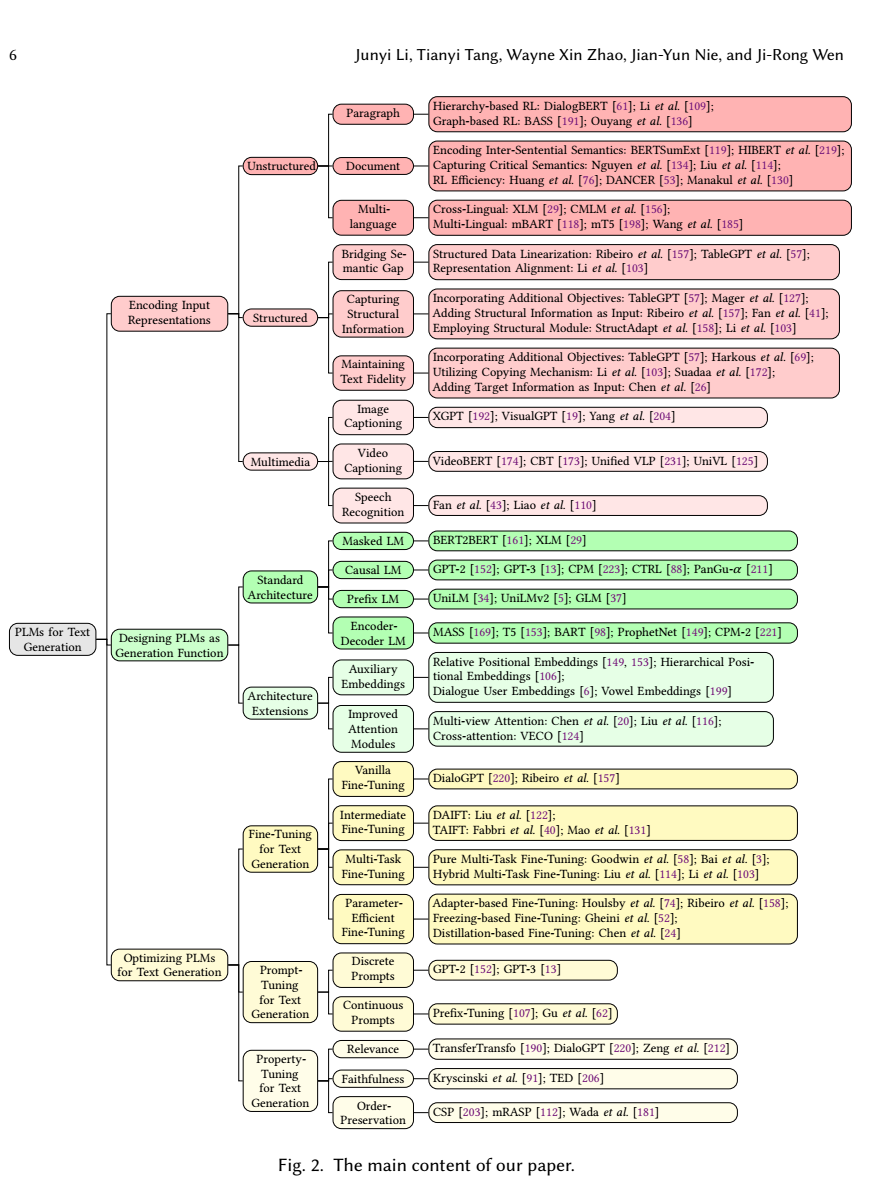
이 페이퍼는 text-generation에 관한 내용을 pretrained-language model 중심으로 다룬 내용 - 여러가지 연구 흐름을 파악하기 용이함
필자의 기존 지식과 논문의 내용을 기반해서 요약을 해봄
0. Abstract
서두
1. 텍스트 생성이란 데이터로부터 자연스러운 말을 생성해내는 것
2. 이 페이퍼에서는 PLM과 관련된 소식들을 다룰 것이며, 3가지 포인트를 짚을 것이다.
- input data들을 어떻게 인코딩해서 의미를 간직하도록 만들 것인가
- 어떻게 텍스트 생성 모델을 디자인할 것인가
- 어떻게 특정 텍스트 조건을 충족하는 최적화 방법은 무엇이 있는가
3. 그리고 마지막으로 각종 어려움과 앞으로의 텍스트 생성의 발전 방향을 다루고 결론으로 마무리 지을 것이다.
1. introduction
인트로
- 텍스트 생성과 관련된 연구에는 대화 시스템, 기계 번역, 텍스트 요약이 대표적이다.
이것의 핵심 목표는 input-output 함수를 학습하는 것이다.- 보통 딥러닝의 seq-seq 프레임워크를 사용하고, encoder-decoder 구조라고 많이 불린다. encoder에서 텍스트를 가공하는 부분을 input embeddings이라고 부르고 그것에 기반해 decoder에서 텍스트를 생성한다. 이러한 구조에 사용하는 dnn은 RNN기반과 GNN기반이 있다. 이러한 기법은 end-to-end 학습으로 가져갈 수 있어 성능이 잘 나올 수 있고, 좀 더 작은 차원에서 semantic 정보를 캐치하여 언어적 특성을 배운다.
- 현대에는 Pretrained language model을 많이 쓰고, pretrain-finetune 구조를 채택하고 있다. Transformer 기반을 사용하고, encoder 기반 BERT나 decoder 기반 GPT가 있다. 이것은 전체적인 관점에서는 transfer-learning이며 pretrain 방법에서는 self-supervised로 볼 수 있으며, 대규모 corpus에서 학습을 통해 자연어를 좀 더 잘이해하고 인간의 언어를 유창하게 표현할 수 있도록 돕는다.
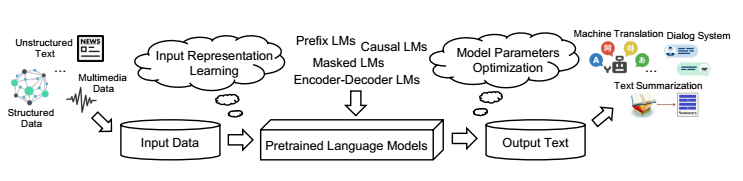
2. preliminary(outline)
2.1 텍스트 생성
: input x(text,image,table,knowledge bases) to output y
: PLM을 기반으로 생성 함수를 만든다.
텍스트 생성의 종류들(5 가지)
- x가 주어지지 않거나 랜덤 벡터일 때(GAN이란 유사한 듯)
: unconditional text generation이라고 부르고, 유창함과 자연적인 것을 만들 때 사용한다. - x가 discrete한 것일 때(뉴스 토픽이나, 감정일 때)
: attribute-based generation이라고 부름, 이 때 x는 생성 controlling factor라고 부른다. - x가 structured 데이터 일 때(knowledge base나 table 데이터)
: data-to-text generation이라고 부르며, 보통 data를 설명하는 텍스트를 생성하는 task에 많이 사용한다. - x가 multimedia input일 때(음성, 이미지)
: image caption이나 speech recognition이 대표적이다. - x가 text-sequence일 때(그냥 단순히 text라고 생각하면 됨)
: 기계 번역이나, 텍스트 요약, 대화 시스템이 대표적이다.
2.2 PLM
: 먼저 대규모의 라벨없는 corpus를 이용해 사전학습하고, 실제 task에 맞춰 fine-tuning하는 방법의 요소
- Transformer
- encoder based : BERT -> XLNET -> RoBERTa -> ERNIE- decoder based : GPT - 1 - 2 - 3, PANGU, GSared, Switch-Transformer
- encoder-decoder based : T5 - BART
- PLM 종류
- masked language model- causal language model
- prefix language model
- encoder-decoder language model
2.3 text generation에 PLM 적용하는 방법
- input data : 효과적인 representation(일종의 잠재 공간이라고 생각하면 됨)을 개발해서 언어적 의미를 갖고 있도록 만들어야 함
- model architecture : 어떠한 모델 구조를 가져갈 것인가를 고민하고, denoised autoencoder와 autoregressive decoder 등을 보통 사용하고 현재는 더 다양한 구조를 고안해서 적용함
- optimiation 알고리즘 : 어떻게 생성함수를 최적화 할 것인가?
3. encoding input representations
encoding하는 3가지 타입
- unstructered input
- structured input
- multimedia input
3.1 unstructured
: 단순 문장,문단,문서와 같은 텍스트를 이용해 모델링하는 방법이다. input information을 정확하게 이해하고 유의미한 text representation을 만드는 것을 필요로 한다.
-
paragraph representation learning : hierarchy-based, graph-based가 있음. 여러 개의 문장들로 구성된 문단의 representation을 배우는 방법
- hierarch-based
: 담화와 같은 텍스트를 input으로 받는 DialogBERT가 있다. 이는 처음에 담화의 나타난 발화를 인코딩하고, 그 뒤 전반적인 담화의 측면에서의 문맥도 고려해서 최종적인 representation을 만든다. 하지만 이러한 방법은 history정보가 없기 때문에, 이를 개선하기 위해 맨 처음에 모든 담화 텍스트를 한 번에 dense representation으로 바꾸고 그것을 바탕으로 각각의 부분 담화를 repsentation으로 바꾸는 방식을 고안해 냈다.
- graph-based
: 긴 문단에서는 반복적이고 대조되는 정보들이 포함되어 있다. 이를 모델링하기 위해 문장들을 관련 있는 것들끼리 해체해서 점과 선으로 연결짓는 형태를 사용한다. 대표적인 예로는 phrase-relation graph가 있고, 이러한 모델은 정보 요약에 굉장히 많은 도움을 준다. 또다른 예로는 conversational machine reading이 있는데, input text를 두 가지 보조 그래프로 나누는 방법이다. explicit graph와 implicit graph로 나누는데, 이를 통해 담화 유닛 구성요소 간의 복잡한 상호작용들을 캐치하도록 한다. -
Document Representation learning : 여러 문단들로 구성된 문서일 경우 사용.
- encoding inter-sentential semantics
: MLM기법은 token-level의 의미를 파악하게 할 뿐 문장 간의 의미를 파악하는 것이 아니다. 이러한 문장 간의 의미를 파악하기 위해 제안된 방법은 document encoding을 hierarchical한 방법으로 문장들을 인코딩하는 것이다. 그래서 sentence 자체의 단어 인코더와 document를 이용한 sentence 인코더를 두 개 활용한다.
- Capturing Critical Semantics
: 이 방법은 document 전체적인 핵심 정보를 파악해서 그것을 텍스트 생성시 반영하게 하기위한 방법이다. 그래서 pretrained 학습에서 topic-aware contrastive learning을 사용해서 document 전체 주제를 캡쳐하고, 중요한 사실을 요약하게 한다.
- Representation Learning Efficiency
: self-attention은 길이에 따라 제곱수로 파라미터가 늘어나므로, 효율성 제고가 필요하다. 해결방법으로 local self-attention 방법과 explicit content selection 방법이 존재한다. 또한 처음 input에 넣을 때 긴 문서를 쪼개서 넣는 방법이 존재한다. -
multi-language representation learning : 보통 pretrained할 때, 단일 영어 corpus로 학습을 하기 때문에 기계 번역과 같은 task에 적용하기 쉽지 않다.
- Cross-lingual representations
: 이 방법은 두 개의 언어를 이용해 cross-lingual representation을 구성하는 방법이다. XLM이 대표적이지만 representation 공간이 불분명하고 한계점이 존재한다. 따라서 inexplicit한 representation을 explicit하게 만들기 위해 1. cross-lingual n-gram embeddings을 구성하고, 2. n-gram traslation table을 추론하도록 한다.
- multi-lingual representations
: 나라별 언어 corpus를 돌아가면서 한 번씩 pretrain하는 방법이다. mBart와 mT5가 있다. 언어 별 서로 다른 특징이 있는 점을 고려해서, contrastive loss objective를 사용한다. 대표적으로 2가지가 있는데, contrastive sentence ranking(CSR)과 sentence aligned substitution(SAS)가 있다. CSR 방법은 문서에서 문장들을 sampling하여 중요도에 따라 정답과 오답셋을 만든 다음, 무엇이 더 중요한 지 판단하도록 학습하도록 하여, 언어마다 중요한 정보를 구분하도록 만들어 언어 별 차이점을 고려하게 한다.(??????? 설명이 저세상이네... 좀 더 찾아봐야 겠네요)
3.2 structured input
: table, graph, tree와 같은 것을 이용해서 텍스트 생성하는 방법이다. 대표적으로 의료보고서나 기상보고서가 있다. 비구조 text input과 다른 점은 세 가지 있다. 첫 번째로, 의미적인 차이가 자연어랑 구조적인 보고서 사이에 존재한다. 두 번째로, 구조적 정보를 담는 것이 중요하다. 세 번째로, 텍스트 생성할 때 구조적인 언어 내용에 맞게 텍스트를 잘 생성하여야 한다.(text fidelity)
-
Bridging the semantic gap : PLMs은 비구조적 언어로 학습하기에, 이러한 것을 구조적 언어로 연결해줘야 한다.
- structured data linearization
: 단순히 input dada를 input sequence로 선형 변환한다. knowledge graph(KG)를 triple sequence로 변형하는 방법과 사람이 템플릿에 맞게 input data를 바꾸는 방법이 있다.
- representation alignment
: 위처럼 직접적으로 넣어주는 방법과 달리, input data를 embedding으로 변환 후 그것을 모델에 넣어주는 방법이다. 먼저 KG의 요소들 embedding으로 바꾸고, 그것을 PLM의 entity embedding에 맞추는 것이다. -
capturing structural information : 비구조적 언어와 달리, <entity,relation,entity> triple과 같은 구조를 파악해야 한다.
- incorporating additional training objective
: reconstruction loss를 도입해 input data의 semantic structure를 되돌리도록 만든다. 예를 들어, table의 특성 이름을 라벨로 해서 그것을 복원하도록 학습하는 것을 추가하는 것이 있다. 또한, output text를 structural information에 맞게 조정하는 방법이 있는데, 이 경우 cycle-consistency loss를 이용한다.
- adding structural information as input
: 이 방법은 위 방법과 달리 직접적으로 구조 정보를 input으로 주는 것인데, graph embedding으로 바꿔서 같이 넣어주거나 구조를 나타내는 특수 토큰(ex. "H","R","T")들을 head entity 앞에 넣어주는 방법이 있다.
- employing structural encoding module
: 이 방법은 input을 같이 넣어주는 것이 아닌 인코더 모듈을 따로 두는 것이다. StructAdapt가 대표적인데, GNN 모듈로 새로운 representation을 생성한다. -
maintaining text fiedlity
- incorporating additional training objectives
: content matching loss나 semantic fidelity classification loss를 도입해서 할루시네이션과 생략과 같은 에러를 방지하고 중요한 정보를 기반으로 생성하도록 만든다.
- utilizing copy mechanism
: pointer-generator라는 방법을 사용한다. input에 있는 정보를 그대로 들고와서 output에 생성한다.
- adding target information as input
: intermediate meaning representation을 활용해서 생성 모듈이 logical form을 유지하도록 하는 방법이다.
3.3 multimedia input
: image, 비디오, 스페치를 넣는 것을 의미한다.
-
image captioning
: 이미지를 묘사하는 것이다. XGPT, visualGPT가 있다. 텍스트와 이미지 객체와 이미지에 나오는 텍스트들이 이러한 task를 해결하는 중요한 요소이다. -
video captioning
: VideoBERT와 CBT가 있다. 그리고 이러한 모델이 개선되어, UniVL 모델이 만들어졌다. -
말 인식(speech recognition)
: 음성을 말로 바꾸는 작업이다. (이 분야는 필자들이 잘 모르는 것 같다.)
4. Designing PLMS for text generation
4.1 표준 아키텍쳐
: transforemr 기반 BERT, GPT-3, UniLM이 있다. 그리고 이들을 학습하는 방법은 각각 MLM,causal LM, prefix LM이다.
- MLM
: input에 마스크를 씌운다음 그것을 맞추는 테스크로 pretraining한다. RoBERTa 모델이 대표적이다. - Causal LM
: 다음 단어를 맞추는 방식으로 학습한다. GPT-3가 대표적이며, 이 모델을 제안한 논문에서는 finetuning 없이 prompt(few examples)만 있다면 원하는 결과를 생성할 수 있다고 한다. 그러나 전형적인 LM의 문제인 양방향의 정보를 고려하지 못한다. - prefix LM
: UniLM이 대표적이며, 발전되어 GLM, XLNET이 존재한다.mixture attention masks를 활용해서 학습을 한다. input에 있는 토큰들은 서로 attending을 하고, y에 있는 토큰들은 토큰들과 기존에 생성된 텍스트를 attending 한다. UniLM에서는 prefix attention mask를 이용하여 조건적으로 생성 작업을 한다. - encoder-decoder LM
: transformer 구조를 준수한 모델이며, T5와 BART가 대표적이다. BART는 기존의 텍스트를 일부로 변형한 다음 다시 복원하는 작업을 수행하며 학습한다.
4.2 구조 확장
: extended embeddings과 개선된 attention모듈을 소개한다.
-
Auxiliary embeddings
: absolute learned embeddings을 사용한 BERT, GPT가 있다
: relative positional embeddings을 사용한 T5,UNiLMv2가 있다.
: hierarchical positional embeddings을 이용해 intra- and inter- sentence정보를 활용한 시 생성 모델이 있다.
: dialog state embeddings과 user embeddings을 이용해 conversation 생성을 만든 모델이 있다.
: multi-lingual 모델에서 언어 임베딩도 사용하고, 운율 정보를 위한 시 모델에서 라임과 모음 임베딩을 사용한다. -
imporved attention modules
: 모두를 참조하지 않는 sparse attention계열의 window attention, gloabl attention, random attention, sinkhorn attention이 있다.
: dialogue history나 current state, presona information input을 이용한 mean poolinng을 통과하여 축약 후 cross-attention에 정보를 넘겨준다.
: 다양한 관점에서 embedding을 처리하는 방법이 있고, attention을 graph netwrok로 대체해서 구조 정보를 파악하도록 하는 것도 있고, attention module 다음에 gating 메카니즘을 추가해서 condition-aware 정보를 주입하도록 한다.
5. Optimizing PLMS for text generation
: 이번에는 fine-tuning, prompt-tuning, property-tuning을 다뤄볼 것이다.
5.1 fine-tuning
-
vanilla fine-tuning : PLMs을 cross-entropy loss로 학습하는 방법이 있다. DialoGPT는 multi-turn dialogue session을 모델링해서 학습을 했다. 또다른 모델로 BART와 T%가 있다. 이러한 종류의 fine-tuning은 작은 데이터셋일 경우 오버피팅이 된다.
-
intermediate fine-tuning: DAIFT와 TAIFT가 대표적인 방법이며 작은 데이터셋일 경우 도입하는 것이 바람직하다. 같은 도메인이거나 같은 NLP task의 데이터셋을 같이 학습하는 것을 통해 small dataset문제를 해결하려는 시도이다.
- Domain adpative intermediate Fine-tuning
: text 생성용 데이터셋이 아닌 다른 NLP 데이터셋을 이용한다. 대신 도메인은 같아야 한다. 예를 들어, 기계번역에서 기계번역용 데이터셋이 아닌 다른 데이터셋을 활용한다.
- Task adpative intermediate Fine-tuning
: text 생성 task이지만 다른 도메인의 데이터셋을 이용한다. 예를 들어, 요약 task에서 zero-shot, few-shot의 성능을 끌어올리기 위해 사용한다. 또 다른 예로는 상식에 기반한 이야기를 만들기 위해 다른 도메인의 데이터를 이용해서 학습한다.
-
multi-task fine-tuning : pure MTFT와 hybrid MTFT가 존재한다. 생성 task말고 보조적 task도 수행하도록 하여 학습을 진행하는 방법이다.
- Pure Multi-Task Fine-Tuning
: 보조적인 task 또한 다른 종류의 생성 task를 하도록 하는 방법이며(두 가지 언어 간의 생성을 풀면서 동시에 한 가지 언어로만 생성하는 경우도 추가한 경우), 이러한 방법은 데이터의 희소성을 해결하기 위해 고안된 방법이다. 보통 요약이나 Q&A에서 한다.
- Hybrid Multi-Task Fine-Tuning
: 보조적인 task를 생성 task가 아닌 다른 것을 하도록 하는 방법이다. 보통 text-style이나 topic change와 같은 task를 이용해 생성 text의 내용을 통제하기 위해 사용한다. -
parameter efficient fine-tuning :
- adapter-based
: adapter라는 특수 레이어를 추가해서 input vector를 차원을 줄이도록 하고 그것을 다시 복원하도록 하여, plm의 파라미터는 고정하고 adapter layer만 학습하는 방법이다.
- freezing-based
: 최근 연구에 따르면 모든 PLM의 파라미터를 업데이트할 필요가 없다고 한다. 따라서 부분적인 파라미터들만 학습을 하도록 하는 방법이다. 특히 cross-attention layer들의 파라미터가 굉장히 중요하다고 한다. 따라서 한 연구에서는 이러한 레이어만 부분적으로 학습하는 방법을 사용했다.
- distillation-based
: teacher모델을 이용해 작은 student 모델을 학습하는 방법이다. teacher모델로 PLM을 사용하고 student는 훨씬 작은 모델을 설계해서 teacher 모델의 output 분포를 따라하도록 작은 모델을 학습한다.
5.2 prompt-tuning
: pretraining 목적과 downstream task의 학습 목적이 불일치하는 현상을 해결하기 위해, downstream task를 language modeling task처럼 바꿔 pretraining하도록 한다.
-
background
: 1. applying a template : make a slot [X] input & [Z] answer
: 2. slot [x]에 input text를 집어 넣는다.
ex) x = I love this movie, template = [X] it was a really [z] movie. -> z를 prediction하도록 학습 -
discrete prompts
: 프롬프트에서 언어 의미적으로 input data와 output data가 어떻게 연결되는지 정의한다. 위의 제시된 예가 대표적이다. 프롬프트에 따라 성능이 좌우되기에 automatic search를 통해 template token을 찾는다. -
continuous prompts(soft prompts)
: embedding space에서 프롬프트를 학습하도록 한다. prompt만의 weight를 가지게 하고, PLM paramter들을 동결한 후 sequence continuous vector만 학습하도록 prefix tuning이 대표적이다. 이것을 이용해 dialog generation과 같은 task를 잘 수행하기 위한 연구를 하고 있다.
5.3 property-tuning
- relevance : topical semantics. 예를 들어, 다이얼로그 시스템에서 스피커의 성격이나 대화 주제들이 일관되게 생성해야 한다.
: DialogGPT는 Pr(history,response) 결합확률 분포를 풀도록 했다.
: TF-IDF masking을 이용한 condition-related expressions를 생성하도록 하는 사례도 있다.
-
faithfulness : 생성된 텍스트가 input text와 연관이 있어야 한다.
: 요약 문제에서 이상한 요약을 하면 안되는 것이 대표적이 예시이다.
: contextual network나 denosing autoencoder, them modeling loss등을 이용해서 이러한 문제를 해결한다. -
order-preservation : 단어나 구의 순서가 자연스러워야 한다.
: 번역 문제에서 한 연구 흐름으로 code-switching pre-training(CSP)를 활용해서 단어 정렬(word alignment)을 맞추도록 한다.
: 번역 문제에서 다른 연구 흐름으로 representation alignment를 통해 순서에 맞게 단어를 생성하도록 한다.
6. Challenges and Solutions
6.1 data view
-
데이터 부족 문제
- transfer learning
: dialog 시스템에서 다른 도메인 포함하여 먼저 fine-tuning을 진행한 다음에, 특정 도메인에 맞게 fine-tuning 하는 방법이다.
- data augmentation
: weak-supervised data를 구성하는 것을 통해 성능을 희소성 문제를 푸는 방법이다. retrieval model(검색 모델)을 이용해 simulated data를 만드는 방법이랑, 기존 text를 약간 변형해서 사용하는 perturbation-based 방법(일부로 생략,삭제 순서바꾸기 등을 적용하는 것)이 있다.
- multi-task learning
: 위에서 설명했듯이, 여러 task를 풀도록하면서 학습한다.
-
다른 도메인 간의 transfer learning 문제
- pretraining on intermediate data
: pretraining 할 때부터 domain과 관련된 데이터 만을 이용해서 학습한다.
- pretraining on intermediate task
: pretraining 할 때부터 같은 task의 데이터 만을 이용해서 학습한다. -
pretraining용 corpus의 데이터 편향 문제
: race나 gender, age문제에 편향되어 있다. 이를 해결하기 위해 성을 swap해서 데이터를 변형하거나, 이름이나 대명사(he,she)를 masking 처리한다거나와 같은 방법을 이용한다.
6.2 model view
-
모델 압축
: PLM들은 매우 크고 리소스가 많이 들기에 사용하기 조심스럽다.
- quantization
: 고유한 weight 값들을 제거하는 방법이다. 다시 말해, 중요한 weight들을 제외한 나머지 하찮은 weight를 제거하는 것이다. 특히 FC 레이어의 weight가 주요 제거 대상이다.
- prunning
: 중복되거나 덜 중요한 weight를 제거하는 방법이다. 전체 레이어를 제거할 수도, 아니면 블락 내의 weight들을 중요도에 따라(gradient 크기를 측정해서 판단) 각각 제거할 수도 있다.
- knowledge distillation
: student model을 만들어, teacher 모델의 분포를 배우도록 학습하여 모델 크기를 줄인다. -
모델 확장
: 성능을 개선하는 측면에서 바라본 관점이다.
- large-scale PLMs
: 크고 방대한 데이터일수록 성능이 좋아진다.
- knowledge-enriched PLMs
: 외부의 지식들을 모델에 주입하면 성능이 좋아진다. 이러한 실험은 CALM이나 ERNIE3.0에서 행해졌다.
- efficient PLMS
: 점차적으로 몇 스텝에 걸쳐 비교적 작은 corpus들을 늘려가며 pretraining해도 성능이 준수하게 나온다. -
모델 강건성
: 노이즈에 좌우되지 않는 튼튼한 모델을 만들고 싶다.
- character embedding
: sub-word emedding이 주요한 에러의 요인인데, 처음에 한 번 틀리면 계속 틀린 텍스트를 생성해버린다. 그래서 sub-word와 character embedding을 함께 썼을 때 생성 테스크의 성능이 올라 갔다.
- Data augmentation
: semantic neighborhood측면에서 일반화가 잘 안된다는 것이 PLM의 단점인데, 이를 해결하기 위해 "MLM with 가우시안 노이즈"를 이용해 가상의 데이터들을 만들며 학습하는 방법을 활용했다.
6.3 optimizing view
-
텍스트의 특수한 속성을 만족하는 것
- coherence를 올리는 것
: coherence란 텍스트가 나타내고자 하는 의미가 의미론적으로 적합한 지를 의미한다.
: text planning을 통해 개선할 수 있다.(document plan, sentence plan, sugraphs plan)
- preserving the factuality
: input data에 있는 사실과 생성된 text사실이 일치해야 한다. 위에서 언급했던 pointer-generator를 이용한다.
- improving the controllability
: Plug & Play LM은 classifier들을 이용해서 원하는 타입의 text를 생성하도록 했다. 모델 아키텍쳐를 수정하지 않고 원하는 텍스트를 만들도록 주제, 키워드, 분포 이동 등을 이용한다. -
mitigating tuning instabilities
: 적은 데이터셋으로 인한 모델의 불안정을 해결하고 싶다.
- intermediate fine-tuning
: 전형적인 pretrain-finetune 방법을 의미한다.
- mixout strategy
: 두 개의 PLMs을 가지고 확률에 따라 parameter들을 섞어서 학습하면, regularization을 부과하는 효과를 얻을 수 있다.(신기하네...?)
- contrastive learning
: cross-entropy loss로 fine-tuning하는 대신에, contrastive loss를 사용한다.(근데 이것은 안정성이기 이전에 성능이 안 나올 것 같은데?)
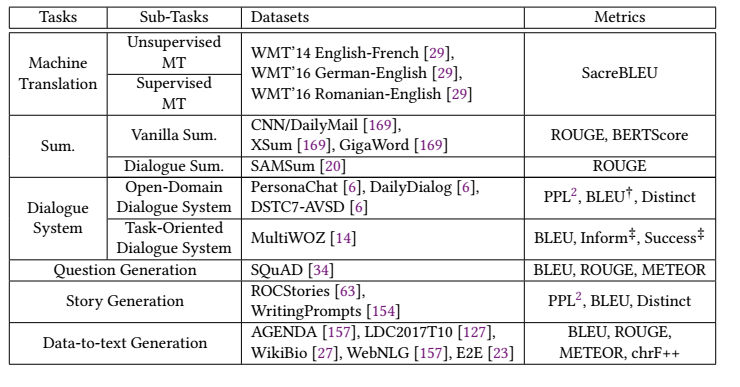
7. Evalutation and Resources
7.1 evaluation
- N-gram overlap metrics : matching rule
- BLEU : 텍스트를 1-gram, 2-gram 다 비교함
- ROUGE : 요약 task 성능 측정
- METEOR : BLEU를 개선해서 wordnet과 조화평균(보통 변화율을 측정하는데 쓰임)을 이용해서 측정
- ChrF++ : 번역에서 character level 단위 n-gram 적용해서 측정
- diversity metrics : 어휘 다양성을 측정(대화 시스템이나 스토리 생성)
- Distinct : distinct n-gram을 측정
- Semantic similarity metrics : sentence를 vector로 치환후 비교
- BERTscore : 벡터 유사도 비교를 통한 측정
7.2 resources
- transformers, fairseq 사용
8. Applications
- 기계 번역
- 비지도 기계번역(UMT)
: 첫 번째로 한 가지 언어로만 학습하고 언어 별로 번갈아면서 pretraining 하고나서 두 번째로 반복적인 back-translation을 적용하는 방법이다.
-- 두 가지 언어 쌍으로 UMT 한다.
-- 두가지 언어에 제 3의 언어를 참조해서 학습하는 방법도 있다. back-translation loss를 이용한다.
- 지도 기계 번역
: parallel corpora를 pretraining이나 finetuning에서 사용하는 방법이다.
- 텍스트 요약
- document 요약
- 다이얼로그 요약
- 다이얼로그 시스템
: history context에 기반하여 대답을 생성해야 하는 task이다. 두 가지의 카테고리로 나뉘는데, 첫 번째는 open-domain이고 두 번째는 task-oriented이다. 전자는 일상 생활이나 여가 스포츠에 관해서 이야기하는 것이라면 후자는 상대방이 업무를 하는 것(구매,예약 등)에 도움을 주는 것이 목적이다.
-
open-domain dialogue system : chatbot, 일상 대화를 가능하게는 것
: 보통 레딧,트위터,weibo같은 곳의 포럼 포스트나 코멘트를 이용해서 사전 학습한다. DialoGPT나 Meena가 GPT-2의 구조를 이용해서 만들었다. Blender나 PLATO는 seq2seq loss를 이용해서 만들었다. 이러한 모델들은 단조로운 대답(bland response을 피하기 위해 다양한 방법을 이용했다.
: 기존에 dialog 데이터로 사전학습한 것이 아닌 일반 PLMs을 이용해서 만든 모델도 있다. 모델들의 예시로는 transferTransfo나 dialogBERT, DialoFlow, styleDGPT가 있다. -
task-oriented dialogue system : 이것의 목적은 사용자의 의도와 그것에 따른 slot-value 채우기이다. 보통 생성 관련으로 PT-2를 백본으로 사용한다.
- 기타
- Question generation : 문제 만들기
- story generation : new나 해설 만들기
- data-text generation : 설명이나 구조적 텍스트를 만드는 것. 위의 것들은 text-text generation임
- 상식을 만드는 것이나 글 쓰는 스타일 바꾸는 것 등이 있을 수 있다.
9. Conclusion and Future Directions
- controllable generation : 원하는대로 text를 생성할 수 있도록 만드는 것이 미래의 방향 중 하나이다. 특히 coarse(전체적인)가 아닌 grained(세부적인) 측면에서 컨트롤하기가 매우 어렵다.
- optimization exploration : prompt-based가 연구중이고 fine-tuning 여러가지 방면으로 개선해야 한다.
- Language-agnostic PLMs : 영어에 국한된 것이 아닌 언어 자체의 특성을 학습할 수 있는 모델적 개선이 필요하다.
- Ethical Concern : 잠재적인 윤리문제를 인식하고, PLMs이 편견을 가지고 학습된 것이 아닌 지 항상 조심해야 한다.
