쉬운 내용이라 생각했었다.
하지만 저장소 패턴을 장고에 적용해보려고 생각하면 할수록 어려워졌다.
일단 시작점은 이렇다.
우리에겐 복잡한 도메인 모델이 있다.
도메인 모델의 영속화를 위해 외부 영역(인프라 환경)이 필요하다.
데이터베이스가 필요하다는 말이다.
그럼 이제 어떻게의 문제로 넘어간다.
어떻게 저수준의 데이터베이스 모델을
고수준의 도메인 모델에 의존시킬 수 있을지(DIP)에 대한 장이다.
⭐️ 내용 정리
1️⃣ 서론(p.59): 고수준 모듈인 비즈니스 로직(도메인 모델)과 DB 계층을 분리해라
2️⃣ 2.1절(p.60): 영속적인 저장소가 필요하다.
3️⃣ 2.2절(p.61): 앞으로 논의할 도메인 모델 영속화의 정의와 범위가 사람마다 다를 수 있다. MVP는 웹 API로 한정한다.
4️⃣ 2.3절(p.62): 양파 아키텍처를 지향하자.
양파 아키텍처
표현계층→비즈니스 로직 계층←DB 계층
3-tier 아키텍쳐에서 들어봤을 것이다.
기본적으로 표현계층, 비즈니스 로직 계층, DB계층으로 나눈다. 표현계층은 비즈니스 로직 계층에만 의존하고, 다시 비즈니스 로직 계층은 DB계층에만 의존하도록 하는 것이 정석이라고 생각해왔다.
하지만 도메인 모델은 어딘가에 의존되면 안 된다. 표현계층과 DB계층이 비즈니스 로직 계층을 의존하게 해야한다. 왜냐하면 비즈니스 로직 계층은 도메인 모델이 반영되어 있는 고수준 모듈이기 때문이다.
DIP가 지향하는 점은 명확하다.
고수준 모듈(도메인 모델)이 저수준 모듈을 의존해서는 안 된다.
즉, 표현 계층과 DB계층은 저수준 모델로써, 비즈니스 로직 계층의 추상화를 상속받아야 한다.
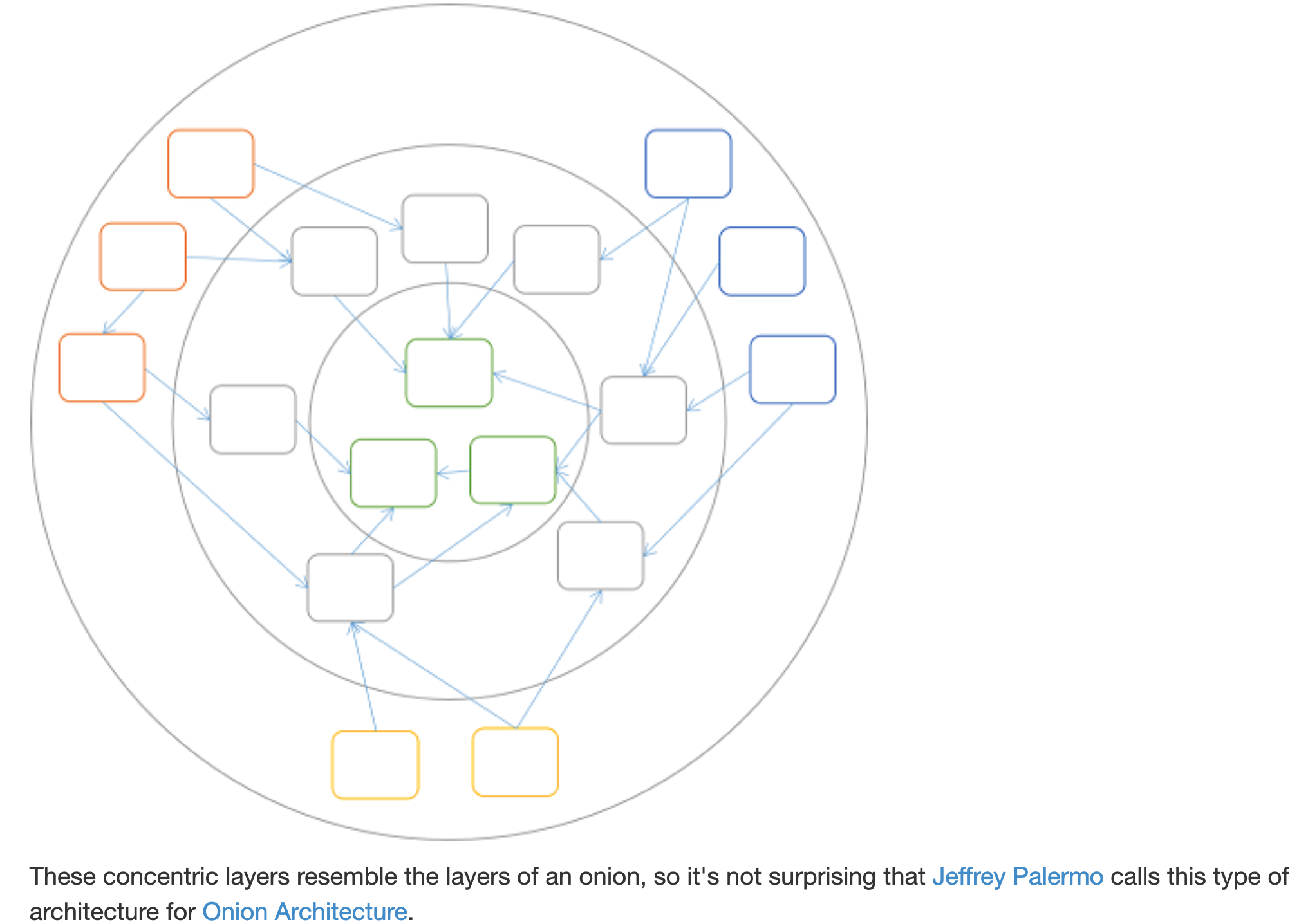
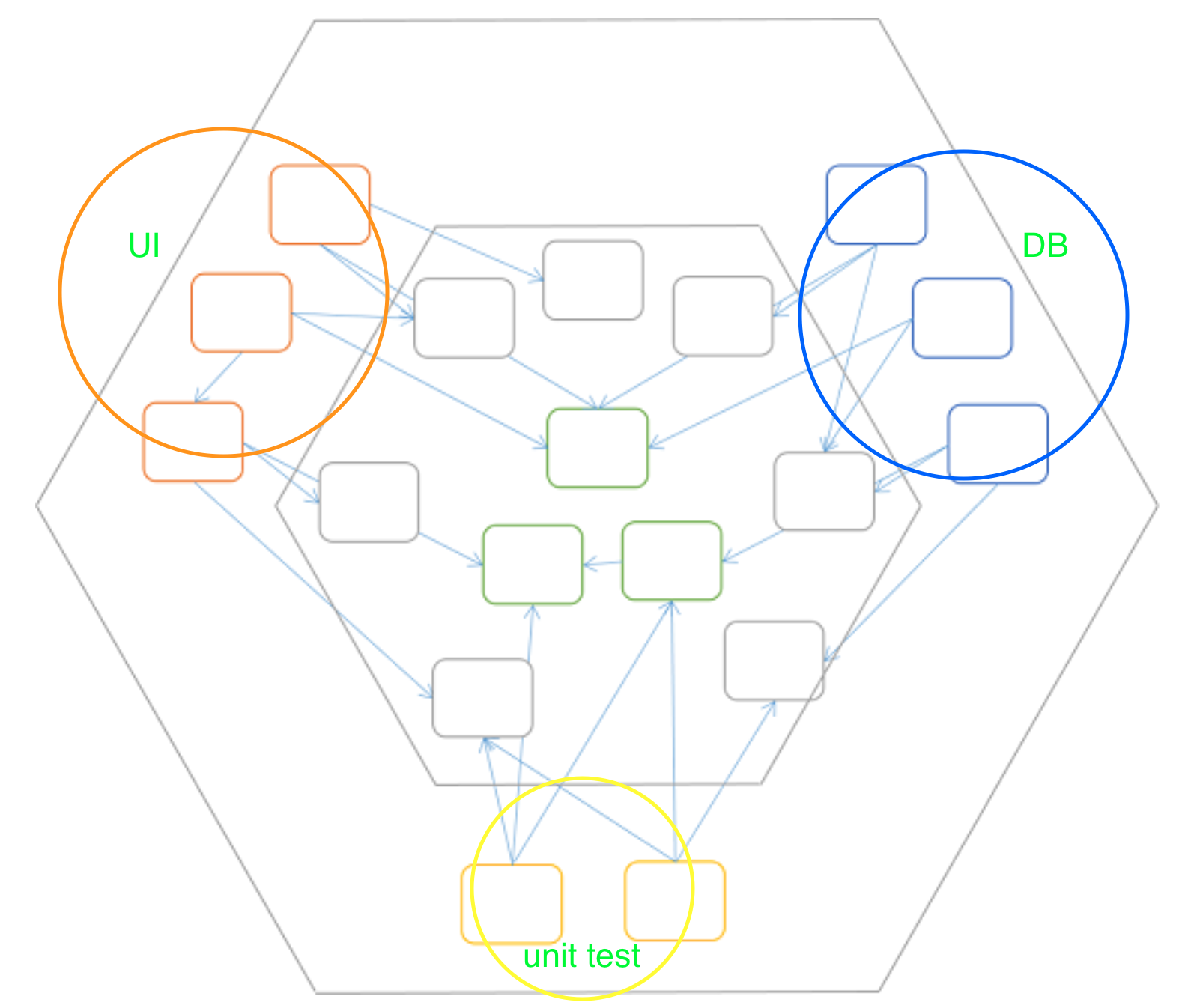
출처: https://blog.ploeh.dk/2013/12/03/layers-onions-ports-adapters-its-all-the-same/
5️⃣ 2.4절(p.65, p.334): 모델에 의존하는 ORM
장고는 고전적 매퍼를 지원하지 않는다.
즉, 개발자가 스키마를 정의하고, 스키마와 도메일 모델을 상호변환하는 매퍼를 또 구축하지는 않는다.
ORM에 대해서
ORM은 객체와 DB 사이의 관계를 이어주는 역할을 한다. 그런 면에서 ORM을 지원하는 웹 프레임워크를 사용한다는 것 자체가 이미 DB 추상화를 사용하고 있다는 반증이다.
예를 들어, MariaDB, MySQL, PostgreSQL 포함해서 우리가 어떤 DB를 택하든 도메인 모델이 직접 의존할 필요가 없다는 걸 이미 Django가 보여주고 있다. 또한, ORM을 통해 유저의 결제 내역이 DB에 저장될 때, 어떻게 MySQL에 저장되는지 알 필요가 없다. 위와 같은 ORM의 가장 중요한 특징을 영속성 무지(persistence ignorance)라고 한다.
👁 하지만 ORM만으론 DIP를 따른다고 말하기엔 부족한 면이 있다.
models.py에 하나의 모델만 보더라도 여러 필드에 대한 프로퍼티를 상세히 작성한다. 게다가 모델을 함부로 변경하기가 어려운데, 정말 DIP이 잘 적용됐다고 말할 수 있는가?
특히, 장고에 익숙한 나의 경우 평소 작성하는 모델이 ORM에 의존하고 있다는 말이 충격으로 다가왔다. 즉, 장고의 모델은 ORM 클래스를 직접 상속받는다.
ORM이 모델에 의존하는 구조였음 좋겠지만, 현실은 그렇지 못한 것이다.
이것은 장고의 Active Record 때문이다. 테이블의 한 row와 객체 하나는 동일하다. 그 객체가 데이터인 동시에 매니저를 통해 간단한 로직까지 수행할 수 있다.
6️⃣ 2.5절 저장소 패턴(장고 미해당)
아이디어는 이렇다.
모든 데이터가 메모리 상에 있다는 환상을 주는 것이다.
도메인 모델이 DB 데이터 접근과 같은 디테일한 사항을 알 필요가 없도록 하는 효과다.
장고 미해당이라고 언급한 이유는 장고의 모델 메소드 자체가 이미 데이터 접근이 알고 있기 때문이다.
import all_the_information_in_the_world
def create_a_batch():
"""인메모리 데이터 추가"""
batch = Batch(...)
all_the_information_in_the_world.batches.add(batch)
def update_a_batch(batch_id, new_quantity):
"""인메모리 데이터 변경 """
batch = all_the_information_in_the_world.batches.get(batch_id)
batch.change_initail_quantity(new_quantity)
마치 Redis 인메모리 시스템처럼 객체를 불러오고, 변경/저장한다.
위의 예시처럼 인터페이스를 add와 get으로만 강제함으로써,
도메인 모델과 데이터베이스 사이의 결합을 끊어버렸다.
⭐️ 장고에서 할 수 있는 것들에 대해서
❶ 장고는 DDD를 적용하기 어려운 프레임워크다?



시종일관 저장소 패턴이 어색하게 느껴지는 이유도 그래서다.
책에서는 레포지토리를 통해 '데이터'와 '데이터 접근'을 분리하려고 한다.(2.3절)
하지만 장고는 모델 매니저가(Product.objects.get, save() 등을 지원한다.)
즉, Active record로써, 테이블의 한 row가 데이터 그 자체이면서 기본적인 데이터 접근까지 지원하다. 그래서 장고를 사용하는 나에겐 이 둘을 분리하라는 내용이 매우 어색하고 심지어는 비효율적이라고 생각하게 한다.
야샬이 유튜브에서 "장고를 추천하지 않는 이유"라는 영상을 올렸는데, 혹시 이 부분 때문에 그런건 아닌가 하는 생각을 한다. 장고는 "웹" 프레임워크로써, 웹 환경에서의 도메인 모델 및 그 구현에 초점이 맞춰져야 하는데, DB와 너무나 tightly coupled 돼 있다.
이미 태생 자체가 DB와의 강한 결합인 녀석에게
그 둘을 분리하려는 시도를 하는 것 자체가 말이 안 된다고 느꼈다.
왜냐하면 그 부분이 마음에 들지 않으면 장고를 사용하지 않으면 된다.
DDD를 장고의 철학보다 우선시하려했다.
간단한 CRUD 기반의 비즈니스 모델이면서 빠른 서비스 배포가 중요하다면 장고는 좋은 선택지다. 하지만 처음부터 내 비즈니스가 복잡한지, 앞으로 복잡해질지에 대한 판단을 초반에 알기란 어렵다.
❸ 장고에서 DDD를 온전히 적용 불가는 OK, 그렇다면 실무에서 장고 기반 비즈니스 로직 분리 방법은??
- 전제:
1) DIP 위배: 모델이 ORM을 임포트(의존)
2) active record 방식: 데이터 모델, 데이터 접근 방식 분리 불가➩ 현 상황에서 내가 할 수 있는 것을 말해보자
1) 장고의 Fat Model
- 장고가 권장하는 방식은 뚱뚱한 모델, 날씬한 뷰다.
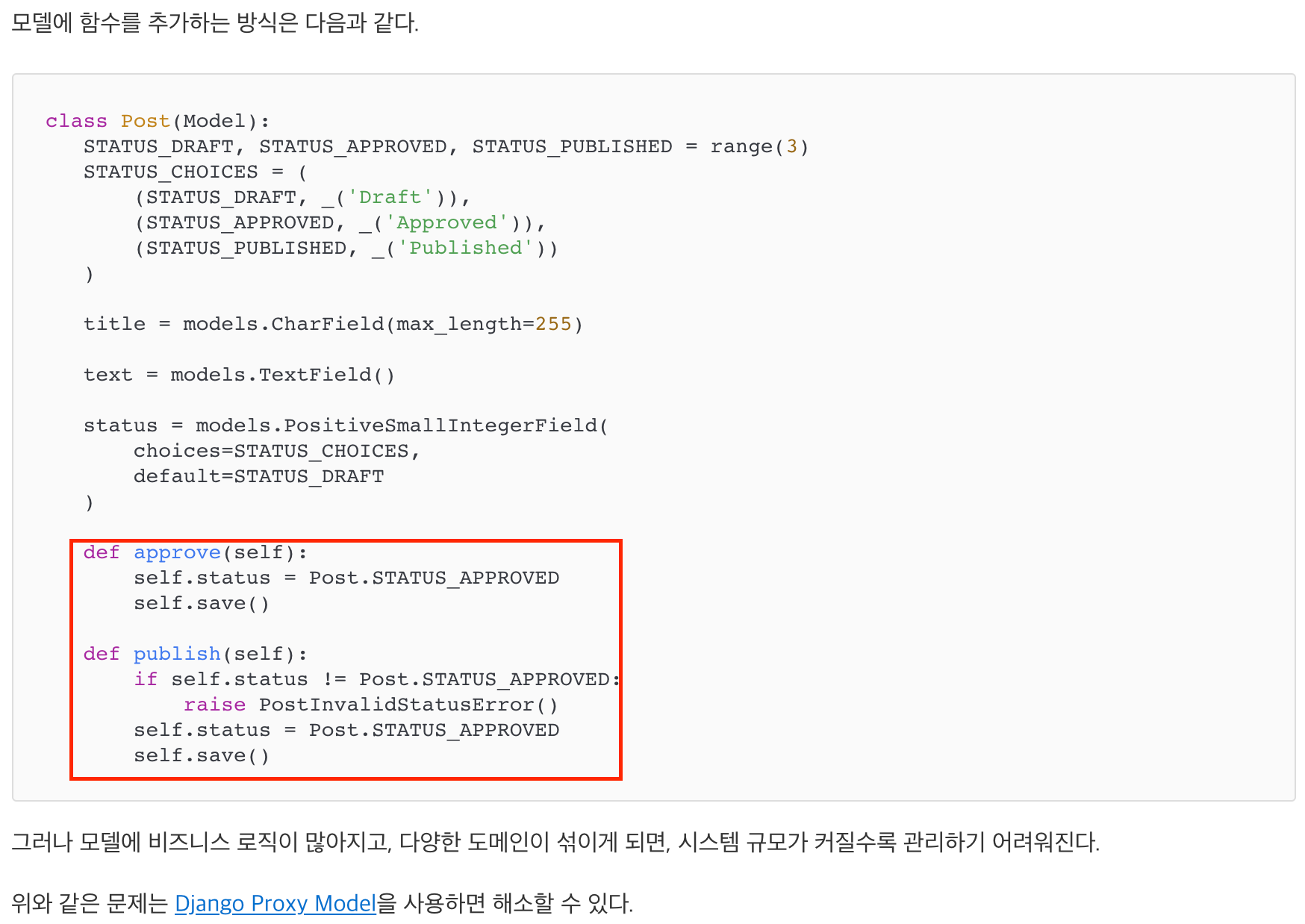
하지만 실무에서 모델 메소드가 점점 비대해지고 있는 상황이다.
가독성이 저하된다는 사실은 확실하다🥺.
특정 모델에 종속되는 모델 메소드만 1300줄이 된다.
class Example(models.Model):
name = models.CharField()
...
def a(self):
...
def b(self):
...
def c(self, status):
...
def d(self, date):
...
def e(self, price):
...
def f(self, category_id):
...
def g(self):
...
def h(self):
...
def i(self):
...
def j(self):
...
def k(self, place):
...
def l(self, time):
...
def m(self):
...
def n(self):
...
def o(self):
...
def p(self):
... 위와 같은 패턴의 모델이 수십 개 된다고 생각해보자.
장고의 Fat model은 경도비만 수준에서의 이야기 아닐까?
초고도 비만의 모델이 야기하는 문제에 대해서는 왜 언급이 없을까.
또한, 비즈니스 모델이 복잡해질수록 모델 메소드에 여러 모델들이 임포트(의존)돼야 한다. 데이터 모델 바로 하단에 수많은 모델 메소드가 있고, 각 모델 메소드는 다른 데이터 모델들을 임포트하게 되어 우리의 models.py는 스파게티처럼 될 것이다.
2) ProxyModel
장고 공식 문서,
" Sometimes, however, you only want to change the Python behavior of a model
– perhaps to change the default manager, or add a new method."
데이터 모델은 변함이 없지만, 특정 API에서만 사용될 비즈니스 로직을 추가하고 싶거나 ordering 순서를 다르게하고 싶을 때 등이다.
품절된 상품,
직접 계약을 맺은 업체의 상품,
현장 구매 가능한 상품들,
마감 임박 상품들,
(배너 클릭시) 정렬 순서가 기존과는 상이하도록 한 상품들,
정오 이전의 제품들,
정오 이후의 제품들,
얼리버드 제품들 등
이처럼 하나의 Product 데이터 모델에도 비즈니스 복잡도에 따라 다양한 필터가 적용된 쿼리셋이 필요하다.
# serializers.py
queryset = Product.objects.filter(...).prefetch_related(...).select_related(...) 그때마다 위처럼 매번 필터 조건을 다르게 가져가는게 아니라
아래의 proxy 모델을 정의내리고 그 정의를 serializer에서도 사용하는 것이다.
class SoldoutProductManager(models.Manager):
def get_queryset(self):
query_set = super(SoldoutProductManager, self).get_queryset()
return query_set.filter(is_soldout=True)
# 품절 상품
class SoldoutProduct(Product):
objects = SoldoutProductManager()
class Meta:
proxy = True
# 마감 임박 상품
class IsHurryProductManager(models.Manager):
def get_queryset(self):
query_set = super(IsHurryProductManager, self).get_queryset()
return query_set.filter(is_hurry=True)
class IsHurryProduct(Product):
objects = IsHurryProductManager()
class Meta:
proxy = True하지만 이 부분 역시 Super Fat Model의 문제점이 있다.
실제로 가독성 측면에서 절실히 느끼고 있다.
좋은 대안이 아님을 정말 확신한다
3) 장고의 service.py or logic.py
그나마 이 방식이 좋다고 생각하는 이유는 코드의 물리적 분리 때문이다.
models.py에 데이터 부분과 비즈니스 로직 부분이 공존한다는 것은
서로 다른 두 속성이 같이 섞여 있는 구조이며, 각각의 영역이 비대해질수록
가독성이 떨어지고 관리도 어려워진다고 판단했다.
IDE에서 models.py를 보고 있을 땐, 데이터 모델을 보고 있다는 것이 명확하고,
관련 비즈니스 로직은 Product앱 내의 service.py에 있다는 그 인식의 경계가 명확해진다.
적어도 가독성 측면에서는 이점이 있다. 왜냐하면 데이터 모델은 간단히 유지될 수 있기 때문이다. 둘 다 비대해질 바에는, 한 곳만 비대해지게 하자 라는 관점이랄까.
# logic.py
from .models import User
def activate_user(user_id):
user = User.objects.get(pk=user_id)
# set active flag
user.active = True
user.save()
# mail user
send_mail(...)