1. YOLOX 공개 모델
YOLOX에서 공개한 모델은 경량 모델인 nano, tiny와 yolov3(spp)의 백본인 darknet53, s, m, l, x 모델로 구성된다.
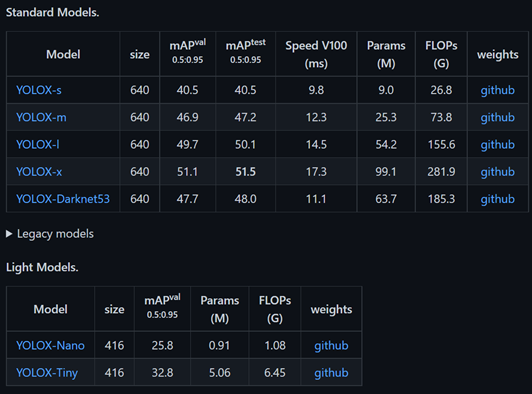
coco dataset에 대한 mAP 결과를 보면 V100 기준 속도가 비슷한 YOLOX-m 모델과 YOLOX-Darknet53 모델의 mAP가 0.8로 유의미한 차이를 보인다. 즉, yolox-darknet53 모델은 yolov3와 비교하여 yolox 논문의 우수성을 확인하기 좋으며, acc/process time 그래프에서 타 yolo 시리즈와 비교해서 장점을 주장하기에도 가장 적절한 모델로 볼 수 있다.
yolox-darknet53의 Neck FPN만 적용되고,
s,m,l,X 모델은 FPN+PAN이 적용되는데 왜 m 모델보다 darknet53의 결과가 좋은건지 의문이다. 아마 darknet53의 백본 구조가 yolox의 스케일 백본 구조보다 효율적일 수도 있겠다.
yolov5에서 도입된 depth/width scale 파라미터를 통해 간편하게 Set surgery 할 수 있다.
2. YOLOX 커스텀 학습
yolox의 학습 명령어는,
$ python tools/train.py -f /path/to/your/Exp/file -d 8 -b 64 --fp16 -o -c /path/to/the/pretrained/weights [--cache]
yolox의 커스텀 학습을 위해서는 yolox_root/exps/ 하위의 exp.py 파일을 수정해야하며,
exp.py 파일은 yolox_root/yolox/exp/yolox_base.py 파일의 Exp Class를 상속받고,
학습 관련 파라미터를 수정하는 구조이다.
yaml, cfg 등을 이용하는 타 프레임워크와는 다르지만,
파싱 부분이 없고 소스코드를 직접 수정하는 yolox의 구조가 어렵지는 않았다.
또한 여러 서버를 묶어서 학습하는 기능이 있는데, 사용해보지는 않았다.
yolox의 경우 수렴이 빠르고 데이터에 따라 다르지만 300epoch 기준 하루밖에 소요되지 않았다.
V100x4 서버 기준.
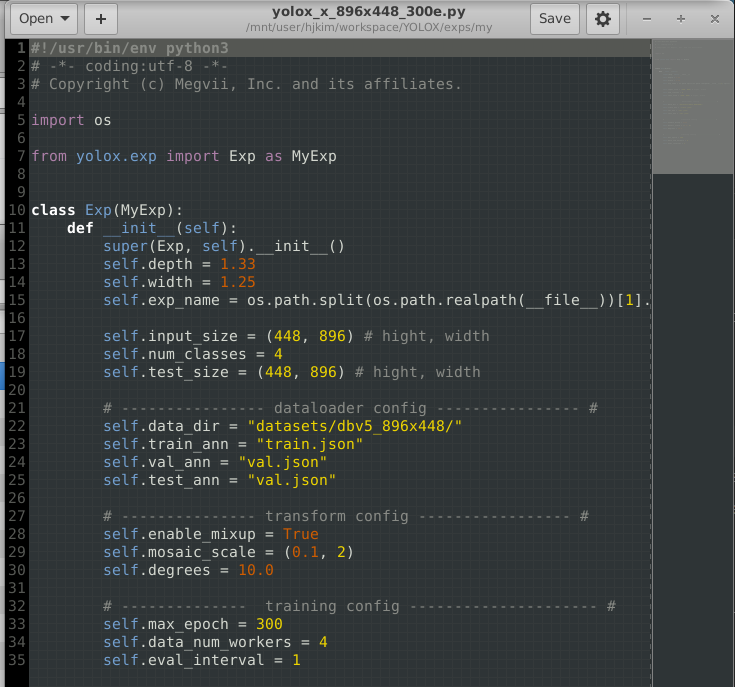
coco 형식의 dataset을 경로에 위치시키고 dataloader 경로 파싱 부분 코드는 직접 바꿔줬다.(폴더관리가 쉽게)
모델이 정방형이 아닐 경우 input_size 파라미터를 설정해줘야하며, (hight, width) 순서에 주의해야한다.
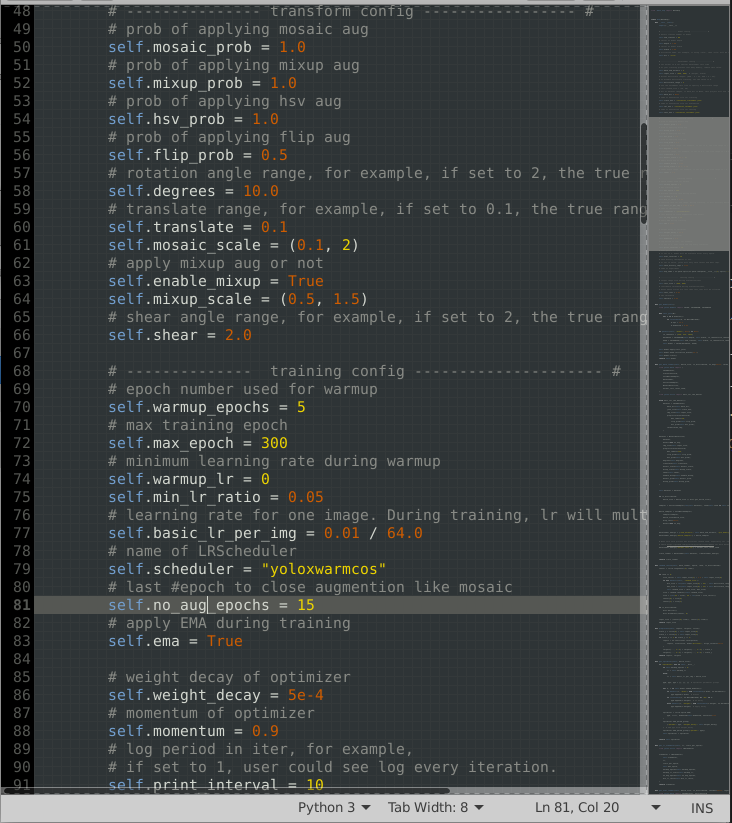
yolox root/yolox/exp/yolox_base.py 파일에서 no_aug_epochs 파라미터를 주의해야하는데, 그 이유에 대해서는 뒤에 설명하겠다.
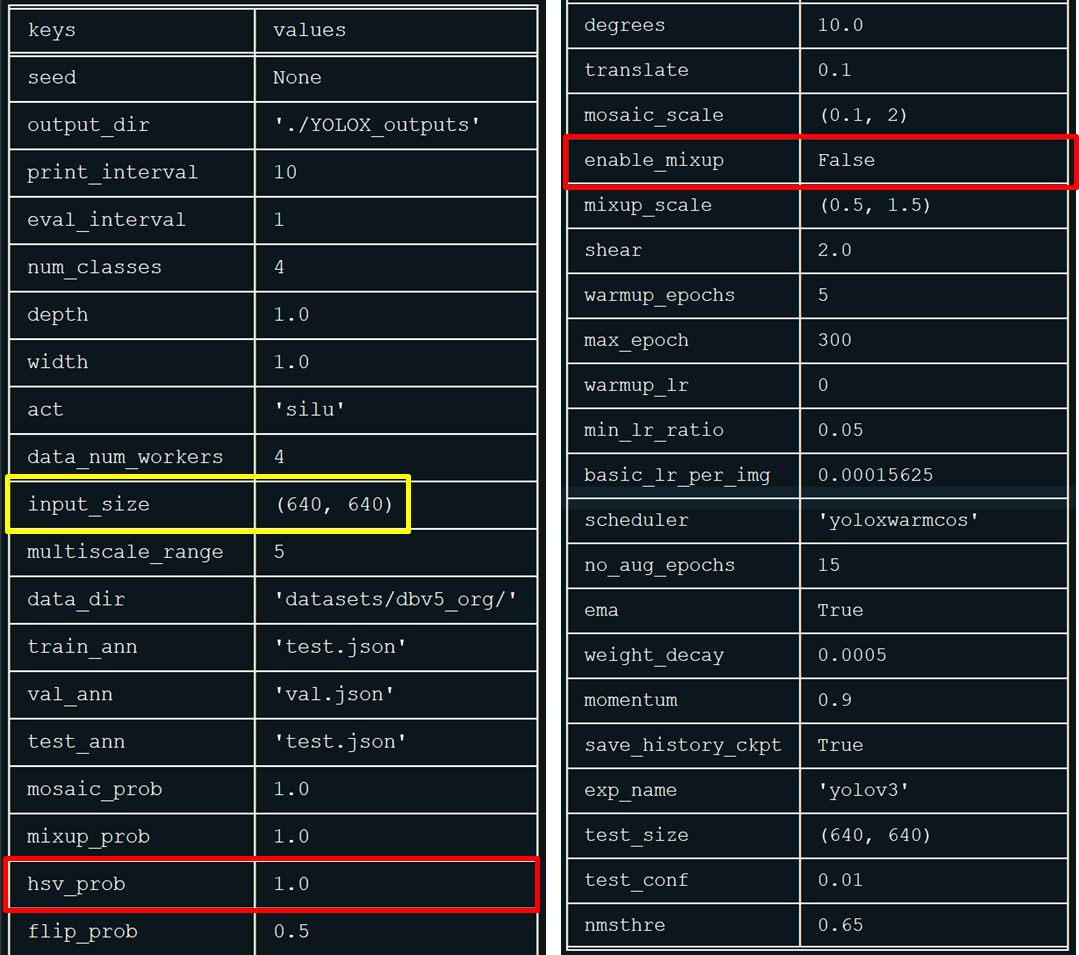
학습을 시작하면 하이퍼파라미터가 출력된다.
3. yolox strong augmentation
나의 경우 커스텀 데이터셋의 경우 gray 채널이기 때문에 hsv augmentation을 h, s 변경 부분은 주석처리하고 value. 즉, brightness 만 변경되도록 코드를 수정해줬다.
augmentation 관련 코드는 yolx_root/yolox/data/data_augment.py에 위치한다.
여기서 코드를 수정하여 augmentation 이미지를 저장하여 확인할 수 있다.

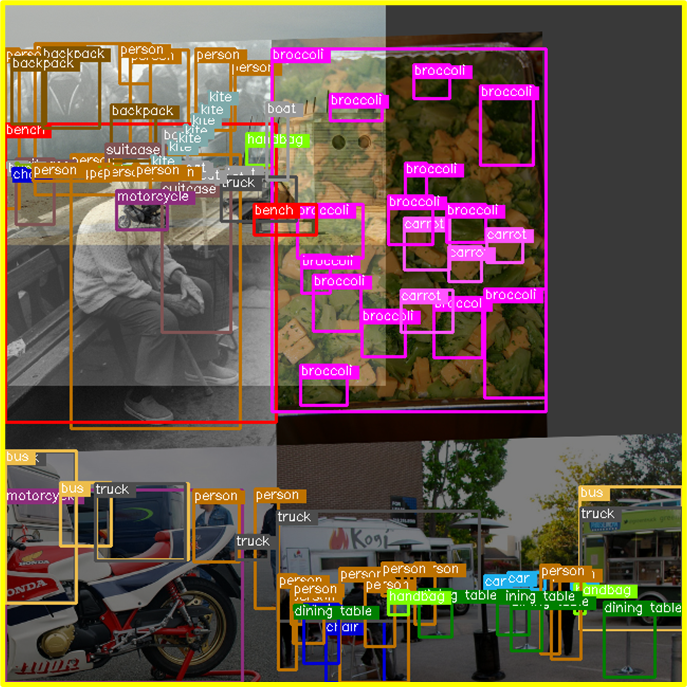
위 2장의 이미지는 coco 데이터셋에 대한 기본설정 값 augmentation 결과이다.
yolox에서는 mixup, mosaic porb 가 모든 이미지에 적용되는데,
mixup의 경우, 기준 이미지 1장에 mosaiced image(4 images)가 1:4 로 mix되며. 1에 해당하는 기준 이미지는 좌상단(0,0)에서 시작하여 확대/축소 resize. rotation은 적용되지 않은 상태로 조합된다.
mixup은 다양한 배경과 obj가 섞여. 일반화 관점(ex. 냉장고 안의 코끼리)에서 학습이 더 잘되는(classification 개선) 효과가 있다.
아래 이미지는 mixup을 off 시킨 결과.

커스텀 데이터셋의 경우 극단적으로 augmentation이 적용되어 obj들이 가장자리에 몰리고, 비정상적인 바운딩 박스가 너무 많이 발생하는 문제가 예상된다.
(실제로도 문제가 있다. 4장에서 설명.)


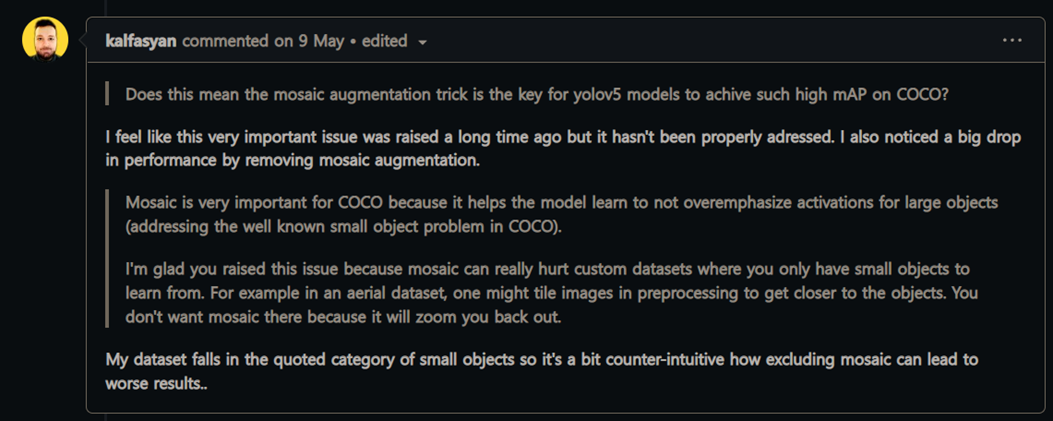
아래는 극단적인 예로 mosaic 적용을 하면 안되는 데이터셋이다.

위의 위성데이터셋 처럼 obj가 매우작은 경우 mosaic4 적용 시 사이즈가 4/1로 작아지게되며, 마지막 피쳐맵의 gird size 보다 작을 경우 학습이 아예 안될 수 있다.
4. yolox 학습 시 주의사항
3장에서 yolx augmentation된 이미지들의 경계가 너무 심하게 잘리고 망가지는 문제를 지적했는데. yolox의 augmentation 방식을 보면, mosiac 적용 전 각각의 이미지에 아래와 같이 cutout이 적용되는데,


경계영역의 bounding box 문제를 해결하기 위해 나름의 아이디어가 들어가있다. 이미지 dimension을 고려한 cutout.

그러나 여기서 rotation도 들어가고.. 스케일 축소도 들어가는데. NVS 특성상 가장자리에 오브젝트가 많고, 작은 오브젝트가 많은 우리 데이터셋에는 적절하지 않은 것 같다.
즉, coco 데이터셋에는 잘 맞지만 우리 데이터셋에는 적합하지 않다는 것!
예상되는 해결방안은,
1) aug 파라미터를 약하게 조정하는것
2) yolox aug 방식을 수정하는것(cutout 알고리즘 수정)
3) 가장자리의 경계상자는 loss 계산 시 무시하거나, 아예 이미지 자체를 pass하도록 수정.
3) 방식에 대한 언급은 yolov5 repo의 issue에서 찾을 수 있었다.

부정확한 경계상자 문제.
꼬리와 뒷다리만 보이는 개의 부분을, 개로 볼 것인가? 는
프로젝트의 요구사항에 따라 다를 것이다.
단순하게 생각했을때 이러한 cropping Issue는 recall은 증가시키고 fppi 오검출 또한 증가시키는 작용을 할 것이다.
그리하여...
yolox에서도 issue를 검색해본 결과, 아래의 답변을 찾았다.
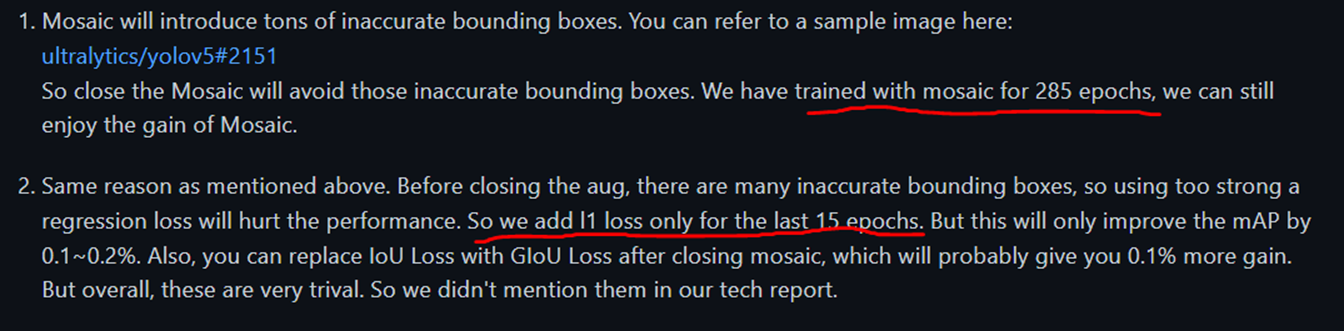
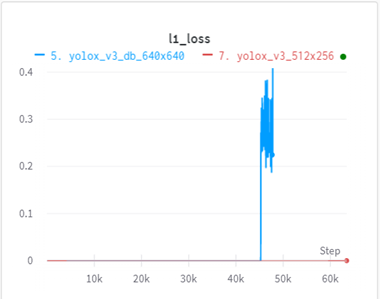
즉, yolox에서는 전체 300epoch중 285 epoch은 mosaic/mixup을 포함한 강력한 augmentation을 적용하고, 마지막 15epoch에서는 off 시켜 학습한다는 것.
로스함수 또한 bce에서 l1으로 변경된다.
대부분의 학습에서 augmentation의 장점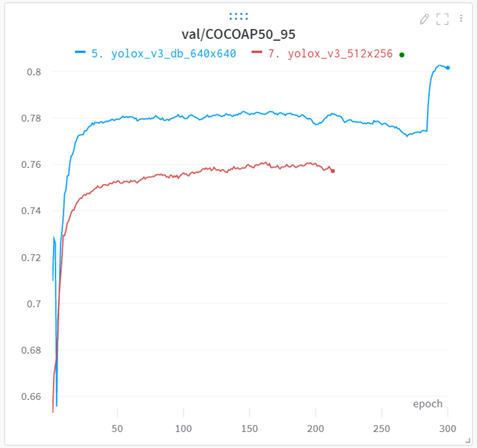
을 취득하고, 마지막에 다듬으면서 0.1~0.2%의 mAP 개선효과를 얻을 수 있다고 한다.
나의 데이터셋의 경우 마지막 15epoch에서의 변화가 정량적으로도 크게 차이나고, 동영상 평가에서의 차이는 더 심했다.
예를들어 동일한 mAP의 150epcoh 모델과, aug off가 작동한 290epoch을 비교하면 150epoch 모델은 아래와같이 정말 이상한 오검출이 많이 발생한다.

obj가 없는 하늘과 건물에 발생하는 오검출은 mixup으로 인해 발생한 것으로 추측한다.
마지막 epoch에서 이러한 현상을 제거하는 yolox의 방식이 신선했다.
1) 극단적인 augmentation으로 학습 후, no_aug 학습.
2) aug_prob를 밸런스있게 조정하여 처음부터 끝까지 학습.
두가지 학습전략에 따른 차이도 분석해볼 필요가 있을 것 같다.
이렇게 보면 yolox의 기본설정 학습시, ~285 epoch은 비정상적인 모델이고 last 15 epoch을 선택해야하는데, github/paper에는 이러한 내용이 없다.
이 문제 때문에 1달정도 시간을 허비한 것 같다.
모델은 100epoch 전에 수렴하는데 원인을 알 수 없는 오검출과, 이 모델을 tensorrt 변환 시에는 증상이 더 심해지는 것...
yolox를 학습할때 가장 중요한 부분이라고 생각한다.
메그비 yolox repo는 doc에 이러한 내용을 추가할 필요가 있다.(귀찮아서 이슈제기 안함)
