ImageNet Normalization
Pytorch 사용시 torchvision.transform 을 이용해서 여러 비전 관련 작업들을 수행한다. 여러 사람들이 다양한 데이터를 사용하고 이를 이용해 모델을 학습 시킨다.
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
이때 전처리 정규화 과정의 평균과 표준편차는 대부분 이미지넷의 통계치를 사용한다. 그럼 이 정규화 코드는 무엇을 의미할까?
이미지의 구간 범위를 0-1로 하면 평균은 0.5로 하는것이 일반적이라고 생각되지만 그렇지 않다.
위 수치는 ImageNet 데이터세트의 평균과 표준편차 통계치이다.
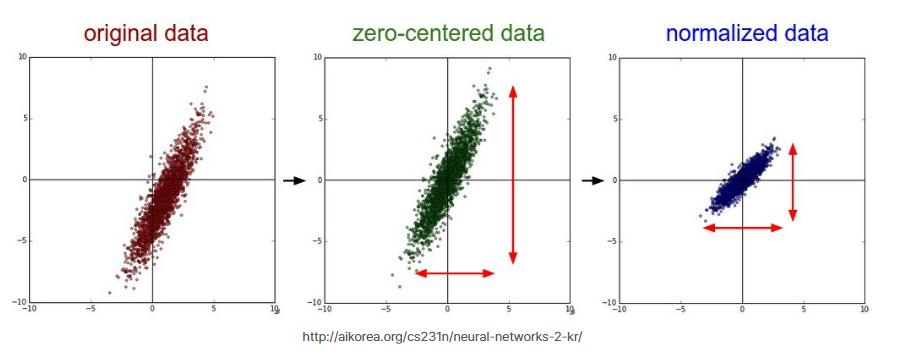
실제 각 채널(rgb) 별 정규화되는 값의 범위는 아래와 같이 계산된다.

Gray Scale ImageNet Normalization
만약 학습데이터셋이 gray scale 도메인이라면,
(rgb 채널 값이 같음)
두가지 선택지가 있다.
- 커스텀 학습데이터셋으로부터 직접 mean/std 값을 구해서 사용
- mean/std 값 구하기 예제코드
import os import torch from torchvision import datasets, transforms from torch.utils.data.dataset import Dataset from tqdm.notebook import tqdm from time import time N_CHANNELS = 1 dataset = datasets.MNIST("data", download=True, train=True, transform=transforms.ToTensor()) full_loader = torch.utils.data.DataLoader(dataset, shuffle=False, num_workers=os.cpu_count()) before = time() mean = torch.zeros(1) std = torch.zeros(1) print('==> Computing mean and std..') for inputs, _labels in tqdm(full_loader): for i in range(N_CHANNELS): mean[i] += inputs[:,i,:,:].mean() std[i] += inputs[:,i,:,:].std() mean.div_(len(dataset)) std.div_(len(dataset)) print(mean, std) print("time elapsed: ", time()-before)
- Gray Scale로 변환된 ImageNet Dataset의 mean/std 값을 사용
-
Mean: 0.44531356896770125
-
Std: 0.2692461874154524
ImageNet 정규화된 사전학습 모델을 Gray Scale(IR 카메라) 도메인에 적용하는 경우
IR 데이터셋으로 직접 학습이 불가능하여,
rgb 도메인으로부터 학습된 사전학습 모델을 사용해야만 하는 경우에는아래의 솔루션을 적용할 수 있다.
- IR 데이터셋의 mean / std 를 구하고, (영상의 명암 특성을 반영)
정규화 후 값의 범위가 사전학습 된 imagenet norm의 값 범위와 유사하게 역산.
따라서, 아래와 같은 방식으로 역산할 수 있다.


Computer Vision / ADAS / DMS / Face Recognition