
📌NLP(Natural Language Processing)
📄 Seq2Seq
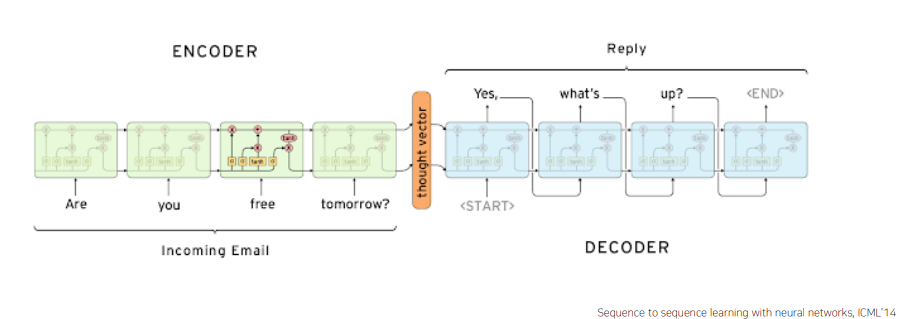
Seq2Seq 는 many-to-many 구조로 sequence 데이터의 입력을 받아 또 다른 sequence 데이터로 변환하는 모델이다.대표적인 예로 machine translation 을 생각해볼 수 있는데, 일반적인 word-level 의 many-to-many 구조는 다음과 같은 문제가 발생한다.
-
"I love you"->"난 사랑해 널"과 같이 어순을 표현하지 못한다. -
"How are you?"(3 단어) ->"잘 지내?"(2단어) 로 변환하여야 하지만 source 의 max_seqeunce_length에 의존적인 변환은 어색한 변환이 될 수 있다.
이를 해결하기 위해 RNN 기반(LSTM or GRU)의 Encoder 와 Decoder를 이용한 Seq2Seq 모델이 등장하게 되었다.
✏️ Encoder
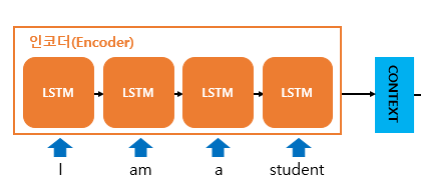
Encoder는 입력문장의 모든 단어들을 순차적으로 입력 받은뒤 마지막에 하나의 고정된 사이즈 벡터(Context Vector)로 모든 정보를 압축 한다. 그 구조를 자세히 살펴보면,
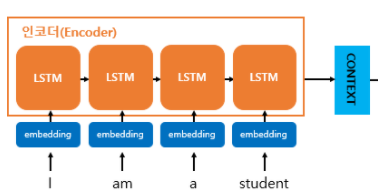
입력받은 문장들은 tokenization 과 word embedding 을 통해 변환되어 각 time step 의 입력이 된다. Encoder 는 모든 단어를 입력 받은 뒤 마지막 time step 의 hidden state(Context Vector) 를 decoder의 입력으로 들어가게 된다.
✏️ Decoder
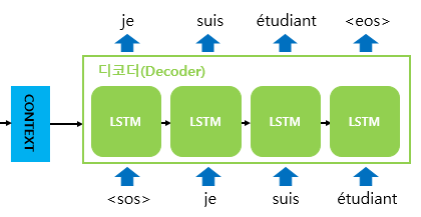
Decoder 는 encoder가 넘겨준 context vector 를 RNN 셀의 첫번째 hidden state로 사용한다. 위의 그림에서 주목할것은 <sos>(Start Of Sentence) 토큰과 <eos>(End Of Sentence) 토큰인데, 이를 train / test 과정을 나눠서 살펴보도록 한다.
✅Train
이전에 Character-level Language Model 에서 언급하였지만, 학습과정에서의 decoder는 encoder로 부터 받은 context vector 와 실제 정답 상황인 <sos> je suis étudiant를 입력으로 주는 teacher forcing 기법을 통해 je suis étudiant <eos> 가 나오도록 학습한다.
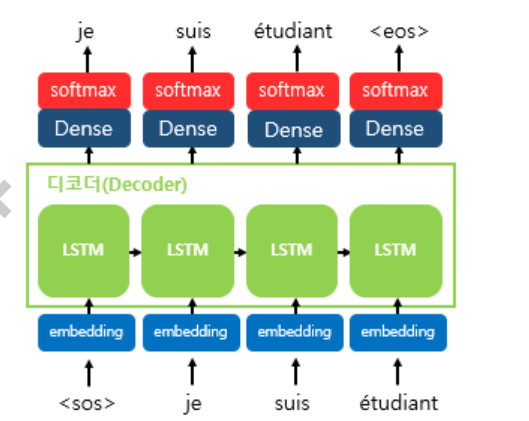
이후, 각 RNN 셀을 통과한 결과값들은 Dense layer(Hidden state를 입력으로 받아 분류개수로 출력해주는 feed-forward network) 지나 출력단어로 나올 수 있는 다양한 단어들로 예측하기 위해 softmax함수를 거쳐 결정한다.
✅Test
Test 과정에서는 context vector 와 <sos> 토큰만을 입력으로 받아 다음에 등장할 확률이 높은 단어를 예측하여 그 결과를 다음 time step으로 넣어주고 <eos> 토큰이 다음 단어로 예측 될때까지 이 과정을 반복한다.
✏️ 개선된 Seq2Seq
Seq2Seq2 모델은 고정된 사이즈의 context vector에 모든 정보를 담기 때문에 문장이 길어질 경우 과거의 정보를 유실할 가능성이 있다. 예를 들어, 다음과 같은 문장이 입력으로 들어온다면,

decoder 의 첫 출력 "I" 는 멀리 있는 입력 "나" 의 정보가 잘 전달 되도록 학습이 되야할 것이다. 그런데, 문장이 길어져 거리가 멀어지게 된다면 과거의 정보가 유실될 가능성이 있어 제대로 된 첫 출력 "I"가 나오지 않을 수 있다. 문제점은 잘못된 예측값이 다음 time step의 입력으로 들어가기 때문에 그 이후에도 잘못된 예측값이 나올 가능성이 커지는 것이다. 그래서 다음과 같이 입력데이터를 반전시키는 트릭을 이용하여,

성능을 끌어올리게 된다. 물론 평균적인 거리는 그대로이겠지만 sequential data의 경우 앞선 데이터에 대한 정확한 예측이 뒤의 예측에서도 좋은 결과로 이루어지기 때문이다.
📄 Seq2Seq With Attention
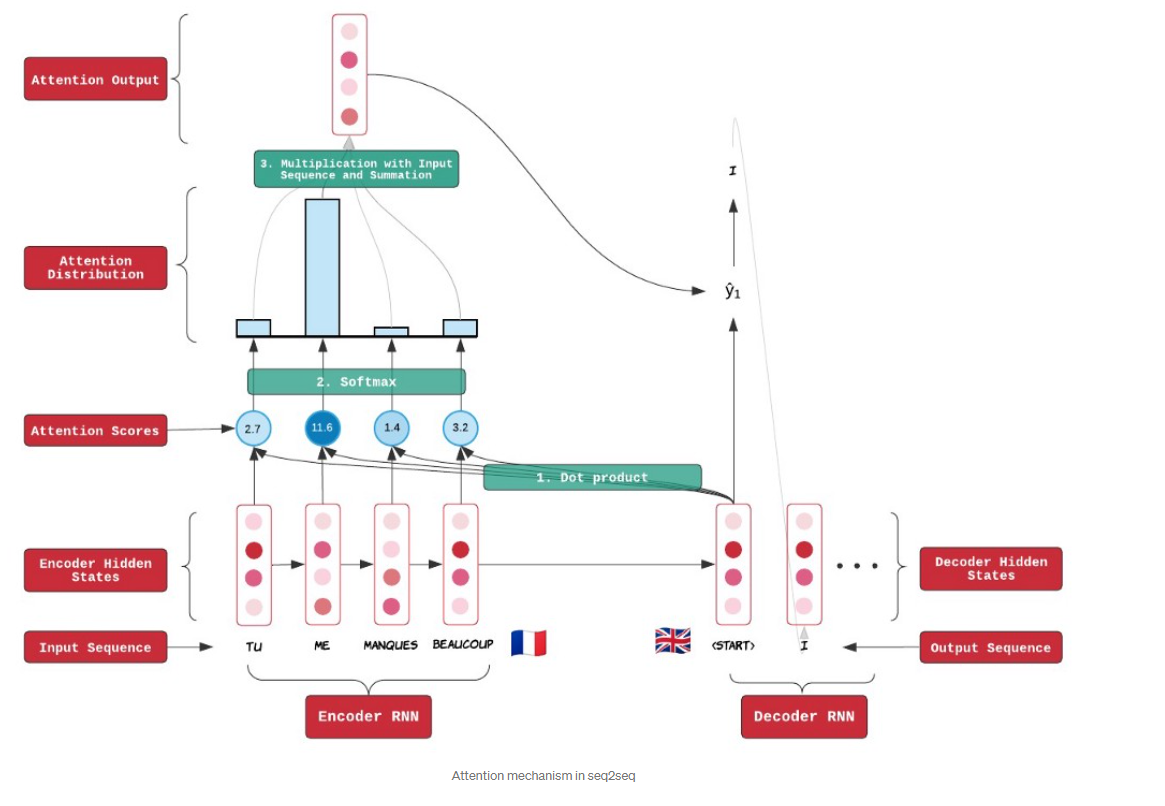
Seq2Seq 가 상당히 성공적이였지만 한가지 문제점을 가지고 있다. 기존의 Seq2Seq는 고정된 사이즈의 context vector 를 가지고 모든 정보를 담기 때문에 source의 길이가 길어 진 경우 충분치 않은 결과가 나올 수 있다. 즉, 단순히 encoder의 마지막 hidden state의 결과를 context vector로 활용하였기 때문에 길이가 길어질 경우 이 전의 정보들이 유실될 가능성이 있다는 것이다. 그래서 "각각의 집중해야할 hidden state의 정보를 담는다면 유의미한 모든 정보를 담을 수 있지 않을까?" 하는 motivation 에서 Encoder-Decoder 를 기반으로 Attention(Align) 모듈을 추가한 Seq2Seq with Attention 모델이 등장하였다.
✏️ Attention Score
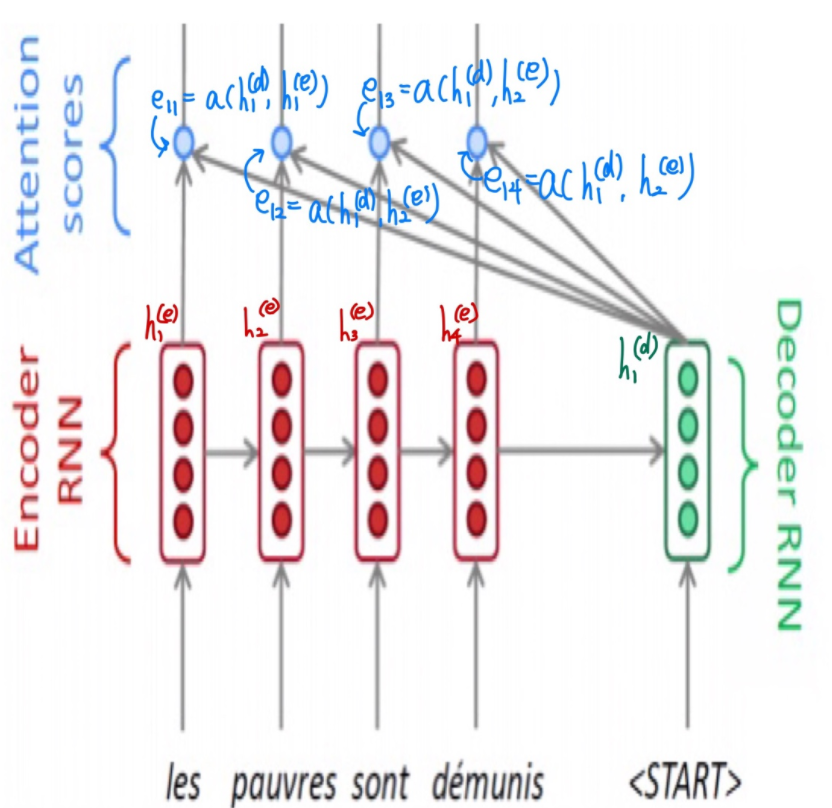
Attention Score는 encoder의 어느 time step에 집중할지를 decoder의 hidden state 와 encoder의 hidden state 를 alignment model 를 통해 scalar 로 점수화한 것이다. Attention Score 는 decoder 의 각 time step hidden state 마다 encoder의 모든 time step hidden state 에 대해서 계산이 된다.
Alignment model 는 다양하게 있지만, 대표적으로 3개의 모델은 다음과 같다.
✅ Dot Product
Attention Score 를 구하는 가장 간단한 방법은 내적연산이다.
✅ Luong's Aligned Model
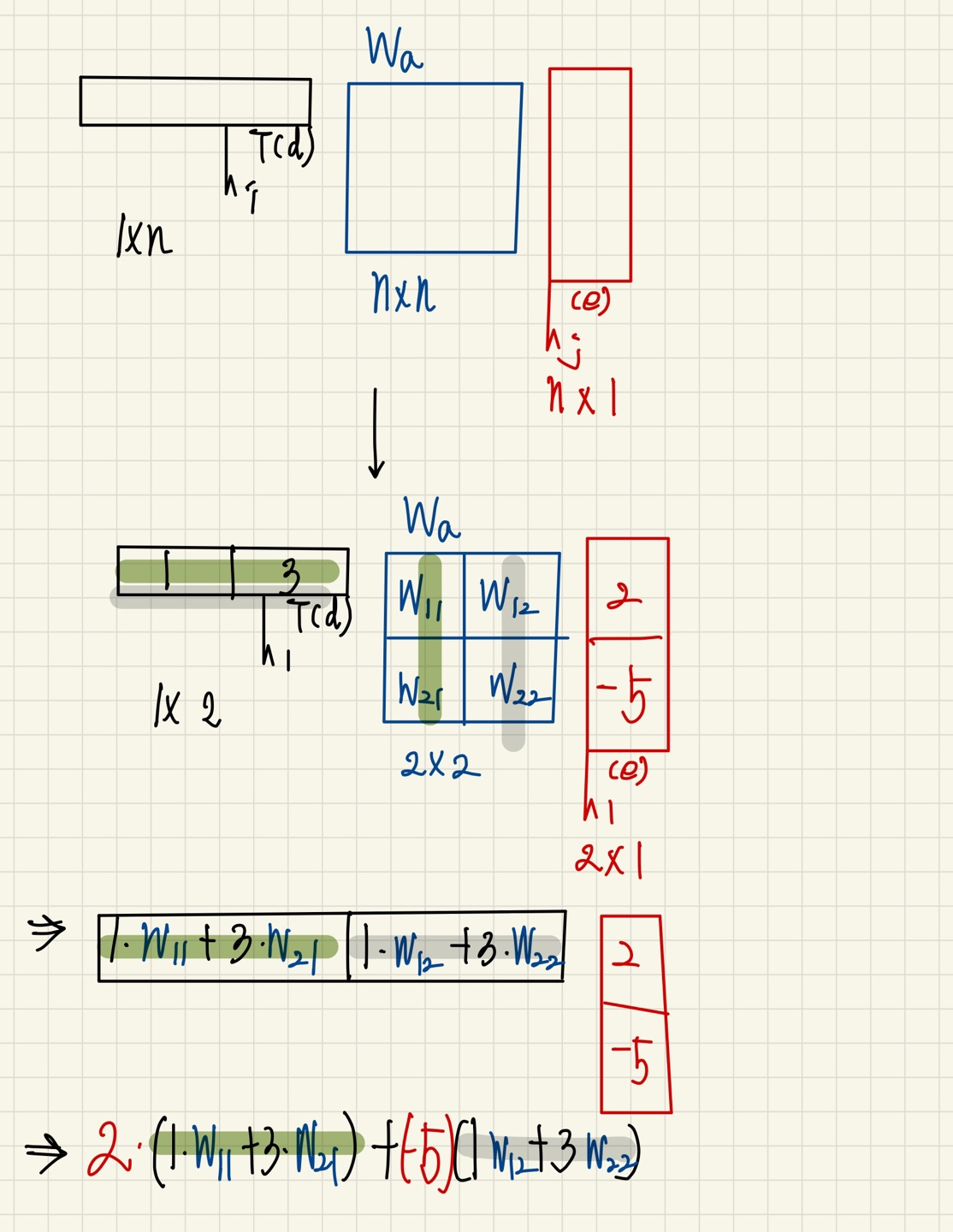
Attention Score 를 구하는 또 다른 방법으로는 추가적으로 학습가능한 를 두어 각각의 가중치를 결정하는 것이다.
✅ Bahdanau's Aligned Model
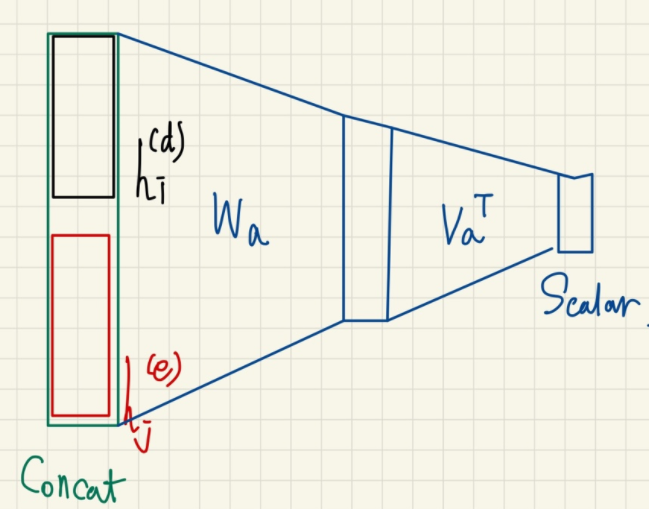
Attention Score 를 구하는 또 다른 방법으로는 concat 을 기반으로 추가적으로 학습가능한 MLP 를 이용하여 결정하는 것이다.
✏️ Attention Distribution
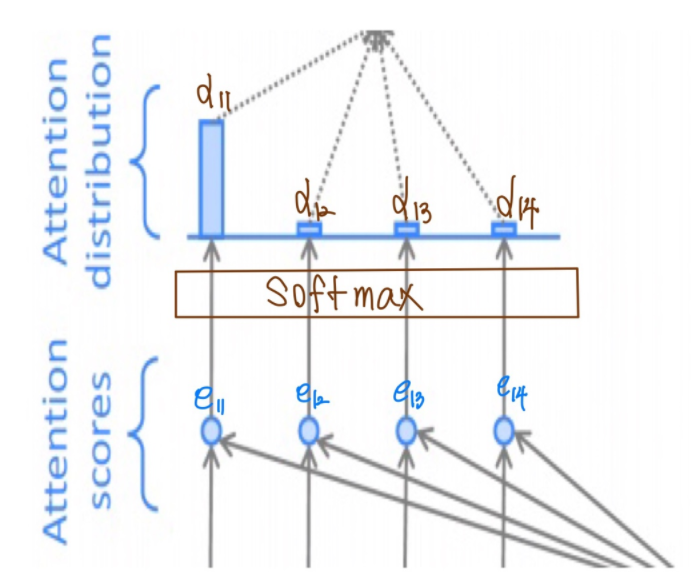
앞서 계산한 attention score를 이용하여 입력 크기만큼의 분류, 즉 softmax 함수를 통과시켜 확률화 된 는 Attention Distribution 을 만들어 낸다. 이렇게 계산된 값은 각 time step에 대한 가중치 가 된다.
✏️ Attention Output(Context Vector)
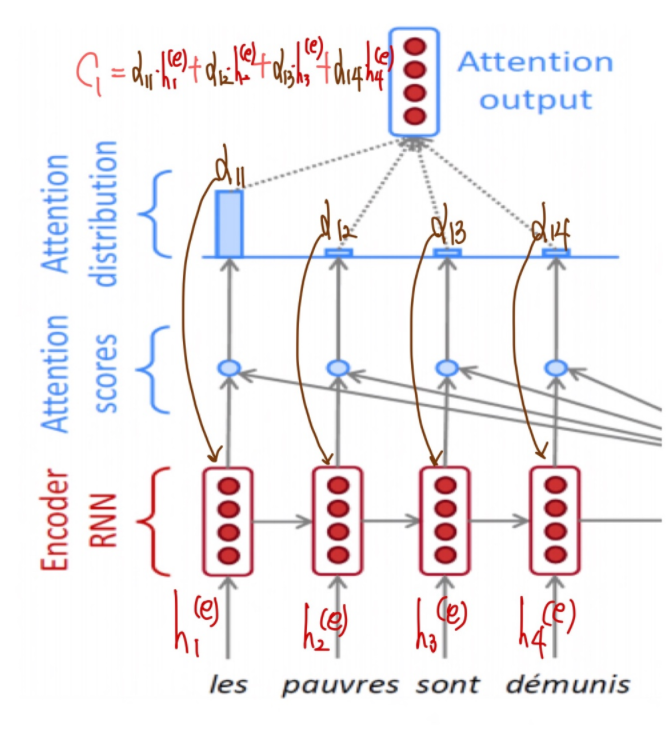
앞서 계산한 attention distribution, 즉 가중치를 가지고 encoder의 hidden state 들의 가중평균을 계산하여 하나의 벡터 를 생성한다. 이것이 Attention Output(Context Vector) 이며, 이 벡터는 각 decoder의 time step마다 다르다. 이것은 각 decoder의 hidden state 가 어떤 곳에 집중(attention)할지를 결정하는것이며 기존의 Seq2Seq 모델에서 고정된 사이즈의 context vector의 문제를 해결하였다.
✏️ Decoder Hidden State
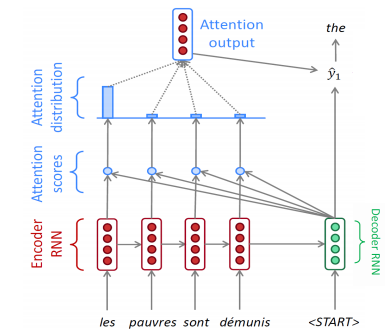
다음 hidden state 은 앞서 계산된 context vector , 이전 decoder hidden state , 이전 decoder의 target word 를 이용하여 출력된다. 또한 output layer 는 와 를 concatenation 후 선형변환 한다.
✏️ Training
빠른 학습을 위해 teacher forcing 을 기반으로 한다. 그러나 test set에서는 첫 토큰을 가지고 그 다음 토큰을 순차적으로 예측하기 때문에 train과 test의 gap을 줄이기 위해 초반에는 teacher forcing을 적용하다가 후반에는 test set의 inference 방식과 동일하게 예측값을 그 다음 time step으로 넣어주는 방식으로 변화 시킨다.
✏️ Advantages
-
Seq2Seq With Attention은 decoder가 필요한 특정 정보를 attention 하게 함으로써 성능을 향상 시켰다. -
Seq2Seq에서 하나의 고정된 사이즈를 가지는 context vector를 가져 긴 문장의 경우 정보를 제대로 담지 못하는 bottle neck 문제를 해결하였다. -
Seq2Seq의 경우 time step을 따라 gradient update를 해야하기 때문에 문장이 길어질 경우 gradient vanishing 문제가 생겼다. 그러나Attention이 추가됨에 따라 과거의 정보에 접근하는 shortcut을 제공하게 되었고, gradient를 변동없이 전달할수 있게 되었다. -
Attention은Attention Distribution을 통해 정보해석 가능성을 제공하여 decoder가 내부적으로 어떤 곳에 attention 하였는지 알 수 있게 된다.
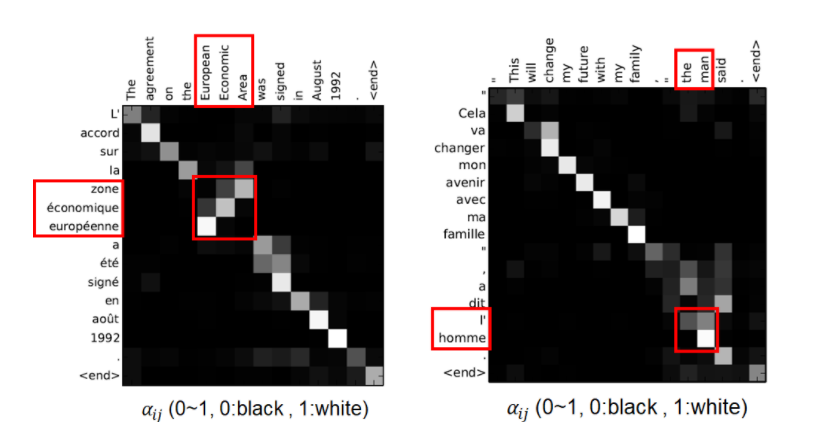
위의 그림은 프랑스->영어 로의 번역결과이며, 그때의 attention score를 matrix형태로 나타낸 것이다. 이때 흰색에 가까울수록 attention score가 1 / 검은색에 가까울수록 0 에 가까운것이다.
matrix를 보면 일반적으로 단어별로 monotonic alignment 되는 경향을 확인할 수 있다. 하지만 "European","Economic","Area"을 보면 단순히 순서대로 매칭한것이 아닌 잘 align하여 매칭되는것을 확인할 수 있다. 또한 "the", "man"을 보면
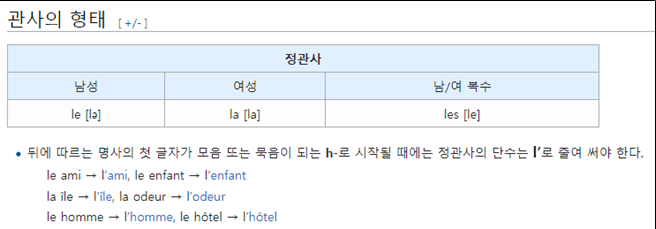
"the"를 "le","la","les","l" 중 어떤 것으로 번역할지를 "man" 에 attention하여 결정하고 있음을 확인할 수 있다. 즉, Attention 을 통해 time step 중 중요한 특정 정보에 집중하고 있다는 것을 확인할 수 있다.
📄 Beam Search
LM(Language Model) 은 단어 시퀀스에 확률을 할당(assign)하는 일을 하는 모델이다. 이를 조금 풀어서 쓰면, 가장 자연스러운 단어 시퀀스를 찾아내는 모델이다. 단어 시퀀스에 확률을 할당하게 하기 위해서 가장 보편적으로 사용되는 방법은 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것이다. 이때, 확률 값에 기반하여 다양한 경우의 수가 존재할텐데 모든 경우의 수를 고려하는 것은 비효율적이며 너무 작을 확률값 까지 고려한다면 생성된 문장의 quality가 떨어질 수 있다. 그렇다고 해서 가장 높은 확률값을 고려하는 방법 역시 모델이 단순한 generation을 하도록 하게 만드는 단점이 있다. 이러한 문제의 대안으로 제안된 Beam Search에 대해 살펴보도록 한다.
✏️ Greedy Search
이름에서 알수있듯이, 근시안적으로 현 time step에서 가장 높은 확률의 단어를 예측한다.

위의 예시는, 현 time step에서 가장 높은 확률의 단어를 예측하고 있는 상황이다. 하지만 이것의 가장 큰 문제점은 만약 올바른 예측 "me" 가 아닌 잘못된 "a" 를 예측했을 경우 잘못된 예측임을 알았음에도 되돌릴수 있는 방법이 없으며 이 결과는 연쇄적으로 잘못된 결과를 예측하게 만든다.
✏️ Exhaustive Search
이름에서 알수 있듯이, 가장 이상적인 방법은 모든 경우의 수를 고려하여 예측하는것이다.
이것은 decoder의 각 time step t 마다 만큼 기하급수적으로 연산이 증가함을 의미한다. 즉 의 복잡도를 가지게 되며 이상적인 방법이지만 비효율적인 방법이다.
✏️ Beam Search
Greedy Search와 Exhaustive Search의 차선책으로 decoder의 각 time step 마다 k개(Beam size, in practice 5 ~ 10)의 가능한 경우의 수(Hypothesis)를 고려하여 가장 높은 확률의 단어를 예측한다. 물론 Beam Search는 Exhaustive Search 처럼 globally optimal solution을 보장해주진 않지만 연산에 있어서 더욱 효율적이다.
이때, 는 monotonic increasing 성질을 가지고 있기 때문에 target 확률값의 비교를 변동없이 유지할수 있게 된다. 또한 확률 값은 0~1 의 범위를 가져 값은 모두 음수를 띄게 되고 높은 score라는 것은 가장 작은 음수임을 의미한다.
다음 예시를 통해 Beam Search 를 좀 더 알아 보도록 한다.

Beam size=k=2 로 가정하였을때, time step에서 vocabulary 에 있는 단어 중 가장 높은 스코어를 갖는 top-k words를 뽑는다.

각 k 개의 hypotheses 중 다음 top-k words를 뽑는다. 이후에는 위 과정을 일반적으로 다음의 조건을 만족할때까지 반복한다.
- 미리 정해진 time step T에 도달
- 미리 정해진 n개의 hypotheses가 생성
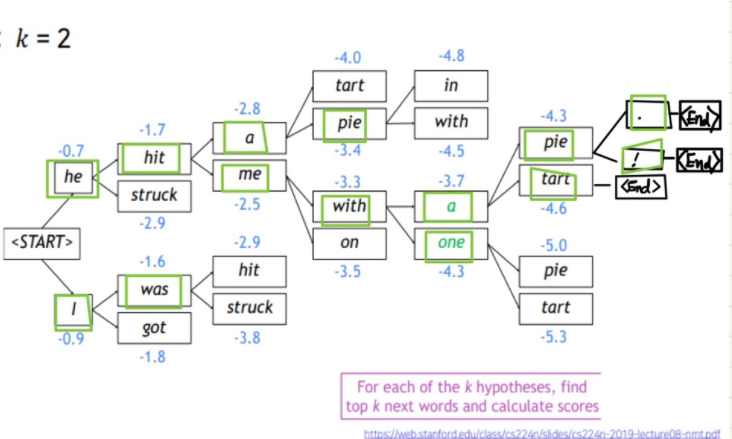
이렇게 생성된 후보군들 중 높은 score를 갖는 문장을 생성 하게 되는데, 이때 주목할것은 각 hypotheses 는 <End> 토큰이 서로 다른 time step에서 발생할수 있다는 것이다. 이것은 hypotheses의 길이가 길어질 경우 낮은 score를 가지게 되는 문제를 만든다. 따라서 일반적으로 normalize 하여 다음과 같이 계산한다.
📄 BLEU Score(Bilingual Evaluation Understudy Score)
✏️ Precision
✏️ Recall
✏️ BLEU
✏️ 이외의 대안
📚 Reference
