뉴스 댓글 개수 크롤링
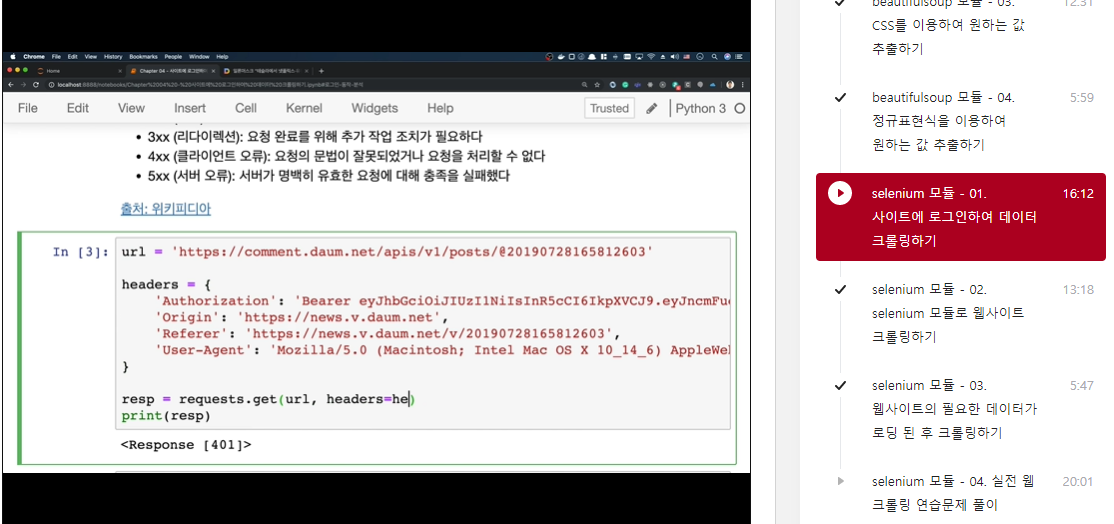
headers = {
'Authorization': 'Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJncmFudF90eXBlIjoiYWxleF9jcmVkZW50aWFscyIsInNjb3BlIjpbXSwiZXhwIjoxNTY0NjcxNDAwLCJhdXRob3JpdGllcyI6WyJST0xFX0NMSUVOVCJdLCJqdGkiOiI3MDllNDI5MC0yZmJjLTRmOTUtOTJlOC1mMTAzMDk5ZjYyYTciLCJjbGllbnRfaWQiOiIyNkJYQXZLbnk1V0Y1WjA5bHI1azc3WTgifQ.fQU2739LvY9EZLlNs-Go1VlCVEtz-I-JdS_kKJeOLDc',
'Origin': 'https://news.v.daum.net',
'Referer': 'https://news.v.daum.net/v/20190728165812603',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
resp = requests.get('https://comment.daum.net/apis/v1/posts/@20190728165812603', headers=headers)
data = resp.json()
data['commentCount']로그인 후 데이터 크롤링 하기
- endpoint 찾기(개발자 도구의 network를 활용)
- id와 password가 전달괴는 form data 찾기
- session 객체 생성하여 login 진행
- 이후 session 객체로 원하는 페이지로 이동하여 크롤링
- endpoint 찾기
import requests
from bs4 import BeautifulSoup
url = 'https://www.kangcom.com/member/member_check.asp'- id, password로 구성된 form data 생성하기
data = {
'id': 'testid',
'pwd': 'testpw'
}- login
- endpoint(url)과 data를 구성하여 post 요청
- login의 경우 post로 구성하는 것이 정상적인 웹사이트
s = requests.Session()
resp = s.post(url, data=data)
print(resp.status_code)- crawling
- login 시 사용했던 session을 다시 사용하여 요청
mypage = 'https://www.kangcom.com/mypage/'
resp = s.get(mypage)
soup = BeautifulSoup(resp.text)
mileage = soup.select_one('td.a_bbslist55:nth-child(3)')
print(mileage.get_text())selenium 모듈 사용하기
selenium
- 웹페이지 테스트 자동화 모듈
- 개발/테스트용 드라이버(웹브라우저)를 사용하여 실제 사용자가 사용하는 것처럼 동작
Downloads - ChromeDriver - WebDriver for Chrome
selenium 예제
- python.org 로 이동하여 자동으로 검색해보기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
chrome_driver = '드라이버 경로/chromedriver'
driver = webdriver.Chrome(chrome_driver)
driver.get('https://www.python.org/')
search = driver.find_element_by_id('id-search-field')
time.sleep(2)
search.clear()
time.sleep(2)
search.send_keys("lambda")
time.sleep(2)
search.send_keys(Keys.RETURN)
time.sleep(2)
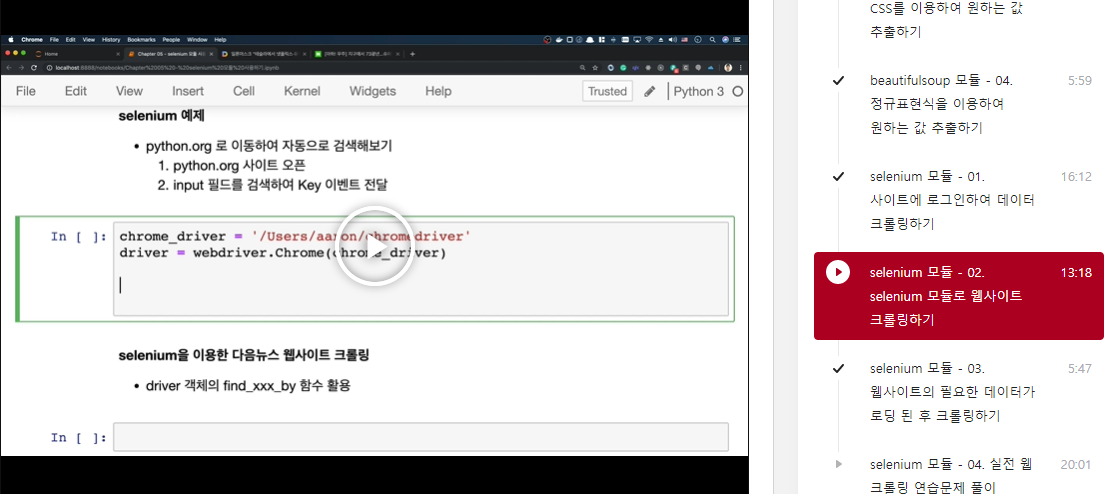
driver.close()selenium을 이용한 다음뉴스 웹사이트 크롤링
chrome_driver = '드라이버 경로/chromedriver'
driver = webdriver.Chrome(chrome_driver)
url = 'https://news.v.daum.net/v/20190728165812603'
# chrome driver 로 해당 페이지가 물리적으로 open
driver.get(url)
src = driver.page_source
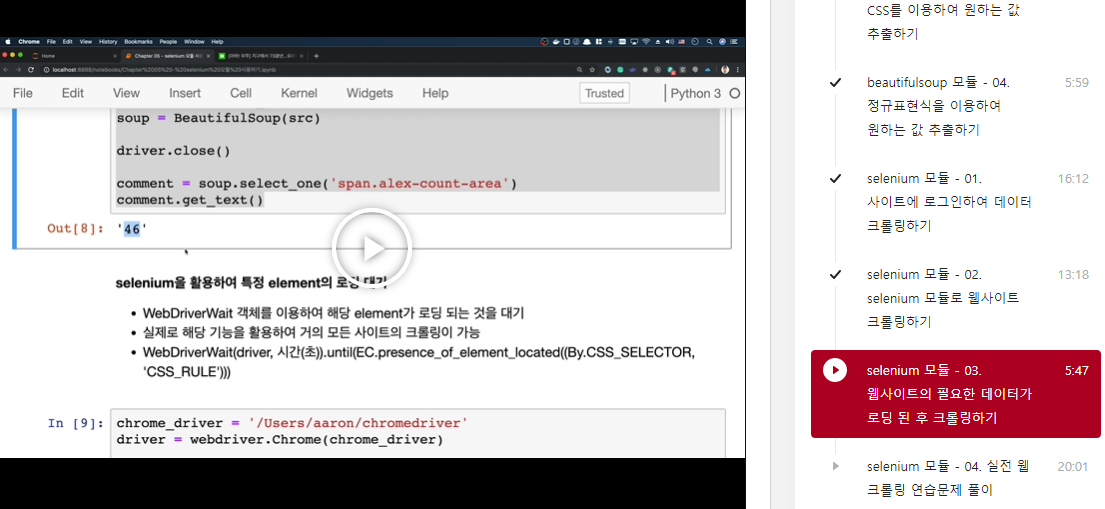
soup = BeautifulSoup(src)
comment_area = soup.select_one('span.alex-count-area')
# chrome driver 사용 후, close 함수로 종료
driver.close()
comment_area.get_text()selenium을 활용하여 특정 element의 로딩 대기
- WebDriverWait 객체를 이용하여 해당 element가 로딩 되는 것을 대기
- 실제로 해당 기능을 활용하여 거의 모든 사이트의 크롤링이 가능
- WebDriverWait(driver, 시간(초)).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'CSS_RULE')))
chrome_driver = '드라이버 경로/chromedriver'
driver = webdriver.Chrome(chrome_driver)
url = 'https://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=081&aid=0003018031'
# chrome driver 로 해당 페이지가 물리적으로 open
driver.get(url)
# 해당 element가 로딩 될때까지 대기
myElem = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '.u_cbox_count')))
src = driver.page_source
soup = BeautifulSoup(src)
comment_area = soup.select_one('.u_cbox_count')
# chrome driver 사용 후, close 함수로 종료
driver.close()
print(comment_area)머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
