
📌 NLP(Natural Language Processing)
📄 Vanila RNN
Vanila RNN 의 전체적인 개념은 미리 살펴봤으므로, 여기선
-
RNN의 다양한 모델 구조
-
가장 간단한 모델을 통한 RNN의 이해
-
RNN은 어떻게 작동하는지에 대한 직관
을 중점적으로 살펴보도록 한다.
✏️ Types of RNNs
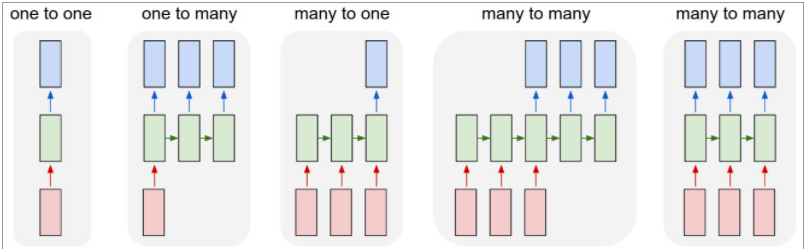
✅ One-to-one
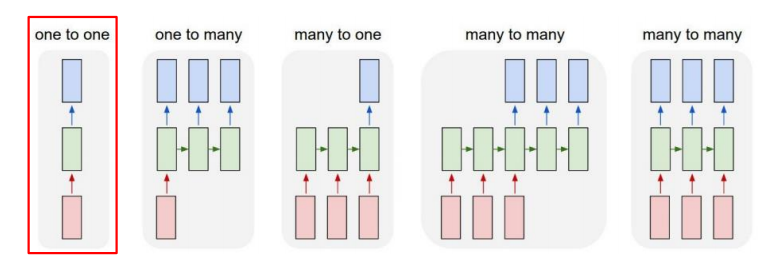
가장 기본적인 구조로,time step이 1인 하나의 입력을 받아 하나의 output을 생성한다. 예를들어, 사람의 키,몸무게,나이로 이루어진 3차원 벡터가 하나의 입력으로 들어오면 선형결합과 비선형 활성함수를 통과하여 정상혈압 / 고혈압 으로 분류하는 binary classifcation 문제를 생각할 수 있다. 이때, 하나의 output은 입력 벡터와 동일한 3차원을 가질 것이고, output 을 sigmoid 함수를 이용해 확률 값으로 변환하여 classifcation 한다.
✅ One-to-many
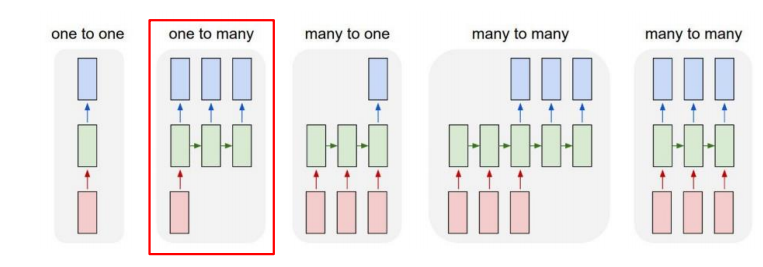
하나의 입력을 받아 sequential output을 생성하는 구조 이다. 예로, image captioning 문제를 생각하면 하나의 이미지를 받아 sequential output를 생성한다. 여기서 의문점이 생길 수 있는데, RNN 구조를 설명할 때 time step이 여러개인 sequential data를 받는 입력으로 설명을 했는데 하나의 이미지는 단일 time step으로 이루어졌다는 것이다. 이것은 입력 벡터와 동일한 차원을 가지면서 0으로 이루어진 벡터를 time step 마다 넣어주는 방식으로 해결할 수 있다.
✅ Many-to-one
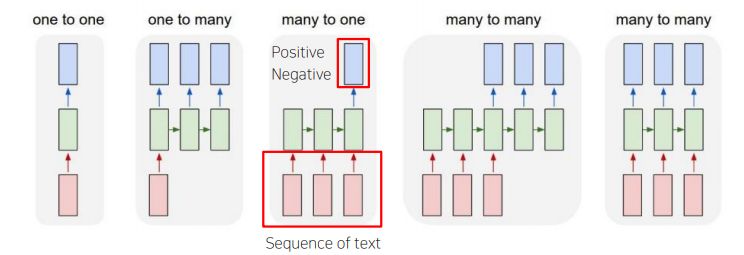
Sequential data를 입력으로 받아 하나의 output을 생성하는 구조이다. 예로, sentiment classification 문제를 생각하면, sequential data 인 문장을 받아 긍정/부정 등 하나의 output을 출력한다.
✅ Delayed many-to-many(Seq2Seq)
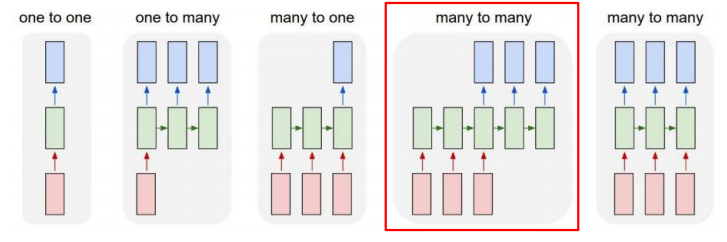
입력과 출력 모두 sequential data를 가지는 구조이다. 예로, machine translation의 경우 입력 문장을 다 읽은 후 번역된 문장을 출력한다. 위의 그림을 바탕으로 생각해보면, 3개의 단어로 이루어진 문장이 들어왔을때, 문장을 다 읽은 후 (3개의 hidden state를 거친 후) 3개의 번역된 단어로 이루어진 문장을 출력하는것으로 이해할 수 있다.(RNN many-to-many 구조의 경우 source 와 target 문장의 max_sequence_length는 동일할 수 밖에 없다. 해당 이슈를 해결하기 위해서 즉, 서로 다른 max_sequence_length인 sourch와 target 을 다루기 위해서 Encoder-Decoder 구조가 있고 추후 살펴보도록 한다.)
✅ Many-to-many(Seq2Seq)
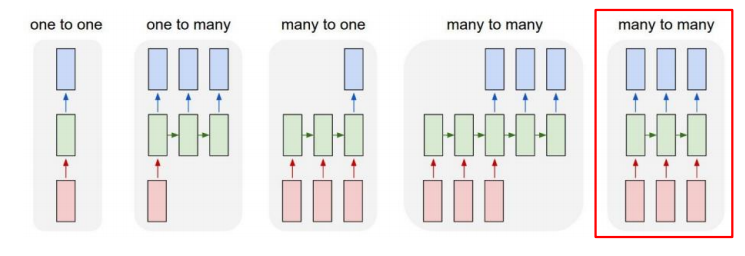
입력과 출력 모두 sequential data를 가지는 구조이다. Delayed many-to-many 와의 차이점은 지연되지 않고 실시간으로 출력된다는 것이다. 예로,video classification on frame level 문제를 생각하면 각 frame들이 입력으로 들어와서 각 frame들이 어떤 장면인지를 실시간으로 출력한다.
✏️ Character-level Language Model
RNN을 이해하기 위해 가장 간단한 Character-level Language Model 을 하나의 학습데이터 "hello" 를 train / test 하는 과정을 살펴 보도록 한다.
✅ Train
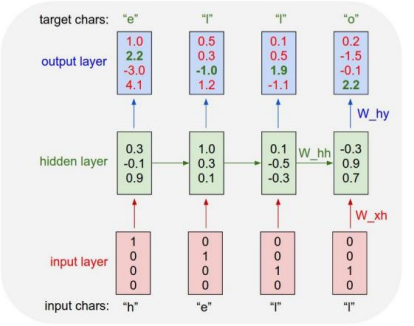
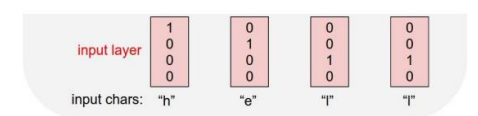
"hello"를 학습하기 위해 가장 먼저 해야할 것은 vocabulary 구축이다. 즉, 중복을 포함하지 않는 character로 이루어진 vocabulary를 구축한다.

구축된 vocabulary 를 바탕으로 one-hot vector 로 표현 한다.(물론, word embedding을 사용하는 것이 좋겠지만 작동원리에 대한 이해가 목적이므로 간단하게 one-hot encoding 한다. ) 이를 바탕으로 RNN에 입력한다.
입력된 각각의 벡터는 선형변환과 비선형 활성화 함수를 통과하고, 그 결과 hyperparameter 인 hidden state의 dimension 만큼의 벡터를 가지게 된다. 이때, time step=1 의 경우 이전 hidden state 이 없으므로 모델 생성시 initialization 을 통해 초기화 해준다.
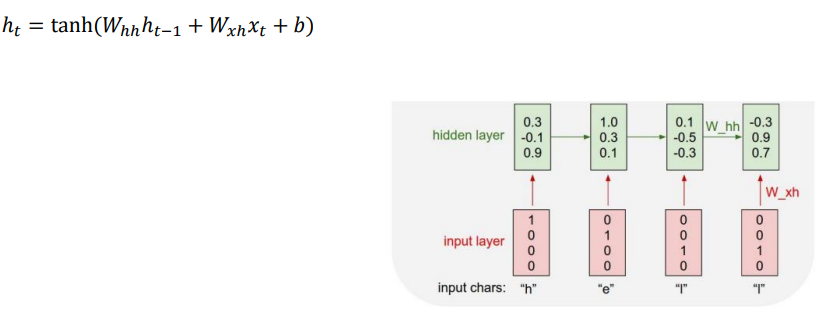
hidden state 를 통과한뒤 선형변환을 통해 입력벡터와 동일한 차원의 logit 이 생성이 되는데, multi-classification 문제이기 때문에 logit 은 softmax 를 통과 한다. time step=1 을 기준으로 살펴보면 학습의 목적은 "h" 가 들어오면 target "e"가 나오도록 하는것 인데 output layer에서 4번째 값, 즉 "o" 의 값이 제일 높은 것으로 보여주고 있다. 그래서 목적함수는 target "e"와의 오차를 줄이는 것, 즉 "e"의 인덱스 위치의 output layer 값을 높이는 방향으로 학습된다.
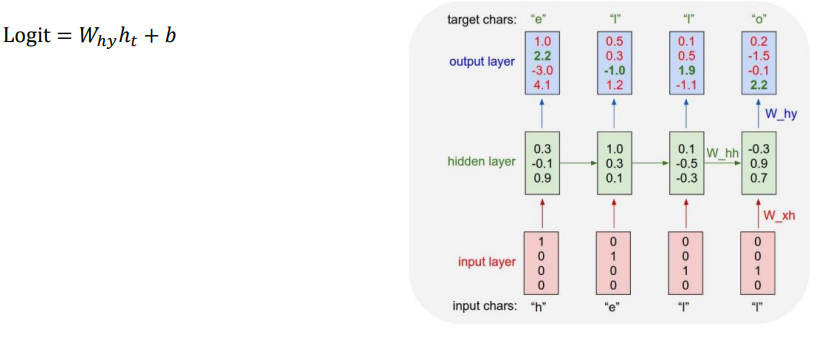
✅ Test
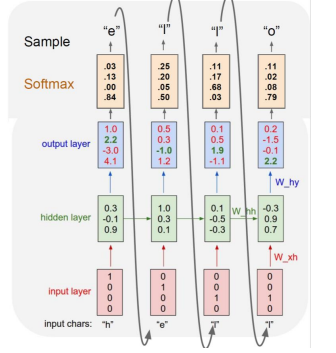
학습된 모델을 가지고 첫번째 character "h" 만을 입력으로 넣게 되면 출력된 결과값 "e" 를 다음 time step으로 입력하게 되고 이 과정을 반복함으로써 결과를 얻게 된다. 주목할 것은 train 과정에서는 각각의 입력벡터(정답)를 넣어주었고 , test 과정은 예측 결과를 다음 time step으로 입력해준다는 것이다. 그렇다면 학습시의 예측 결과를 다음 time step을 넣으면 안될까?
답은 "가능하지만 하지 않는다" 이다. 학습과정을 생각해보면 이 답을 이해할 수 있는데, 초기의 학습 파라미터들은 거의 random character / word 를 출력하고 이를 다음 time step에 전달하는 방식으로 학습할 경우 제대로 된 character / word를 출력하는 것을 어렵게 만든다. 따라서, 학습과정에선 정답 character / word를 다음 time step에 넣어주는 teacher forcing 기법을 적용한다.
✏️ Searching For Interpretable Cells
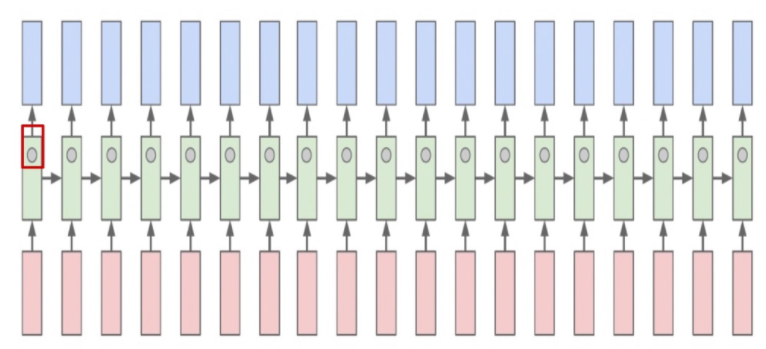
Hidden state vector 는 feature 정보가 함축되어 있다는 것에 착안하여 특정 차원을 고정시켜 각 차원들이 어떤 정보를 담고 있고 어떻게 변화하는지를 시각화 할 수 있다.



위의 결과를 통해 RNN은 sequential data에서 유의미한 패턴을 도출하는 방향으로
학습되어가고 있음을 확인할 수 있다.
📄 LSTM & GRU
LSTM 과 GRU 의 개념은 미리 살펴봤으므로, 여기선 PyTorch 를 이용한 실습을 하도록 한다.
구글 코랩에서 LSTM 실습하기
구글 코랩에서 GRU 실습하기
📚 Reference
