COCO Style Custom Dataset 만들기
1. fifty one 설치
-
fiftyone : 다양한 오픈 데이터셋을 관리할 수 있는 모듈
$ pip install fiftyone
-
fiftyone luunch_app
import fiftyone as fo
# The directory containing the source images
data_path = "./Zzuri/data/"
# The path to the COCO labels JSON file
labels_path = "./Zzuri/labels.json"
# Import the dataset
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.COCODetectionDataset,
data_path=data_path,
labels_path=labels_path,
)
if __name__ == "__main__":
# Ensures that the App processes are safely launched on Windows
session = fo.launch_app(dataset)
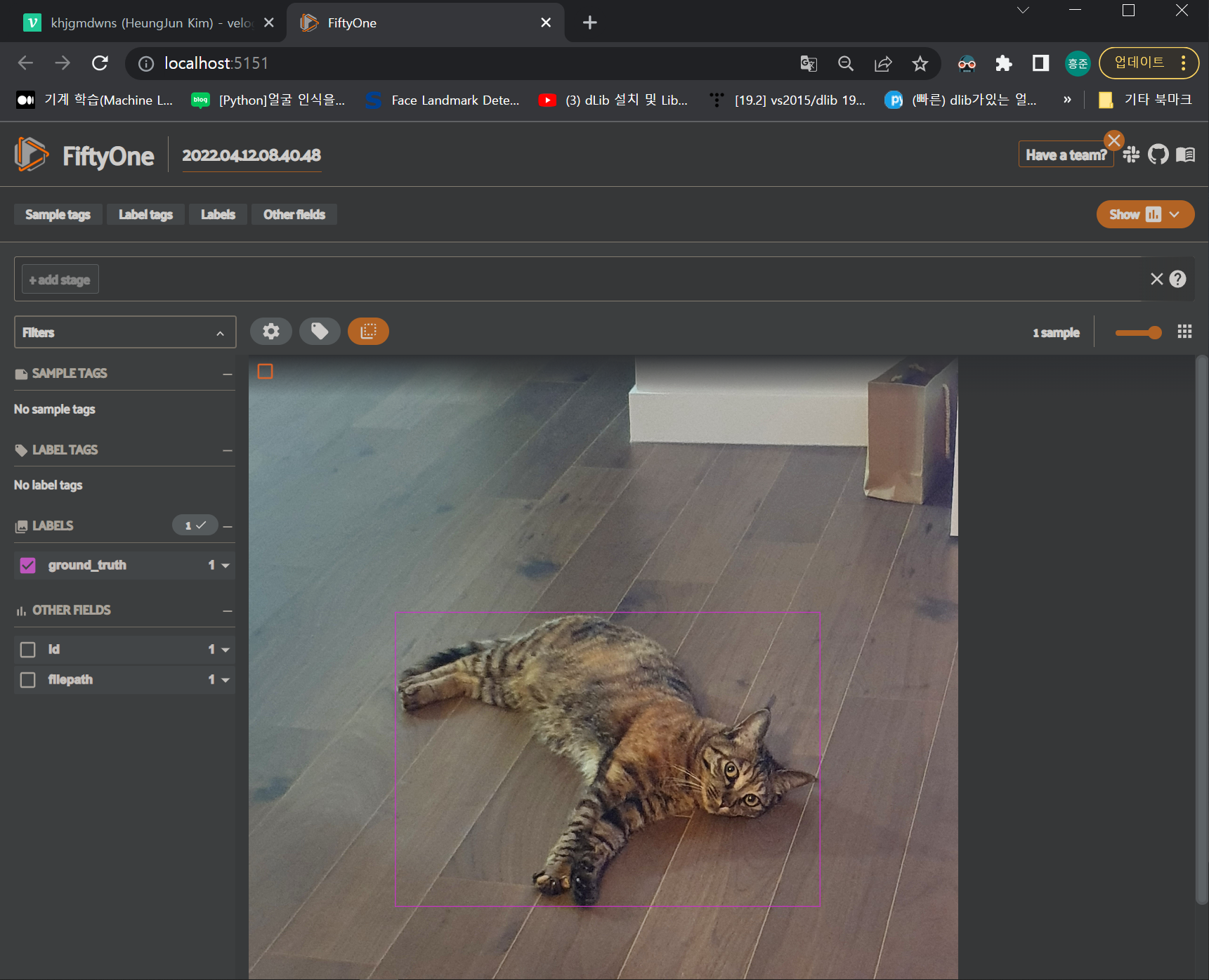
session.wait()- fifty one app을 launch하면 localhost:5151 웹으로 연결되며 dataset을 감상할 수 있다.
- 세상에서 제일 귀여운 고양이🐈 dataset을 감상해보자!
2. COCO Style Custom Dataset 만들기
- caffe 기반에서 사용했던 gt label을 coco style로 변환하였다.
import fiftyone as fo
import os
gt_path = "iray/labels/"
image_path = "iray/images/"
gt_files = os.listdir(gt_path)
dataset = fo.Dataset()
# Set default classes
dataset.default_classes = ["Person", "Vehicle", "Animal", "Bike"]
dataset.save() # must save after edits
# Create samples for your data
samples = []
for i in range(len(gt_files)):
#for i in range(1):
image_name = image_path+gt_files[i]
image_name = image_name[:-3] + 'png'
print(str(i + 1) + ' : ' + image_name)
gt_file = open(gt_path+gt_files[i])
sample = fo.Sample(filepath=image_name)
detections = []
for line_text in gt_file:
tokens = line_text.split()
label = dataset.default_classes[int(tokens[0])]
box_width = float(tokens[3])
box_height = float(tokens[4])
left_top_x = float(tokens[1]) - box_width/2
left_top_y = float(tokens[2]) - box_height/2
bounding_box = [left_top_x, left_top_y, box_width, box_height]
detections.append(
fo.Detection(label=label, bounding_box=bounding_box)
)
# Store detections in a field name of your choice
sample["ground_truth"] = fo.Detections(detections=detections)
samples.append(sample)
# Create dataset
print('add_samples...')
dataset.add_samples(samples)
dataset.save() # must save after edits
print('export...')
# Export the dataset
dataset.export(
export_dir="iray/",
dataset_type=fo.types.COCODetectionDataset,
label_field="ground_truth",
)
-
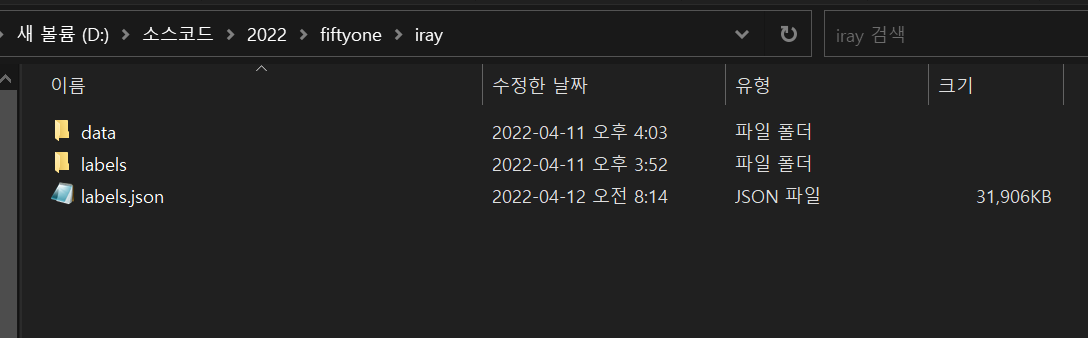
아래와 같이 COCO type의 데이터셋이 생성된다.
-
jq 다운로드
jq를 이용해서 만들어진 coco labels.json 파일을 보기 편하게 변환할 수 있다.$ jq-win64.exe . .\labels.json > labels_cvt.json
{
"info": {
"year": "2022",
"version": "1.0",
"description": "Exported from FiftyOne",
"contributor": "hjkim",
"url": "https://voxel51.com/fiftyone",
"date_created": "2022-04-11T18:44:23"
},
"licenses": [],
"categories": [
{
"id": 0,
"name": "Person",
"supercategory": null
},
{
"id": 1,
"name": "Vehicle",
"supercategory": null
},
{
"id": 2,
"name": "Animal",
"supercategory": null
},
{
"id": 3,
"name": "Bike",
"supercategory": null
}
],
"images": [
{
"id": 1,
"file_name": "MIR1.0_20190814191628SN_TP29_WN1_C1_NKOR_RAYS_PU_FD_OKSH_00448.png",
"height": 256,
"width": 512,
"license": null,
"coco_url": null
},
.
.
.
Computer Vision / ADAS / DMS / Face Recognition