
📌 NLP(Natural Language Processing)
📄 Introduction
자연어(Natural Language) 를 다루는 분야는 여러가지가 있는데, 크게 다음과 같이 분류할 수 있다.
-
Natural Language Processing
-
Text Mining
-
Information Retrieval
✅ Natural Language Processing (Major conferences : ACL,EMNLP,NAACL)
NLP(Natural Language Processing) 는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 분야로 , 크게 다음과 같이 분류할 수 있다.
-
Low-level Parsing
-
Tokenization: 텍스트 자체를 처리할 수 없기 때문에 말뭉치(Corpus)를 문법적으로 더 이상 나눌수 없는 토큰(Token)으로 분리하는 작업이다.
-
Stemming: 텍스트 안에서 많은 조건에 따라 변화된 단어로부터 어간(Stem)을 추출하는 작업이다. 예를들어,
play는plays,playing,played등과 같이 조건에 따라 달라지게 되는데, 어간play를 추출한다.
-
-
Word and Pharse level
-
Named Entity Regocnition(NER): 이름을 가진 개체(Named Entity,고유명사)를 인식하는 것으로, 어떤 이름을 의미하는 단어를 보고 그 단어가 어떤 유형인지를 인식하는 작업이다. 예를들어,
"New York Times"를 각각의 단어로 보는 것이 아닌 하나의 고유명사로 인식한다. -
Part-Of-Speech(POS) Tagging: 문장 내 단어들의 품사를 식별하여 태그를 붙여주는 작업이다.
-
-
Sentence Level
-
Sentiment analysis: 주어진 텍스트의 positive,negative 등 text polarity 를 파악하는 작업이다.
-
Machine Translation: 한 언어에서 다른 언어로 텍스트나 음성을 번역하는 작업이다.
-
-
Multi-sentence and Paragraph Level
-
Entailment Prediction: 문장간의 함의(Entailment)를 파악하는 작업이다. 예를들어,
"어제 나는 결혼했다"와"어제 최소한 한명은 결혼했다"라는 텍스트가 주어졌을 때, 첫번째 텍스트가 참이라면 두번째 텍스트는 참이 되는데, 이와 같이 문장간의 연관성을 파악한다. -
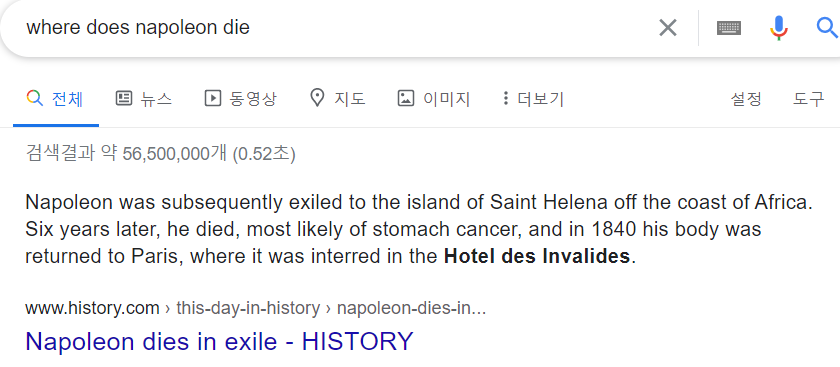
Question Answering: 질문이 가진 의미를 파악하여 정답을 도출하는 작업이다. 예를들어,
Where does napoleon die?를 구글에 입력하였을때, 그 의미를 정확히 파악하여 다음과 같이 정답을 도출한다.
-
Dialog Systems: 챗봇 같이 대화시스템(Dialog Systems)을 위한 작업이다.
-
Document Summarization: 주어진 문서의 내용을 자동으로 요약하는 작업이다.
-
✅ Text Mining (Major conferences : KDD,The WebConf(formerly,WWW),WSDM,CIKM,ICWSM)
Text Mining 은 대규모 텍스트 형태의 비정형 데이터로 유의미한 정보를 이끌어 내는 분야로, 대표적으로 Document Clustering(Topic Modeling) 과 같이 연관 있는 문서들을 그룹화 하는 작업이 있으며, 최근에는 SNS를 통한 사회망이 대두된 시점에서 유의미한 정보를 이끌어 내고 있다. 주요 컨퍼런스로는 KDD,The WebConf(formerly,WWW),WSDM,CIKM,ICWSM 가 있다.
✅ Information Retrieval (Major conferences : SIGIR,WSDM,CIKM,RecSys)
Information Retrieval 은 집합적인 정보로부터 원하는 내용과 관련이 있는 부분을 얻어내는 분야로, 대표적으로 검색을 했을 때 원하는 정보를 도출하는 검색 시스템 / 사용자가 직접 검색하지 않아도 선제적으로 사용자와 밀접한 정보를 도출하는 추천 시스템 이 있다.
📄 Bag-Of-Words
기계는 텍스트 자체를 이해할 수 없으므로, 수치화 하여 기계가 알아들을수 있게 해야한다. Bag-Of-Words 는 수치화 하는 기법중 하나로, 단어들의 순서는 고려하지 않고, 출현빈도(Frequency) 기반의 단어 표현 방법이다.
✏️ Concepts
✅ Step 1

단어들의 빈도수를 파악하기 위해서는 주어진 텍스트를 단어의 집합들로 표현해야 한다. 가장 간단한 방법은 주어진 텍스트에서 중복된 단어를 제거하고 유일한 단어들을 모아 Vocabulary set 을 생성하는 것이다.
✅ Step 2

주어진 vocabulary set을 one=hot vector 를 이용하여 수치화 한다. 즉, 위와 같이 8개의 단어를 가지는 vocabulary가 있다고 가정했을 때, 8-dimension 벡터를 생성하여 표현하고 싶은 단어의 인덱스를 1, 이 외에는 0 으로 표현한다. 이렇게 생성된 벡터 공간의 벡터들은 유클리드 거리 = , 코사인 유사도 = 0 을 가져 단어의 의미와 상관없이 모두 동일한 관계를 가지게 된다.
✅ Step 3

one-hot vector로 표현된 단어들을 이용하여 주어진 텍스트의 단어 빈도수를 표현한다.
✏️ Naive Bayes Classifier
📄 Word Embedding
Bag-Of-Words에서 언급했지만, 자연어를 기계가 이해하고 효율적으로 처리하기 위해서는 적절히 변환하여 수치화 해야한다. 이것이 중요한 이유는 단어를 표현하는 방법에 따라 NLP 의 성능이 크게 달라지기 때문이다. 예로,위에서 살펴봤던 one-hot vector 의 경우 간단하게 데이터를 표현할 수 있지만, 다음과 같은 명확한 한계점을 가지고 있다.
-
Sparse vector로 많은 공간적 낭비를 일으킨다. -
아이템이 많아졌을 경우
one-hot vector의 사이즈가 급격히 늘어난다. -
단어의 속성이 벡터에 반영되지 않는다.
최근에는 이런 한계를 개선시켜 단어를 공간상의 하나의 점인 dense vector 로 표현하는 word embedding 을 많이 사용하고 있다.
✏️ Word2Vec
Word2Vec 의 핵심 아이디어는 언어학의 Distributional Hypothesis 이다. Distributional Hypothesis 란, "비슷한 분포를 가진 단어들은 비슷한 의미를 가진다" 로 조금 더 쉽게 표현하면 "같이 등장하는 횟수가 많을 수록 두 단어는 비슷한 의미를 가진다" 이다.
기본적으로 Word2Vec는 one-hot vector를 입력으로 받아 하나의 hidden layer를 거쳐 출력하는 shallow neural network 로 일반적인 hidden layer와는 달리 activation function이 존재하지 않고 단순히 look-up 연산을 담당하는 층이며 projection layer 라고 부르기도 한다.
Word2Vec에는 다음과 같이 두가지 방식이 존재하는데, `
-
CBOW(Continuous Bag Of Words)
-
Skip-Gram
CBOW만 제대로 이해한다면 Skip-Gram 역시 쉽게 이해할 수 있기 때문에 CBOW를 자세히 살펴보도록 한다.
✅ CBOW(Continuous Bag Of Words)
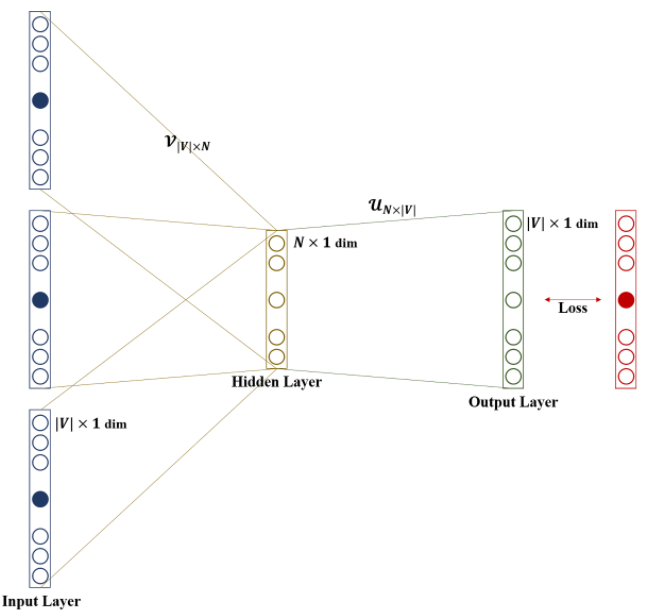
CBOW은 주변단어(Context Word,문맥)를 이용하여 중심 단어(Center Word)를 예측하는 모델 이다. 이때, 몇개의 주변단어를 살필지를 결정하는 범위를 window 라고 정의하여 window size 만큼 앞,뒤 단어를 살핀다. 예를들어,"The fat cat sat on the mat" 라는 문장이 있다면, 중심단어가"cat" 이고 window size=2 일때, 4개의 주변단어 {the,'fat','sat','on'} 로부터 "cat"을 예측한다. 그래서 만약 window size=n 이라면 실제 중심 단어를 예측하기 위해 참고하는 주변단어의 개수는 2n 개 이다.
이제 window size를 정했다면 다음과 같이 sliding window 방식으로 윈도우를 움직여서 주변단어와 중심단어를 바꿔가며 학습을 위한 데이터셋을 만들게 된다.
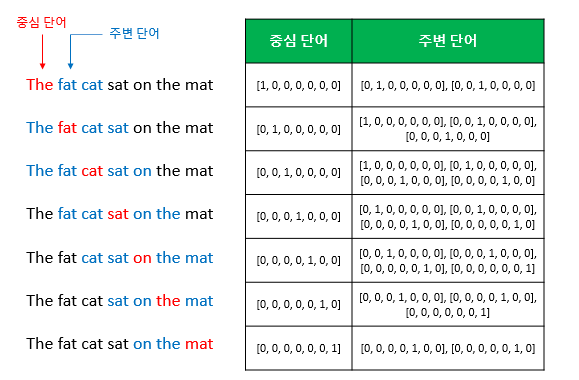
준비된 학습데이터 셋을 가지고 어떻게 학습되는지 구체적인 예시로 살펴보기 위해 중심단어='the' ,window size=2,주변단어={'fat','cat'} 이라고 가정하며 다음과 같이 notation을 정의한다.
- =vocabulary의 크기
- =projection layer의 크기
- =window 크기
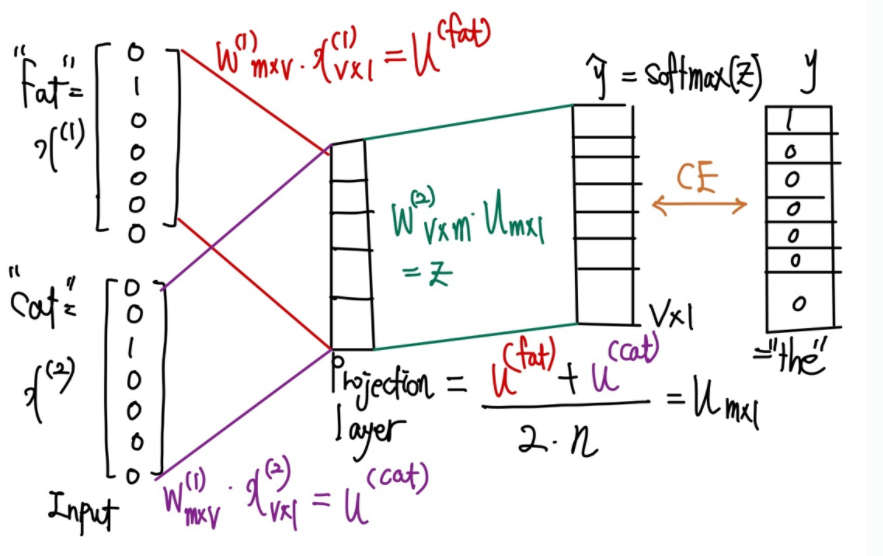
위의 그림을 바탕으로 하나씩 살펴보면 ,
-
n=2이므로2n=4개의 입력을 받아야 하지만,"the"앞에 단어가 없으므로"fat"= ,"cat"= 을 받는다. -
mxv가중치 행렬 과 행렬곱 을 얻고, 과 행렬곱 을 얻는다. -
그 후
2n개 벡터들의 평균u를 얻는다.
-
vxm가중치 행렬와 행렬곱의 결과 을 얻은 후softmax를 취해 0~1 사이의 실수, 각 원소의 총합은 1인 score vector 을 얻는다. 이때, score vector 의 각 값은 i 번째 단어가 중심단어일 확률을 나타낸다. -
score vector와 실제 알고 있는 중심단어
"the"= 의 오차를 줄이기 위해CE(Cross Entropy)함수를 사용한다.
-
이때, 가 i번째 단어라면 i번째 값만 1이고 나머진 0이기 때문에,
를 최소화하는 문제와 같다.
여기서 주목해야 할 것은 가중치 행렬 과 입력벡터의 행렬곱 연산이다. 를 예로 보면,
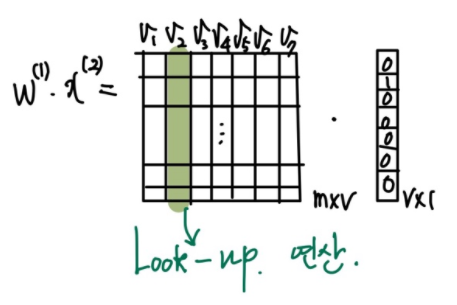
행렬곱연산을 하고 있는 것 같지만 실질적으로는 "cat"= 의 값이 1인 인덱스 , 즉, 의 column을 살펴보는(Look-up) 연산에 불과하다. 즉, 은 각 단어들의 embedding vector를 column으로 묶어 놓은 것이다. 따라서 embedding은 해당 인덱스를 받아 column 을 가져오는 방식으로 쉽게 계산할 수 있다.
학습이 완료된 후에는 의 column / 의 row 중 어떤 것을 embedding vector로 사용할지 결정하면 되고 때로는 , 의 평균치를 선택하기도 한다.
✅ Skip-Gram
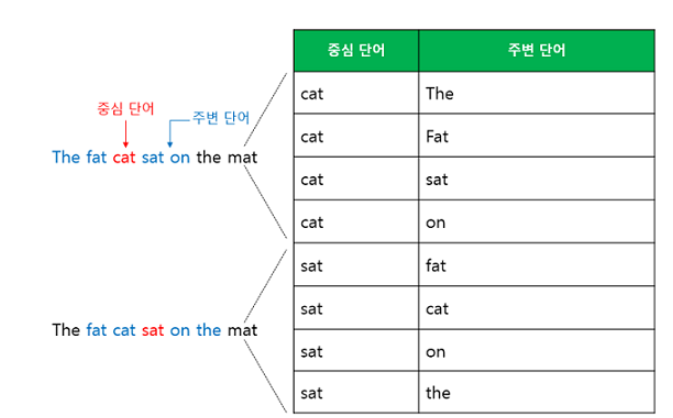
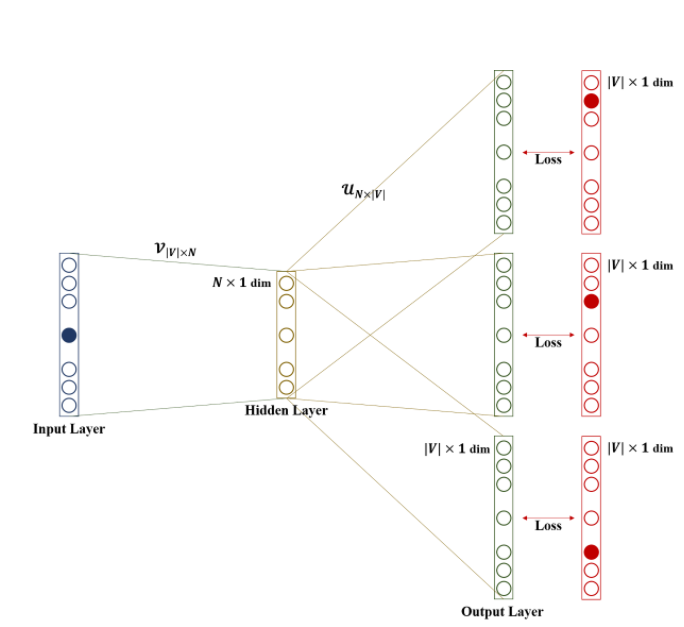
Skip-Gram은 CBOW 와는 반대로 중심단어(Center Word)를 이용하여 주변단어(Context Word)를 예측하는 모델 이다. 여기서는 CBOW 와의 차이점만 살펴보면, CBOW 의 경우 주변 단어를 입력으로 받았기 때문에 project layer에서 평균 벡터를 구하였지만, SKip-Gram은 중심 단어를 입력으로 받기 때문에 평균을 구하는 과정이 없다.
✅ CBOW vs Skip-Gram
현재는 Skip-Gram 을 CBOW보다 더 많이 사용하고 있는데, 다음 그림이 그 이유를 잘 설명 해 주고 있다.
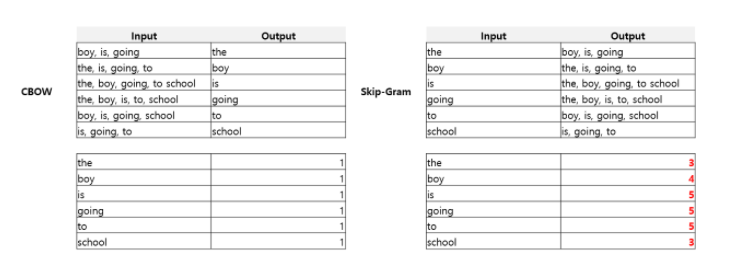
위 그림에Skip-Gram은 context word 가 CBOW 와 비교하여 빈번하게 학습되어 가중치가 적절하게 평가될 가능성이 높다. 따라서 Skip-Gram이 대부분의 상황에서 더 좋은 성능을 보인다고 한다.
✅ Property of Word2Vec
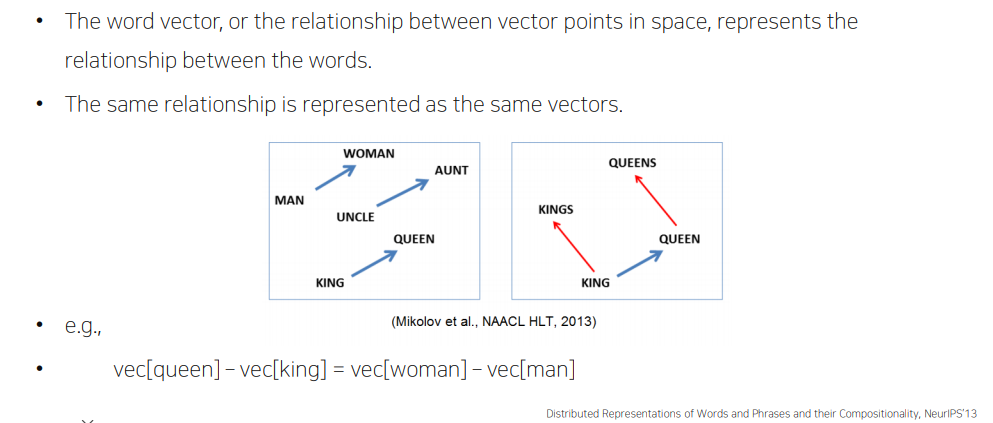
<참고>
Word2Vec 시각화
한글 Word2Vec
✏️ GloVe
📚 Reference
