개요
이 장은 단일 서버로 부터 대규모 이용자들 처리할 수 있는 서버로의 확장 과정에서 고려해야 할 부분에 대해서 다룬다. 이 장의 마지막에 작성된 내용이 이 장을 요약할 수 있다.
- 웹 계층은 무상태 계층으로 만든다.
- 모든 계층에 다중화를 도입하라
- 가능한 많은 데이터를 캐싱하라.
- 여러 데이터 센터를 지원하라.
- 정적 콘텐츠는 CDN을 통해 서비스하라.
- 데이터 계층은 샤딩을 통해 규모를 확장하라.
- 각 계층은 독립적 서비스로 분할하라.
- 시스템을 지속적으로 모니터링하고, 자동화 도구를 활용해라.
이 내용들을 기억하며 책을 따라가면서 어떻게 아키텍처가 변화하는지 살펴보자.
단일 서버
단일 서버란 그 이름에서 알 수 있듯이, 서버를 이루고 있는 모든 개체들이 단 하나의 PC에서 운용되는 상태를 말한다.
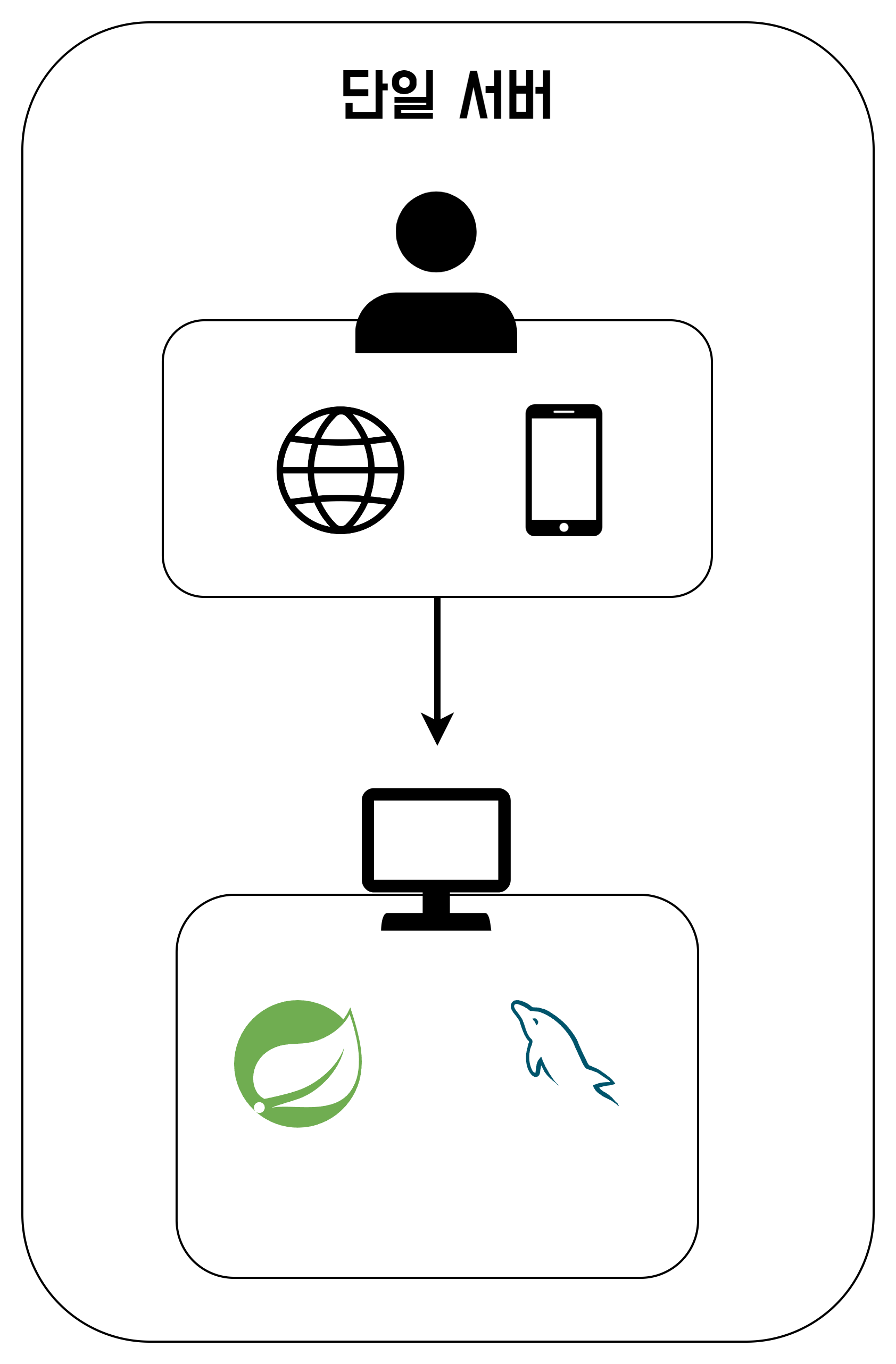
단일 서버에서 나타날 수 있는 문제는 뭘까?
아무래도 서버의 사양이 한정되기 때문에, 많은 유저들의 요청에 대응하기 어려움이 있을 것이다.
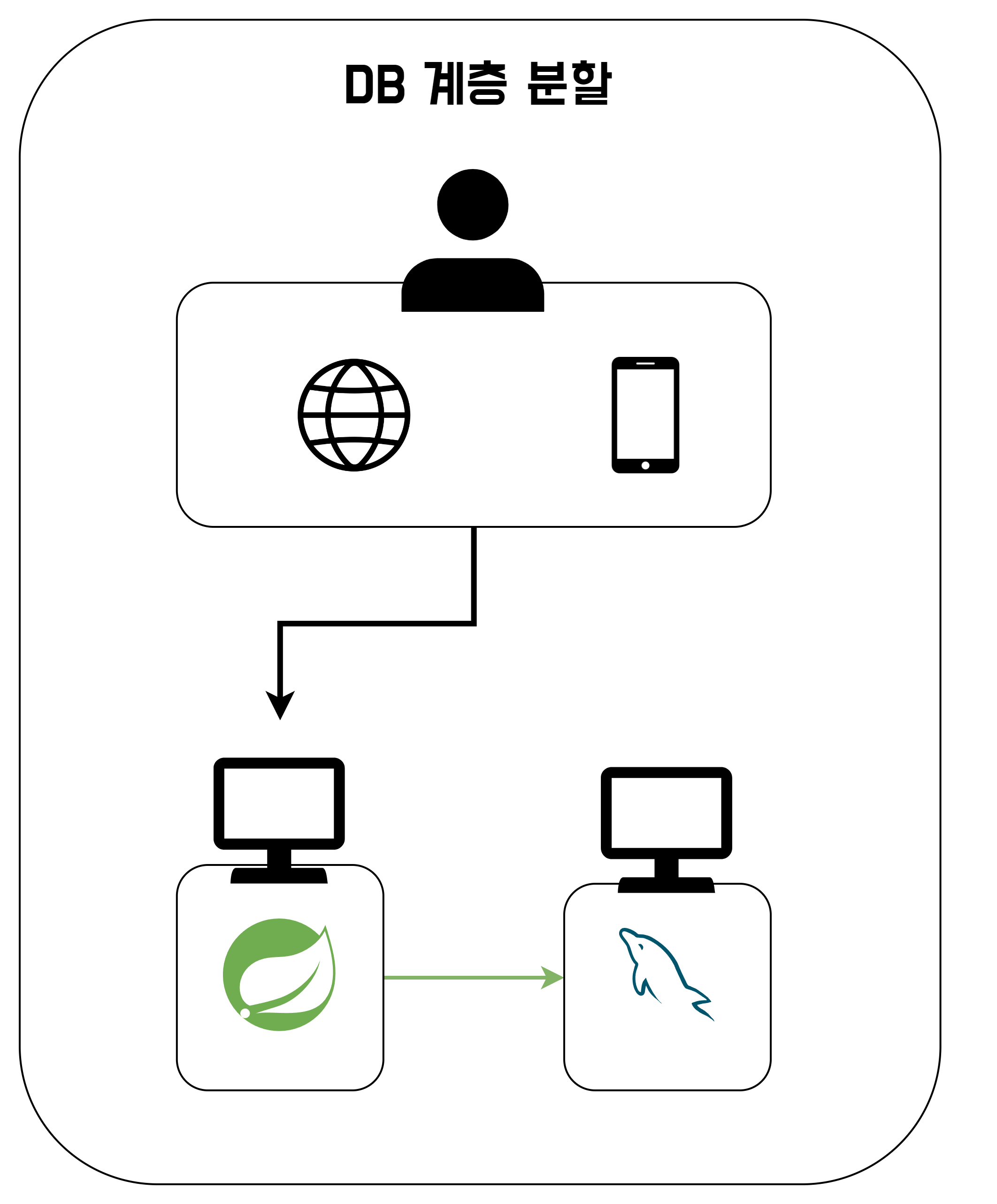
DB 계층 분할
단일 서버로는 조금 처리가 어려워서, 서버를 추가로 구매하려고 한다. 그리고 하나의 서버에서는 웹서버를 띄우고, 다른 하나의 서버에서는 DB를 띄우려고 한다. 이를 통해 PC가 2대가 됐기 때문에, 서버 자원이 늘어났으니 단일 서버보다는 더 많은 요청을 처리할 수 있을 것이다.
로드 밸런서 도입
그런데 서비스가 성공해서, 사용자들이 계속 늘어난다. 서버 2대로는 조금 벅차보이는데, 추가로 서버를 구매하려고 한다. 하지만 서버 사용율을 보니 DB서버는 괜찮은데, 웹서버의 자원 사용율이 상당히 높은 것을 확인해, 웹서버를 증설하려고 한다.
웹 서버를 증설하면서, 각 서버에 대해서 동등하게 트래픽을 배분하기 위해 로드 밸런서까지 추가로 도입한다.
그러면 아래 그림과 같이 서버가 구성된다.
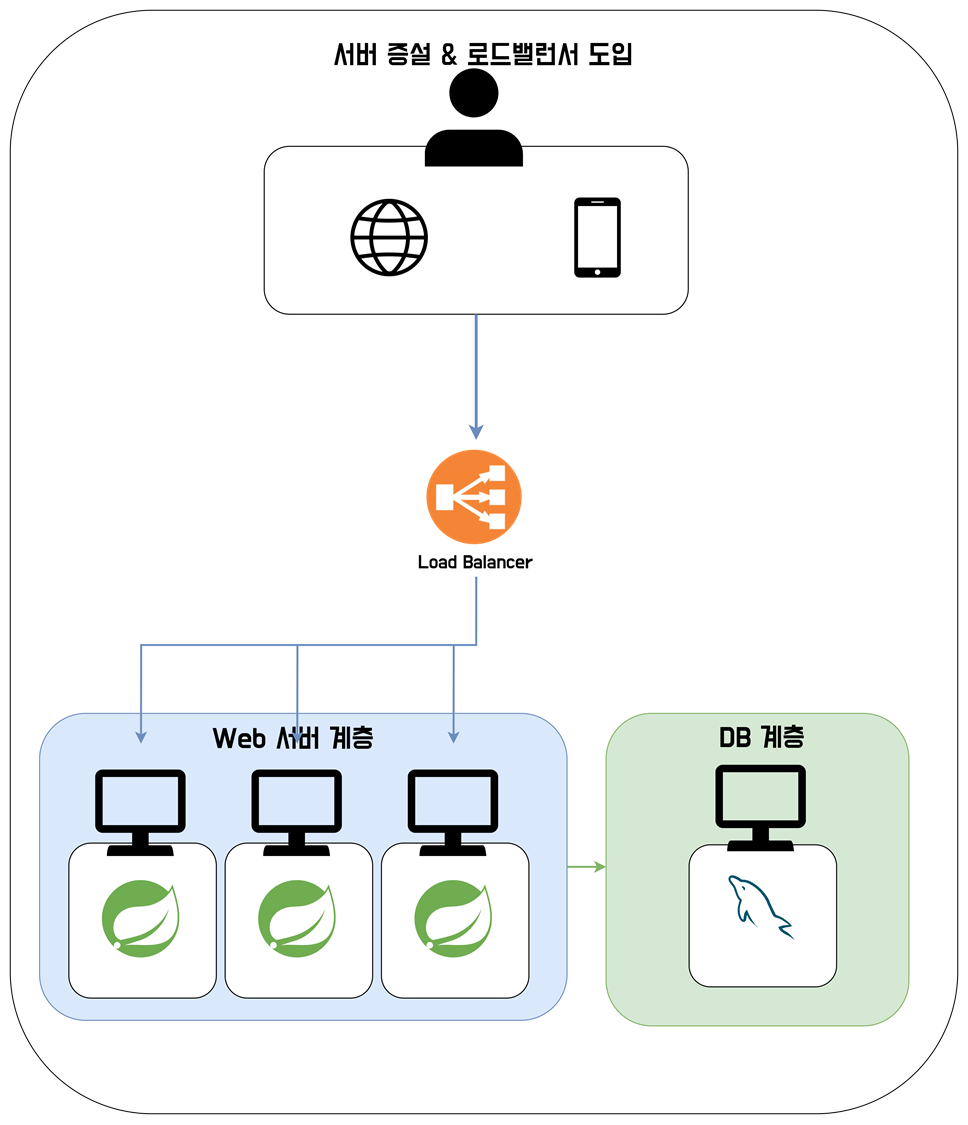
이젠 웹 서버도 여러 대가 되었고, 각자 트래픽을 분산할 수 있어서 확실히 더 많은 유저들의 트래픽을 처리할 수 있게 되었다. 그리고 하나의 서버가 죽더라도, 다른 서버들이 있기 때문에, 서버의 안정성이 상승했다.
DB 계층 다중화
더 많은 트래픽을 처리하다 보니, 이젠 단일 DB 서버 역시 더이상 처리가 어렵게 되었다. DB 서버 역시 다중화 처리를 해주려고 한다.
DB는 주로 읽기 작업을 많이 처리한다. 이런 특성을 활용해 DB는 Master-Slave 패턴을 사용할 수 있다. Master DB는 쓰기 작업을 담당하고, Slave DB는 읽기 작업을 담당한다. Master DB는 쓰기 작업이 진행된 후 Slave DB에게 동기화 처리를 해주는 것으로 둘의 싱크를 맞춰준다.
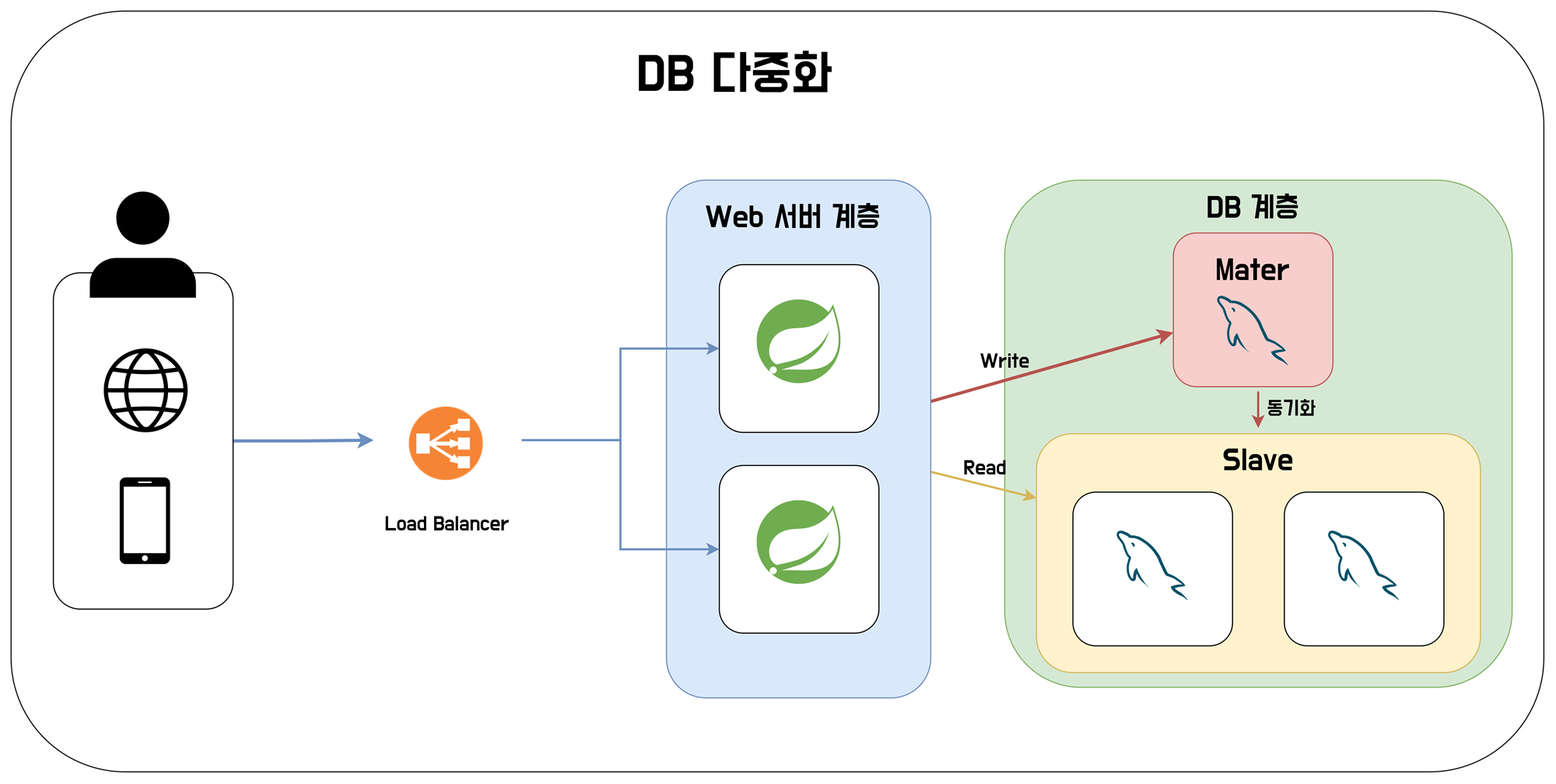
DB 계층을 다중화한 것을 통해 DB 서버가 여러 대가 되었으니 성능 개선과 하나의 DB 서버가 죽더라도, 다른 서버들이 대체가 가능해 안정성이 상승한 효과를 볼 수 있었다.
중간 정리 1
지금까지 단일 서버에서 DB 계층 분리, 서버 다중화 및 로드밸런서 도입, DB 서버 다중화를 통해 더 많은 트래픽을 받을 수 있는 처리를 해주었다.
가장 처음에 요약에 있었던, 모든 계층을 다중화하라에 대한 작업을 진행했던 것이다. 다중화를 통해 1차적으로 서버 자원이 늘어났기 때문에 성능이 좋아졌다. 그리고 서버 중 하나가 죽더라도 다른 서버들이 그 역할을 수행하고 있기 때문에, 안정성이 늘어나는 효과를 볼 수 있었다.
캐시 도입하기
이제는 서비스의 성능으 개선하려고 한다. 성능 개선에 가장 효과적인 방법으로는 캐시를 도입하는 것이다. 캐시는 주로 메모리에 적재하여 데이터를 DB에서 조회하는 것에 비해서 상당히 속도가 빠르다.
캐시를 사용하게 될 경우 몇가지 고려해야 할 문제가 있다.
- 어떤 정보를 저장할 것인가?
- 어떻게 캐시를 삭제할 것인가?
- 얼마나 오랫동안 캐시를 저장할 것인가?
- 캐시 계층의 오류가 발생하면 어떻게 할 것인가?
- 캐시 정보와 실제 정보를 어떻게 일치시킬 것인가?
또한 다양한 캐싱 전략도 있으니, 추후에 찾아보길 바란다. 아무튼 캐시 계층을 추가하면 다음과 같은 아키텍쳐가 생성된다.
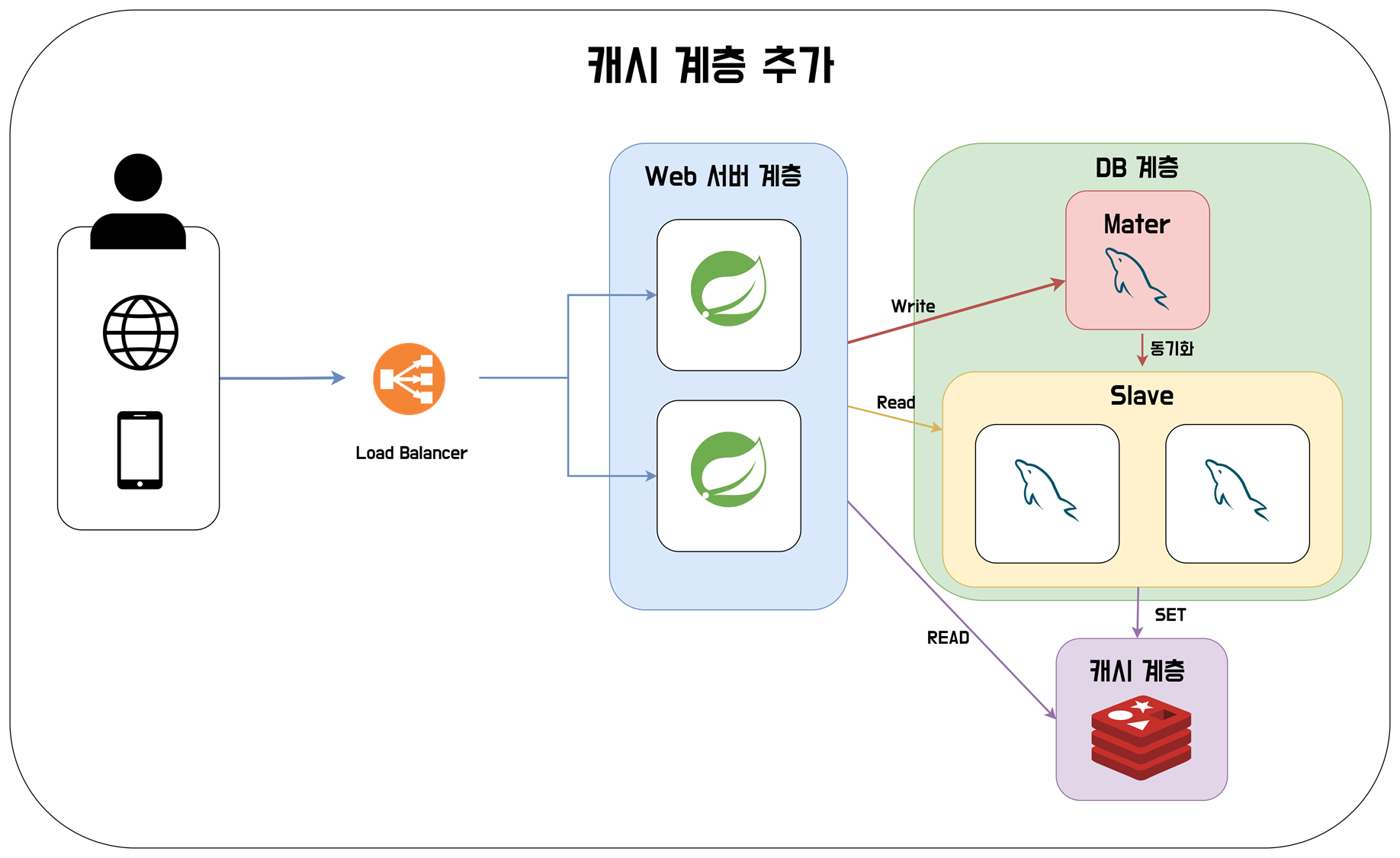
무상태 아키텍처로 구성하기
무상태 아키텍처란 서버가 상태 정보를 갖지 않는 것을 말한다. 서버가 클라이언트의 상태 정보를 갖고 있을 경우, 현재와 같은 다중화 상황에서 클라이언트 <-> 서버간 통신에 서버에 저장된 상태 정보를 이용하기 위해선 반드시 동일한 서버와 통신을 하는 Sticky Session 상태이거나, 모든 서버에 상태 정보를 동기화시켜주는 Session Clustering 작업이 필요하다.
이 두 방법 모두 문제가 발생한다. 먼저 sticky session의 경우 로드 밸런서에도 무리가 가고, 특정 서버에 트래픽이 몰리게 된다면, 로드 밸런싱이 불가능하다는 특징이 있다. 그 다음으로 Session Clustering 작업의 경우 세션 정보를 모든 서버에 동기화 시키는 과정에서 자원 낭비가 발생할 수 있다.
가장 권장되는 방법은 서버의 상태를 저장하는 추가적인 저장소를 배치하는 것이다. 방법은 DB, NoSQL 등.. 다양하게 존재한다. 이를 추가해보자.
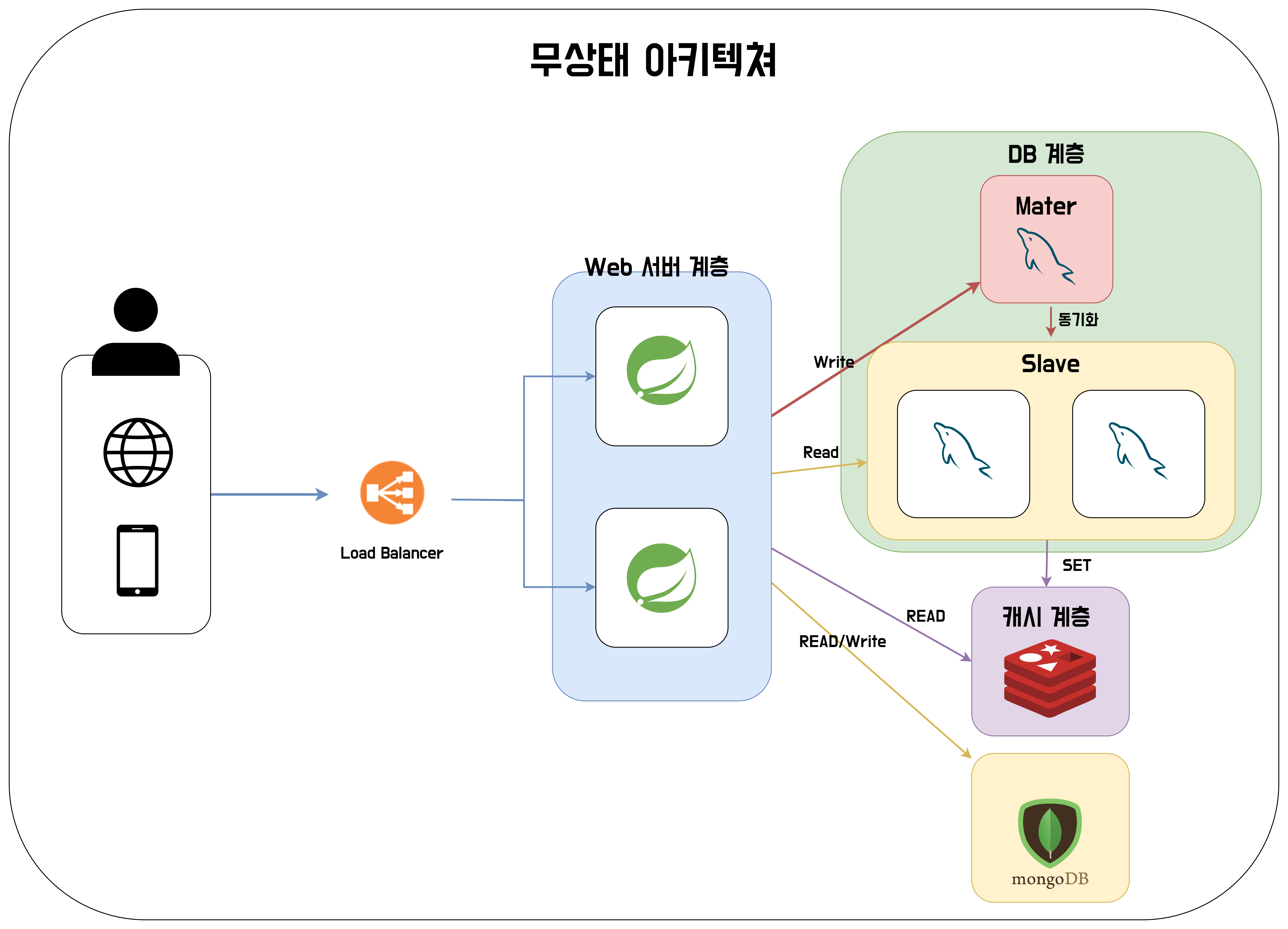
이를 통해 상태를 갖지 않는 아키텍처를 완성할 수 있었다.
메세지큐로 서버를 독립적으로 구성하기
Web 서버 계층을 만들고자 할 때, 모든 기능을 가진 application을 계속 추가하는 것을 효율적이지 않을 수 있다. 하나의 서버에서 기능 A와 B가 있는데, B 기능의 활용도가 9할인 상황에서, A 기능까지 추가 할 필요는 없다고 생각할 수 있기 때문이다.
이를 위해 A 기능과 B 기능을 처리하는 서버를 분리해보자.
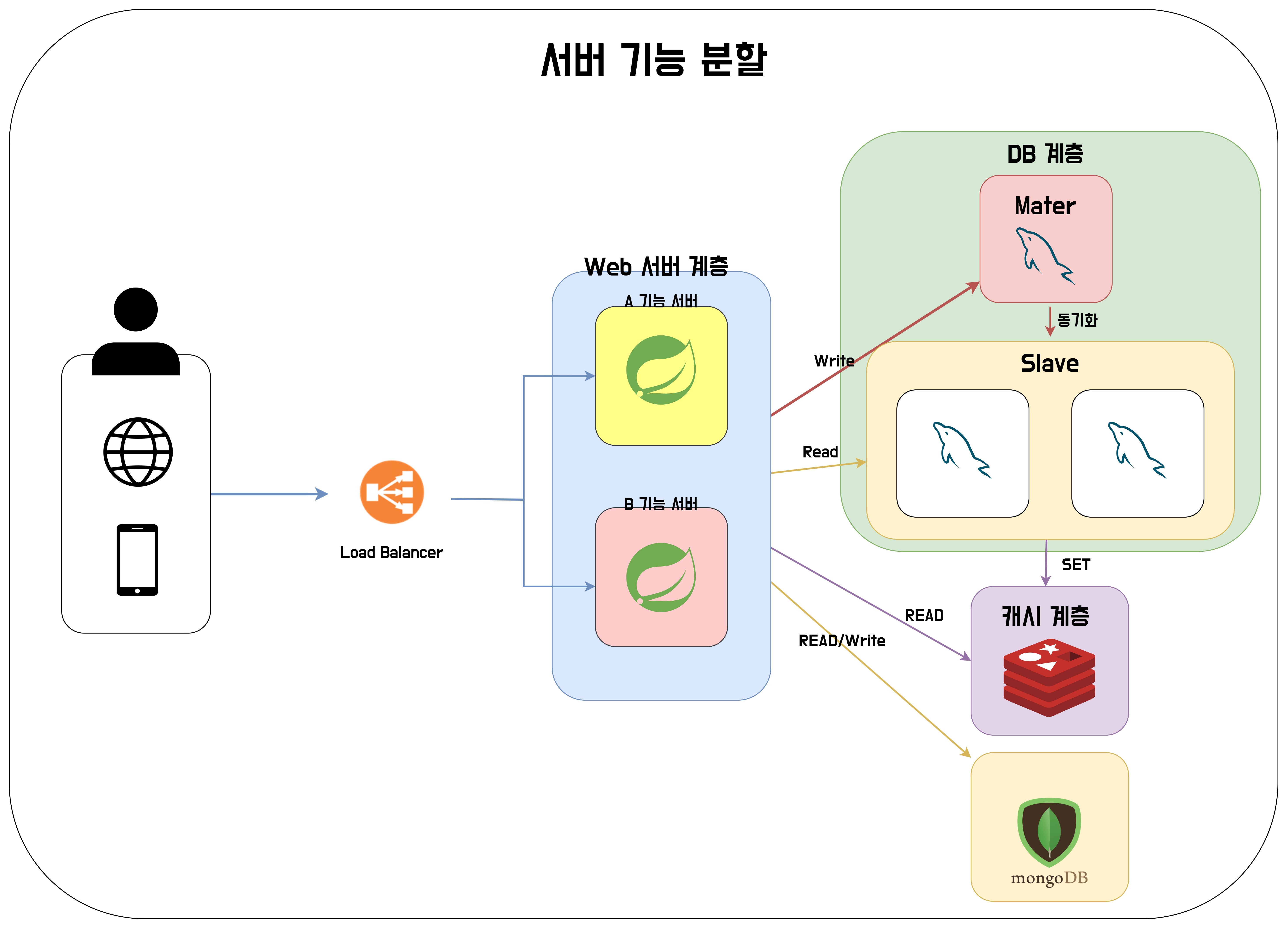
뭐.. 아래와 같이 구성할 수 있을 것 같다. 하지만 A 기능과 B 기능이 서로 연관된다면 A 서버가 B 서버를 호출하는 등의 일이 발생할 것이다. 그렇다면 A 서버에서는 B 서버에 대한 의존성을 갖게 될 것이다. 단 두개의 경우에서는 별것이 아니라고 생각이 될 수 있겠지만.. A 기능이 B, C, D, E ... 이렇게 많은 기능들에 연관을 갖고 있다면 A서버를 B,C,D,E... 서버들을 호출하는 것에 대한 어려움도 있을 것이고, 서버를 확장하는데 어려움이 생길 것이다. 이를 위해 구독-발행 패턴을 적용할 수 있는 메세지큐를 도입해보자.
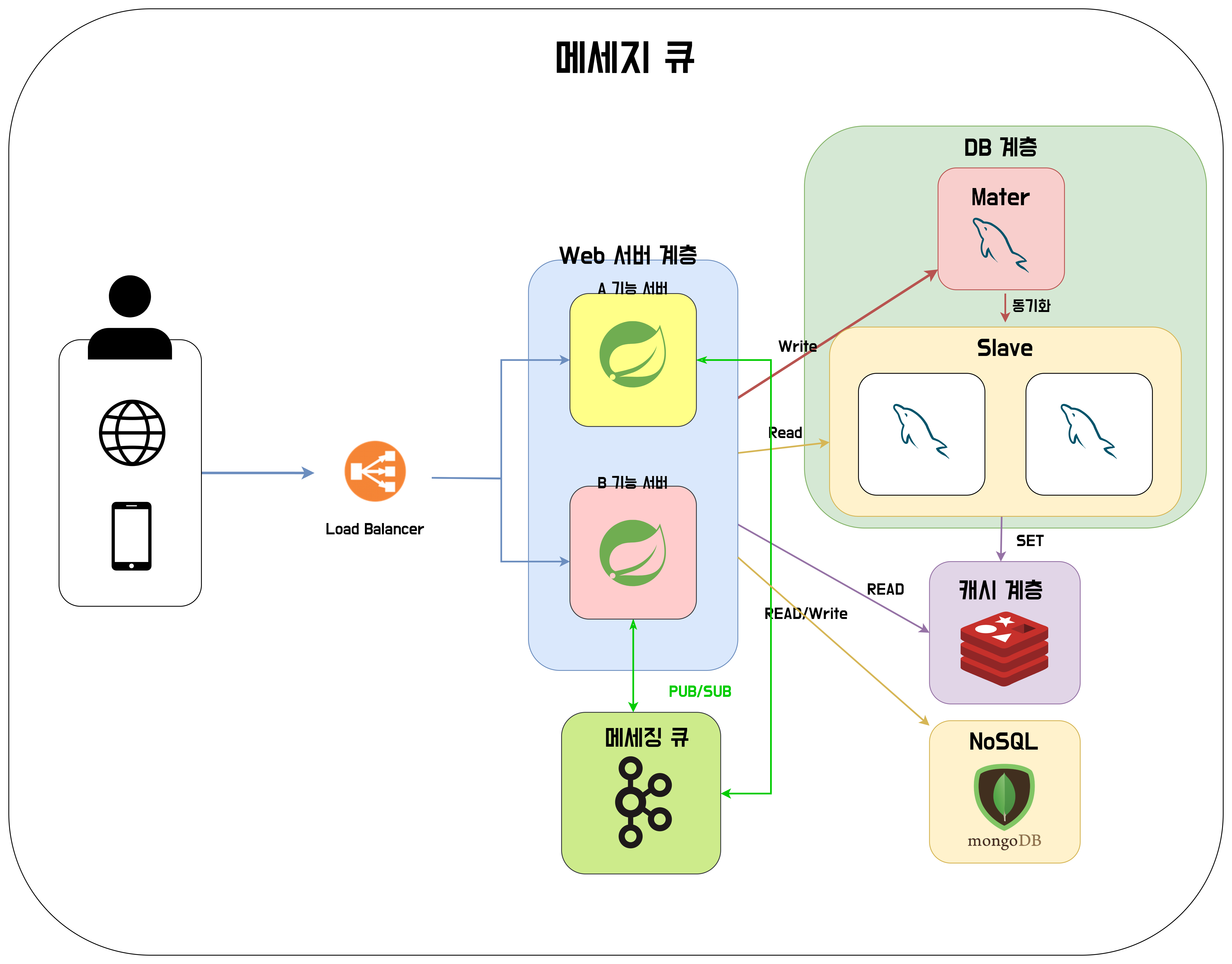
이젠 서버간의 독립성을 얻을 수 있게 되었다.
DB 규모확장
DB에 쌓이는 부하에 대해서는 다중화 작업을 통해 처리는 해줬는데, DB에 데이터 자체가 많이 쌓이니까 용량이 부족해진다. DB에 대한 규모를 확장해줘야 할 시기가 온 것이다.
규모 확장 방법은 2가지로 스케일 업과 스케일 아웃이 존재한다.
스케일 업은 서버의 스펙 자체를 업그레이드 시키는 것이다. CPU, Memory, Storage의 사이즈를 업그레이드 시키는 것이다. RDBMS를 사용하는 경우 스케일업이 쉽지만, 스케일업 자체는 비용도 많이 들고 업그레이드 하는 한계가 명확하게 존재한다.
그래서 보통은 스케일 아웃 방법을 이용한다.
DB의 경우 스케일아웃을 하는 방법으로는 샤딩을 사용한다. DB의 데이터를 각종 알고리즘을 사용해 저장하는 위치 자체를 정한다. 샤딩을 사용하더라도 특정 영역에 많은 데이터가 쏠리게 된다면 이후 균등작업을 해줘야 한다는 것을 잊지 말아야 한다.
정리
지금까지 1장에 있는 내용에 따라서 단일 서버부터 DB의 스케일 아웃까지 알아보았다. 그럼 처음에 나왔던 리스트를 다시 한번 확인해보자. 사실 이 내용을 정리하면서 CDN, DS, 모니터링은 안했지만, 그 외에는 이 과정을 통해서 충분히 이해할 수 있다고 생각한다.
- 웹 계층은 무상태 계층으로 만든다.
- 모든 계층에 다중화를 도입하라
- 가능한 많은 데이터를 캐싱하라.
- 여러 데이터 센터를 지원하라.
- 정적 콘텐츠는 CDN을 통해 서비스하라.
- 데이터 계층은 샤딩을 통해 규모를 확장하라.
- 각 계층은 독립적 서비스로 분할하라.
- 시스템을 지속적으로 모니터링하고, 자동화 도구를 활용해라.
