ACL2022 - MDRG 리뷰(multimodal Dialogue Response Generation)
사전지식
1. Clip
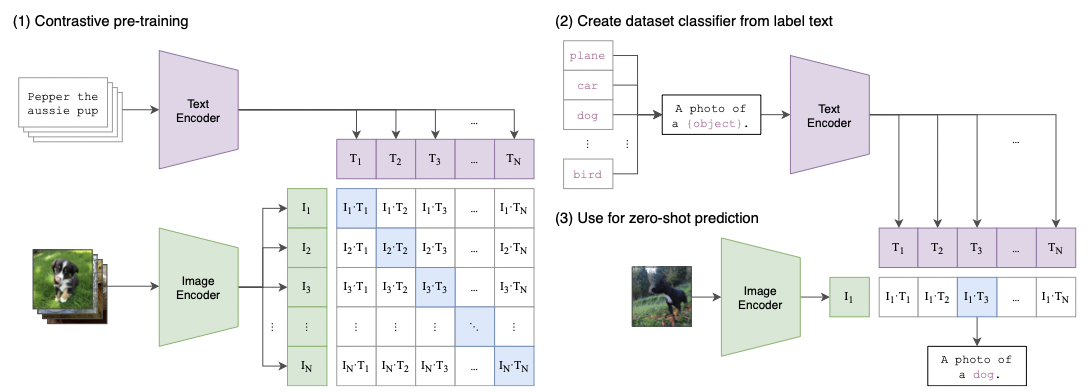
- text와 이미지의 임베딩 벡터를 구해서 매핑되는 것의 확률을 높이는 방식으로 학습 -> 일종의 추천시스템 user-item 느낌이라고 생각해도 무방할 듯 하다.
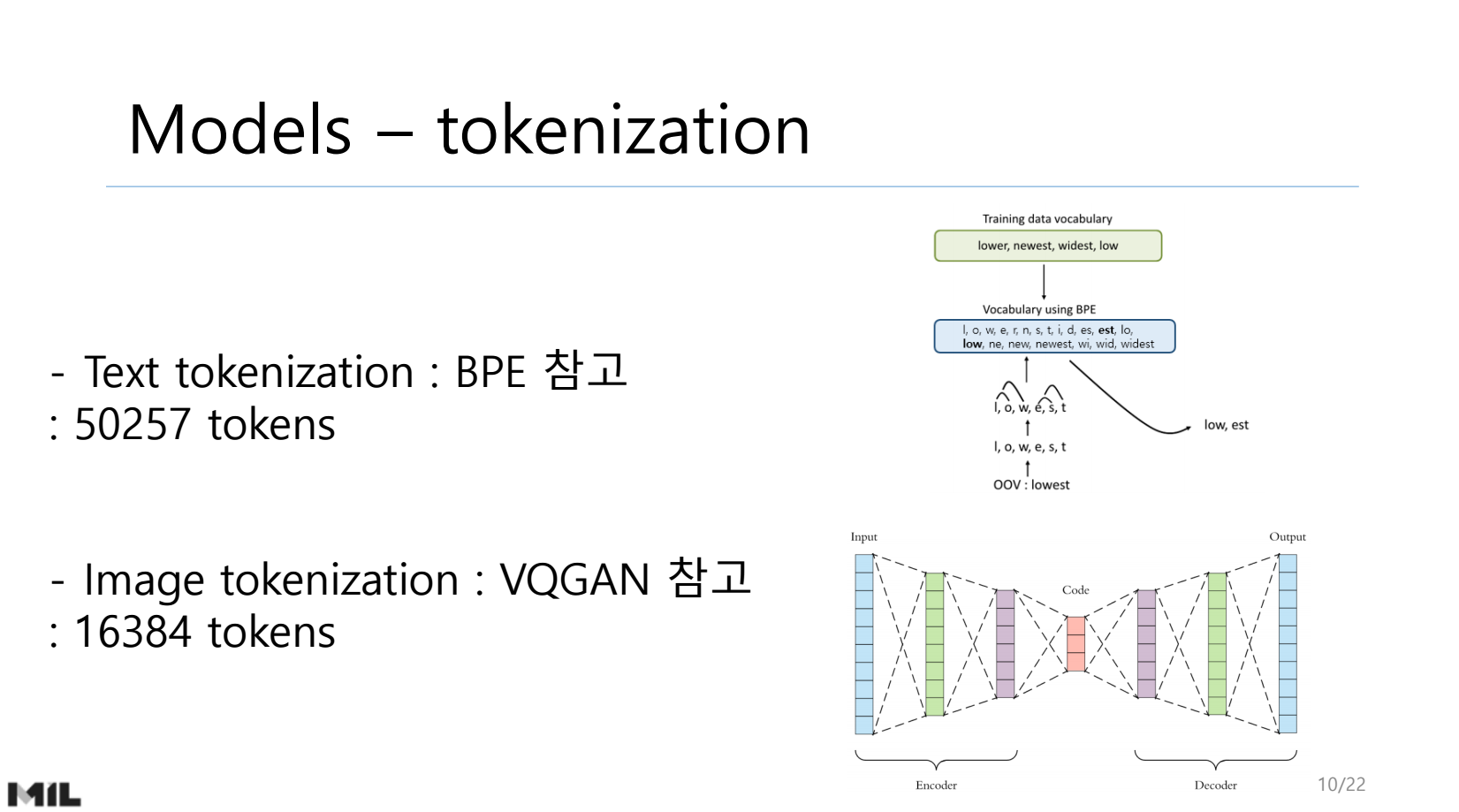
2. VQGAN
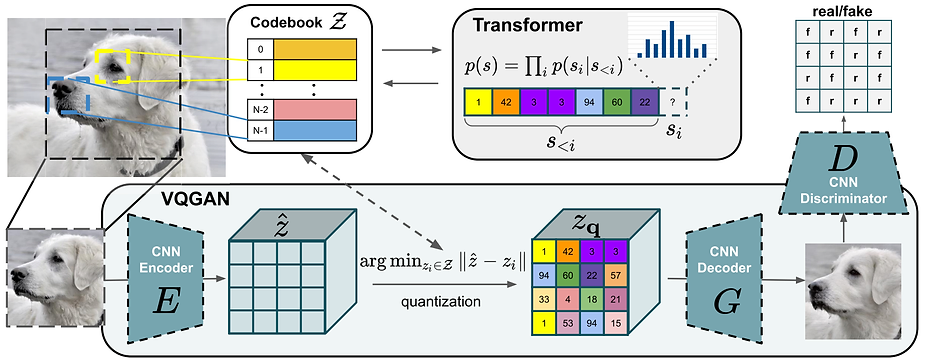
: 과정
- 이미지를 인코더에 넣는다.
- 연속적인 벡터를 이산화된 벡터로 만든다
- 이산화된 벡터끼리 attention을 적용한다.
- 디코더로 복원한다.
- 실제 이미지에서 온 것은 실제 이미지로, 가짜 이미지에서 온 것은 가짜 이미지로 판별한다.
: loss
- reconstruction loss(복원한 것이 원본과 같아야 한다.)
- discriminator loss(판별을 정확하게 해야 한다.)
- transformer loss(attention 부분에서 이미지 autoregressive하게 학습해서 관계를 잘 학습한다.)
- perceptual loss(코드북 잘 만들고, 다양하게 매핑하도록 한다.)
3. DALLE(정확힌 2)
- CLIP모델을 이용하여 이미지 벡터를 생성한다.
- 위의 이미지 벡터를 디퓨전 모델에 집어 넣어서 이미지를 생성한다.
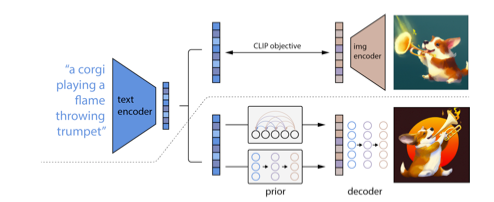
- prior부분의 위쪽은 autoregressive 하게 VQGAN 사용해서 토큰 방식
- prior부분의 아래쪽은 디퓨전모델 방식으로 노이즈 추가-제거 복원 방식
MDRG start





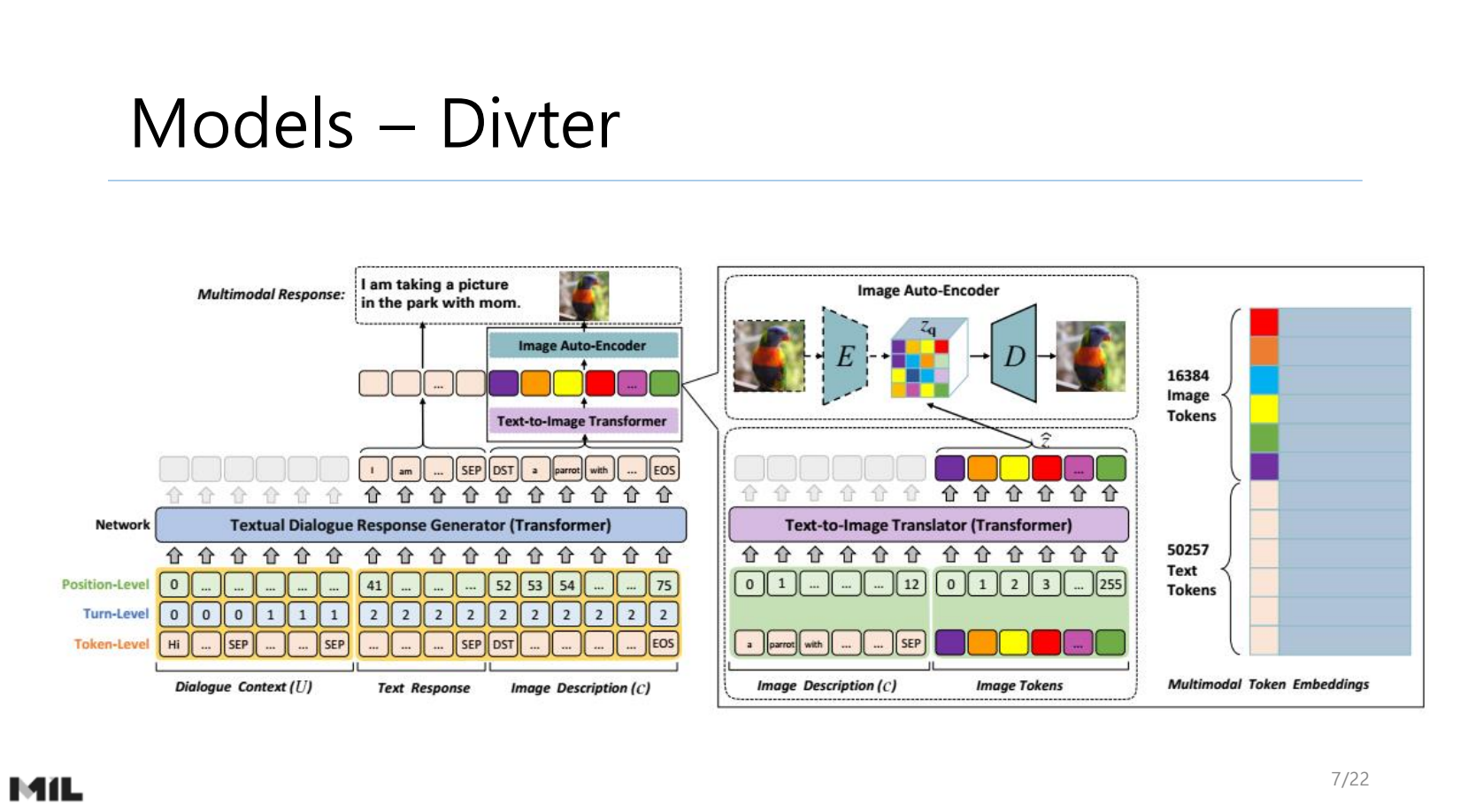

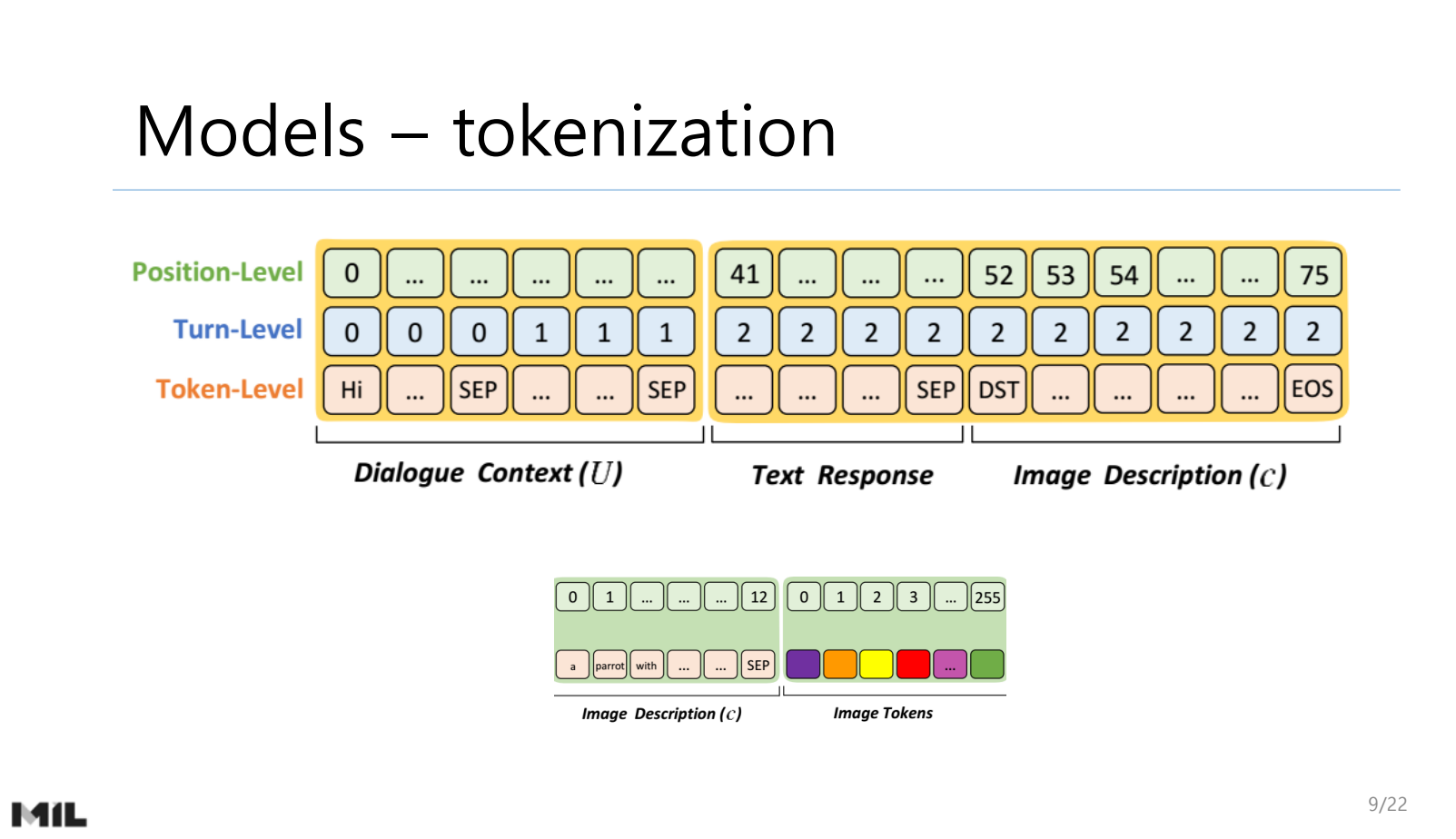
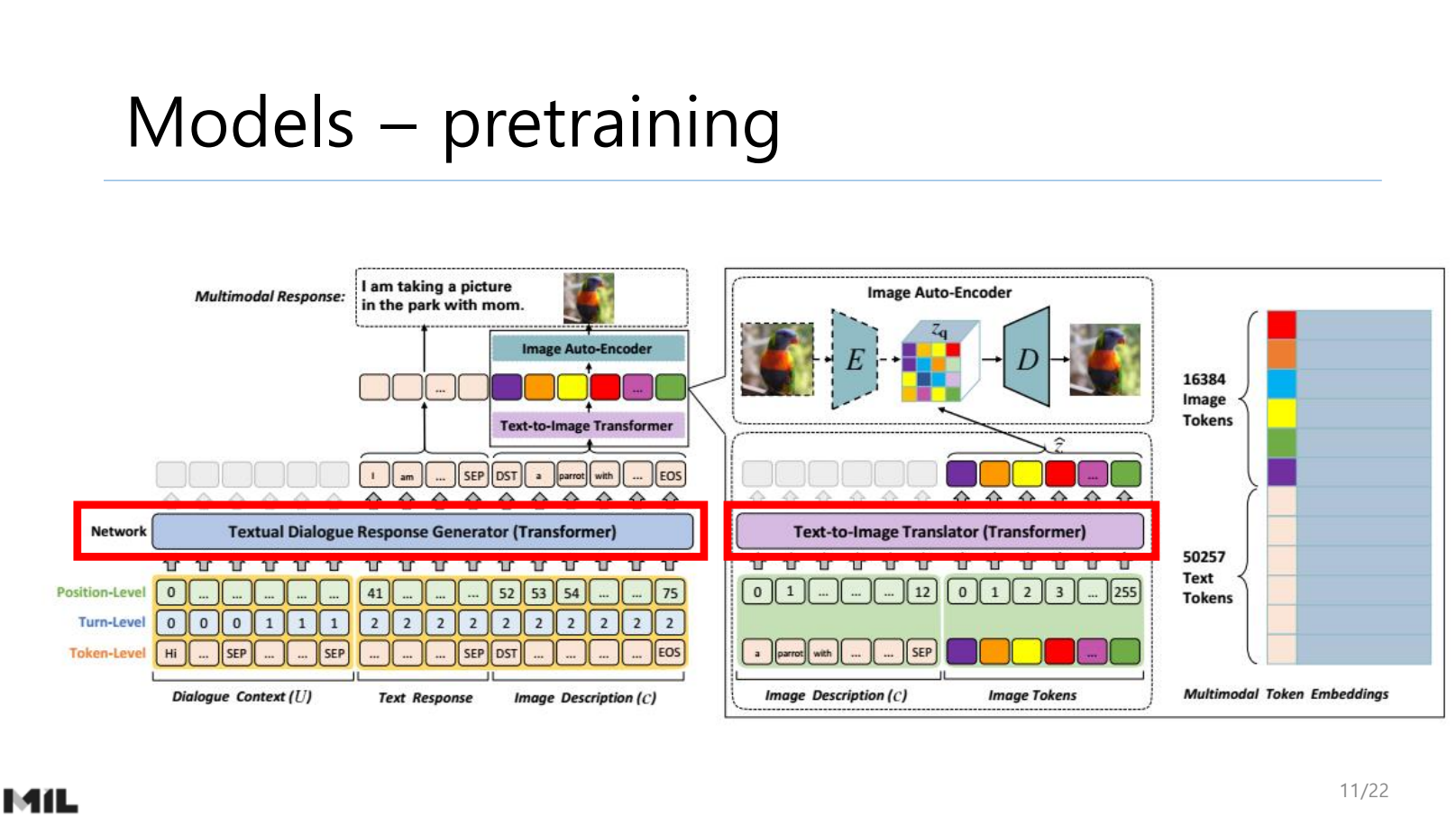
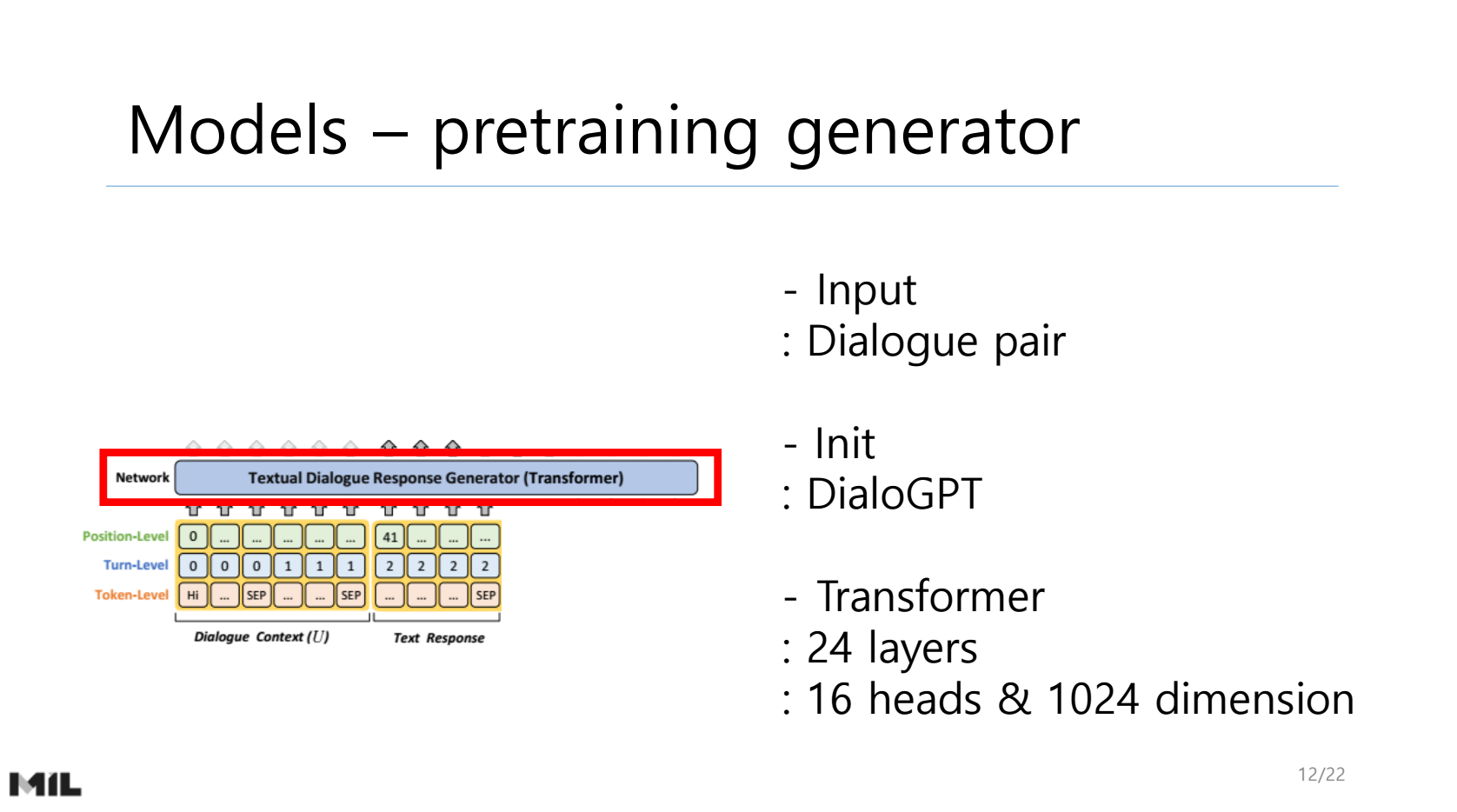
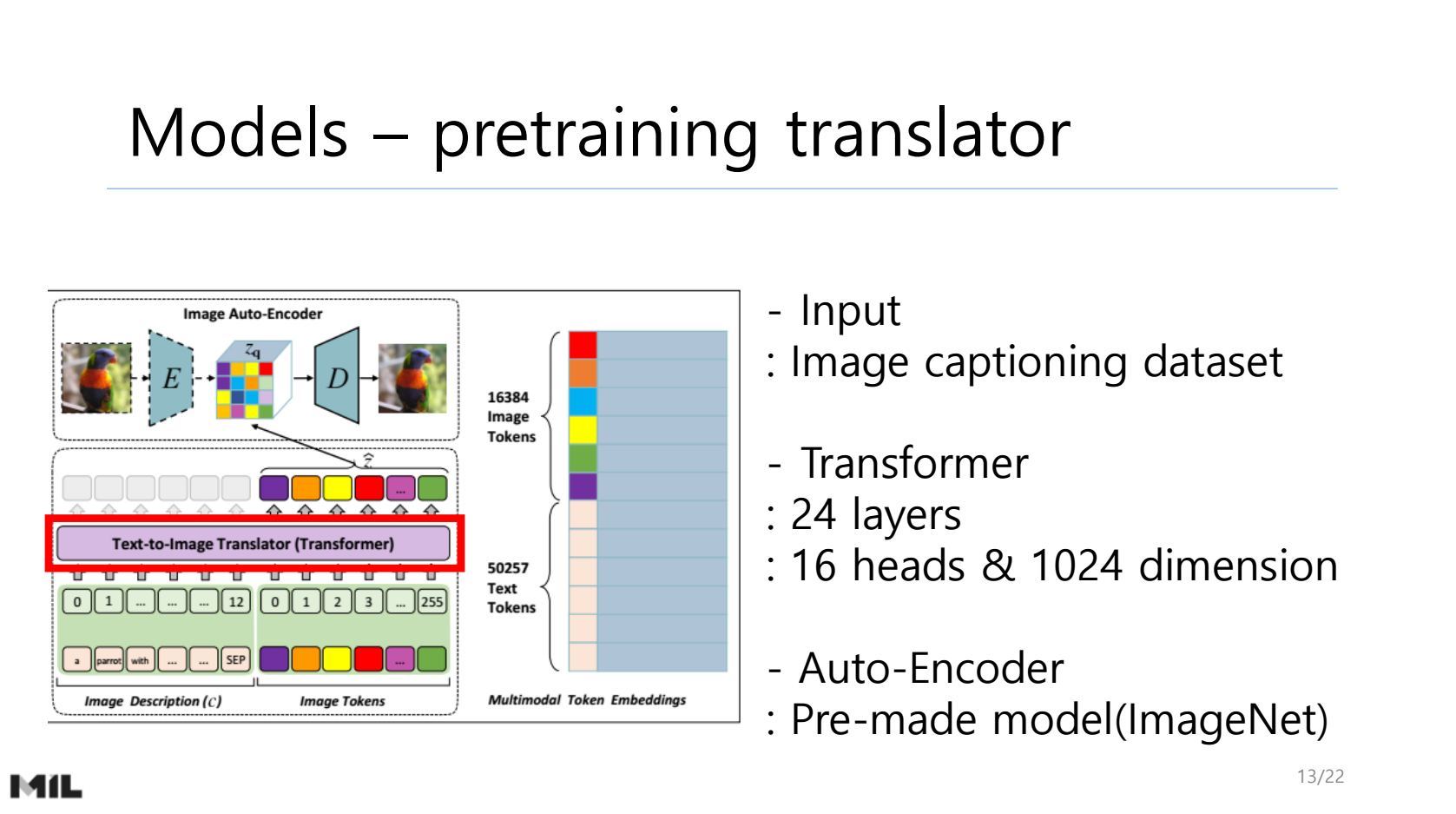
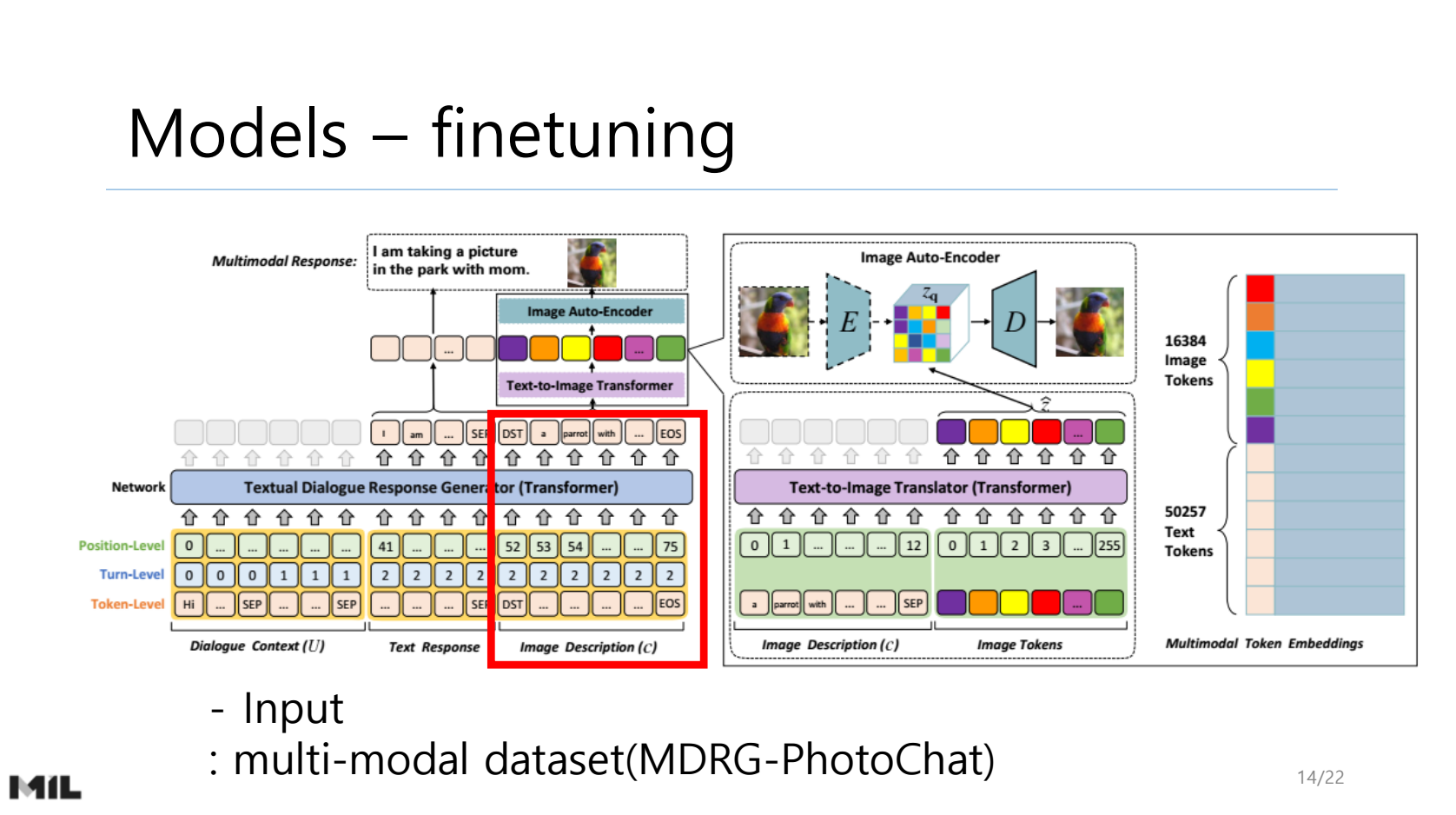


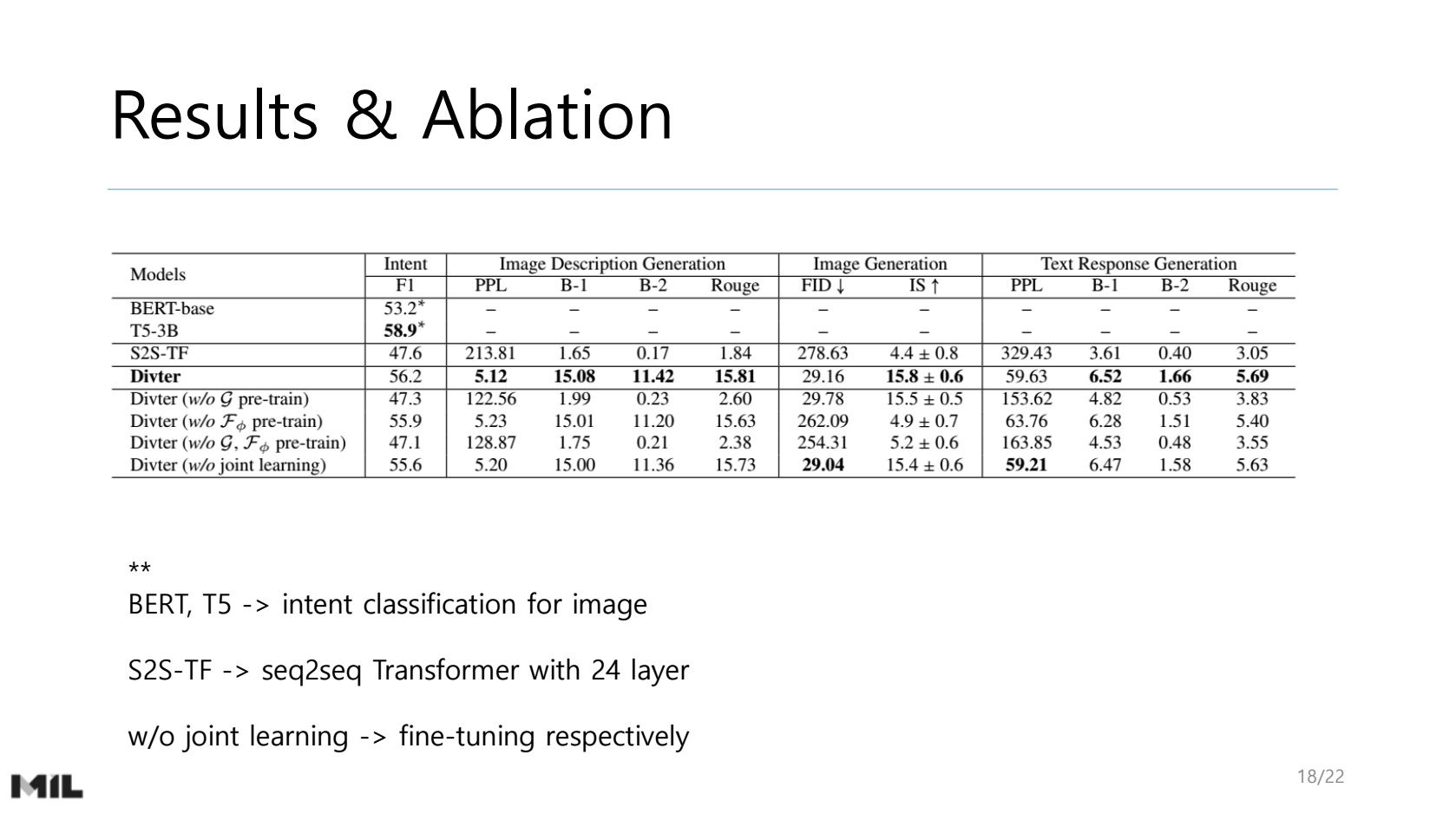



NLP Researcher : https://hyukhunkoh-ai.github.io/