'Daum'의 검색어를 가져와 보자.
① Beautiful Soup는 HTML과 XML파일들에서 원하는 데이터를 추출하게 도와주는
파이썬 전용 라이브러리다. → from bs4 import BeautifulSoup 로
패키지를 import시킨다.
(처음에 다운로드를 받기 위해 pip install bs4를 진행해준다.)
② urllib.request는 URL(Uniform Resource Locator)을 가져오기 위한 파이썬 모듈이다. 그 모듈 내 urlopen 메소드를 사용하기 위해
from urllib.request import urlopen 코드를 작성한다.
③ response = urlopen('https://www.daum.net/')
response 변수에 urlopen 메소드의 매개변수로 '다음 홈페이지'를
넣어준다.
■ 파이썬 syntax를 활용하여
with urlopen('https://www.daum.net/') as response: 로 작성해도 된다.④ soup = BeautifulSoup(response, 'html.parser')
⑤ for anchor in soup.select('a.link_favorsch'):
print(anchor.get_text()) 를 통해 검색어가 나오는
html 태그 및 클래스를 추출해 낸다.
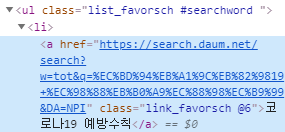
검색어마다 공통적으로 a라는 태그 클래스가 "link_favorsch"가 있음을
알 수 있다. 이는 홈페이지에서 'F12'(개발자 도구)를 눌러서
확인할 수 있다.⑥ 아래와 같이 코드를 작성하여 Run했을시,
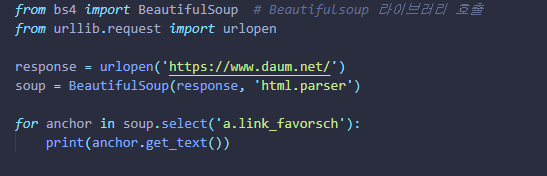

cmd 창에 '검색어'데이터만 추출됨을 확인할 수 있다.
⑦ 검색어 앞에 1. 2.등과 같이 순위가 출력되게 수정하고 포스트를 마무리 하려고 한다.
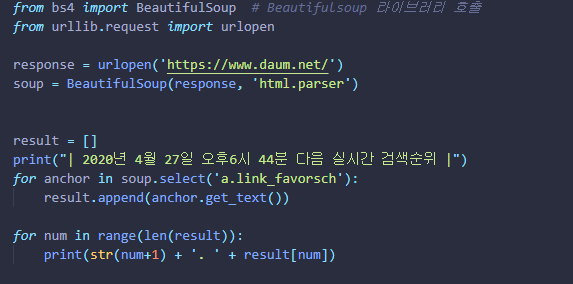

이중 for문(nested loop)로 구현할 수도 있으나,
최근에 youtube 영상을 보며 '빅오'에 대한 개념을 들은 적이 있어서
단일 for문으로 작성했다.
리스트 내 데이터가 증가할 수록 이중for문의 경우 지수함수의 그래프로처럼
run 소요시간이 길어진다고 한다.
단일 for문의 경무(y=ax)
이 부분이 굉장히 흥미로웠었는데, 좀 더 공부해 볼만한 주제라고 생각한다.
- One step at a time -