HTTP method(GET, POST) 이해하기
HTTP(HyperText Transfer Protocol)
- HTML 문서 등의 리소스를 전송하는 프로토콜
- GET 요청: 데이터를 URL에 포함하여 전달(주로 리소스 요청에 사용)
- POST 요철: 데이터를 Form data에 포함하여 전달(주로 로그인에 사용)
HTML 엘레멘트 이해하기(태그, 속성, 값)
HTML(Hyper Text Markup Language)
- 웹사이트를 생성하기 위한 언어로 문서와 문서가 링크로 연결되어 있고, 태그를 사용하는 언어
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Test</title>
</head>
<body>
<p>Test</p>
</body>
</html>태그(Tag)
- HTML문서의 기본 블락
- 브라우저에게 어떻게 렌더링될지 전달
- <태그명 속성1="속성값1" 속성2="속성값2">Value</태그명>
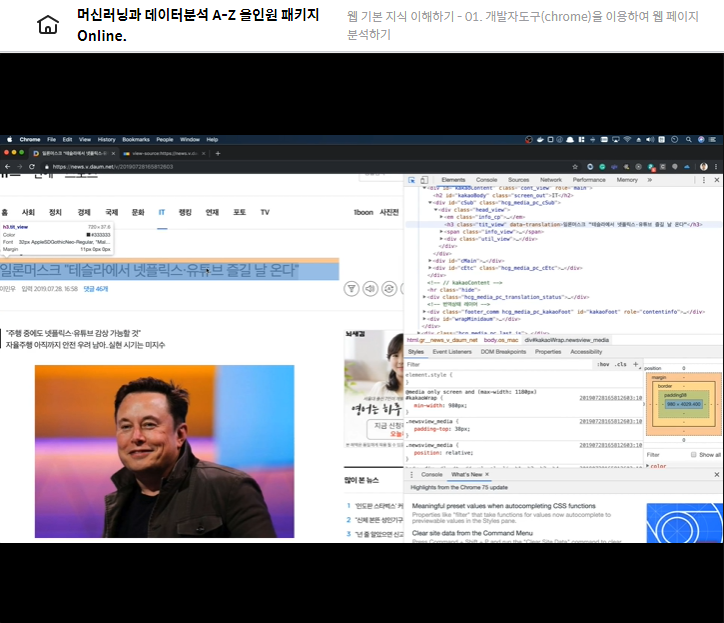
<h3 class="tit_view">예제입니다.</h3>API의 활용
requests 모듈
- http request/response를 위한 모듈
- HTTP method를 메소드 명으로 사용하여 request 요청 예) get, post
import requestsget 요청하기
- http get 요청하기
- query parameter 이용하여 데이터 전달하기
import requests
url = 'https://www.naver.com/'
resp = requests.get(url)
resp.textpost 요청하기
- http post 요청하기
- post data 이용하여 데이터 전달하기
import requests
url = 'https://www.kangcom.com/member/member_check.asp'
data = {
'id': 'testid',
'pwd': 'testpw'
}
resp = requests.post(url, data=data)
resp.textHTTP header 데이터 이용하기
- header 데이터 구성하기
- header 데이터 전달하기
url = 'https://news.v.daum.net/v/20190728165812603'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
resp = requests.get(url, headers=headers)
resp.textHTTP response 처리하기
- response 객체의 이해
- status_code 확인하기
- text 속성 확인하기
url = 'https://news.v.daum.net/v/20190728165812603'
resp = requests.get(url)
if resp.status_code == 200:
resp.headers
else:
print('error')공공데이터 포털 OPEN API 사용하기
- 공공데이터 포털 회원가입 / 로그인
- API 사용 요청 / 키 발급
- API 문서(specification)확인
- API 테스트 및 개발
Endpoint 확인하기
- API가 서비스되는 서버의 IP 혹은 domain 주소
endpoint = 'http://api.visitkorea.or.kr/openapi/service/rest/EngService/areaCode?serviceKey={}&numOfRows=10&pageSize=10&pageNo=1&MobileOS=ETC&MobileApp=AppTest&_type=json'.format(serviceKey)key 값 확인하기
- 서비스 호출 트래킹할 목적이나 악의적인 사용을 금지할 목적으로 주로 사용
- 새로 발급받은 키는 1시간 이후 사용 가능
Parameter 확인하기
- API 호출에 필요한 parameter 값 확인 및 구성
import requests
endpoint = 'http://api.visitkorea.or.kr/openapi/service/rest/EngService/areaCode?serviceKey={}&numOfRows=10&pageSize=10&pageNo={}&MobileOS=ETC&MobileApp=AppTest&_type=json'.format(serviceKey, 1)
resp = requests.get(endpoint)
print(resp.status_code) # 200
data = resp.json() # type: dict
print(data['response']['body']['items']['item'][0])요청 및 Response 확인
- requests 모듈을 활용하여 API 호출
- response 확인하여 원하는 정보 추출
- json 데이터의 경우, python dictionary로 변경하여 사용가능
beautifulsoup 모듈
beautifulsoup 모듈 사용하기
from bs4 import BeautifulSouphtml 문자열 파싱
- 문자열로 정의된 html 데이터 파싱하기
html = '''
<html>
<head>
<title>BeautifulSoup test</title>
</head>
<body>
<div id='upper' class='test' custom='good'>
<h3 title='Good Content Title'>Contents Title</h3>
<p>Test contents</p>
</div>
<div id='lower' class='test' custom='nice'>
<p>Test Test Test 1</p>
<p>Test Test Test 2</p>
<p>Test Test Test 3</p>
</div>
</body>
</html>'''find 함수
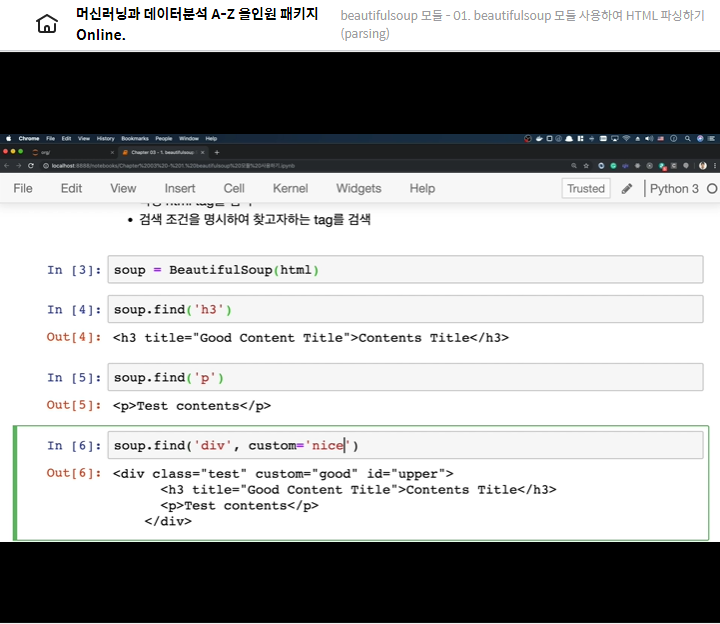
- 특정 html tag를 검색
- 검색 조건을 명시하여 찾고자하는 tag를 검색
soup = BeautifulSoup(html)
soup.find('h3')
# <h3 title="Good Content Title">Contents Title</h3>
soup.find('p')
# <p>Test contents</p>
soup.find('div', class_='test')
"""
<div class="test" custom="good" id="upper">
<h3 title="Good Content Title">Contents Title</h3>
<p>Test contents</p>
</div>
"""
attrs = {'id': 'upper', 'class': 'test'}
soup.find('div', attrs=attrs)
"""
<div class="test" custom="good" id="upper">
<h3 title="Good Content Title">Contents Title</h3>
<p>Test contents</p>
</div>
"""find_all 함수
- find가 조건에 만족하는 하나의 tag만 검색한다면, find_all은 조건에 맞는 모든 tag를 리스트로 반환
soup.find_all('div', class_='test')
"""
[<div class="test" custom="good" id="upper">
<h3 title="Good Content Title">Contents Title</h3>
<p>Test contents</p>
</div>,
<div class="test" custom="nice" id="lower">
<p>Test Test Test 1</p>
<p>Test Test Test 2</p>
<p>Test Test Test 3</p>
</div>]
"""get_text 함수
- tag안의 value를 추출
- 부모tag의 경우, 모든 자식 tag의 value를 추출
tag1 = soup.find('h3')
print(tag)
# <h3 title="Good Content Title">Contents Title</h3>
tag.get_text()
# 'Contents Title'
tag2 = soup.find('p')
print(tag2)
# <p>Test contents</p>
tag2.get_text()
# 'Test contents'
tag3 = soup.find('div', id='upper')
print(tag3)
"""
<div class="test" custom="good" id="upper">
<h3 title="Good Content Title">Contents Title</h3>
<p>Test contents</p>
</div>
"""
tag3.get_text().strip()
# 'Contents Title\nTest contents'attribute 값 추출하기
- 경우에 따라 추출하고자 하는 값이 attribute에도 존재함
- 이 경우에는 검색한 tag에 attribute 이름을 [ ] 연산을 통해 추출가능
- 예) div.find('h3')['title']
tag = soup.find('h3')
print(tag)
# <h3 title="Good Content Title">Contents Title</h3>
tag['title']
# 'Good Content Title'다음 뉴스 데이터 추출
- 뉴스기사에서 제목, 작성자, 작성일, 댓글 개수 추출
- 뉴스링크
- tag를 추출할때는 가장 그 tag를 쉽게 특정할 수 있는 속성을 사용
- id의 경우 원칙적으로 한 html 문서 내에서 유일
- id, class 속성으로 tag 찾기
- 타이틀
- 작성자, 작성일
import requests
from bs4 import BeautifulSoup
url = 'https://news.v.daum.net/v/20190728165812603'
resp = requests.get(url)
soup = BeautifulSoup(resp.text)
title = soup.find('h3', class_='tit_view)
title.get.test()
# '일론머스크 "테슬라에서 넷플릭스·유튜브 즐길 날 온다"'
soup.find_all('span', class_='txt_info')
"""
[<span class="txt_info">이민우</span>,
<span class="txt_info">입력 <span class="num_date">2019. 07. 28. 16:58</span></span>]
"""
info = soup.find('span', class_='info_view')
info.find('span', class_='txt_info')
# <span class="txt_info">이민우</span>- CSS를 이용하여 tag 찾기
- select, select_one 함수 사용
- css selector 사용법
- 태그명 찾기 tag
- 자손 태그 찾기 - 자손 관계(tag tag)
- 자식 태그 찾기 - 다이렉트 자식 관계(tag > tag)
- 아이디 찾기 #id
- 클래스 찾기 .class
- 속성값 찾기 [name='test']
- 속성값 prefix 찾기 [name^='test']
- 속성값 suffix 찾기 [name$='test']
- 속성값 substring 찾기 [ name*='test']
- n번째 자식 tag 찾기 :nth-child(n)
import requests
from bs4 import BeautifulSoup
url = 'https://news.v.daum.net/v/20190728165812603'
resp = requests.get(url)
soup = BeautifulSoup(resp.text)
soup.select('h3')
"""
[<h3 class="tit_view" data-translation="true">일론머스크 "테슬라에서 넷플릭스·유튜브 즐길 날 온다"</h3>,
<h3 class="tit_cp">아시아경제 주요 뉴스</h3>,
<h3 class="txt_newsview">많이본 뉴스</h3>,
<h3 class="txt_newsview">포토&TV</h3>,
<h3 class="txt_newsview">이 시각 추천뉴스</h3>]
"""
soup.select('#harmonyContainer > p')
# [<p data-translation="true"><ⓒ경제를 보는 눈, 세계를 보는 창 아시아경제 무단전재 배포금지></p>]
soup.select('h3.tit_view') # soup.select('h3[class="tit_view"]')
# [<h3 class="tit_view" data-translation="true">일론머스크 "테슬라에서 넷플릭스·유튜브 즐길 날 온다"</h3>]
soup.select('h3[class^="tx"]')
"""
[<h3 class="txt_newsview">많이본 뉴스</h3>,
<h3 class="txt_newsview">포토&TV</h3>,
<h3 class="txt_newsview">이 시각 추천뉴스</h3>]
"""
soup.select('h3[class$="_view"]')
# [<h3 class="tit_view" data-translation="true">일론머스크 "테슬라에서 넷플릭스·유튜브 즐길 날 온다"</h3>]
# 부분 문자열
soup.select('h3[class*="view"]')
"""
[<h3 class="tit_view" data-translation="true">일론머스크 "테슬라에서 넷플릭스·유튜브 즐길 날 온다"</h3>,
<h3 class="txt_newsview">많이본 뉴스</h3>,
<h3 class="txt_newsview">포토&TV</h3>,
<h3 class="txt_newsview">이 시각 추천뉴스</h3>]
"""
soup.select('span.txt_info:nth-child(1)')
# [<span class="txt_info">이민우</span>]- 정규표현식으로 tag 찾기
import re
# h1, h2, h3... 찾아오기
soup.find_all(re.compile('h\d'))- 댓글 개수 추출
- 댓글의 경우, 최초 로딩시에 전달되지 않음
- 이 경우는 추가적으로 AJAX로 비동기적 호출을 하여 따로 data 전송을 함
- 개발자 도구의 network 탭에서 확인(XHR: XmlHTTPRequest)
- 비동기적 호출: 사이트의 전체가 아닌 일부분만 업데이트 가능하도록 함
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
