모델 경량화를 위한 Pruning 적용 방법
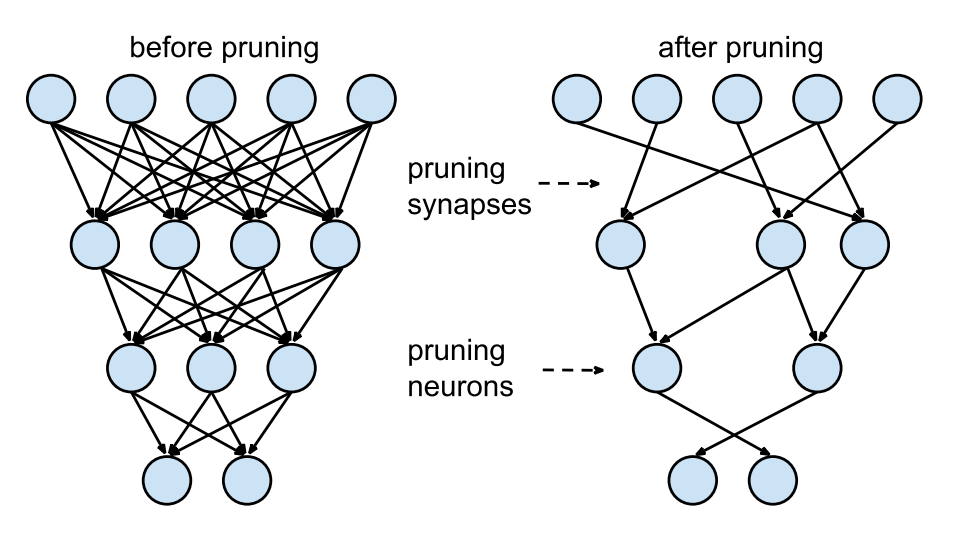
NPU 제조사에서 pruning을 지원하지 않는 경우, 다음과 같은 방법을 통해 Pruning을 적용할 수 있습니다:
1. PyTorch 기반 Pruning
PyTorch에는 다양한 pruning 기법을 지원하는 torch.nn.utils.prune 모듈이 있습니다. 이를 통해 네트워크의 특정 가중치 또는 필터를 제거할 수 있습니다.
2. Pruning 후 ONNX 변환
Pruning이 적용된 PyTorch 모델을 ONNX로 변환하여 후속 양자화를 수행할 수 있습니다.
Pruning 적용 절차
- PyTorch에서 Pruning 적용: 모델의 특정 레이어에 pruning을 적용하고, 중요한 가중치만 남겨두는 방식으로 수행됩니다.
- Pruning 후 재학습 (Fine-tuning): Pruning 후 모델의 성능을 회복시키기 위해 재학습을 진행합니다.
- ONNX로 변환: Pruning이 적용된 모델을 ONNX 형식으로 변환합니다.
- 양자화: ONNX 모델을 NPU 제조사 SDK를 이용하여 INT8 양자화 모델로 변환합니다.
Pruning 적용 예제 (PyTorch)
import torch
import torch.nn.utils.prune as prune
import torch.nn.functional as F
import torchvision.models as models
# 모델 불러오기
model = models.resnet18(pretrained=True)
# 프루닝 적용 예시 (conv1 레이어에 50% 프루닝 적용)
prune.l1_unstructured(model.conv1, name='weight', amount=0.5)
# 프루닝 적용 후의 모델 가중치
print(list(model.named_parameters()))
# 프루닝 후 fine-tuning을 위해 재학습
# 예제이므로 데이터로더와 학습 루프는 생략
for epoch in range(10): # 예제 학습 루프
for inputs, targets in train_loader:
outputs = model(inputs)
loss = F.cross_entropy(outputs, targets)
loss.backward()
optimizer.step()Pruning과 Quantization 순서
일반적으로 Object Detection 모델 경량화에서는 다음 순서를 따릅니다:
- Pruning: 모델의 불필요한 가중치를 제거하여 모델을 경량화합니다. 이를 통해 모델의 크기를 줄이고 추론 속도를 높일 수 있습니다.
- Quantization: Pruning이 적용된 모델을 INT8 양자화하여 더욱 경량화하고 NPU 등에서 효율적으로 추론할 수 있게 합니다.
결론
- Pruning과 Quantization 절차: 일반적으로 Pruning을 먼저 수행한 후 Quantization을 진행합니다. Pruning을 통해 모델의 크기를 줄이고, 이후 Quantization을 통해 더 높은 추론 성능을 달성할 수 있습니다.
- Pruning 지원이 없는 경우: PyTorch와 같은 딥러닝 프레임워크에서 제공하는 Pruning 기능을 활용하여 모델을 경량화한 후, NPU 제조사의 SDK를 통해 Quantization을 수행합니다.
이러한 절차를 따르면 다양한 NPU에서 효율적으로 Object Detection 모델을 배포할 수 있습니다.

Computer Vision / ADAS / DMS / Face Recognition