지연된 조인
드라이빙 테이블만으로 필요한 데이터를 먼저 필터링한 후, 최소한의 레코드로만 조인을 수행하는 기법이다.
조인을 사용하는 쿼리에서 GROUP BY, ORDER BY, LIMIT 등이 함께 사용될 때 성능을 높이기 위해 조인을 최대한 늦추고 필요한 데이터만 먼저 필터링한다.
같은 결과를 반환하는 두 쿼리를 예시로 진행해보자.
SELECT e.*
FROM salaries s, employees e
WHERE e.emp_no = s.emp_no
AND s.emp_no BETWEEN 10001 AND 15000 -- 5,000명 대상
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10;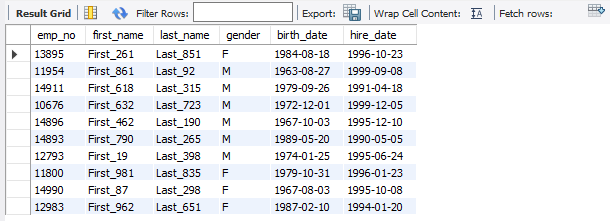
0.031 sec / 0.000 sec 가 소요되었다.
SELECT e.*
FROM (
SELECT s.emp_no
FROM salaries s
WHERE s.emp_no BETWEEN 10001 AND 15000
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10
) x, employees e
WHERE e.emp_no = x.emp_no;
0.015 sec / 0.000 sec 가 소요되었다. 시간도 단축 되었다.
실행 계획 비교
옵티마이저를 통해 두 쿼리 실행 계획을 비교해보자.
1. 기존 쿼리
EXPLAIN FORMAT=TREE
SELECT e.*
FROM salaries s, employees e
WHERE e.emp_no = s.emp_no
AND s.emp_no BETWEEN 10001 AND 15000
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10;실행계획:
-> Limit: 10 row(s)
-> Sort: sum(s.salary) DESC, limit input to 10 row(s) per chunk
-> Stream results (cost=16380 rows=1.01)
-> Group aggregate: sum(s.salary) (cost=16380 rows=1.01)
-> Nested loop inner join (co...2. 지연된 조인 적용 쿼리
EXPLAIN FORMAT=TREE
SELECT e.*
FROM (
SELECT s.emp_no
FROM salaries s
WHERE s.emp_no BETWEEN 10001 AND 15000
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10
) x, employees e
WHERE e.emp_no = x.emp_no;실행계획:
-> Nested loop inner join (cost=5 rows=0)
-> Table scan on x (cost=2.5..2.5 rows=0)
-> Materialize (cost=0..0 rows=0)
-> Limit: 10 row(s)
-> Sort: sum(s.salary) DESC, limit input to 10 row(s) per chunk
...옵티마이저는 지연된 조인 쿼리의 비용을 5로 예측한 반면, 원래 쿼리의 비용은 16380으로 예측했다. 비용 차이가 약 3,000배에 차이난다.

Studying Everyday