numpy 모듈 & ndarray 이해하기
- 성능 : 파이썬 리스트보다 빠름
- 메모리 사이즈 : 파이썬 리스트보다 적은 메모리 사용
- 빌트인 함수 : 선형대수, 통계관련 여러 함수 내장
import numpy as np
import matplotlib as plt
x = np.array([1, 2, 3])
y = np.array([2, 4, 6])
print(x) # [1 2 3]
print(y) # [2 4 6]
numpy 모듈 함수 이용
np.array 함수로 생성하기
import numpy as np
x = np.array([1, 2, 3, 4])
print(x)
y = np.array([[2, 3, 4], [1, 2, 5]])
print(y)
print(type(y))
"""
[1 2 3 4]
[[2 3 4]
[1 2 5]]
<class 'numpy.ndarray'>
"""np.arange 함수로 생성하기
import numpy as np
np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1, 10)
# array([1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1, 10, 2)
# array([1, 3, 5, 7, 9])
np.arange(5, 20, 5)
# array([ 5, 10, 15])np.ones, np.zeros로 생성하기
import numpy as np
np.ones((3, 4))
# array([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]])
np.ones((2, 2, 2))
"""
array([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]])
"""
np.zeros((3,5))
"""
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
"""np.empty, np.full로 생성하기
np.empty((3, 4))
"""
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
"""
np.full((3, 2), 7)
"""
array([[7, 7],
[7, 7],
[7, 7]])
"""np.eye로 생성하기
- 단위 행렬 생성
np.eye(3)
"""
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
"""np.linespace로 생성하기
np.linspace(1, 10, 3)
# array([ 1. , 5.5, 10. ])
np.linspace(1, 10, 4)
# array([ 1., 4., 7., 10.])
np.linspace(1, 10, 5)
# array([ 1. , 3.25, 5.5 , 7.75, 10. ])reshape 함수 활용
- ndarray의 형태, 차원을 바꾸기 위해 사용
x = np.arange(1, 16)
print(x)
x.reshape(3, 5)
"""
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
"""random 서브 모듈 함수 이용
rand 함수
- 0, 1사이의 분포로 랜덤한 ndarray 생성
import numpy as np
np.random.rand(2, 3)
"""
array([[0.8596183 , 0.62532376, 0.98240783],
[0.97650013, 0.16669413, 0.02317814]])
"""randn 함수
- n: normal distribution(정규분포)
- 정규분포로 샘플링된 랜덤 ndarray 생성
import numpy as np
np.random.randn(5)
# array([-1.69751436, -0.33407334, 0.88470927, 0.20456871, -1.086702 ])
np.random.randn(3, 4)
"""
array([[ 0.44756853, -0.93118759, 0.46549303, -0.32103462],
[-0.69280955, -1.59401986, -1.54582636, 0.11431481],
[-0.39335493, -1.58291022, 0.72940243, 0.3318997 ]])
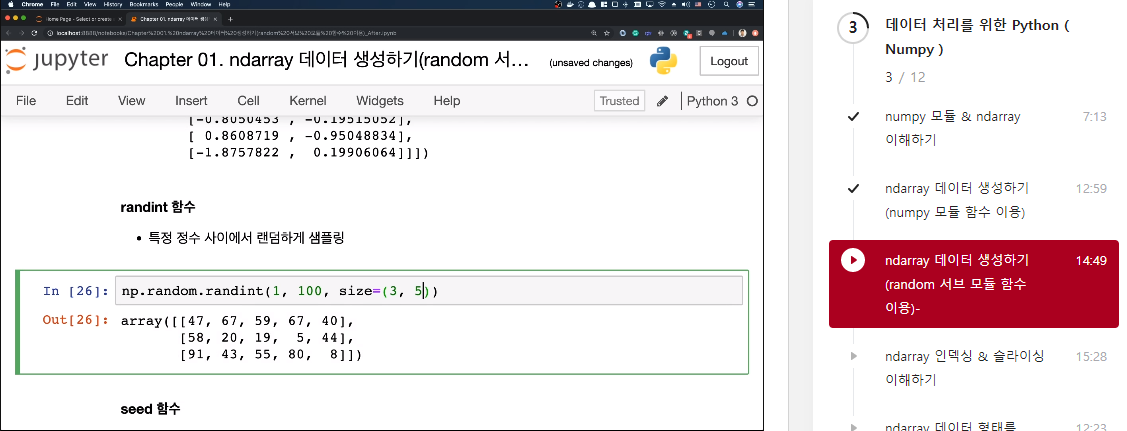
"""randint 함수
- 특정 정수 사이에서 랜덤하게 샘플링
import numpy as np
np.random.randint(1, 100, size=(3, 5))
"""
array([[25, 94, 59, 29, 83],
[83, 8, 95, 3, 64],
[ 3, 88, 18, 91, 94]])
"""seed 함수
- 랜덤한 값을 동일하게 다시 생성하고자 할 때 사용
import numpy as np
np.random.seed(100)
np.random.randn(3, 4)choice
- 주어진 1차원 ndarray로 부터 랜덤으로 샘플링
- 정수가 주어진 경우, np.arange(해당숫자)로 간주
import numpy as np
np.random.choice(100, size=(3, 4))
"""
array([[83, 4, 91, 59],
[67, 7, 49, 47],
[65, 61, 14, 55]])
"""
x = np.array([1, 2, 3, 1.5, 2.6, 4.9])
np.random.choice(x, size=(2, 2), replace=False)
"""
array([[1. , 2.6],
[2. , 4.9]])
"""확률분포에 따른 ndarray 생성
- uniform
- normal 등
import numpy as np
np.random.uniform(1.0, 3.0, size=(3, 4))
"""
array([[2.76970659, 1.71901569, 2.19771789, 1.70959122],
[1.68038043, 1.35616198, 1.47538842, 1.08972456],
[2.01086286, 1.75250491, 2.1856108 , 2.25988375]])
"""
np.random.normal(size=(3, 4)) # np.random.randn(3, 4)
"""
array([[-0.43760186, -1.90579488, -1.22901933, 0.79489886],
[-1.16050814, 0.54605552, 1.16325833, 0.65887702],
[ 0.52368926, 1.32715607, 1.11252447, -1.07462961]])
"""머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
