yolox paper : link
yolox github : link
yolox 리뷰 : link
yolox scratch 튜토리얼 : link
1. YOLOX의 장점
기존에 사용중이던 yolo v5 model과 비교하여 yolox가 가지는 장점을 서술해보면,
- yolo v3의 darknet backbone 기반에 몇가지 아이디어를 추가하여 우수한 성능을 보임
- 비슷한 시기(2021년) 발표된 다양한 yolo 시리즈 중 우수한 acc/speed 를 보임
- Megvii 에서 개발되어 다양한 프레임워크 포팅 예제 및 검증된 소스코드 제공
- yolox에 적용된 Augmentation / SimOTA / multi positives / anchor-free 아이디어는 다른 Detection 알고리즘에 적용해도 효과를 볼 수 있음
2. YOLOX vs YOLOR

비슷한 시기(2021년)에 발표된 yolof, yolos, yolop, yolor 등 다양한 yolo 시리즈 중 정확도/속도 면에서 우위에 있는
yolox 와 yolor 적용을 검토하였다.
가장 정확도가 높은 것은 yolor(55.4 mAP) 이지만 tiny/nano와 같은 가벼운 모델은 제공되지 않으며,
edge 시스템을 위한 경량 모델의 경우 yolox가 유리한 것으로 나타난다.
나의 경우 타겟 device 의 퍼포먼스를 고려해야 하기때문에 yolox를 선택했다.
- Nvidia Jetson Xavier NX/TX2
- Ambarella CV25/CV22
+포스팅 작성 시점에서는 yolox 분석 및 적용(torch, tensorrt)을 완료하였는데, xavier nx 의 성능이 기대 이상였고, 결과적으로 yolox-X 모델을 적용하게 되었는데, L 이상의 모델은 경량모델으로 보기 어렵고 YOLOR의 가벼운 모델을 적용하는 것이 더 나은 선택이였을 것 같다.
결과적으로 yolox는 기존 모델인 yolo v5보다 빠르고 정확했으며, 논문에서 주장하는 빠른 수렴속도, anchor free의 장점, small size obj 검출 등 모든 면에서 우수했다.
3. YOLO X 논문 간단 리뷰
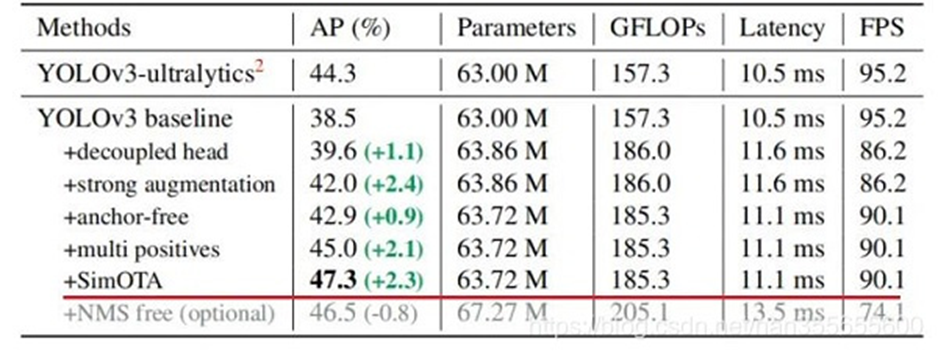
위 테이블을 보면 yolox는 yolov3 baseline에서 추가된 아이디어로 38.5 mAP에서 47.3mAP로 성능을 크게 끌어올렸다.
각 기법이 독립적으로 적용되지 않은 것도 있기때문에 적용 시 정확도 증가(초록색+ 값)은 정확하지 않을 수 있다.
yolox의 경우 anchor free 기반으로 anchor 기반에 최적화된 yolov4, yolov5가 아닌 yolov3(spp)를 base로 하였고, 강력한 augmentation 기법과 anchor-free 가 특징이다.
다양한 기법을 적용해 성능을 끌어올리는 yolo의 철학이 느껴진다.

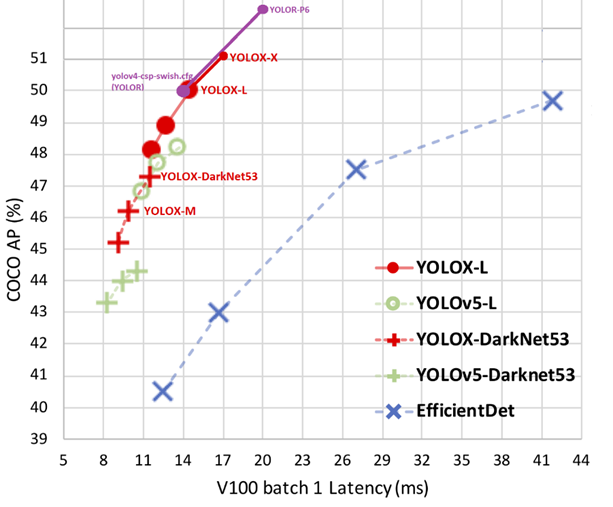
위 그래프를 보면 YOLOX-L(=yolov4-csp-swish yolor) 모델부터는 yolox를 적용하는것 보다는 yolor을 검토하는 것이 좋다.
단, yolor은 논문이 난해하며 핵심 아이디어만 설명되어있으므로 분석하기가 매우 어렵다.
앞서 설명했지만 적용하고자 하는 하드웨어의 성능에 따라
(실시간 필요 시 25fps를 만족하는 범위 내에서)
yolox-L 이상 모델을 적용할 것인가? 유무가 중요한 선택이 될 것이다.
※ 2022년 7월을 기준으로는 상황이 다르다.
yolov6(2022.06) / yolov7(2022.07) 출시로 인해...
yolov7은 현재까지나온 모든 실시간 검출 알고리즘과, 실시간이 아닌 rcnn, transformer 계열의 대부분의 알고리즘 성능을 뛰어넘는다.
다시 돌아와 yolox에 적용된 기법을 살펴보면,




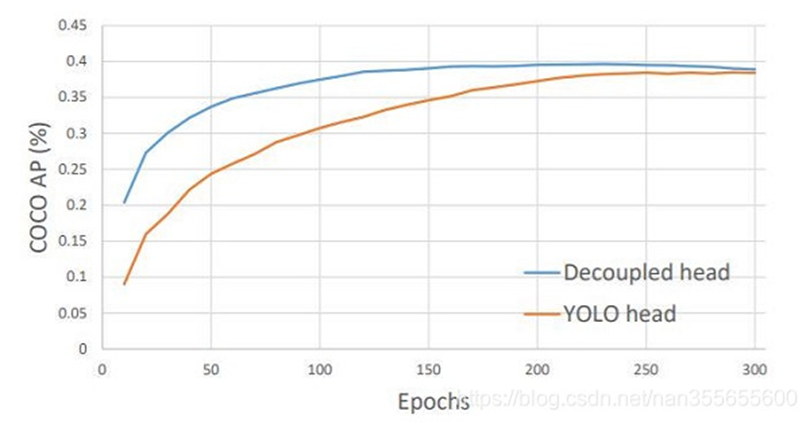
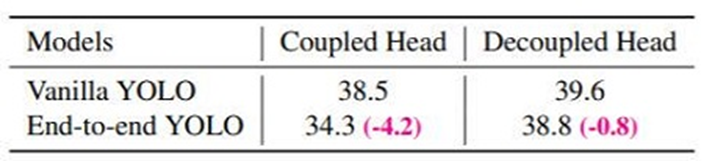
backbone과 nect은 기존의 yolov3(spp)와 동일하고 head가 분리되었다.
head를 분리하므로써, 학습 수렴속도를 향상하고 mAP가 계선되었다.
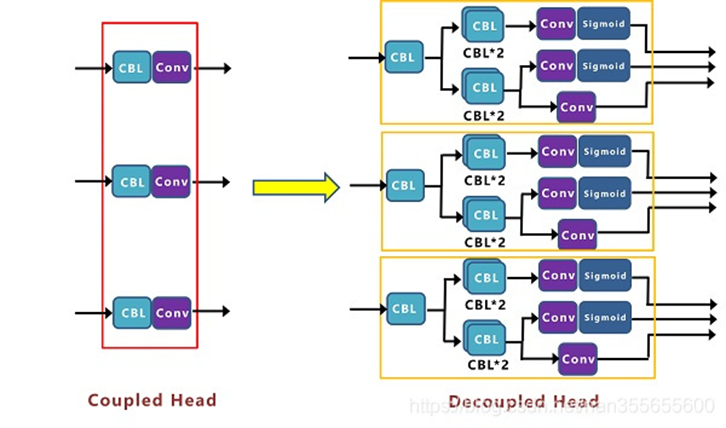
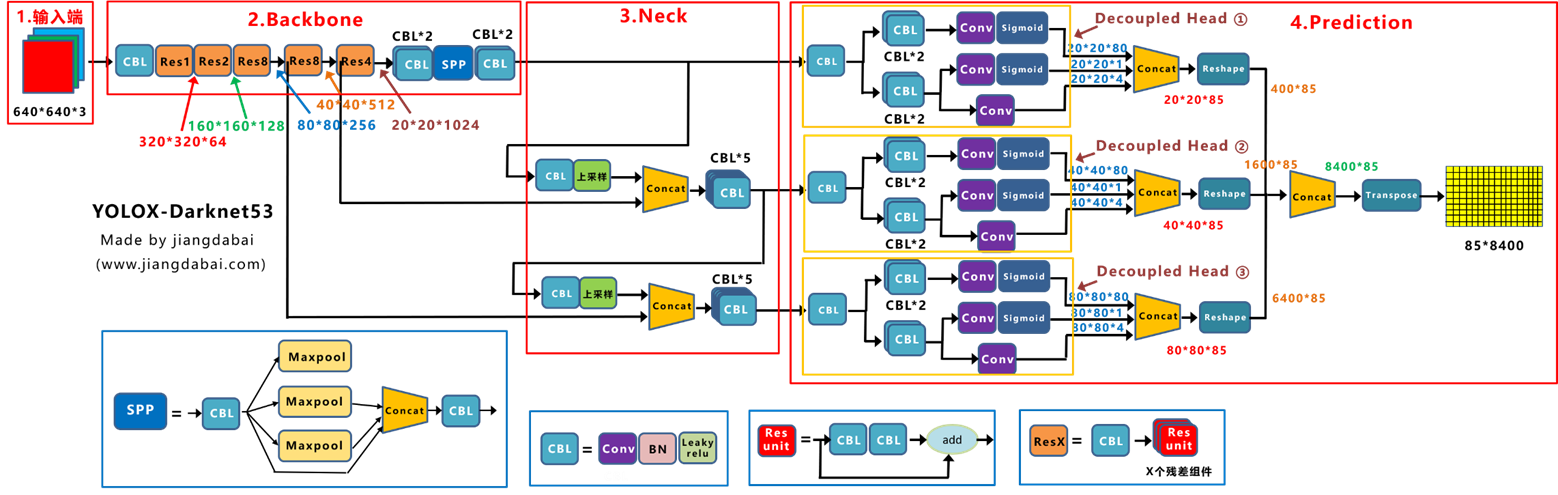
모델의 전체 구조를 도식화한 그림이다.
netron을 통해 모델의 구조가 도식화된 그림과 동일한 것을 확인했다.

- Anchor free

yolov3(416x416)의 경우 3가지 스케일에 대해 하나의 셀에서 3개의 앵커 즉,
YOLOv3(416) Anchor =
3×(13×13+26x26+52x52)×85 = 904,740
의 앵커가 생성되지만.
Anchor free 방식으로 하나의 셀(또는 grid) 에서 1개의 anhor를 계산하는 yolox에서는 yolov3 대비 1/3개의 앵커를 생성한다.
즉 동일한 사이즈(416)라 가정하면,
(13×13+26x26+52x52)×85 = 301,580
개의 앵커가 생성된다.
또, 모델 학습전 개발자가 미리 적절한 앵커 사이즈(비율)을 계산해야하는 번거러운 과정도 생략된다.
간단 리뷰라서 생략하지만 SimOTA와 multi-positives 또한 yolox의 핵심 기술이라고 볼 수 있다.
(anchor 기반에 비해 anchor-free 기반의 recall이 떨어지는 단점을 개선하기 위한 아이디어들..)
아래는 anchor 기반과 ahhor free 기반의 차이를 정리한 그림이다.

여기까지 정리하고, 다음 포스팅은 실제로 YOLOX를 학습하는 과정에서의 시행착오 및 새롭게 알게된 점 등을 정리할 예정이다.
