1. Object-Detection coco Benchmark SOTA
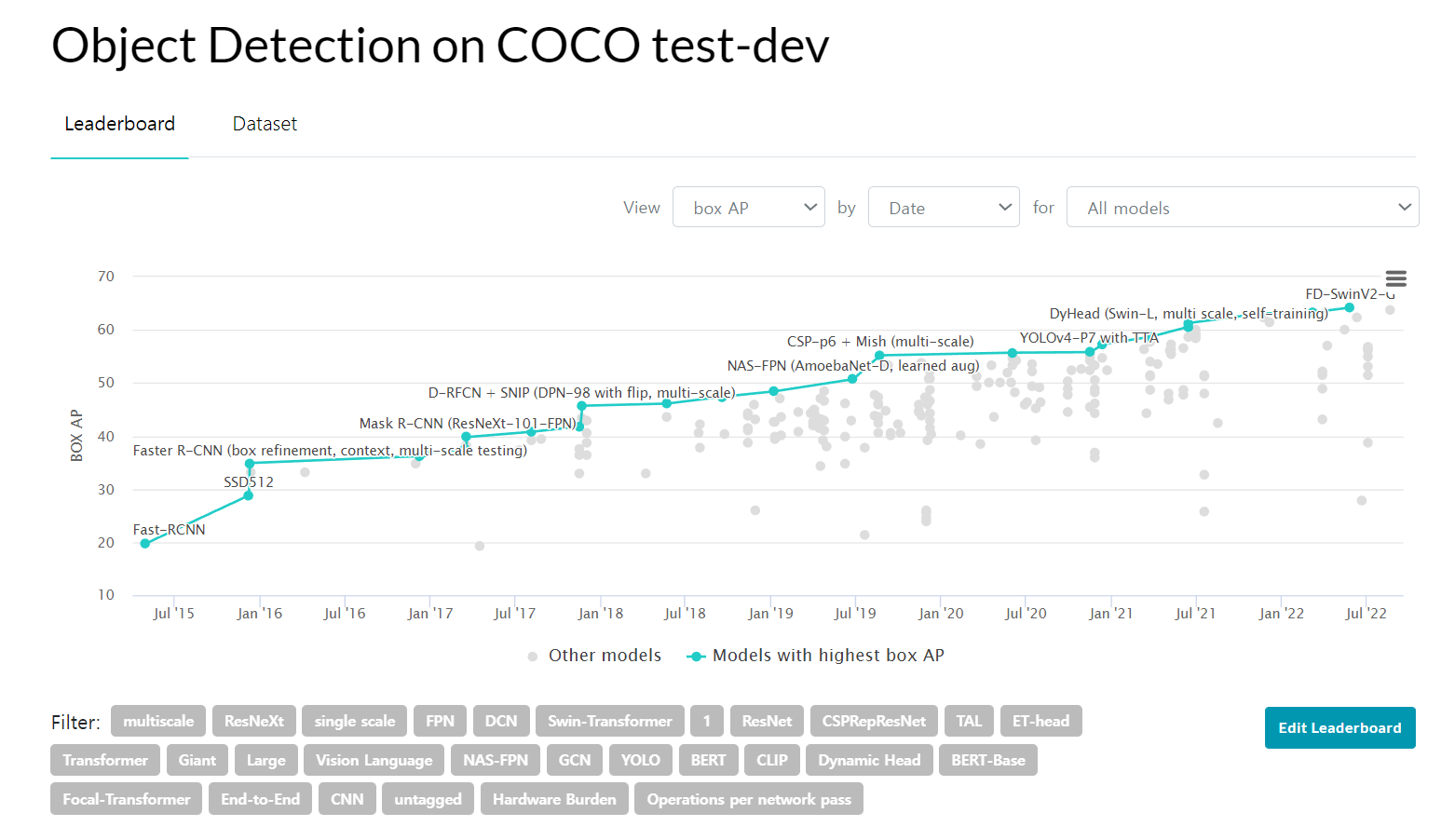
COCO dataset은 객체 검출 분야의 기준 데이터셋이기 때문에 최첨단의 Object-Detection 논문이 발표될 때마다, COCO Benchmark 랭킹이 갱신된다.
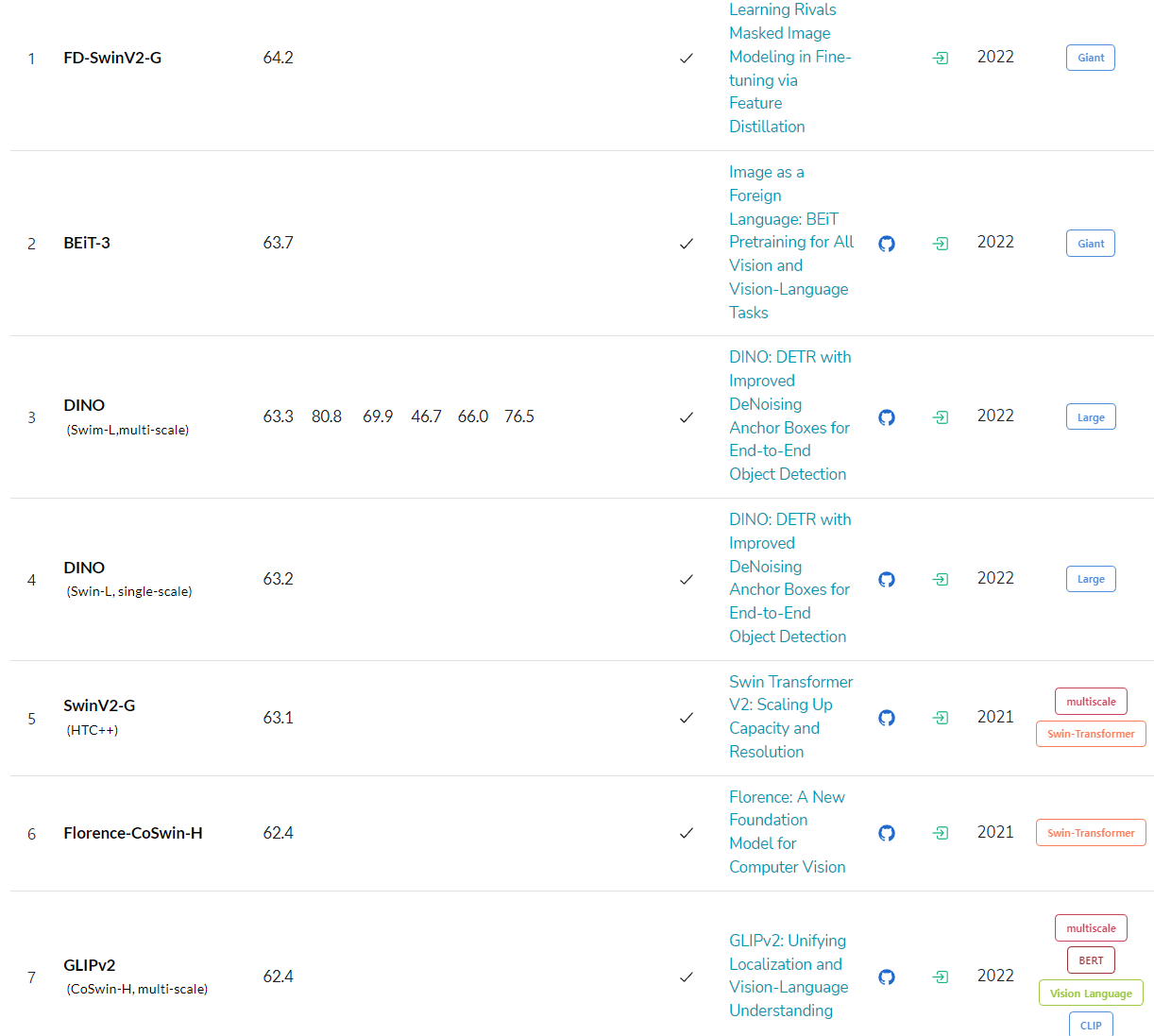
22년 상반기까지는 DINO 가 SOTA(1위)에 자리 매김하고 있었으나, 최근(2022년 8월) 순위가 변경되었다.
순위권에 있는 모델은 Swin+HTC(hybrid task cascade) 기반이거나 DINO와 같은 end-to-end, BEIT 기반으로 실시간과는 거리가 멀다.
순위권 알고리즘의 대부분이 git repo에 소스코드를 공개하지만, 밴치마크에서 최상의 성능을 기록한 모델과 configure은 제외된 경우가 많다.
즉, 핵심은 제외하고 일부 공개로 봐야겠다.
swin-transformer 기반의 object detection을 테스트 하기위해,
mmdetection 기반의 ms swin-transformer object detection 모델을 학습 및 분석하고 느낀 의문점이 있다.
yolo 시리즈의 경우 실시간 처리와 성능을 만족하기위해 다양한 augmentation, bag-of-freebies, anchor free, gIOU 등의 아이디어를 도입하는 반면,
swin 개열의 논문들은 최소한의 augmentation에, 고전적인 mask-rcnn / cascade m-rcnn / HTC 들을 이용한다.
코드뿐만아니라 논문에서도 backbone 아키텍쳐 구조의 효율성만을 다루는데,
banchmark에 리스트된 ms를 필두로하는 object detection 연구들은 주로 academic 성향이 강한 듯하다.
즉, "모든 방법들을 총동원해서 최고의 성능을 끌어올리자!" 가 아닌 우리가 설계한 아키텍쳐가 효과적임을 증명하는것이 중점이며, 이를 위해서는 그외의 요소(디텍션 알고리즘, augmentation, loss func)등은 고정적으로 사용하는 경향이 있다.
반면 yolo의 철학은 누구나 다양한 아이디어를 접목해서, 더나은 detection 알고리즘으로 개선하려는 경향성이 강한데, yolo의 다양한 변종 시리즈가 많은 이유인 것 같다.
또 yolo는 실시간 처리가 가능하며, 서버에서의 다채널 객체검출, Edge 시스템 적용이 가능한 장점으로 인해 현업에서 인기가 많다. 글로벌 기업에서 yolo의 새로운 버전을 출시하기도 한다.
yolo와 swin을 접목한 버전도 있지만 아직 첨단의 성능을 달성하지는 못하고 있다.
2. Benchmark 공정성
yolov7 repo의 이슈 중 밴치마크 공정성에 대한 언급이 있다.
paper에 명시된 mAP와 밴치마크의 mAP가 다르다는 것인데,
YOLOR-d6 : 55.4 mAP
YOLOv7-E6E : 56.8 mAP
YOLOR-d6-benchmark : 57.3 mAP
YOLOv7-E6E-benchmark : 56.8 mAPyolor의 성능이 밴치마크에서 더 높게 기록되어, yolov7이 주장하는 실시간 SOTA의 결과와는 모순된다.
yolov7은 yolor의 아이디어에서 개선되었고, paper와 소스코드의 저자또한 공유되는데 왜이런 결과가 나타나는지 많은사람들이 의문을 제기했고, 밴치마크가 공정하지 않다고 말한다.
coco benchmark에는 coco이외의 extra training dataset을 추가해 학습한 모델도 제출이 가능하다는 것.
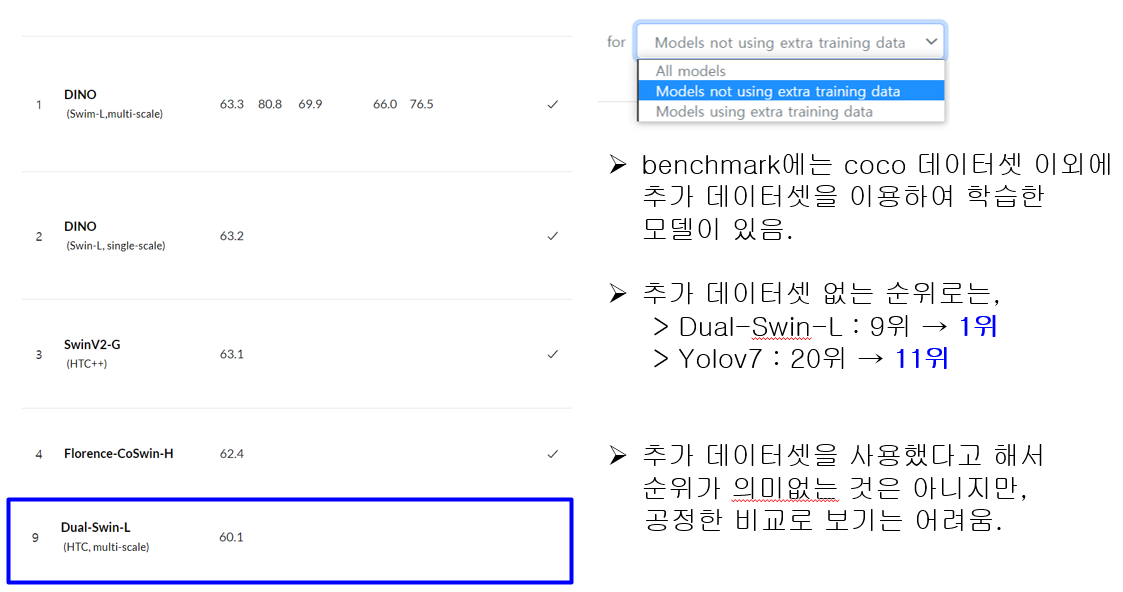
밴치마크 사이트에서 필터링 기능을 이용하면 extra training 데이터셋을 사용한 순위를 필터링하는 기능이 있는데, extra 셋 사용유무를 정확히 알 수 없는 모델이 많아서 신뢰하기는 어렵다.
2022 상반기 기준으로 SOTA 성능이였던 DINO가 extra dataset을 제외하면 1위가 아니라는 주장도 있었다.
사용자는 어떤데이터셋을 썻든간에 최고의 성능을 원하기 때문에,
coco 데이터에 대해 최고의 성능을 기록해보자는 취지로보면 공정성 논란이 없을 수도 있지만
밴치마크를 기준으로 알고리즘의 성능 우위를 판단하는 것은 무리가 있다. 참고만 하는 것이 좋겠다.
이와 관련해 yolov4의 저자이자 darknet 프레임워크의 컨트리뷰터인 AlexeyAB는 아래와 같이 답변했다.