pivot, pivot_table 함수의 이해 및 활용하기
import numpy as np
import pandas as pddf = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '화요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df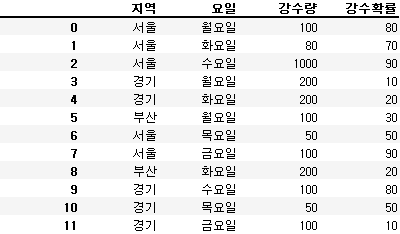
pivot
- dataframe의 형태를 변경
- 인덱스, 컬럼, 데이터로 사용할 컬럼을 명시
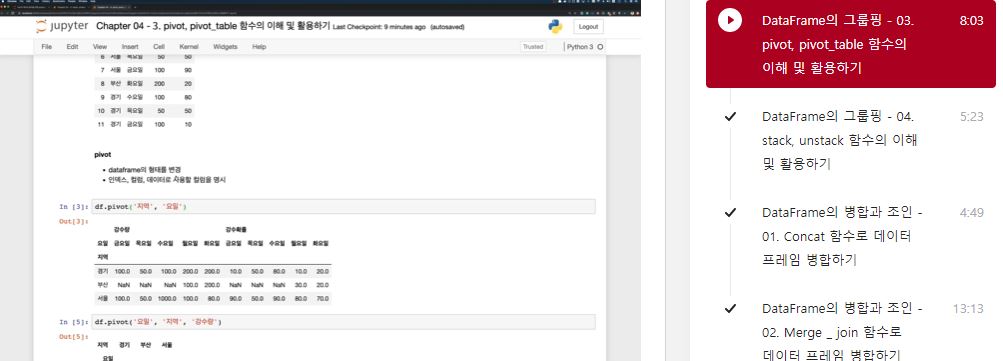
df.pivot('지역', '요일')
df.pivot('요일', '지역')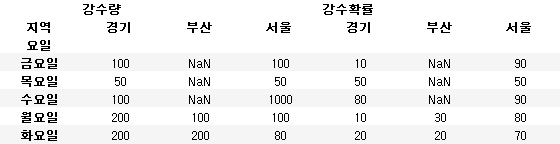
pivot_table
- 기능적으로 pivot과 동일
- pivot과의 차이점
- 중복되는 모호한 값이 있을 경우, aggregation 함수 사용하여 값을 채움
pd.pivot_table(df, index='요일', columns='지역', aggfunc=np.mean)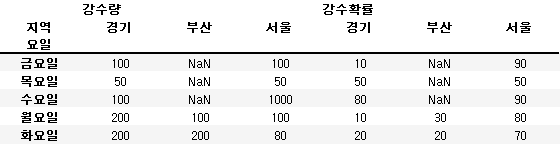
stack, unstack 함수 이해 및 활용하기
import numpy as np
import pandas as pddf = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '화요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df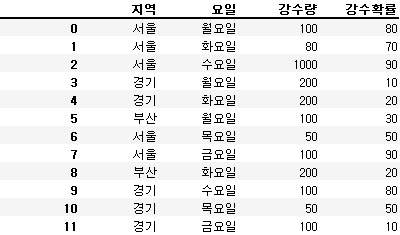
stack & unstack
- stack : 컬럼 레벨에서 인덱스 레벨로 dataframe 변경
- 데이터를 쌓아올리는 개념으로 이해하면 쉬움
- unstack : 인덱스 레벨에서 컬럼 레벨로 dataframe 변경
- stack의반대 operation
- 둘은 역의 관계에 있음
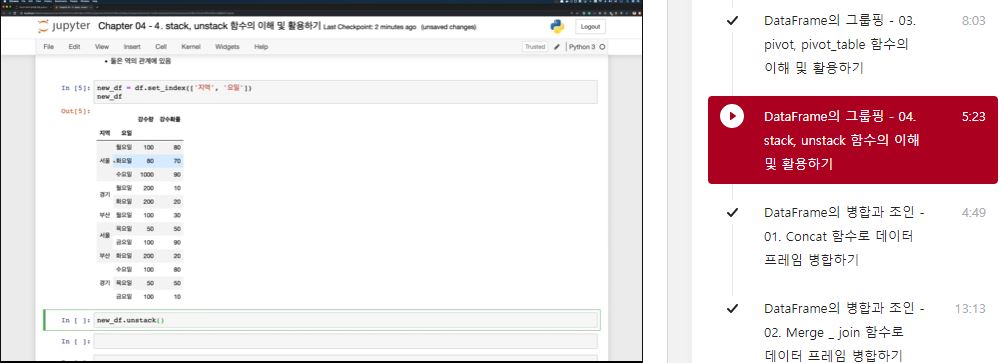
new_df = df.set_index(['지역', '요일'])
new_df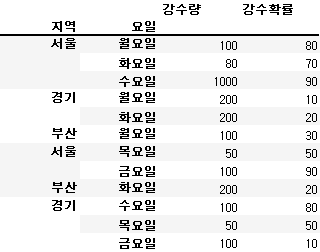
# 첫번째 레벨의 인덱스를 컬럼으로 이동
new_df.unstack(0)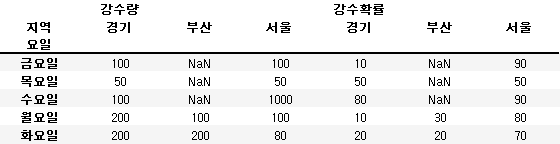
# 두번째 레벨의 인덱스를 컬럼으로 이동
new_df.unstack(1)
# 첫번째 레벨의 컬럼을 인덱스로 이동
new_df.unstack(0).stack(0)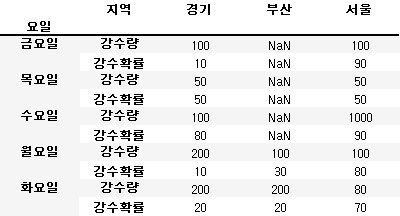
new_df.unstack(0).stack(1)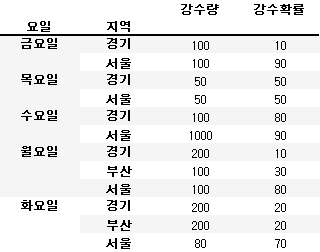
new_df.stack
>>> <bound method DataFrame.stack of 강수량 강수확률
지역 요일
서울 월요일 100 80
화요일 80 70
수요일 1000 90
경기 월요일 200 10
화요일 200 20
부산 월요일 100 30
서울 목요일 50 50
금요일 100 90
부산 화요일 200 20
경기 수요일 100 80
목요일 50 50
금요일 100 10>Concat 함수로 데이터 프레임 병합하기
import numpy as np
import pandas as pdconcat 함수 사용하여 dataframe 병합하기
- pandas.concat 함수
- 축을 따라 dataframe을 병합 가능
- 기본 axis = 0 -> 행단위 병합
- column명이 같은 경우
df1 = pd.DataFrame({'key1' : np.arange(10), 'value1' : np.random.randn(10)})
df2 = pd.DataFrame({'key1' : np.arange(10), 'value1' : np.random.randn(10)})df2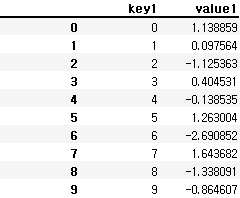
pd.concat([df1, df2], ignore_index = True)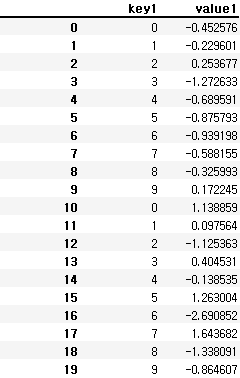
pd.concat([df1, df2], axis = 1)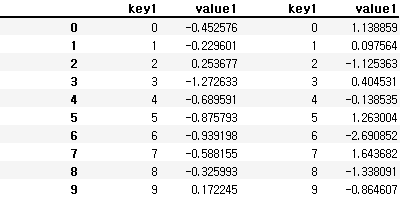
- column 명이 다른 경우
df3 = pd.DataFrame({'key2' : np.arange(10), 'value2' : np.random.randn(10)})pd.concat([df1, df3], axis=1)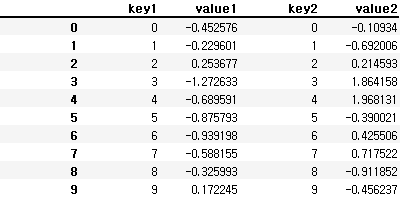
Merge, join 함수로 데이터 프레임 병합하기
import numpy as np
import pandas as pddataframe merge
- SQL의 join처럼 특정한 column을 기준으로 병합
- join 방식 : how 파라미터를 통해 명시
- inner : 기본값, 일치하는 값이 있는 경우
- left : left outer join
- right : right outer join
- outer : full outer join
- join 방식 : how 파라미터를 통해 명시
- pandas.merge 함수가 사용됨
customer = pd.DataFrame({'customer_id' : np.arange(6),
'name' : ['철수'"", '영희', '길동', '영수', '수민', '동건'],
'나이' : [40, 20, 21, 30, 31, 18]})
customer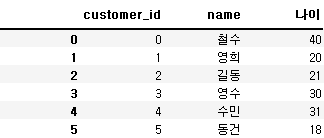
orders = pd.DataFrame({'customer_id' : [1, 1, 2, 2, 2, 3, 3, 1, 4, 9],
'item' : ['치약', '칫솔', '이어폰', '헤드셋', '수건', '생수', '수건', '치약', '생수', '케이스'],
'quantity' : [1, 2, 1, 1, 3, 2, 2, 3, 2, 1]})
orders.head()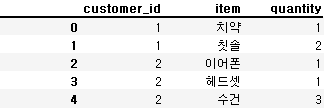
- on
- join 대상이 되는 column 명시
pd.merge(customer, orders, on='customer_id', how='inner')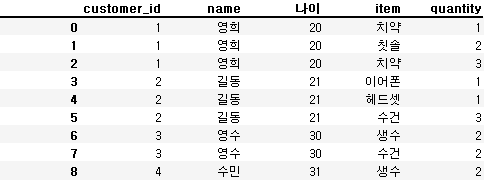
pd.merge(customer, orders, on='customer_id', how='left')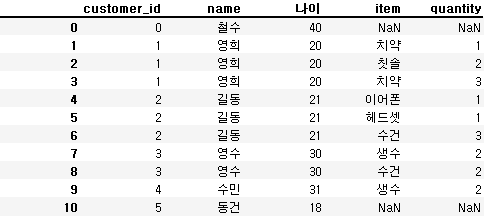
pd.merge(customer, orders, on='customer_id', how='right')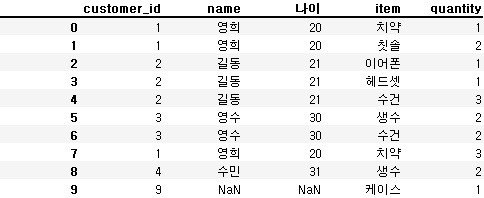
pd.merge(customer, orders, on='customer_id', how='outer')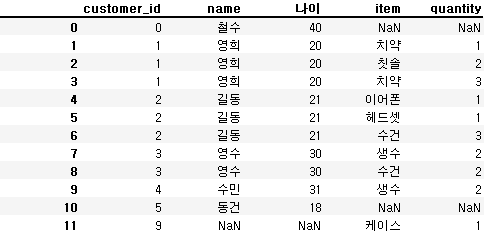
cust1 = customer.set_index('customer_id')
order1 = orders.set_index('customer_id')cust1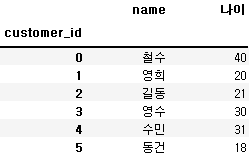
order1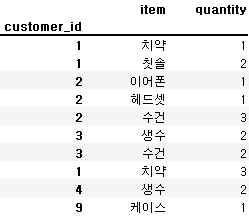
pd.merge(cust1, order1, left_index=True, right_index=True)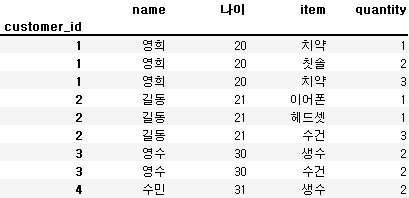
join 함수
- 내부적으로 pandas.merge 함수 사용
- 기본적으로 index를 사용하여 left join
cust1.join(order1, how='inner')
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
