유사 화장품 추천 프로젝트
00. 프로젝트 기획안 🖥🧾
📝 목차
0. 주제 및 목표
1. 기획의도 및 배경
2. 데이터 수집 및 특성
3. 모델
4. 참고 문헌
0. 주제 및 목표
- 자연어 처리를 활용한 유사 화장품 추천 시스템 구축
- 감성품질(자연어)과 성분 간의 매핑
- 추후 시스템의 고도화를 위한 사전 작업
1. 기획의도 및 배경
📌 [ 배경 ]
시장 안정성 및 사업 성장 가능성:
- 세계 미용산업의 꾸준한 성장률 + 경제위기시에도 상대적으로 강한 회복력
셀프케어 트렌드로 피부관리 제품의 판매량 증가 (코로나19, AI기술+뷰티산업 결합의 영향) - 세계 뷰티테크 시장 연평균 19.1%씩 성장, 2023년 예상 시장규모 930억 달러(약 113조원) 이상
- 국내 뷰티테크 사업을 위한 인프라 구비
- 2018년 맞춤형화장품 관련 법안 통과
- 2020년 세계 최초로 맞춤형화장품 제도 시행
📌 [ 기획 의도 ]
- 현재 시장에 존재하는 맞춤형화장품 서비스(기성 제품 최저가 탐색, 주성분 검색 등)보다 고도화된 서비스가 최종 목표
- 그 전에 자연어와 화장품 성분 간의 정확한 매핑 관계를 찾기 위한 파일럿 프로젝트
- 📍 [최종 목표] 화장품의 소프트웨어화:
- 화장품의 지속적인 버전업 가능
- 재고관리 용이
- 락인 효과 발생
2. 데이터 수집 및 특성
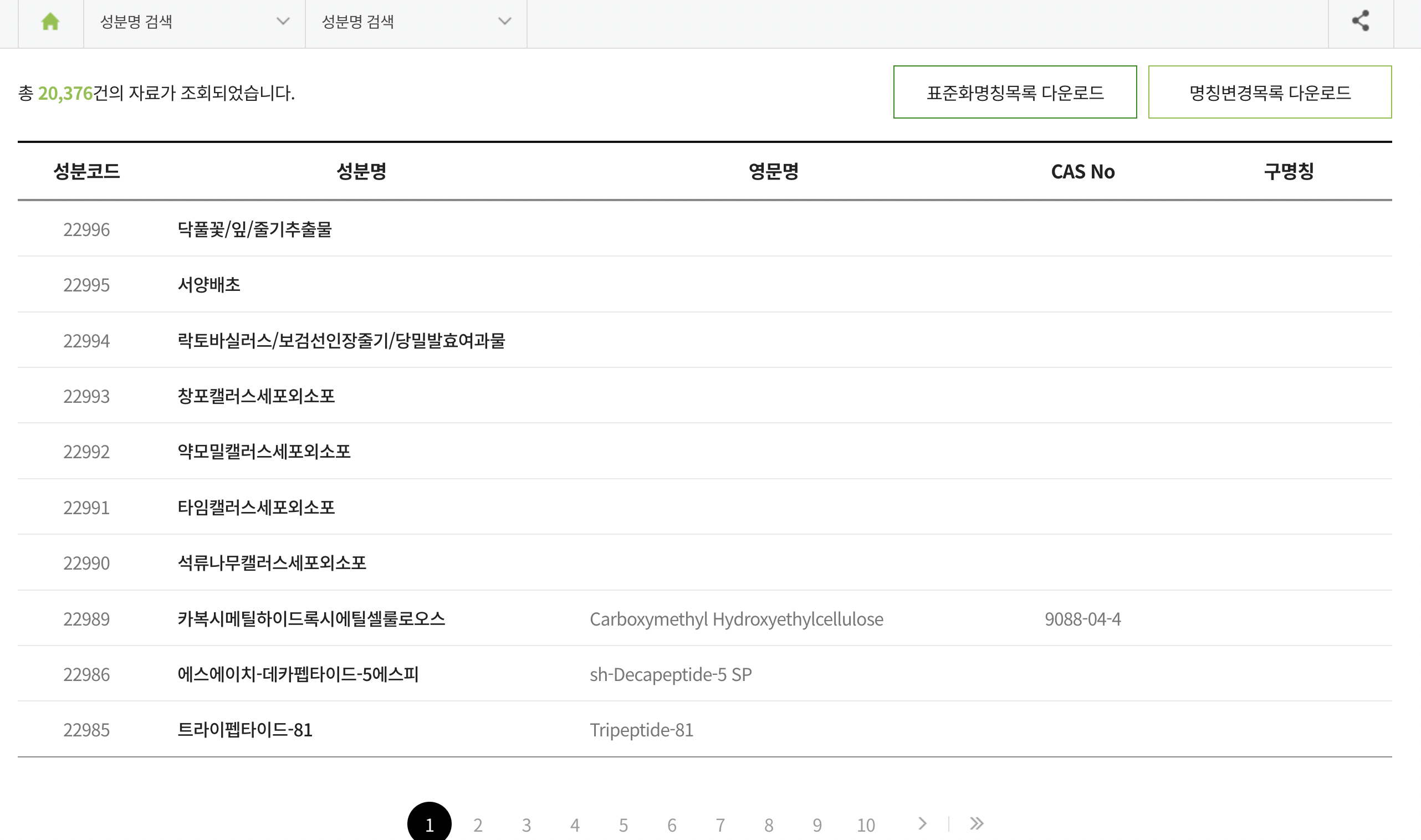
https://kcia.or.kr/cid/main/
대한 화장품 협회 성분사전
- 화장품 성분의 국문명, 영문명(INCI), CAS No, 구 명칭을 제공한다.
- 20,000개 정도의 데이터가 존재하며, CAS No를 제외하고는 모두 str 데이터.
https://incidecoder.com/
Incidecoder
- 화장품(제품), 성분, 성분의 효능 에 대한 데이터를 제공한다.
📌 Ingredients
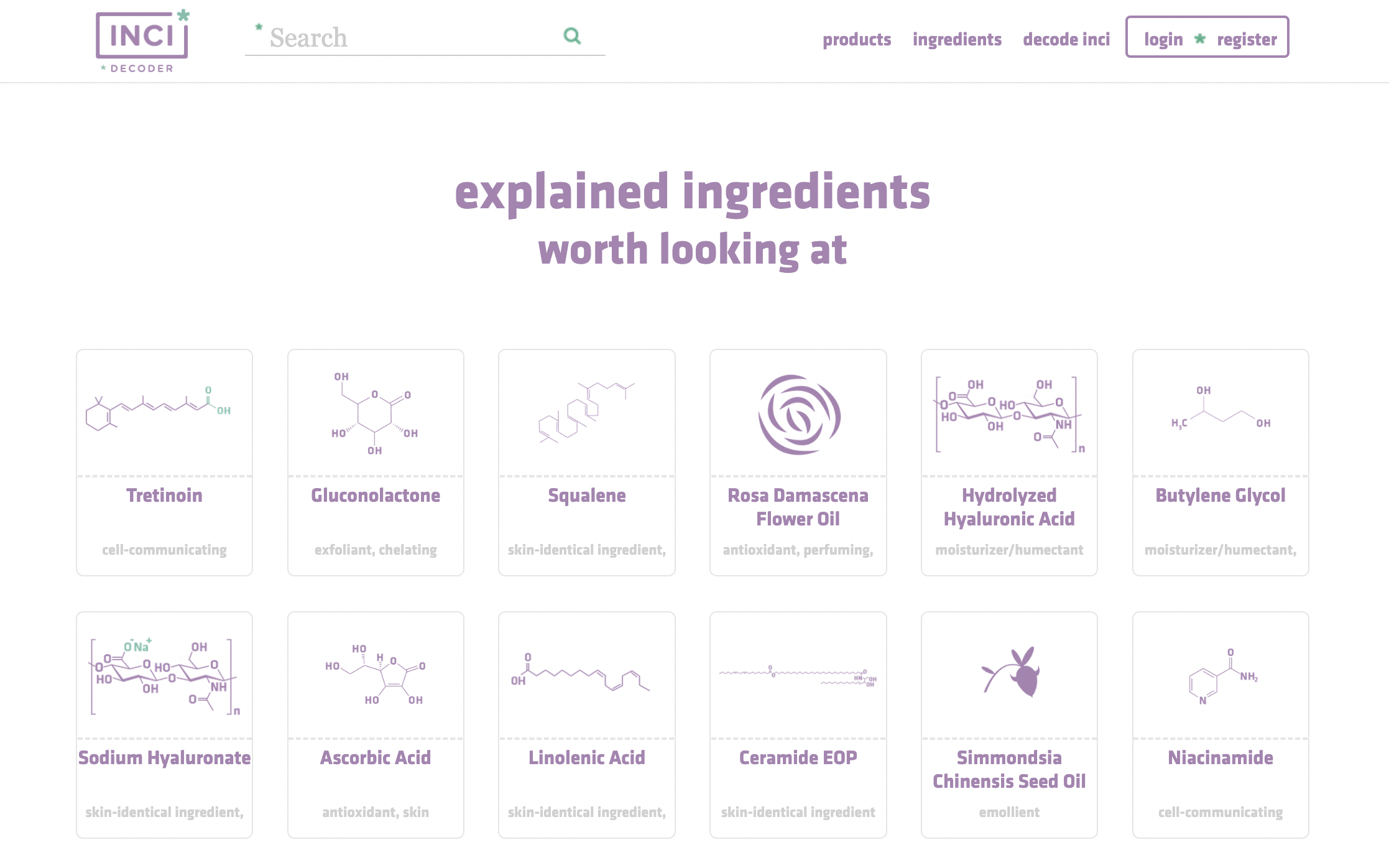

해당 성분이 들어간 Products(str type)를 제공한다.
📌 Products
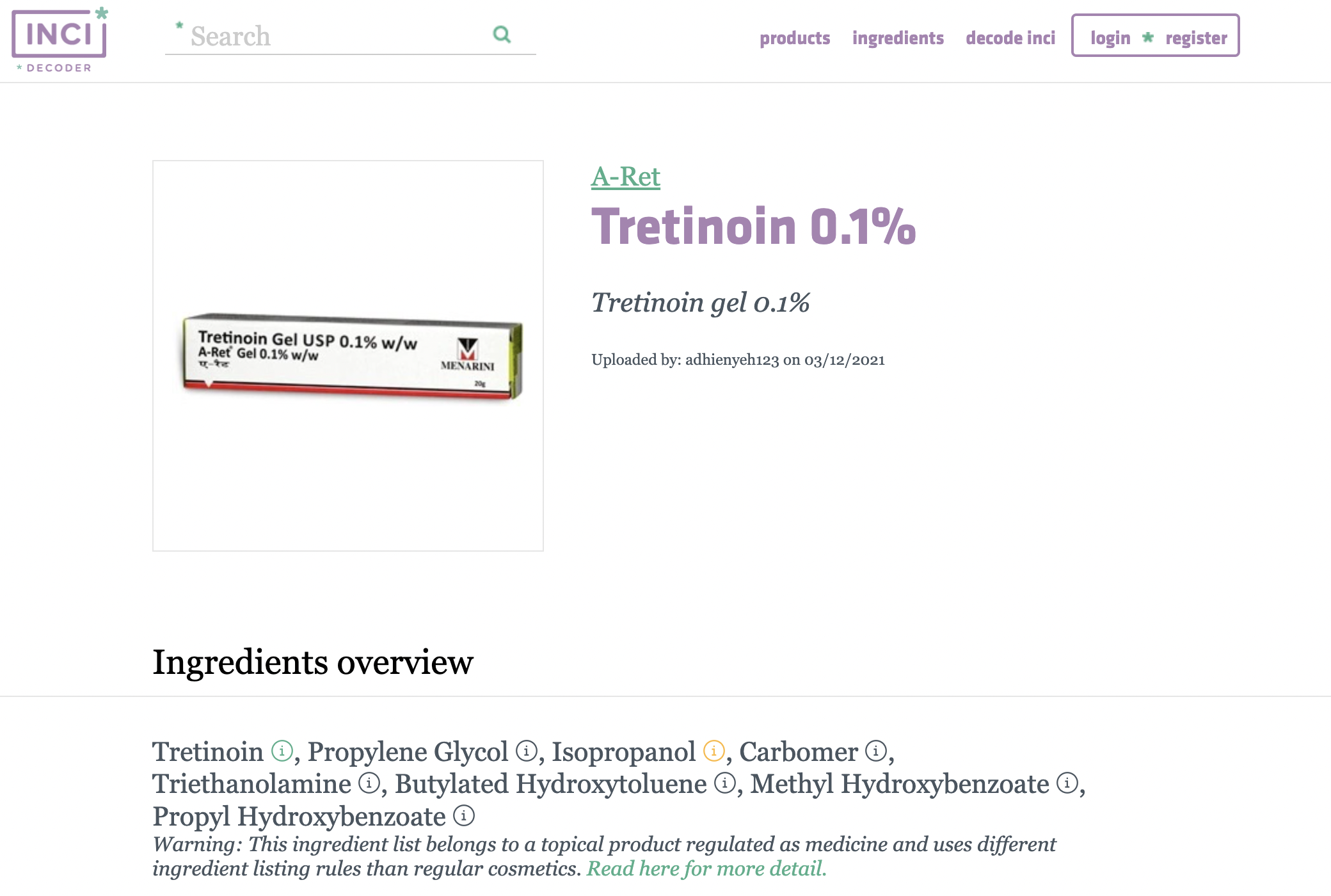
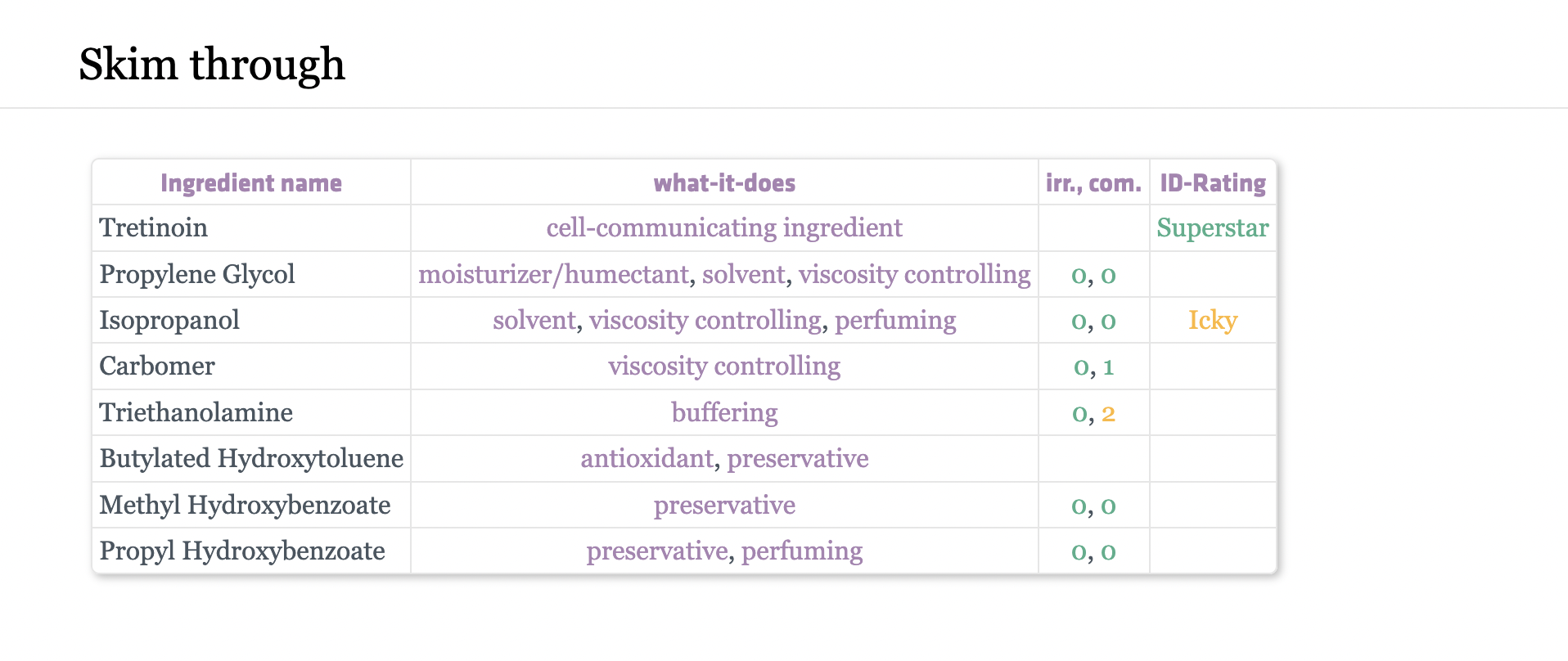
- 해당 제품에 어떤 성분이 있는지
- 각 성분이 어떤 효능을 가지고 있는지
table 형식으로 str타입의 데이터들을 제공한다.
전성분 데이터는 제품 내 비율이 높은 순서대로 성분이 나열된다.
다만, 1% 미만으로 존재하는 부수적 성분에 대해서는 이 규칙이 적용되지 않음
3. 모델
📌 [ 선정 기준 ]
각 화장품은 제품 내 성분의 함량에 따라 순서를 지니고 있음.
성분이 나열된 순서를 통해 화장품 간의 유사도를 측정할 수 있을 것이라 판단.
나열된 성분은 토큰화된 문장과 같으며, 이에 착안하여 자연어 처리 모델을 활용하기로 결정.
📍GPT:
- GPT(Generative Pre-trained Transformer)는 트랜스포머의 디코더 아키텍쳐를 활용한 일방향 언어모델.
- 이전 단어들이 주어졌을 때 다음 단어가 무엇인지 맞추는 과정에서 프리트레인(pretrain).
- 문장 시작부터 순차적으로 계산한다는 점에서 일방향(unidirectional).
📍 BERT:
- BERT(Bidirectional Encoder Representations from Transformers)는 트랜스포머의 인코더 아키텍쳐를 활용한 양방향 마스크 언어모델(Masked Language Model).
- 문장 중간에 빈칸을 만들고 해당 빈칸에 어떤 단어가 적절할지 맞추는 과정에서 프리트레인.
- 빈칸 앞뒤 문맥을 모두 살필 수 있다는 점에서 양방향(bidirectional).
이 때문에 GPT는 문장 생성에, BERT는 문장의 의미를 추출하는 데 강점을 지닌 것으로 알려져 있음.
모델을 프로젝트에 어떻게 활용할 것인지에 대한 구체적인 사항은 추후 추가할 예정.
