org/wiki/%EB%B6%80%EB%8F%99%EC%86%8C%EC%88%98%EC%A0%90
예)21.8125를 2진수로 표현하면
| 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 |
21은 10101.0이 되고 (16 + 4 + 1 = 21)
0.8125는 0.11010이 된다 (0.5 + 0.25 + 0.0625 = 0.8125)
이는 바꿔말하면 이 된다.
따라서, 32Bit 정규화된 부동소수점수로 나타낸다면
- 맨 앞 비트의 부호는 0(양)이고,
- 지수부 부호는 0(양)이며,
- 지수의 5를 이진법으로 바꾸면 000101이고,
- 지수부 나머지 6개 비트는 000101,
- 가수부는 101011101000…이 된다.
이것을 결합하면 00000010110101110100000000000000 가 된다.
0 00000101 10101110100000000000000

가수부에 무한정 담아낼 수 없기 때문에 완전히 정확하지 않을 수 있다. double은 8Byte이기 때문에 float보다 2배 더 정확하게 표현이 가능하다.
🔍참고
실수를 상수로 적을경우 소수점 뒤에 f를 붙이지 않으면 double 자료형으로 간주한다.
data = 10. (double 형)
data = 10.f (float 형)🤔❔ 만약
예를들어 삼각함수의 대한 값과 어떤 모든 연산을 다 했을 때 결과값이 1.0이 되는 조건에서 실행되게 다음과 같이 수식을 작성했다면,
어떤 연산 == 1.0f결과적으로 테스트를 해보면 1.0에 매우 가까운 0.99999998과 같은 값이 들어가게 되는 경우가 있기 때문에 조건에 해당되지 않아서 정상적으로 실행되지 않을 수 있다.
이처럼 실수의 정밀도 개념을 알지 못하면 예상치 못한 오류를 야기할 수 있다.
부동 소수점 방식의 오차
🔖예문
int i;
float sum = 0;
for (i = 0; i < 1000; i++)
{
sum += 0.1;
}
cout << "0.1을 1000번 더한 합계는 " << sum <<"입니다.";
실행 결과
0.1을 1000번 더한 합계는 99.999입니다.📃 설명
위의 예제에서 0.1을 1000번 더한 합계는 원래 100이 되어야 하지만, 실제로는 99.999가 출력된다.
이처럼 컴퓨터에서 실수를 가지고 수행하는 모든 연산에는 언제나 작은 오차가 존재하게 된다.
2. 연산자
2-1. 연산자의 종류
대입 연산자
= (대입)
+= (덧셈 후 대입)
-= (뺄셈 후 대입)
*= (곱셈 후 대입)
/= (나눗셈 후 대입)
%= (나머지 후 대입)a=b a에 b의 값을 대입
산술 연산자
+ (더하기)
- (빼기)
* (곱하기)
/ (나누기)
% (나머지) '모듈러스' 라고 함, 피연산자가 모두 정수여야 함.🔖예문
int data = 10 + 10; //(더하기 먼저 계산후 대입)
data = data + 20;
data += 20; //(데이터에 20을 더한 값을 다시 데이터에 대입, 위 수식과 같다.)
data = 10 % 3; // data = 1
data = 10 % 3.; // 실수타입의 모듈러스는 문법 오류다. 나머지가 존재하지 않음.
data = 10 % (int)3.; // 굳이 성립시킬려면 실수타입을 정수타입으로 형변환을 해줘야 한다.
data = 10./ 3.; // data = 3 의 정수를 갖는다.
data = (int)(10. / 3.); // 하지만 명시적으로 형변환을 해주는게 좋다.증감 연산자
++ 다음단계로 증가
-- 이전단계로 감소🔖예문
int data = 0;
data++; // data = 1
data++; // data = 2
data--; // data = 1
data--; // data = 0📃 설명
정수 나 실수 자료형일 때 단순히 1이 증가 한다 혹은 1이 감소한다 라고 할 수도 있지만 나중에 포인터에서 실수를 유발할 여지가 있다.
그렇기 때문에 한 단계가 증가/감소한다고 생각하는게 더 낫다.
++data; // 전위(전치)
data++; // 후위(후치)🔖예문
int data = 0;
int a = 10;
data = a++; // 여기서 data의 값은 10이다. a++는 대입연산자보다 나중에 수행됨.
📃 설명
++/-- 가 변수 앞에 붙었는지 뒤에 붙었는지에 따라 연산자 우선순위가 바뀜.
후위(후치)연산자는 모든 연산자들을 통들어서 가장 나중에 수행된다. 대입 연산자보다도 늦다.
예문 2-3)에서 data의 값을 바로 증가시키려는 의도였다면 전위(전치)연산자로 써야한다.
그래서 특별한 이유가 없으면 가급적 전위 연산자로 쓰는게 좋다.
🔖예문
int data = 0;
int a = 10;
data = ++a; // 여기서 data의 값은 11이다.🔍참고
위 예문에서 a의 값 역시도 따로 대입하지 않아도 자동으로 11로 바뀐다.
논리 연산자
! (논리부정/역, not)
&& (논리곱, and)
|| (논리합, or)참(true) : 0이 아닌 값, 1
거짓(false) : 0
🔍참고
0이 아닌 값은 전부 참으로 간주한다.
하지만 컴퓨터가 우리에게 참의 값을 주게 될 경우에는 1을 반환한다.
int a = true; // a = 1
int b = false; // b = 0bool = 논리 전용 자료형. 1Byte이지만 0하고 1밖에 모르는 바보.
🔖예문
bool IsTrue = 100; // IsTrue = 1;
// 논리부정
IsTrue = !IsTrue; // IsTrue = false;
int iTrue = 100;
iTrue = !iTrue; // iTrue = 0;
// 논리곱
iTrue = 100 && 200; // iTrue = 1;
iTrue = 0 && 200; // iTrue = 0;
// 논리합
iTrue = 0 || 200; // iTrue = 1;
iTrue = 0 || 0; // iTrue = 0;📃 설명
and형인 &&은 둘 중 하나라도 거짓이면 거짓, 모두 참이어야 결과값이 참이며,
or형인 ||은 둘 중에 하나만 참이어도 결과값은 참이 된다.
비교 연산자
== (동등 비교)
!= (부등 비교)
> (크기 비교)
< (작기 비교)
>= (크거나 같은 비교)
<= (작거나 같은 비교)3. 조건문
3-1. if, else if, else 구문
🔖예문
if (조건식 1)
{
// 조건식 1의 결과가 참일 때 실행하고자 하는 명령문;
}
else if (조건식 2)
{
// 조건식 2의 결과가 참일 때 실행하고자 하는 명령문;
}
else
{
// 모든 조건식의 결과가 거짓일 때 실행하고자 하는 명령문;
}📃 설명
조건식 1이 참이면 밑에조건식 2나else문은 실행하지 않고if문만 실행한다.조건식 1이 거짓이고조건식 2가 참이면else if문만 실행하고 나머지는 실행하지 않는다.조건식 1, 2가 모두 거짓이면else문만 실행한다.
🤔❔ 만약
1.조건식 1, 2가 모두 거짓인데 else 문을 작성하지 않았다면?
🔖예문
if (조건식 1) // 조건식 1이 거짓
{
// 조건식 1의 결과가 참일 때 실행하고자 하는 명령문;
}
else if (조건식 2) // 조건식 2도 거짓
{
// 조건식 2의 결과가 참일 때 실행하고자 하는 명령문;
}
// 결과적으로 아무것도 실행하지 않는다.2.조건식 1과 조건식 2에 대해 명령문이 독립적으로 실행되게 하려면 else if 문을 사용하지 않고 각각에 대해 if 문을 작성한다.
🔖예문
if (조건식 1)
{
// 조건식 1의 결과가 참일 때 실행하고자 하는 명령문;
}
if (조건식 2)
{
// 조건식 2의 결과가 참일 때 실행하고자 하는 명령문;
}3-2. switch, case 구문
🔖예문
switch (10)
{
case 10:
// 조건이 참이면 이 부분을 실행한다.
break;
case 20:
// 조건이 참이면 이 부분을 실행한다.
break;
default: // case 문이 전부 거짓이면 default 문이 실행된다.
break;
// break;를 만나면 {}중괄호 영역에서 빠져나온다.
}위 예문을 if, else 구문으로 바꾸어보면
🔖예문
int iTest = 10;
if (iTest == 10)
{
// 조건이 참이면 이 부분을 실행한다.
}
else if (iTest == 20)
{
// 조건이 참이면 이 부분을 실행한다.
}
else
{
// 모든 조건식의 결과가 거짓일 때 실행하고자 하는 명령문;
}🔍참고
1) if, else 문과 switch, case 문이 비슷한데 왜 두개가 있을까?
문법적으로는 크게 차이가 없다.
프로그래머의 코딩 방식에 따라서 가독성과 표현방식 등 상황에 맞게 선호하는 문법을 사용하면 된다.
2) 각 case문에break;를 깜빡하고 적지 않아도 문법적으로 오류가 발생하지 않기 때문에 주의가 필요하다.
아래와 같이 의도적으로 break;를 적지 않는 경우도 있다.
🔖예문
switch (iTest)
{
case 10:
case 20:
case 30:
// iTest가 10, 20, 30 일 때 실행된다.
break;
default: // case 문이 전부 거짓이면 default 문이 실행된다.
break;
}3-3. 삼항 연산자
🔖예문
iTest == 20 ? iTest = 100 : iTest = 200;
// iTest == 20이 참이면 iTest에 100을 대입하고,
// 거짓이면 200을 대입해라.위의 삼항연산자를 if, else구문으로 다시 작성해보면
🔖예문
if (iTest == 20)
{
iTest = 100;
}
else
{
iTest = 200;
}🔍참고
삼항 연산자는 가독성이 좀 떨어지기 때문에 특별한 경우 아니면 사용하지 않는다.
3-4. 비트 연산자
비트(Bit) 단위로 연산이 진행되는 연산자
<< (비트 좌측 시프트) // 왼쪽으로 한칸씩 민다.
>> (비트 우측 시프트) // 오른쪽으로 한칸씩 민다.🔖예문
unsigned char byte = 1; // (0, 0, 0, 0, 0, 0, 0, 1)
byte = byte << 1; // (0, 0, 0, 0, 0, 0, 1, 0) = 2(2배 증가)
// byte <<= 1; 로 표현할 수 있다. 📃 설명
byte <<= n 이면 byte는 배가 되고,
byte >>= n 이면 byte는 로 나눈 몫이 된다.
& (비트 and) // 비트 곱
| (비트 or) // 비트 합
^ (비트 xor)
~ (비트 not) // 비트 역📃 설명
비트 자리수 끼리 연산
& : 두 Bit 다 1이면 1, 하나라도 0이면 0
| : 두 Bit 다 0이면 0, 하나라도 1이면 1
^ : 두 Bit가 같으면 0, 다르면 1
~ : Bit를 반전시킨다 (1, 0, 1, 0) (0, 1, 0, 1)
🔍참고
비트 연산자가 많이 쓰일까?
예를들어 전처리기를 사용해 상태이상에 대한 값을 넣어준 후에 비트값을 넣었다 뺐다 하는 식으로 상태이상을 관리할 수 있다. 아래에서 자세히 알아보면,
전처리기 (Macro)
# 키워드가 붙은 전처리기 구문은 모든 컴파일 과정중에 제일 먼저 실행됨
#define : 내가 적은 구문을 특정 숫자로 치환해줌.
🔖예문
#define HUNGRY 1 // 배고픔 상태. 보통은 16진수로 쓴다. 0x1
#define THIRSTY 2 // 목마름 상태. 16진수로 0x2
#define TIRED 4 // 피곤함 상태. 16진수로 0x4
...
unsigned int iStatus = 0;
iStatus |= HUNGRY; // iStatus에 1에 해당하는 비트를 대입한다. 비트 합은 하나라도 1이면 1
iStatus |= THIRSTY; // iStatus에 2에 해당하는 비트를 대입한다.
// 현재 목마름 상태인지 물어보자
if (iStatus & THIRSTY) // & 비트 곱은 둘 다 1이여야 1을 반환하기 때문.
{
// 목마름 상태일 때 실행할 부분.
}위 예문에 따른 비트 결과
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
🤔❔ 만약해당 자리만 비트를 제거하고 싶다면?
비트연산자 ^ (xor)를 사용했을 때
그 자리에 비트가 없으면 오히려 집어넣는게 되기 때문에, 비교구문을 사용하여 해당 자리에 비트가 존재 하는지 여부를 먼저 확인해야 한다.
그렇기 때문에 보통, 특정 자리의 비트를 제거할 때는,
아래와 같이 반전시킨 비트를 비트곱 연산 해주는 방법을 사용한다.
iStatus &= ~THIRSTY;| 연산 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | |
| & | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| = | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
이렇게 하면 해당 자리에 비트가 존재하는지 비교할 필요 없이 바로 빼줄 수 있다.
📃 설명
전처리기를 사용하는 장점
1) 직관적이라 가독성이 좋다.
2) 코드 유지보수에 용이하다.
3) 함수에 해당 인자를 전달해 줄 수 있다.
🔍참고
비트 자릿수는 보통 16진수로 표현한다.
🔖예문
#define HUNGRY 0x001
#define THIRSTY 0x002
#define TIRED 0x004
#define COLD 0x008
#define FIRE 0x010 -> 16이 되면 자리수 올림 하기 때문.
#define POISON 0x020
#define CURSE 0x040
#define BLEED 0x080
#define STUN 0x100
#define SHOCK 0x200
...
1, 2, 4, 8 로 반복되는 걸 볼 수 있다.조건 연산자
? : (조건 연산자)
포인터 연산자
& (주소 연산자)
(역참조 연산자)4. 변수(1)
4-1. 함수 기초
🔖예문
int Add(int a, int b) // 반환하는 자료형이 int형인 Add 함수
{
return a + b;
}
int main() // 반환하는 자료형이 int형인 main 함수
{
int iData = Add(100, 200) // Add 함수 호출, a와 b에 해당하는 인자값을 입력.
return 0;
}4-2. 지역변수/전역변수 기초
지역변수
🔖예문
int iFunc(int left, int right)
{
int local = 0; // iFunc이라는 함수 안에 선언된 변수. left, right, local 모두 지역변수.
// 스택 메모리 영역
}함수 안에 또 다른 지역을 만들면 같은 이름으로 쓸 수도 있다.
🔖예문
int iFunc1()
{
int local = 0;
int iFunc2()
{
int local = 0; // iFunc1에 이미 local이라는 변수가 있지만,
// iFunc2안에서만 사용할 수 있는 local이라는 변수를 정의할 수 있다.
}
}전역변수
🔖예문
int global = 0; // 함수 바깥에 선언된 변수. 전역변수.
// 데이터 메모리 영역
int iFunc()
{
...
}5. 반복문
5-1. for문
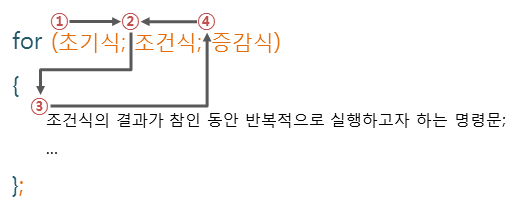
🔖예문
int main()
{
for (int i = 0; i < 4; ++i)
{
printf("Output Test\n"); // 화면에 Output Test를 띄우고 다음줄로 개행
}
}
실행결과
Output Test
Output Test
Output Test
Output Test5-2. while문

🔖예문
int main()
{
int i = 0;
while(i < 4)
{
printf("Output Test\n");
++i;
}
}
실행결과
Output Test
Output Test
Output Test
Output Test5-3. continue, break
continue
반복구문이 수행될 때 continue를 만나면 아랫부분은 더이상 수행하지 않고, 다음 단계로 넘어가도록 함.
🔖예문
int main()
{
for (int i = 0; i < 4; ++i)
{
if(i % 2 == 1)
{
continue; // i가 홀수일 때는 다음단계로 넘어감. 아래부분은 실행하지 않음.
}
printf("Output Test\n");
}
}
실행결과
Output Test
Output Testbreak
반복구문이 수행될 때 break를 만나면 반목문을 더이상 실행하지 않고 종료시킨뒤, 반복문 바로 다음에 위치한 명령문을 실행한다.
🔍참고
goto 문은 프로그램의 흐름을 지정된 레이블(label)로 무조건 변경시키는 명령문이다.
goto 문은 다른 제어문과는 달리 아무런 조건 없이 프로그램의 흐름을 옮겨준다.
따라서 가장 손쉽게 사용할 수 있지만, 반면에 프로그램의 흐름을 매우 복잡하게 만들기도 한다. 이러한 단점 때문에 현재는 디버깅 이외에는 거의 사용되지 않는다.
6. printf, scanf 문자 입출력
전처리기로 #include <stdio.h>를 입력 후 사용할 수 있다.
6-1. printf
명령프롬프트 창(콘솔 창)에 원하는 문자열을 출력할 수 있다.
🔖예문
#include <stdio.h>
int main()
{
printf("abcdef %d \n", 10); // %d라는 치환문자 자리에 10이라는 정수로 치환시킨다.
return 0;
}
실행결과
abcdef 10for문과 같이 사용해보자.
🔖예문
#include <stdio.h>
int main()
{
for(int i = 0; i < 5; ++i)
{
printf("Output i : %d \n", i);
}
return 0;
}
실행결과
Output i : 0
Output i : 1
Output i : 2
Output i : 3
Output i : 4 다른 타입의 치환문자를 알아보자
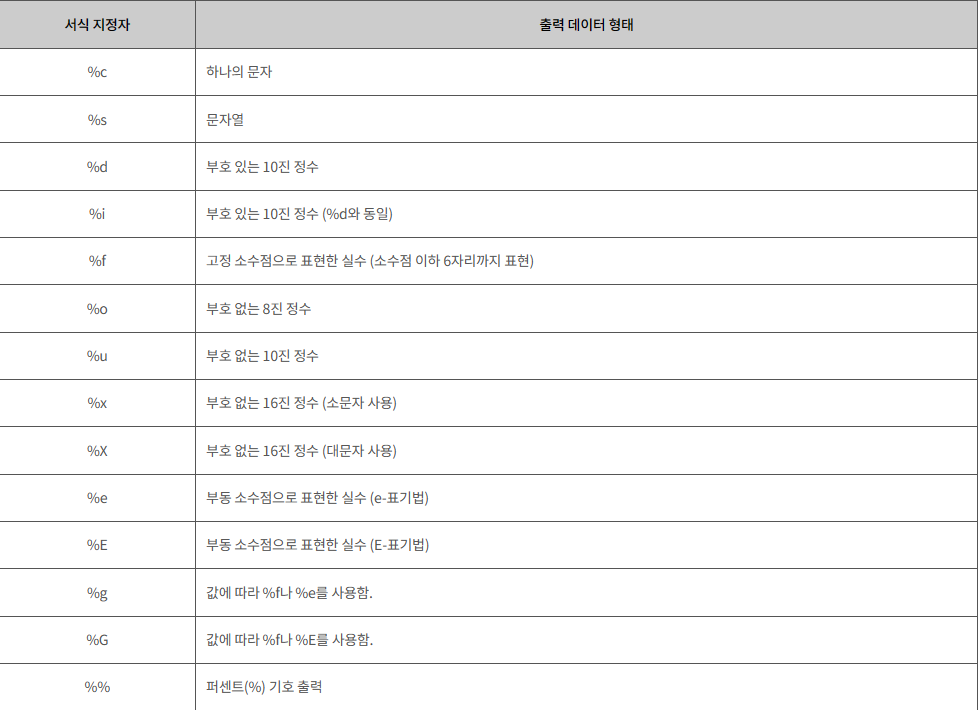
🔖예문
printf("%%c를 사용한 결과 : %c\n", 'a'); // 문자
printf("%%s를 사용한 결과 : %s\n", "즐거운 C언어"); // 문자열
printf("%%f를 사용한 결과 : %f\n", 0.123456);
printf("%%f를 사용한 결과 : %f\n", 0.123456789); // 소수점 6자리까지만 표현
printf("%%o를 사용한 결과 : %o\n", 123); // 8진 정수
printf("%%x를 사용한 결과 : %x\n", 123); // 16진 정수
printf("%%g를 사용한 결과 : %g\n", 0.001234); // 값에 따라 %f나 %e
printf("%%g를 사용한 결과 : %g\n", 0.00001234); // 값에 따라 %f나 %e
printf("%%G를 사용한 결과 : %G\n", 0.000001234); // 값에 따라 %f나 %E
실행결과
%c를 사용한 결과 : a
%s를 사용한 결과 : 즐거운 C언어
%f를 사용한 결과 : 0.123456
%f를 사용한 결과 : 0.123457
%o를 사용한 결과 : 173
%x를 사용한 결과 : 7b
%g를 사용한 결과 : 0.001234
%g를 사용한 결과 : 1.234e-05
%G를 사용한 결과 : 1.234E-06※출처 : http://www.tcpschool.com/c/c_intro_printf
6-2. scanf
🔖예문
#include <stdio.h>
int main()
{
int iInput = 0;
scanf_s("%d", &iInput);
}
실행결과
// 콘솔창에서 100을 입력하면 iInput에 100이라는 정수값이 대입된다.