
용어 정리
- 헥사고날에서의 용어
- Domain
- 사용자가 이용하는 앱의 기능, 회사의 비즈니스 로직을 정의하고 있는 영역
- Entity
- 비즈니스 로직을 캡슐화한 객체
- Domain
아 그러면 비즈니스 로직을 JPA 개념의 엔티티에 작성하면, 엔티티가 도메인의 주체가 되는거고 비즈니스 로직을 Service 단에 작성하면, Service가 도메인의 주체가 되는거다.
핵심은 도메인 영역은 일반적으로 Service와 Entity를 의미하고, 영속 계층은 Repository를 의미한다.
기존 계층형 아키텍쳐의 문제점
전통적인 Layered Architecture의 경우에는 DB 주도 설계를 유도한다.
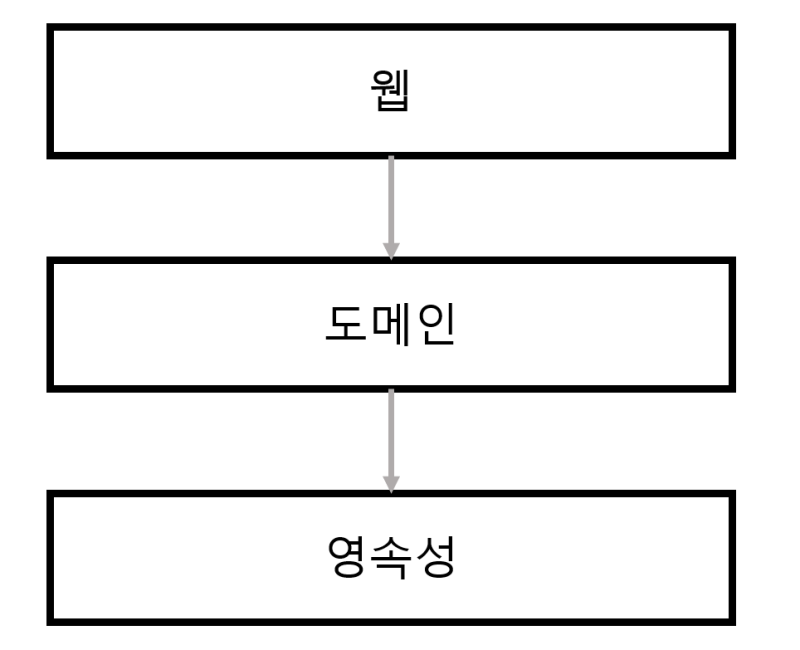
→ 의존성이 영속성 레이어로 향하기 때문에
의존성이 아래로 흐르기 때문에, 도메인 레이어에서 필요로 하는 의존성(헬퍼, 유틸리티)이 영속성 레이어에 계속해서 추가가 되기 때문에 거대해질 수 있다.
이 때문에 내가 그동안 데이터베이스를 중심으로 애플리케이션을 개발한 것이다.
→ 먼저 쿼리를 작성하고, 이 쿼리에 맞춰서 도메인 로직을 작성했었다.
또한 다른 단점으로는 외부 시스템(ex: JPA)을 변경하기 힘들다는 단점이 있다.
→ Spring data가 제공하는 Repository에 지나치게 의존하여서, 추후 ORM을 변경할 경우에 취약하게 된다.
클린 아키텍쳐, 헥사고날
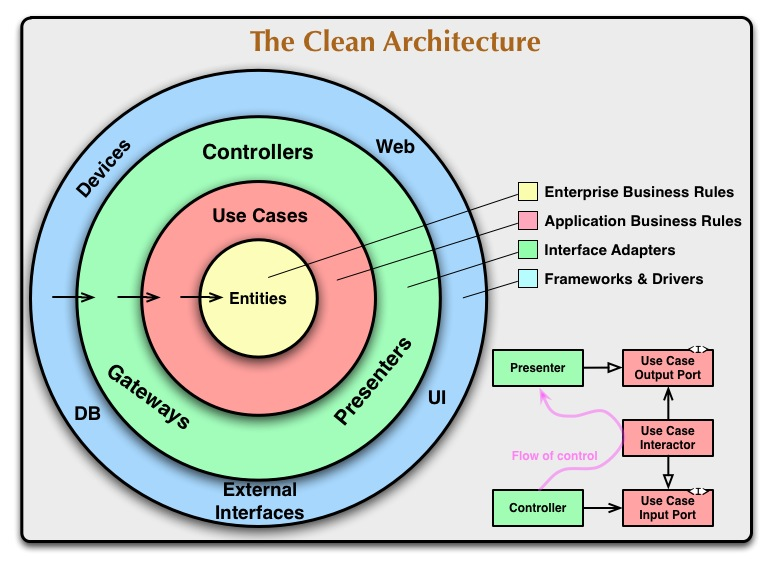
클린 아키텍쳐는 위 계층형 구조의 단점들을 해결해준다.
각 레이어들은 동심원으로 둘러싸여 있고, 이는 도메인 로직을 담당하는 Use Case와 도메인 엔티티로 향하고 있다.
따라서 도메인 코드에서는 어떤 영속성, UI 프레임워크가 사용되는지 알 수 없기 때문에 비즈니스 규칙에 집중할 수 있다.
- 어떻게 집중할 수 있는가?
- 그러려면 먼저 도메인 코드에 대해서 알아야 한다.
또한 다른 서드파티 컴포넌트와 포트를 통해 협력하기에, 외부 시스템 변경에도 용이하다
Use Case는 기존 Service보다 좁은, 기능 단위이기 때문에 넓어지는 Service 문제를 해결할 수 있다.
→ 프로젝트 하다보면 Service가 어마무시하게 뚱뚱해지지 않았는가
헥사고날 아키텍처는 의존의 방향이 레이어드 아키텍처와 다르다.
클린 아키텍처와 마찬가지로 어디에도 의존하지 않는 도메인 객체들이 존재하고, 이들에 의존하는 서비스계층(또는 usecase 계층)이 존재한다.
서비스계층에서 수행되는 비즈니스 로직들은 외부와 연결된 포트를 통해 시스템 외부로 전달되며 인프라는 포트에 의존한다.
한 마디로, 외부와의 통신을 인터페이스로 추상화하여 비즈니스 로직 안에 외부 코드나 로직의 주입을 막는다는 것이 헥사고날 아키텍처의 핵심이다.
실 코드와 함께 보는 헥사고날 주요 컴포넌트
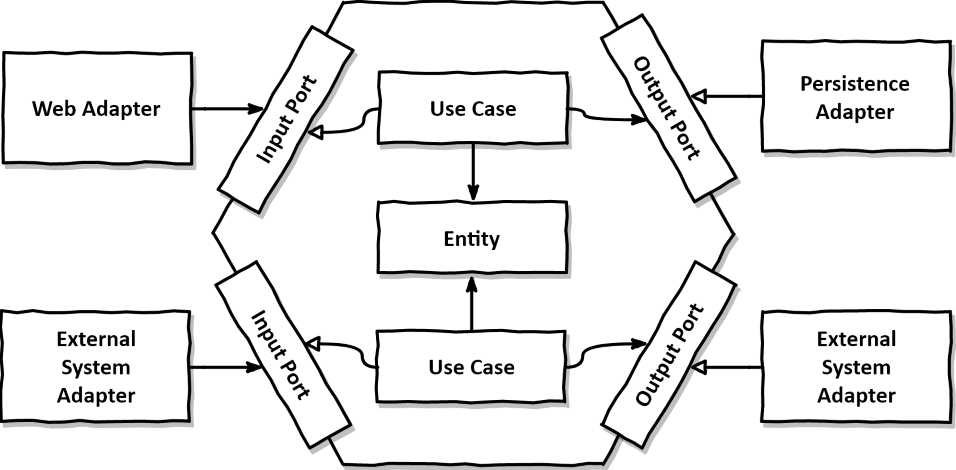
Adapter
- 포트를 통해서 실제로 연결하는 부분을 담당하는 구현체
- Adapter는 애플리케이션 코어에 포트를 통하지 않으면 접근할 수 있는 방법이 없다.
- 오직 포트(Usecase)를 통해서 제공되는 메서드를 이용해야만 핵사고날 내부 코어에 접근할 수 있다.
- Adapter는 2 종류로 분류된다.
-
사용자의 요청을 받아들일 때 사용되는 Adapter : Controller
@RestController @RequestMapping("/account") @RequiredArgsConstructor public class BankAccountController { private final DepositUseCase depositUseCase; private final WithdrawUseCase withdrawUseCase; @PostMapping(value = "/{id}/deposit/{amount}") void deposit(@PathVariable final Long id, @PathVariable final BigDecimal amount) { depositUseCase.deposit(id, amount); } @PostMapping(value = "/{id}/withdraw/{amount}") void withdraw(@PathVariable final Long id, @PathVariable final BigDecimal amount) { withdrawUseCase.withdraw(id, amount); } }→ 일반적으로 애플리케이션 코어에 들어오는 포트를 구현하는 Adapter이다.
→ Adapter라고 명칭을 하는게 맞으나 Controller를 관념상 사용하는 표현이기에 위와 같이 명칭하였다.
→ 입력 어댑터에서는 usecase만을 사용해서 내부에 접근 가능하다.
→ usecase를 둘지, input Port를 둘지 고민을 할 때 usecase가 port보다 추상도가 높기에 usecase를 사용
-
도메인 모델의 처리에 사용되는 Adapter : PersistenceAdapter
@Repository @RequiredArgsConstructor public class BankAccountPersistenceAdapter implements LoadAccountPort, SaveAccountPort { private final BankAccountMapper bankAccountMapper; private final BankAccountSpringDataRepository repository; @Override public BankAccount load(Long id) { BankAccountEntity entity = repository.findById(id) .orElseThrow(NoSuchElementException::new); return bankAccountMapper.toDomain(entity); } @Override public void save(BankAccount bankAccount) { BankAccountEntity entity = bankAccountMapper.toEntity(bankAccount); repository.save(entity); } }→ repository, 즉 영속 계층을 호출해서 DB 작업을 한다.
→ 출력 어댑터쪽에서 추상화 계층인 출력 포트를 구현해주게 된다.
→ 해당 PersistenceAdapter을 누가 호출하는 걸까?
-
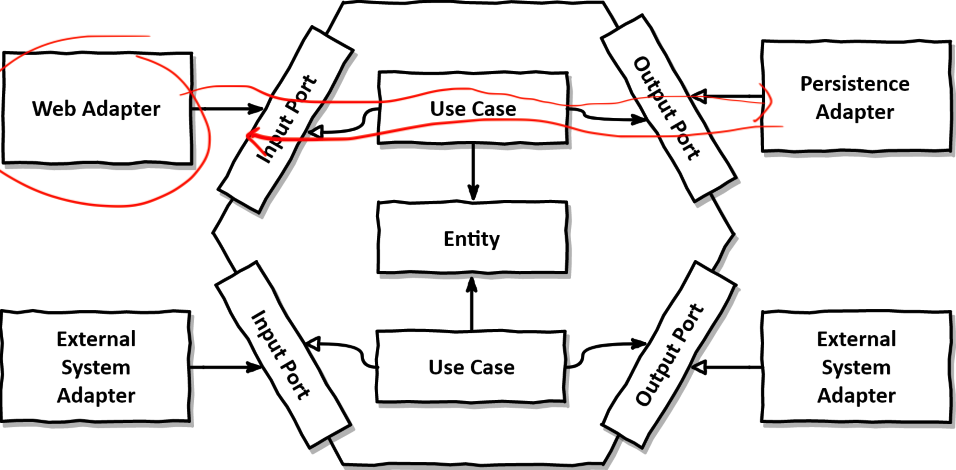
→ 외부 API 요청을 받은 Web Adapter(Controller)에서 요청을 받아서, usecase를 구현한 inputPort(현재 코드에서는 Port 없이 usecase 대신 바로 Service에서 구현함)에서 Out Port에 요청을 하면, Out Port는 출력 Adapter에 접근해 실 DB를 조회한다.
여담
머리가 개 띵했음…
위 사진을 보면 Entity가 persistence 아래 있었다.
헥사고날에서 말하는 도메인은 Entity가 아니었다. 진짜 도메인 그 자체였던 것이었다.
→ 비즈니스 로직은 도메인에 작성되어있고, Service에서는 해당 도메인 로직을 호출하기만하는
영속 계층 자체를 아예 서드파티처럼 구분한다는게 너무 놀라웠다…
Port
- 서비스(또는 usecase)에 어댑터에 대한 명세(specification)만을 제공하는 계층을 의미한다.
- 단순히 인터페이스 정의만 존재하며, DI를 위해 사용된다.
Input Port
@Service
public class FindMemberInputPort implements FindOneMemberUseCase {
private final MemberFindOutputPort memberFindOutputPort;
public FindMemberInputPort(MemberFindOutputPort memberFindOutputPort) {
this.memberFindOutputPort = memberFindOutputPort;
}
@Override
public Optional<Member> findOne(String userId) {
return memberFindOutputPort.findOne(userId);
}
}
---
@Service
public class RegisterMemberInputPort implements JoinMemberUseCase {
private final MemberJoinOutputPort memberJoinOutputPort;
public RegisterMemberInputPort(MemberJoinOutputPort memberJoinOutputPort) {
this.memberJoinOutputPort = memberJoinOutputPort;
}
@Override
public void join(String userid, String pw) {
memberJoinOutputPort.join(userid, pw);
}
}- 현재 우리 프로젝트에서는 Port를 사용하지 않고, 하나의 Service에서 usecase를 바로 구현을 했기에 다른 프로젝트의 Port 코드를 가지고 왔다.
- 입력 포트의 역할은 유스케이스를 구현하는 것이다. 출력 포트(DB 접근)를 사용해 유스케이스를 구현해준다.
- 우리는 해당 유스케이스 구현 역할을 Service에 넘겨주었다.
Output Port
public interface MemberFindOutputPort {
Optional<Member> findOne(String userId);
}
---
public interface MemberJoinOutputPort {
Long join(String userid, String pw);
}- 외부 리소스에서 데이터를 가져오는 역할이다. 출력 포트는 인터페이스로 추상화하고, 실제 구현은 출력 어댑터에 할당하게 된다.
Application Service(usecase)
- 어댑터를 주입 받아 도메인 모델과 어댑터를 적절히 오케스트레이션하는 계층을 의미합니다.
- 예를들어 게시글 작성이라는 usecase는 그에 필요한 Adapter를 주입받고 게시글 도메인 모델을 적절히 제어하는 로직을 지닙니다.
@Service
@RequiredArgsConstructor
public class BankAccountService implements DepositUseCase, WithdrawUseCase {
private final LoadAccountPort loadAccountPort;
private final SaveAccountPort saveAccountPort;
@Override
public void deposit(Long id, BigDecimal amount) {
BankAccount account = loadAccountPort.load(id);
account.deposit(amount);
saveAccountPort.save(account);
}
@Override
public boolean withdraw(Long id, BigDecimal amount) {
BankAccount account = loadAccountPort.load(id);
boolean hasWithdrawn = account.withdraw(amount);
if(hasWithdrawn) {
saveAccountPort.save(account);
}
return hasWithdrawn;
}
}- 내가 이해한 Service는 Input Port에 따른 요청과 Output Port에 요청해받은 응답값을
도메인의 비즈니스 로직을 잘 스까서 다시 InputPort로 전달하는 책임을 가지고 있다. ← 오케스트레이션이라는게 잘 스까는거라고 이해를 했다.
Domain Model
- DDD의 도메인 모델과 동일한 개념을 가지고 있다.
- 엔티티 변경에 대한 모든 로직은 해당 계층에서만 실행된다.
- 외부 Adapet에서 외부 Port로 엔티티를 리턴할 때 도메인 객체로 변환해서 넘겨준다.
@Override public BankAccount load(Long id) { BankAccountEntity entity = repository.findById(id).orElseThrow(NoSuchElementException::new); return bankAccountMapper.toDomain(entity); }
public class BankAccount {
private Long id;
private BigDecimal balance;
@Builder
public BankAccount(Long id, BigDecimal balance) {
this.id = id;
this.balance = balance;
}
public boolean withdraw(BigDecimal amount) {
if(balance.compareTo(amount) < 0) {
return false;
}
balance = balance.subtract(amount);
return true;
}
public void deposit(BigDecimal amount) {
balance = balance.add(amount);
}
public BigDecimal getBalance() {
return balance;
}
}- 도메인 모델을 사용함으로써 얻는 이점
명확한 관심사의 분리-
외부와의 연결에 문제가 생기면
Adapter를 확인하면 될 것이고, 인터페이스의 정의를 변경하고자 한다면Port를 확인하면 됩니다. -
처리 중간에 Custom Metric 측정을 위해 Event Bridge에 이벤트를 보내거나 트레이스를 로그를 심고 싶다면
Service(usecase)를 확인하면 됩니다. -
마지막으로 비즈니스 로직이 제대로 동작하지 않는다면
Domain Model만 확인하면 되는 것이지요.이러한 구조는 결국 쉬운 테스트를 가능하게 해주기도 합니다. 본인의 역할을 수행하기 위해 필요한 Port만 모킹하여 테스트를 쉽게 수행할 수 있습니다.
-
핵사고날에서 발생하는 깨진 창문
- 만약 Port의 네이밍이 범용적이면 여러 usecase를 구현해야 하므로, port가 뚱뚱해지고 이에 따라서 외부 의존성이 늘어날 수록 코드의 로직이 깨지기 쉽고 유지보수 하기 어려워진다.
- port의 이름이 너무 세부적이고, 지엽적이면 보일러 플레이트의 양이 과도하게 많아지게된다.
- 의존성이 적다는 점에선 SRP를 잘 구현했다고 느낄 수 있지만, 현실적인 개발 세계에서는 개발 속도 또한 굉장히 중요한 요소 중 하나이기에 이를 간과해서는 안된다.
즉 MVC 코드가 레거시처럼 느껴질 수 있지만, 아키텍쳐 그 자체보다는 코드가 지니는 가치와 생산성에 집중을 하면 절대 나쁜 코드는 아니다.
반드시 trade-off를 계산하여서 프로젝트의 성격에 맞게 개발을 진행해야 한다.
현재 내 Flow
- 입력 어댑터를 통해 외부에서 요청 들어옴
- 입력 어댑터에서는 추상화된 유스케이스를 사용하지만, 실제 주입되서 사용되는건 usecase를 구현한 BankAccoutService
- 유스케이스에서 추상화된 출력 포트를 사용하지만, 실제 주입되서 사용되는건 출력 어댑터
- 도메인을 사용하는건 출력 어댑터. (입력 어댑터쪽도 유스케이스를 통해 도메인을 리턴받을 수 있음)
참고 레퍼런스
