인덱싱, 슬라이싱 이해하기
인덱싱
- 파이썬 리스트와 동일한 개념으로 사용
- , 를 사용하여 각 차원의 인덱스 접근 가능
1차원 벡터 인덱싱
import numpy as np
x = np.arange(10)
print(x)
>>> [0 1 2 3 4 5 6 7 8 9]
x[3] = 100
print(x)
>>> [ 0 1 2 100 4 5 6 7 8 9]2차원 행렬 인덱싱
x = np.arange(10).reshape(2, 5)
print(x)
>>> [[0 1 2 3 4]
[5 6 7 8 9]]
x[1, 2]
>>> 7
x[0]
>>> array([0, 1, 2, 3, 4])3차원 텐서 인덱싱
x = np.arange(36).reshape(3, 4, 3)
print(x)
>>> [[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]]
[[24 25 26]
[27 28 29]
[30 31 32]
[33 34 35]]]
x[1]
>>> array([[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]])슬라이싱
- 리스트, 문자열 slicing과 동일한 개념으로 사용
- ,를 사용하여 각 차원 별로 슬라이싱 가능
1차원 벡터 슬라이싱
x = np.arange(10)
print(x)
>>> [0 1 2 3 4 5 6 7 8 9]
x[1:5]
>>> array([1, 2, 3, 4])2차원 행렬 슬라이싱
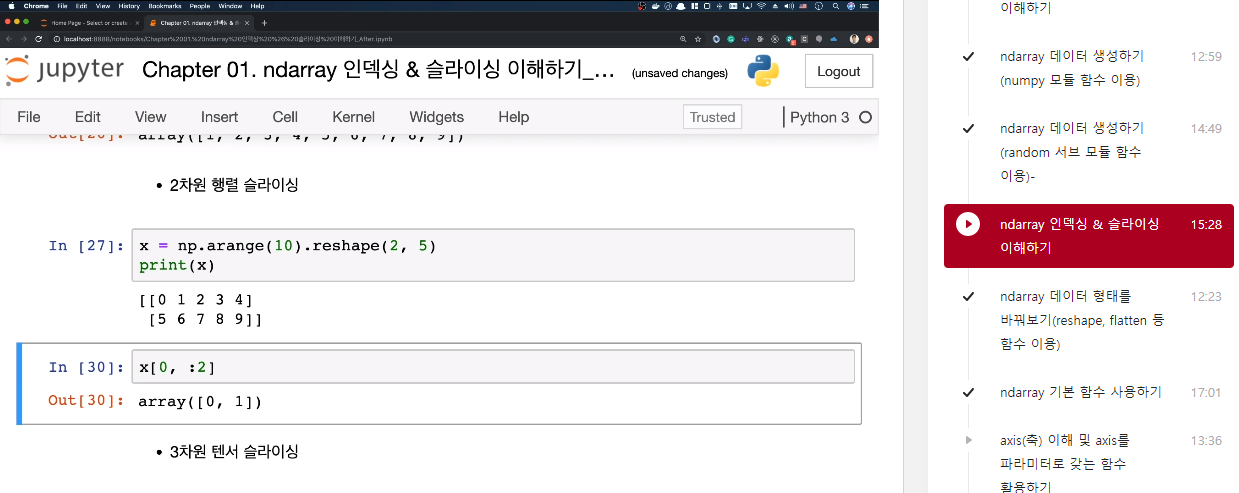
x = np.arange(10).reshape(2, 5)
print(x)
>>> [[0 1 2 3 4]
[5 6 7 8 9]]
x[0, :2]
>>> array([0, 1])
x[:1, :2]
>>> array([[0, 1]])3차원 텐서 슬라이싱
x = np.arange(54).reshape(2, 9, 3)
print(x)
>>> [[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]
[24 25 26]]
[[27 28 29]
[30 31 32]
[33 34 35]
[36 37 38]
[39 40 41]
[42 43 44]
[45 46 47]
[48 49 50]
[51 52 53]]]
x[:1, :2, :]
>>> array([[[0, 1, 2],
[3, 4, 5]]])
x[0, :2, :]
>>> array([[0, 1, 2],
[3, 4, 5]])데이터 형태를 바꿔보기
ravel, np.ravel
- 다차원배열을 1차원으로 변경
- 'order'파라미터
- 'C' - row 우선 변경
- 'F' - column 우선 변경
import numpy as np
x = np.arange(15).reshape(3, 5)
print(x)
>>> [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
np.ravel(x, order='C')
>>> array([100, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14])
temp = x.ravel()
print(temp)
>>> [100 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
temp[0] = 100
print(temp)
print(x)
>>> [100 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
[[100 1 2 3 4]
[ 5 6 7 8 9]
[ 10 11 12 13 14]]flatten
- 다차원 배열을 1차원으로 변경
- ravel과의 차이점: copy를 생성하여 변경함(원본 데이터가 아닌 복사본을 반환)
- 'order'파라미터
- 'C' - row 우선 변경
- 'F' - column 우선 변경
import numpy as np
y = np.arange(15).reshape(3, 5)
print(y)
>>> [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
t2 = y.flatten(order='F')
print(t2)
>>> [ 0 5 10 1 6 11 2 7 12 3 8 13 4 9 14]
t2[0] = 100
print(t2)
print(y)
>>> [100 5 10 1 6 11 2 7 12 3 8 13 4 9 14]
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
x = np.arange(30).reshape(2, 3, 5)
print(x)
>>> [[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]]
x.ravel()
>>> array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29])reshape 함수
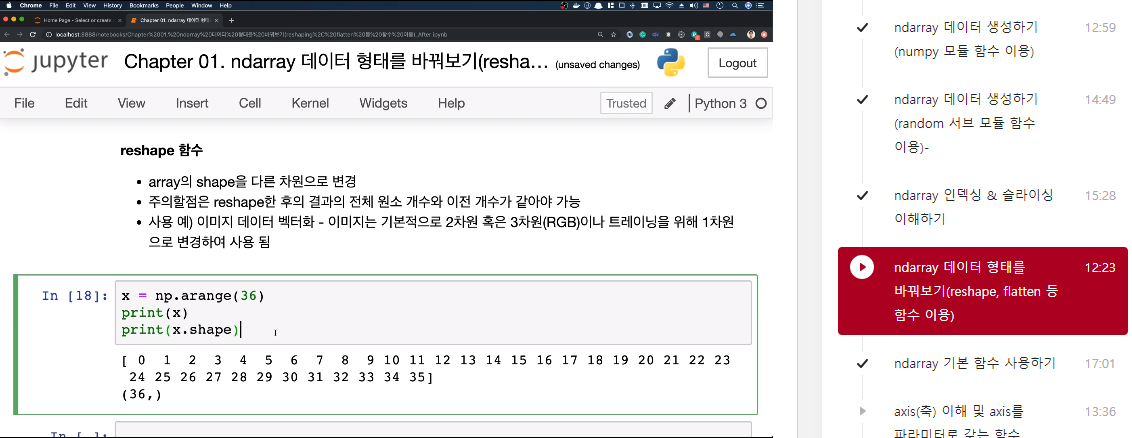
- array의 shape을 다른 차원으로 변경
- 주의할점은 reshape한 후의 결과의 전체 원소 개수와 이전 개수가 같아야 가능
- 사용 예) 이미지 데이터 벡터화 - 이미지는 기본적으로 2차원 혹은 3차원(RGB)이나 트레이닝을 위해 1차원으로 변경하여 사용 됨
import numpy as np
x = np.arange(36)
print(x)
>>> [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35]
print(x.shape)
>>> (36,)
print(x.ndim)
>>> 1
y = x.reshape(6, 6)
print(y.shape)
>>> (6, 6)
print(y.ndim)
>>> 2
k = x.reshape(3, 3, 4)
print(k)
>>> [[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]
[[24 25 26 27]
[28 29 30 31]
[32 33 34 35]]]
print(k.shape)
>>> (3, 3, 4)
print(k.ndim)
>>> 3ndarray 기본함수 사용하기
import numpy as np
x = np.arange(15).reshape(3, 5)
y = np.random.rand(15).reshape(3, 5)
print(x)
>>> [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
print(y)
>>> [[0.29419894 0.10973333 0.44661214 0.72206182 0.33746284]
[0.30929705 0.48161986 0.98595533 0.59121649 0.37234127]
[0.38870562 0.25311819 0.25133838 0.65015452 0.82994021]]연산 함수
- add, subtract, multiply, divide
np.add(x, y) # x + y
>>> array([[ 0.75224468, 1.30055822, 2.06025704, 3.66341736, 4.86524495],
[ 5.42773751, 6.31666404, 7.56224952, 8.22587263, 9.01309335],
[10.41688496, 11.45213627, 12.90228259, 13.29005788, 14.43254152]])
np.subtract(x, y) # x - y
>>> array([[-0.75224468, 0.69944178, 1.93974296, 2.33658264, 3.13475505],
[ 4.57226249, 5.68333596, 6.43775048, 7.77412737, 8.98690665],
[ 9.58311504, 10.54786373, 11.09771741, 12.70994212, 13.56745848]])
np.multiply(x, y) # x * y
>>> array([[ 0. , 0.30055822, 0.12051408, 1.99025208, 3.4609798 ],
[ 2.13868754, 1.89998422, 3.93574662, 1.80698105, 0.11784019],
[ 4.1688496 , 4.97349894, 10.82739106, 3.77075249, 6.05558129]])
np.divide(x, y) # x / y
>>> array([[ 0. , 3.32714241, 33.19114364, 4.52204024,
4.62296833],
[ 11.6894121 , 18.94752579, 12.44998846, 35.41819099,
687.37160021],
[ 23.98743286, 24.3289486 , 13.29960276, 44.81864047,
32.36683492]])통계 함수
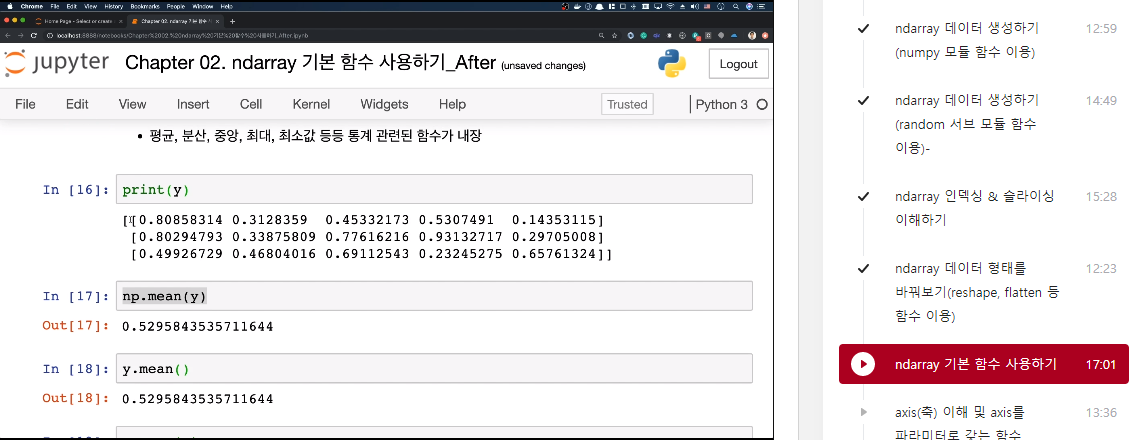
- 평균, 분산, 중앙, 최대, 최솟값 등 통계 관련된 함수가 내장
print(y)
>>> [[0.75224468 0.30055822 0.06025704 0.66341736 0.86524495]
[0.42773751 0.31666404 0.56224952 0.22587263 0.01309335]
[0.41688496 0.45213627 0.90228259 0.29005788 0.43254152]]
np.mean(y) # y.mean()
>>> 0.4454161674239645
np.max(y)
>>> 0.9022825884097446
np.argmax(y) # 최대값의 인덱스
>>> 12
np.var(y), np.median(y), np.std(y) # 분산, 중앙값, 표준편차
>>> (0.06578573103306738, 0.4277375079706378, 0.25648729214732524)집계함수
- 합계(sum), 누적합계(cumsum) 등 계산 가능
print(y)
>>> [[0.75224468 0.30055822 0.06025704 0.66341736 0.86524495]
[0.42773751 0.31666404 0.56224952 0.22587263 0.01309335]
[0.41688496 0.45213627 0.90228259 0.29005788 0.43254152]]
np.sum(y, axis=None)
>>> 6.681242511359468
np.cumsum(y)
>>> array([0.75224468, 1.0528029 , 1.11305993, 1.77647729, 2.64172224,
3.06945975, 3.38612379, 3.94837331, 4.17424594, 4.18733929,
4.60422425, 5.05636052, 5.95864311, 6.24870099, 6.68124251])any, all 함수
- any : 특정 조건을 만족하는 것이 하나라도 있으면 True 아니면 False
- all : 모든 원소가 특정 조건을 만족한다면 True 아니면 False
z = np.random.randn(10)
print(z)
>>> [-0.74826576 -1.40356647 0.12376035 1.102159 0.85542721 0.36086814
-0.10662314 -0.97492934 -0.13502096 -1.41779804]
z > 0
>>> [-0.74826576 -1.40356647 0.12376035 1.102159 0.85542721 0.36086814
-0.10662314 -0.97492934 -0.13502096 -1.41779804]
np.any(z > 0)
>>> True
np.all(z > 0)
>>> Falsewhere 함수
- 조건에 따라 선별적으로 값을 선택 가능
- 예) 음수인 경우 0, 나머지는 그대로 값을 쓰는 경우
z = np.random.randn(10)
print(z)
>>> [-1.82324893 -1.36219435 -1.04253733 0.57851976 1.02263446 0.25444967
-0.33404657 2.53035037 1.60376066 -0.10919724]
np.where(z > 0, z, 0)
>>> array([0. , 0. , 0. , 0.57851976, 1.02263446,
0.25444967, 0. , 2.53035037, 1.60376066, 0. ])머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
