Swin-Object Detection Training 커스텀하기(dataset 수정, without mask)
🍎 커스텀 트레이닝 목표
1) COCO Dataset 축소
- COCO training 데이터셋은 118,287(약 12만장)으로 학습이 오래걸리기 때문에, 다양한 학습을 실험하기 위해 데이터셋을 축소
2) classes_num 축소
- 추후 자신만의 데이터셋 학습을 위해 선행학습(COCO 80→1)
3) segmentation(Mask) 비활성화
- object detection 만을 수행하도록 casecade mask-rcnn config 파일 수정
1. COCO Dataset 축소
-
fiftyone : Dataset 다운로드, 수정, 변환을 위한 라이브러리
$ pip install fiftyone
-
coco2017-train 데이터셋 중 person class에 대해서만 100개의 샘플을 가져오기 스크립트
import fiftyone as fo
import fiftyone.zoo as foz
# To download the COCO dataset for only the "person" and "car" classes
dataset = foz.load_zoo_dataset(
"coco-2017",
split="train",
label_types=["detections", "segmentations"],
classes=["person"],
max_samples=1000,
)※ 치명적 오류.
스크립트를 실행하면 중간에 다운로드 실패 에러가 간헐적으로 발생한다. 스크립트를 재실행하면, 다운로드 완료한 이미지를 제외하고 나머지 이미지를 다운받는데, 이때 손상된 이미지 파일이 포함될 수 있다.
트레이닝 epoch중 랜덤하게 손상된 이미지를 불러오면 학습이 강제종료 되므로, 반드시 손상된 이미지를 복구해야한다.
-
해결방법
coco2017-train(118,287 images) 원본을 다운받고, 필터링된 train dataset(손상된 이미지 포함)의 파일 리스트를 불러와 원본 이미지로 덮어쓰는 스크립트를 작성 -
손상된 필터링 데이터셋 복구 스크립트
import cv2
import os
import shutil
files = os.listdir('my/val2017/')
for i in range(len(files)):
target_path = 'coco/val2017/'+files[i]
dist_path = 'my/val2017_/'+files[i]
shutil.copy(target_path, dist_path)
print(dist_path)1. 커스텀 데이터 세트 구성
-
커스텀 데이터 구성
classes num : 1(person)
train : 3000 images
val : 500 images
test : 500 images -
/Swin-Transformer-Object-Detection/data/my/ 경로에 커스텀 데이터 복사
-
configs/base/datasets/coco_instance.py 수정
2 data_root = 'data/my/' # 'data/coco/'2. Classes_num 축소 및 mask 비활성화
-
모델 config 파일 수정
link : Comment out the configuration related to the mask 참조 -
configs/swin/cascade_mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_giou_4conv1f_adamw_1x_coco.py
_base_ = [
'../_base_/models/custom.py',
'../_base_/datasets/coco_custom.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
model = dict(
backbone=dict(
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
ape=False,
drop_path_rate=0.0,
patch_norm=True,
use_checkpoint=False
),
neck=dict(in_channels=[96, 192, 384, 768]),
roi_head=dict(
bbox_head=[
dict(
type='ConvFCBBoxHead',
num_shared_convs=4,
num_shared_fcs=1,
in_channels=256,
conv_out_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
reg_decoded_bbox=True,
norm_cfg=dict(type='SyncBN', requires_grad=True),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=10.0)),
dict(
type='ConvFCBBoxHead',
num_shared_convs=4,
num_shared_fcs=1,
in_channels=256,
conv_out_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=False,
reg_decoded_bbox=True,
norm_cfg=dict(type='SyncBN', requires_grad=True),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=10.0)),
dict(
type='ConvFCBBoxHead',
num_shared_convs=4,
num_shared_fcs=1,
in_channels=256,
conv_out_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=False,
reg_decoded_bbox=True,
norm_cfg=dict(type='SyncBN', requires_grad=True),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=10.0))
]))
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# augmentation strategy originates from DETR / Sparse RCNN
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='AutoAugment',
policies=[
[
dict(type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
(608, 1333), (640, 1333), (672, 1333), (704, 1333),
(736, 1333), (768, 1333), (800, 1333)],
multiscale_mode='value',
keep_ratio=True)
],
[
dict(type='Resize',
img_scale=[(400, 1333), (500, 1333), (600, 1333)],
multiscale_mode='value',
keep_ratio=True),
dict(type='RandomCrop',
crop_type='absolute_range',
crop_size=(384, 600),
allow_negative_crop=True),
dict(type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
multiscale_mode='value',
override=True,
keep_ratio=True)
]
]),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
data = dict(train=dict(pipeline=train_pipeline))
optimizer = dict(_delete_=True, type='AdamW', lr=0.0001, betas=(0.9, 0.999), weight_decay=0.05,
paramwise_cfg=dict(custom_keys={'absolute_pos_embed': dict(decay_mult=0.),
'relative_position_bias_table': dict(decay_mult=0.),
'norm': dict(decay_mult=0.)}))
lr_config = dict(step=[8, 11])
runner = dict(type='EpochBasedRunnerAmp', max_epochs=12)
# do not use mmdet version fp16
fp16 = None
optimizer_config = dict(
type="DistOptimizerHook",
update_interval=1,
grad_clip=None,
coalesce=True,
bucket_size_mb=-1,
use_fp16=True,
)- configs/base/models/cascade_mask_rcnn_swin_fpn.py
# model settings
model = dict(
type='CascadeRCNN',
pretrained=None,
backbone=dict(
type='SwinTransformer',
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
ape=False,
patch_norm=True,
out_indices=(0, 1, 2, 3),
use_checkpoint=False),
neck=dict(
type='FPN',
in_channels=[96, 192, 384, 768],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
]#,
),
# mask_roi_extractor=dict(
# type='SingleRoIExtractor',
# roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
# out_channels=256,
# featmap_strides=[4, 8, 16, 32]),
# mask_head=dict(
# type='FCNMaskHead',
# num_convs=4,
# in_channels=256,
# conv_out_channels=256,
# num_classes=80,
# loss_mask=dict(
# type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
# model training and testing settings
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=2000,
max_per_img=2000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
# mask_size=28,
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
# mask_size=28,
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.7,
min_pos_iou=0.7,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
# mask_size=28,
pos_weight=-1,
debug=False)
]),
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100#,
# mask_thr_binary=0.5
)
))- mmdet/datasets/coco.py
epoch 이후 evaluation 에서 segm 검증을 하지않으므로 무시하도록 코드를 수정한다.
422 if metric is 'segm':
423 print('pass segm!')
424 continue
3. 마스크 주석 없이 Detection만 트레이닝
-
mmdetection&mmcv 개발자 코멘트
cascade mask rcnn / HTC 알고리즘은 기본적으로 instance segmantation 모델이므로 마스크 주석없이 학습이 되지 않는다고 설명


-
그러나 2. 에 작성한 대로 config 파일을 수정하여 mask_roi_extractor를 제외하고 트레이닝을 한 결과 정상적으로 학습이 되었음.
-
bbox loss graph
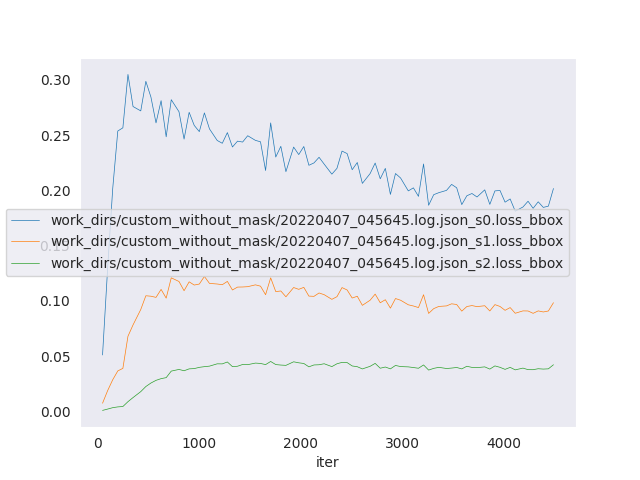
-
mAP graph
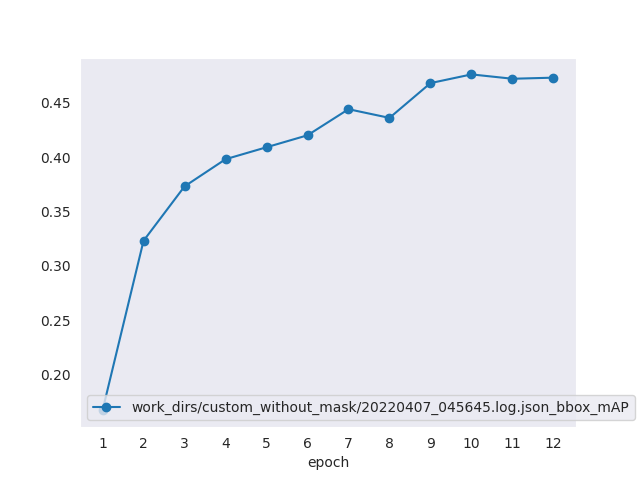
-
Mask Seg(On) vs Mask Seg(Off) 비교
Last mAP 기준 0.4820 / 0.4730 으로 큰 차이는 나이 않는 것 같다.(여러번 학습시 거의 비슷하게 나올지도 모른다)
+) 추가 학습 결과 Mask Seg(Off) 결과 mAP가 0.4780
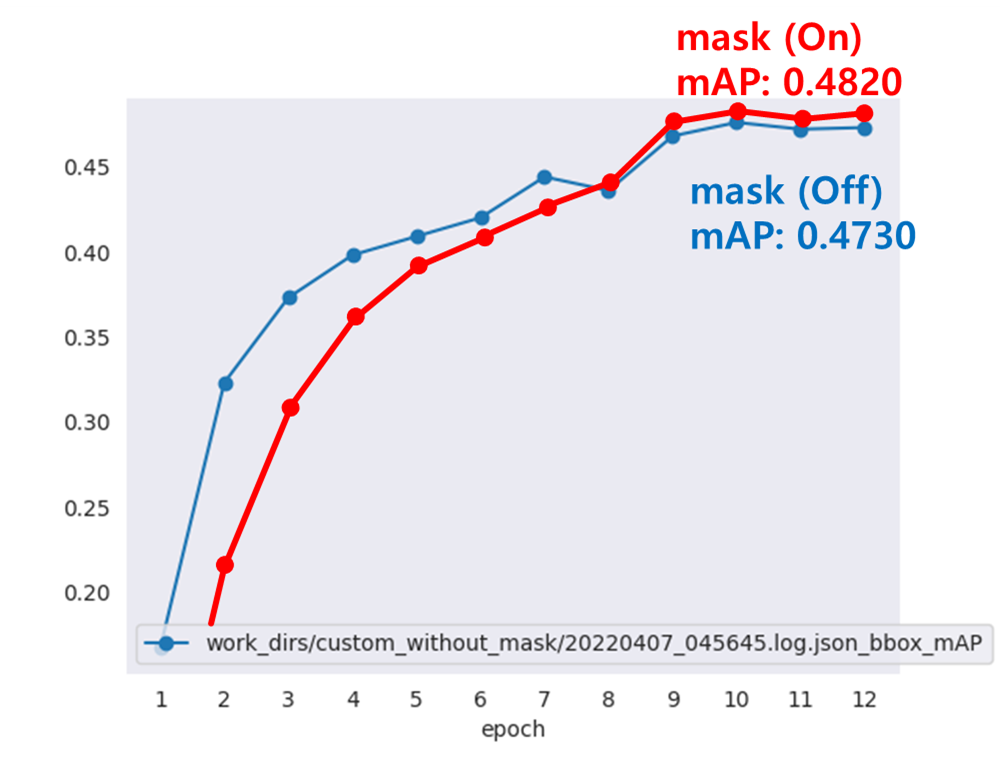
-
마스크 없이 Detection만 학습한 casecade mask rcnn(swin tiny) 결과
(casecad rcnn이라고 부르는게 맞는것 같다.)
coco 데이터셋에서 사람 이미지 3000장으로 제한하여 트레이닝한 결과이므로, 이미지 수가 더 많거나 더 무거운 모델을 적용하면 mAP도 더 높아질 것으로 예상된다.

