범주형 데이터 전처리 하기(one-hot encoding)
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
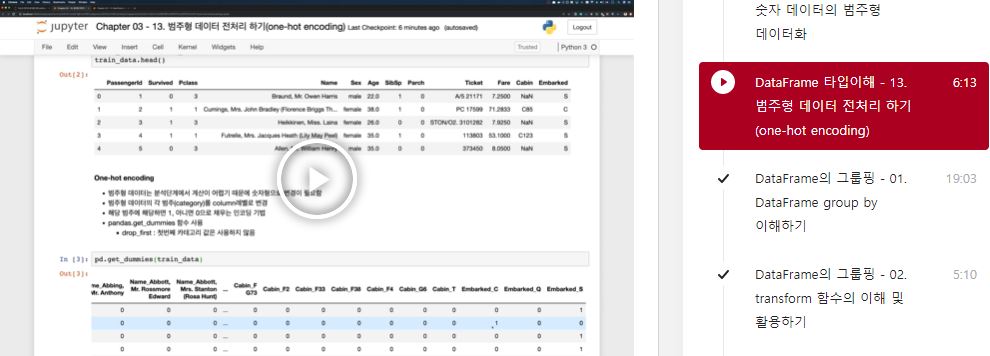
train_data.head()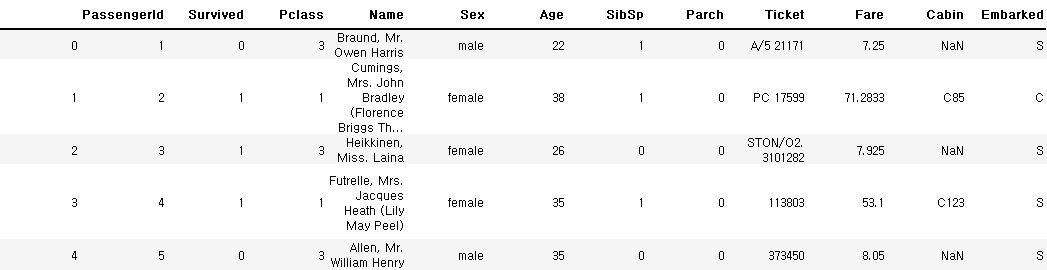
One-hot encoding
- 범주형 데이터는 분석단계에서 계산이 어렵기 때문에 숫자형으로 변경이 필요함
- 범주형 데이터는 각 범주를 column레벨로 변경
- 해당 범주에 해당하면 1, 아니면 0으로 채우는 인코딩 기법
- pandas.get_dummies 함수 사용
- drop_first : 첫번째 카테고리 값은 사용하지 않음
pd.get_dummies(train_data, columns=['Pclass', 'Sex', 'Embarked'], drop_first=False)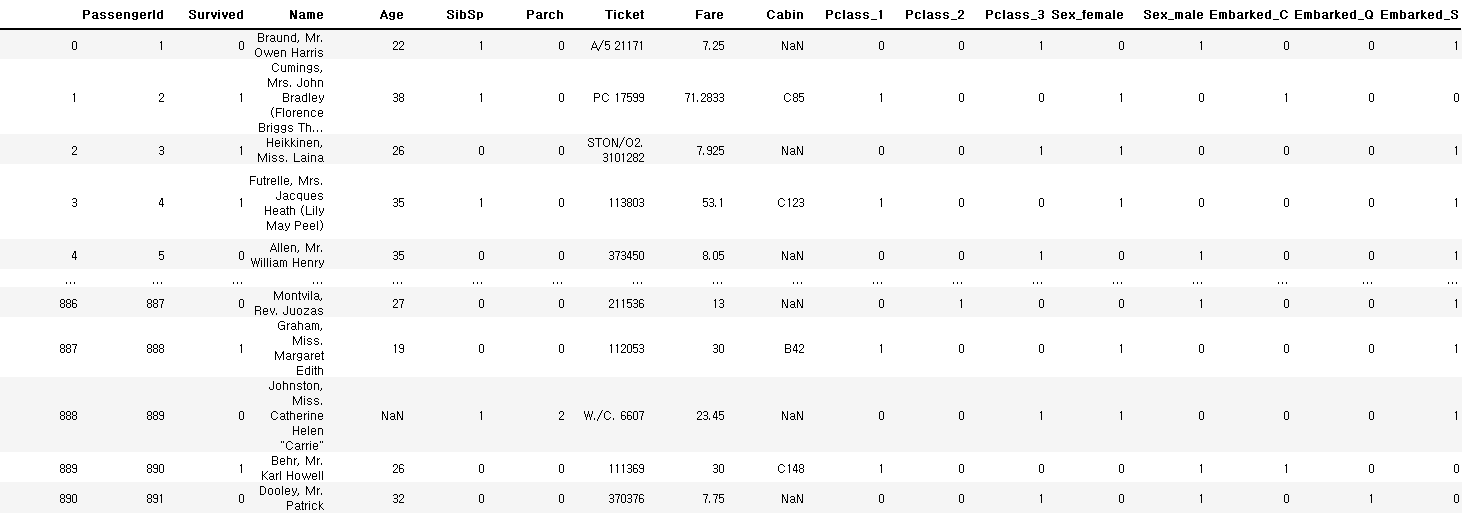
pd.get_dummies(train_data, columns=['Pclass', 'Sex', 'Embarked'], drop_first=True)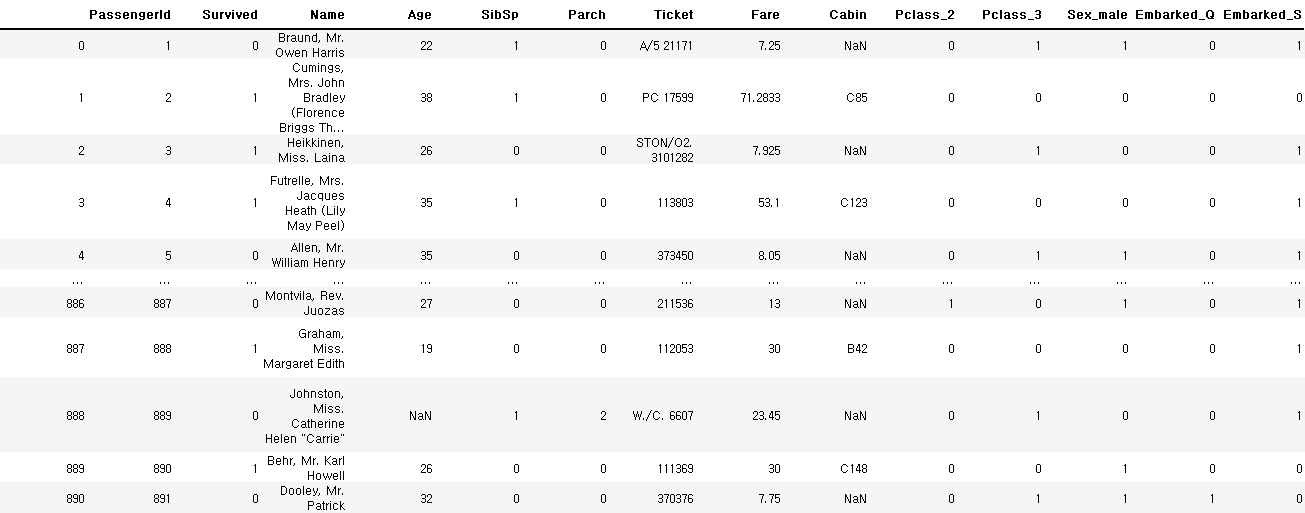
DataFrame group by 이해하기
import pandas as pd
import numpy as npgruop by
- 아래의 세 단계를 적용하여 데이터를 그룹화(SQL의 group by와 개념적으로는 동일, 사용법은 유사)
- 데이터 분할
- operation 적용
- 데이터 병합
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
df = pd.read_csv('../train.csv')
df.head()GroupBy grouops속성
- 각 그룹과 그룹에 속한 index를 dict형태로 표현
class_group = df.gruopby('Pclass'
class_gruop
>>> <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000025C5ECE7308>class_group.groups
>>> {1: [1, 3, 6, 11, 23, 27, 30, 31, 34, 35, 52, 54, 55, 61, 62, 64, 83, 88, 92, 96, 97, 102, 110, 118, 124, 136, 137, 139, 151, 155, 166, 168, 170, 174, 177, 185, 187, 194, 195, 209, 215, 218, 224, 230, 245, 248, 252, 256, 257, 258, 262, 263, 268, 269, 270, 273, 275, 284, 290, 291, 295, 297, 298, 299, 305, 306, 307, 309, 310, 311, 318, 319, 325, 329, 331, 332, 334, 336, 337, 339, 341, 351, 356, 366, 369, 370, 373, 375, 377, 380, 383, 390, 393, 412, 430, 434, 435, 438, 445, 447, ...], 2: [9, 15, 17, 20, 21, 33, 41, 43, 53, 56, 58, 66, 70, 72, 78, 84, 98, 99, 117, 120, 122, 123, 133, 134, 135, 144, 145, 148, 149, 150, 161, 178, 181, 183, 190, 191, 193, 199, 211, 213, 217, 219, 221, 226, 228, 232, 234, 236, 237, 238, 239, 242, 247, 249, 259, 265, 272, 277, 288, 292, 303, 308, 312, 314, 316, 317, 322, 323, 327, 340, 342, 343, 344, 345, 346, 357, 361, 385, 387, 389, 397, 398, 399, 405, 407, 413, 416, 417, 418, 426, 427, 432, 437, 439, 440, 443, 446, 450, 458, 463, ...], 3: [0, 2, 4, 5, 7, 8, 10, 12, 13, 14, 16, 18, 19, 22, 24, 25, 26, 28, 29, 32, 36, 37, 38, 39, 40, 42, 44, 45, 46, 47, 48, 49, 50, 51, 57, 59, 60, 63, 65, 67, 68, 69, 71, 73, 74, 75, 76, 77, 79, 80, 81, 82, 85, 86, 87, 89, 90, 91, 93, 94, 95, 100, 101, 103, 104, 105, 106, 107, 108, 109, 111, 112, 113, 114, 115, 116, 119, 121, 125, 126, 127, 128, 129, 130, 131, 132, 138, 140, 141, 142, 143, 146, 147, 152, 153, 154, 156, 157, 158, 159, ...]}gender_group = df.groupby('Sex')
gender_group.groups
>>> {'female': [1, 2, 3, 8, 9, 10, 11, 14, 15, 18, 19, 22, 24, 25, 28, 31, 32, 38, 39, 40, 41, 43, 44, 47, 49, 52, 53, 56, 58, 61, 66, 68, 71, 79, 82, 84, 85, 88, 98, 100, 106, 109, 111, 113, 114, 119, 123, 128, 132, 133, 136, 140, 141, 142, 147, 151, 156, 161, 166, 167, 172, 177, 180, 184, 186, 190, 192, 194, 195, 198, 199, 205, 208, 211, 215, 216, 218, 229, 230, 233, 235, 237, 240, 241, 246, 247, 251, 254, 255, 256, 257, 258, 259, 264, 268, 269, 272, 274, 275, 276, ...], 'male': [0, 4, 5, 6, 7, 12, 13, 16, 17, 20, 21, 23, 26, 27, 29, 30, 33, 34, 35, 36, 37, 42, 45, 46, 48, 50, 51, 54, 55, 57, 59, 60, 62, 63, 64, 65, 67, 69, 70, 72, 73, 74, 75, 76, 77, 78, 80, 81, 83, 86, 87, 89, 90, 91, 92, 93, 94, 95, 96, 97, 99, 101, 102, 103, 104, 105, 107, 108, 110, 112, 115, 116, 117, 118, 120, 121, 122, 124, 125, 126, 127, 129, 130, 131, 134, 135, 137, 138, 139, 143, 144, 145, 146, 148, 149, 150, 152, 153, 154, 155, ...]}groupping 함수
- 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산
- count - 데이터 개수
- sum - 데이터의 합
- mean, std, var - 평균, 표준편차, 분산
- min, max - 최소, 최대값값
class_group.count()
class_group.mean()['Survived']
>>> Pclass
1 0.629630
2 0.472826
3 0.242363
Name: Survived, dtype: float64- 성별에 따른 생존률 구해보기
df.groupby('Sex').mean()['Survived']
>>> Sex
female 0.742038
male 0.188908
Name: Survived, dtype: float64복수 columns로 groupping
-
groupbby에 column 리스트를 전달
-
통계함수를 적용한 결과는 multiindex를 갖는 dataframe
-
클래스와 성별에 따른 생존률 구해보기
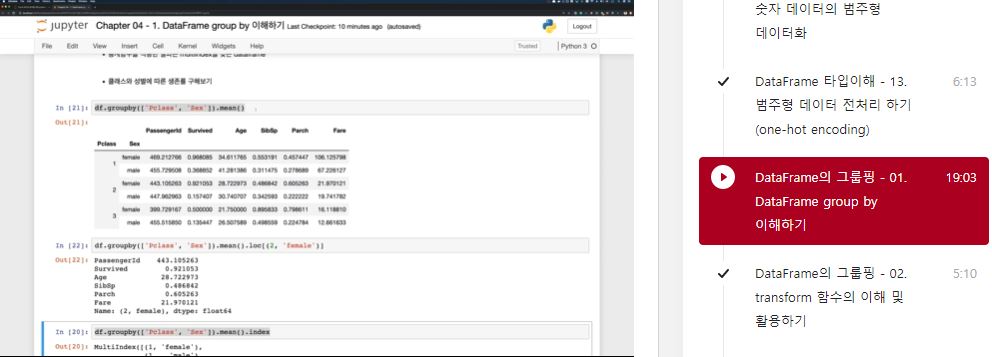
df.groupby(['Pclass', 'Sex']).mean()['Survived']
>>> Pclass Sex
1 female 0.968085
male 0.368852
2 female 0.921053
male 0.157407
3 female 0.500000
male 0.135447
Name: Survived, dtype: float64df.groupby(['Pclass', 'Sex']).mean().loc[(2, 'female')]
>>> PassengerId 443.105263
Survived 0.921053
Age 28.722973
SibSp 0.486842
Parch 0.605263
Fare 21.970121
Name: (2, female), dtype: float64df.groupby(['Pclass', 'Sex']).mean().index
>>> MultiIndex([(1, 'female'),
(1, 'male'),
(2, 'female'),
(2, 'male'),
(3, 'female'),
(3, 'male')],
names=['Pclass', 'Sex'])index를 이용한 group by
-
index가 있는 경우, groupby 함수에 level 사용 가능
- level은 index의 depth를 의미하며, 가장 왼쪽부터 0부터 증가
-
set_index 함수
- column 데이터를 index 레벨로 변경
-
reset_index 함수
- 인덱스 초기화
df.head()
df.set_index(['Pclass', 'Sex']).reset_index()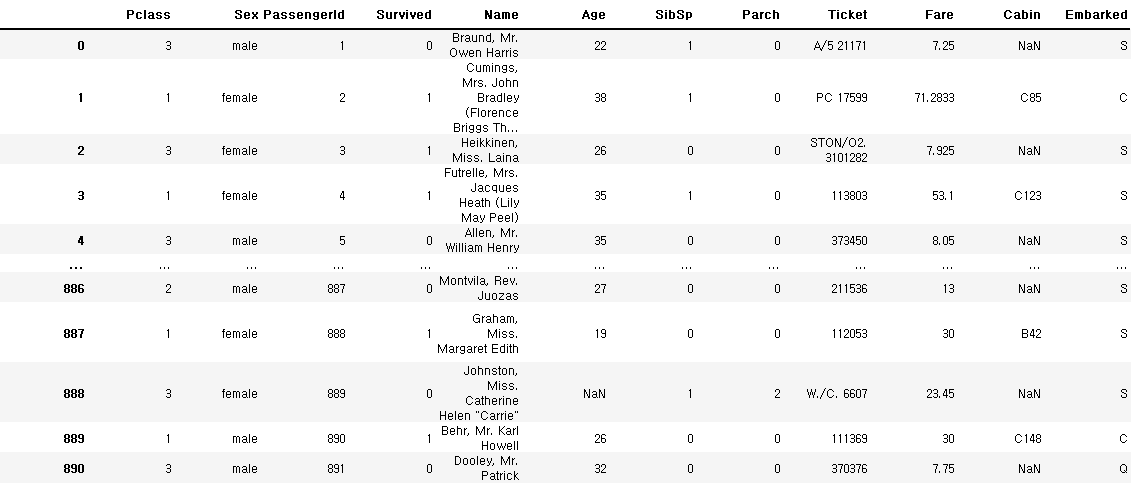
df.set_index('Age').groupby(level=0).mean()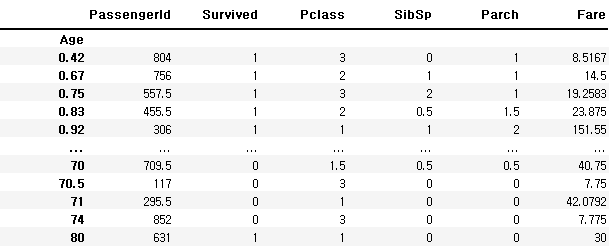
import math
def age_categorize(age):
if math.isnan(age):
return -1
return math.floor(age / 10) * 10df.set_index('Age').groupby(age_categorize).mean()['Survived']
>>> -1 0.293785
0 0.612903
10 0.401961
20 0.350000
30 0.437126
40 0.382022
50 0.416667
60 0.315789
70 0.000000
80 1.000000
Name: Survived, dtype: float64Multiindex를 이용한 groupping
df.set_index(['Pclass', 'Sex']).groupby(level=[0, 1]).mean()['Age']
>>> Pclass Sex
1 female 34.611765
male 41.281386
2 female 28.722973
male 30.740707
3 female 21.750000
male 26.507589
Name: Age, dtype: float64aggregate(집계) 함수 사용하기
- groupby 결과에 집계함수를 적용하여 그룹별 데이터 확인 가능
df.set_index(['Pclass', 'Sex']).groupby(level=[0, 1]).aggregate([np.mean, np.sum, np.max])
transform 함수의 이해 및 활용하기
import numpy as np
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
df = pd.read_csv('../train.csv')
df.head()
transform 함수
- grouby 후 transform 함수를 사용하면 원래의 index를 유지한 상태로 통계함수를 적용
- 전체 데이터의 집계가 아닌 각 그룹에서의 집계를 계산
- 따라서 새로 생성된 데이터를 원본 dataframe과 합치기 쉬움
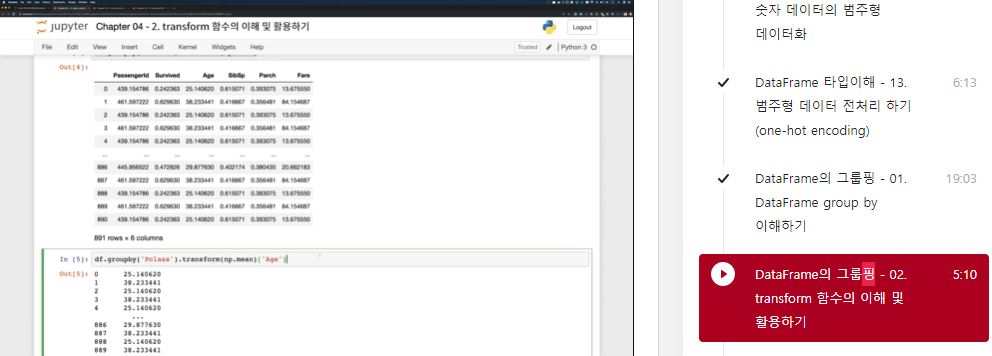
df.groupby('Pclass').mean()
df.groupby('Pclass').transform(np.mean)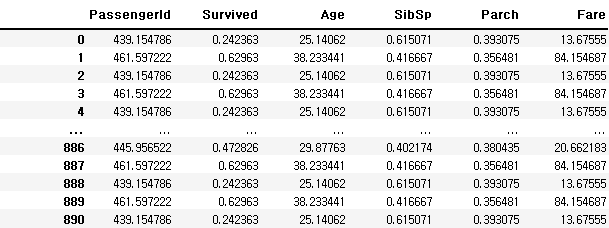
df['Age2'] = df.groupby('Pclass').transform(np.mean)['Age']
df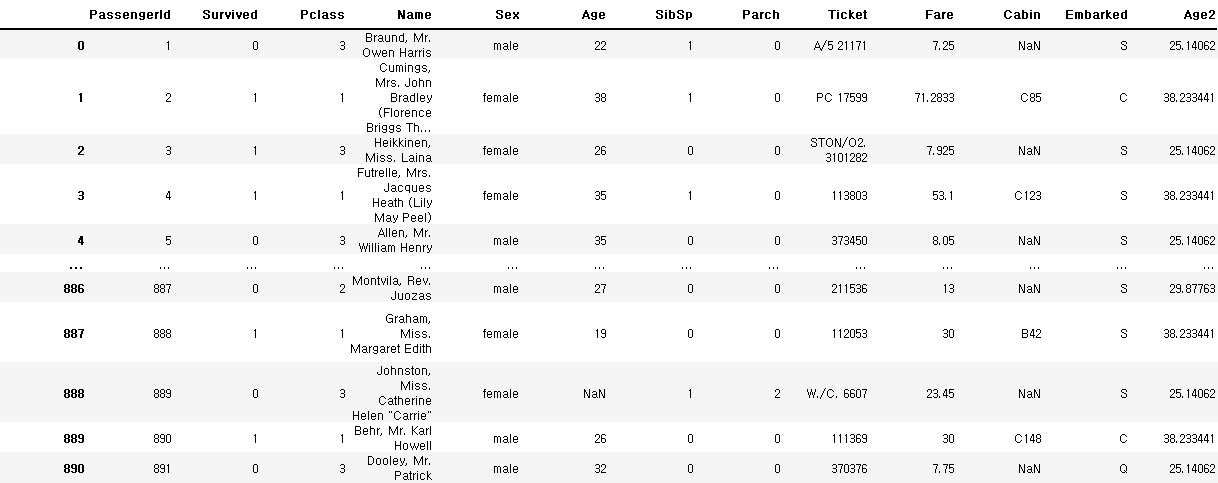
df.groupby(['Pclass', 'Sex']).mean()
df['Age3'] = df.groupby(['Pclass', 'Sex']).transform(np.mean)['Age']
df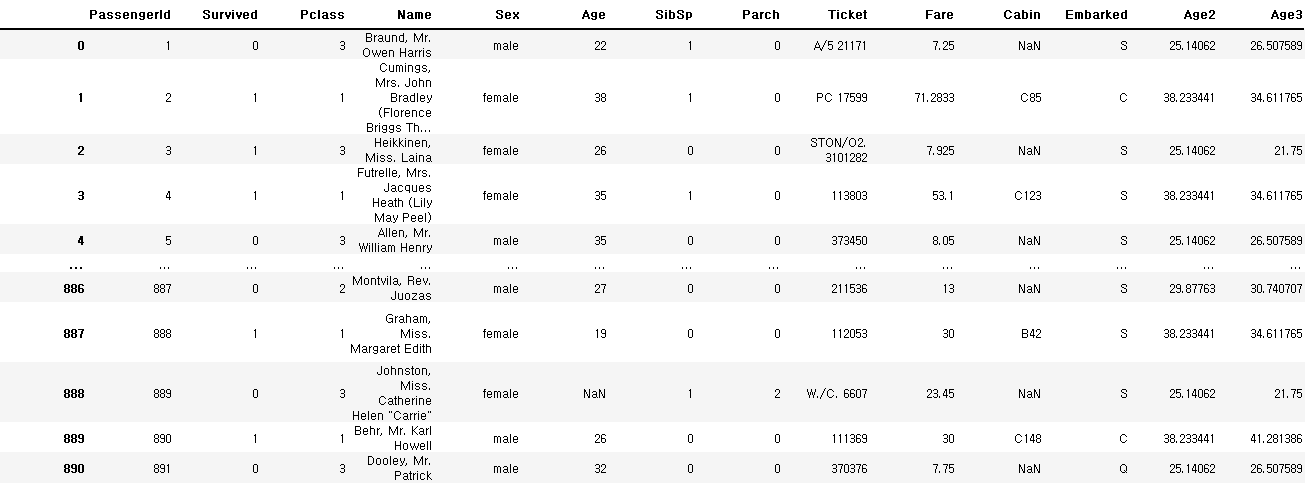
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
