- ICML 2025 oral
- https://arxiv.org/abs/2502.02013
목표:
LLM 응용에서는 “최종 레이어가 가장 좋은 표현”이라는 관행이 널리 퍼져 있음. 저자는 이에 의문을 제기하며, “과연 마지막 레이어가 항상 최적일까?”라는 질문을 던짐. 그리고 “왜 마지막 레이어가 아니라 중간 레이어 임베딩이 더 좋은가?”를 행렬 기반 엔트로피(Matrix-based Entropy)라는 하나의 논리로 설명하고, 실험 결과/실무적 함의를 자연스럽게 연결.
0. 핵심 메시지 (Key Takeaways)
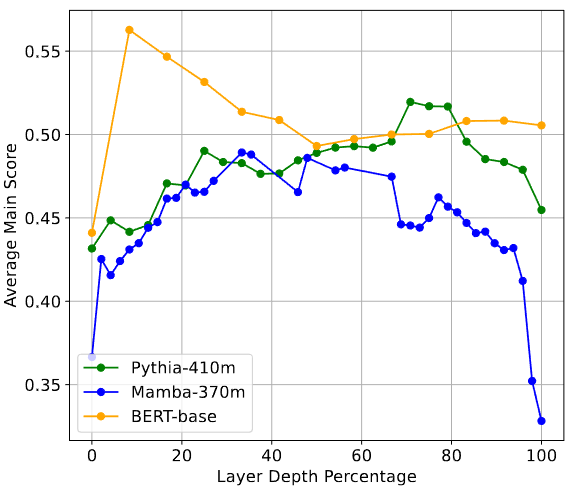
모델 깊이별 MTEB 점수- MTEB(Massive Text Embedding Benchmark) 32개 태스크 실험 결과, 중간 레이어 임베딩이 마지막 레이어보다 최대 16% 더 높은 정확도를 기록했습니다.
- 압축 vs 보존의 균형: 성능 피크는 단순히 깊이의 문제가 아니라, 불필요한 노이즈를 제거하는 압축(Compression)과 핵심 의미를 남기는 보존(Signal Preservation) 사이의 균형점에서 발생합니다.
- 통합 렌즈(Matrix-based Entropy): 압축 정도, 기하학적 형태(곡률), 변형에 대한 강건함(불변성)이라는 서로 다른 지표들을 Gram 행렬의 고유값 분석을 통해 하나의 이론적 틀로 묶어 설명합니다.
1. 문제 설정: 왜 ‘마지막 레이어’가 항상 최선이 아닐까?
- 대부분의 LLM 응용은 마지막 레이어(최종 레이어)의 hidden state를 “가장 고급 의미 표현”으로 간주
- 최종 레이어는 종종 사전학습 목표(예: next-token prediction)에 과도하게 특화될 수 있음
- 즉, “일반적 의미 표현”보다 목표에 맞춘 표현(목적함수 최적화에 유리한 방향)으로 치우칠 위험
2. 이론적 프레임워크 (Theoretical Framework)
이 연구의 가장 큰 기여는 겉보기에 다른 여러 임베딩 성능 지표를 하나의 행렬 기반 엔트로피 수식으로 수학적으 통합했다는 점.
2.1. 행렬 기반 엔트로피
-
: 특정 레이어로부터 뽑은 차원 임베딩 벡터가 개 있을때, 로 표현 가능한 임베딩 행렬 (임베딩 벡터들의 절대좌표)
-
: 로 임베딩 벡터의 유사도 행렬 → 임베딩 벡터들간의 상대적 좌표
-
고유값 ()과 정규화 ():
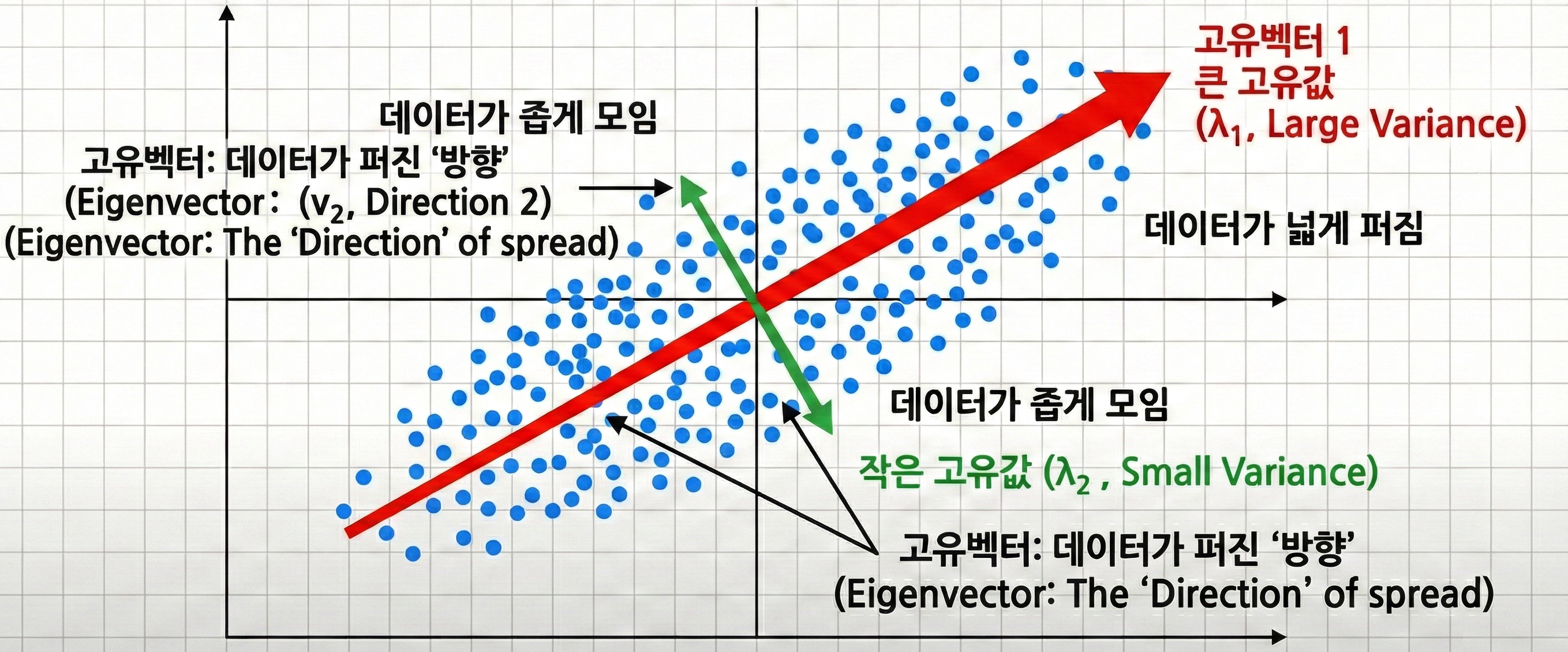
- 고유값 (): 데이터가 특정 축(Principal Axis) 방향으로 얼마나 길게 퍼져 있는지를 나타내는 '크기'
- 수식에서의 의미 : 토큰들이 특정 의미 축 방향으로 얼마나 길게 퍼져 있는지 나타내는 값
- 가 큼 → 비슷한 토큰들이 뭉쳐서 강력한 하나의 의미(축)을 형성함
- ≈ 0임 → 의미 있는 축으로 성장하지 못하고 무시됨 (노이즈로 남음).
- 참고: 유효한 고유값의 개수는 를 넘을 수 없음. (차원의 한계)
- 정규화: 수식 내부의 부분은 고유값들의 합이 1이 되도록 나누어 주는 과정. → 확률값으로 변환
-
엔트로피 계산 ():
- 정규화된 고유값(확률) 분포를 하나의 엔트로피 값()로 환산하는 레니 엔트로피(Rényi Entropy) 공식
2.2 이론의 확장: 엔트로피가 말해주는 3가지 관점 (The Unified View)
본 연구는 Gram 행렬()의 속성(고유값 분포와 원소값)을 분석함으로써, 표현 품질의 3대 요소인 압축, 기하, 불변성을 통합적으로 설명함.
① 정보 이론적 관점 (Information): "압축과 다양성"
질문: 표현이 얼마나 풍부한가(Preservation), 혹은 얼마나 요약되었는가(Compression)?
핵심은 의 고유값 스펙트럼()임.
- High Entropy: 고유값이 골고루 퍼짐 모든 토큰이 각자의 의미를 유지 (Raw Data에 가까움).
- Low Entropy: 고유값이 소수로 쏠림 데이터가 몇 개의 주성분으로 압축됨 (추상화됨).
평가지표
- Prompt Entropy: 단일 문장 내 토큰들의 다양성. 단일 문장의 임베딩 벡터 를 활용해 계산.
- 의미: 토큰들이 임베딩 공간에서 얼마나 넓게 퍼져있는지(다양성/중복도) 측정
- Dataset Entropy: 전체 데이터셋의 수준의 다양성. 여러 프롬프트 N개를 모아서, 각 프롬프트의 mean token embedding(토큰 평균 임베딩) 하나씩 뽑아 를 만들고, 거기에 엔트로피를 적용한 값
- 의미: 모델이 서로 다른 입력(프롬프트)들을 얼마나 잘 구분해서 떨어뜨려 놓는지 보는, 전역(global) 다양성 지표
- Effective Rank :
- 의미: 임베딩 행렬 Z가 실제로 몇 개 “유효한 방향(차원)”을 쓰고 있는지 보는, 일종의 유효 차원 수 느낌의 지표 → 표현이 강하게 압축되면(entropy↓) → effective rank도 줄어드는 방향
② 기하학적 관점 (Geometry): "공간 상의 궤적"
질문: 토큰이 임베딩 공간에서 어떻게 움직이는가?
핵심은 의 원소값()임. 내적은 곧 각도(Cosine Similarity)를 의미함.
평가지표
-
Curvature (곡률): 문장이 진행될 때 임베딩 벡터가 꺾이는 각도
- 곡률 높음: 토큰마다 방향이 급변함 → 표현이 더 국소(local) 신호(표면 형태/근접 토큰 변화)에 민감한 편임.
- 곡률 낮음: 궤적이 더 부드럽게 이어짐 → 더 전역(global) 문맥에 맞춰 정렬된 표현이라는 신호임.
- 발견: 중간 레이어는 국소 정보와 전역 문맥이 조화된 적절한 곡률을 가짐.
③ 불변성 관점 (Invariance): "노이즈 저항력"
질문: 입력을 살짝 바꿔도(오타/동의어) 표현이 유지되는가?
핵심은 섭동(Perturbation) 전후 Gram 행렬의 안정성임.
평가지표
- InfoNCE:
- (원본, 증강본)은 가깝게, (다른 샘플)은 멀게 만드는 대조학습 목적 함수.
- 이론적으로 InfoNCE 손실 최소화는 Dataset Entropy 최대화와 연결됨.
- 는 데이터셋 수준의 행렬 기반 엔트로피( )로 해석될 수 있음.
- 즉, 불변성이 높다는 건, 노이즈()는 버리고 핵심 정보()는 지켰다는 뜻.
- LiDAR (Linear Discriminant Analysis Rank):
- 증강된 샘플들이 클래스(원래 프롬프트) 내에서 얼마나 뭉쳐있는지(응집도) vs 다른 프롬프트와 얼마나 떨어져 있는지(분리도)를 측정.
- LiDAR 점수가 높을수록 증강본이 안정적으로 한 덩어리를 만들고 다른 샘플과 잘 분리됨을 의미.
- DiME (Difference of Matrix-based Entropy):
- 행렬 기반 엔트로피를 직접 활용하여, "원본-증강 데이터 쌍"의 엔트로피와 "원본-무작위 데이터 쌍"의 엔트로피 차이를 계산.
3. 핵심 실험 결과 (Empirical Results)
3.1 "The Middle Peak" 현상
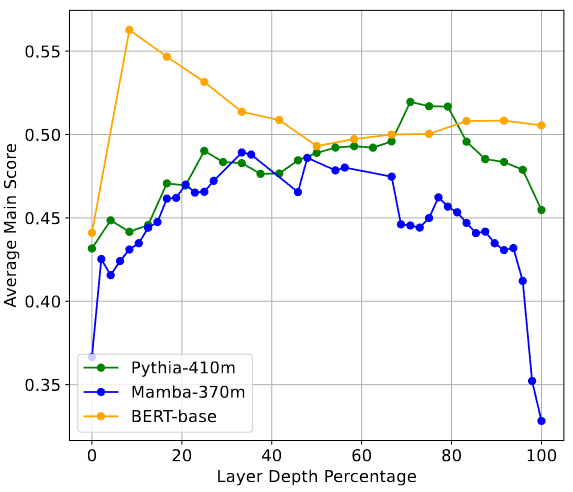
모델 깊이별 MTEB 점수- 실험: Pythia, Mamba, BERT 등 다양한 아키텍처로 MTEB 32개 태스크 수행.
- Average Main Score : MTEB 벤치마크의 32개 하위 태스크(분류, 클러스터링, 재순위화, 검색 등) 각각에서 측정된 주요 평가 지표(예: Accuracy, NDCG, Spearman Correlation)를 모두 합산하여 평균 낸 종합 점수.
- 결과: 거의 모든 모델, 모든 태스크에서 중간 레이어가 최종 레이어를 압도함.
- 평균 성능 향상: 2% ~ 16%.
3.2 지표와 성능의 상관관계
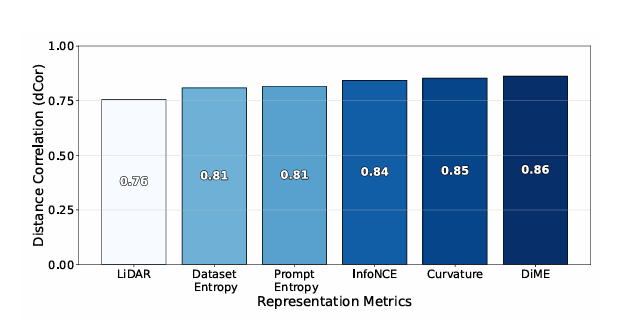
- 2절에서의 6개 지표(특히 Curvature, DiME, InfoNCE)가 실제 성능과 매우 강한 상관관계()를 보임.
- Unsupervised Layer Selection:
- 정답 라벨 없이도, DiME/InfoNCE 점수만으로 "어느 레이어가 최고인지" 찾아낼 수 있음.
- 실제 Pythia-410M에서 이 방식으로 레이어를 선택했을 때 평균 3% 성능 향상 확인.
4. 심층 분석: 아키텍처와 학습 (Deep Dive)
4.1 아키텍처별 "압축 계곡 (Compression Valley)"
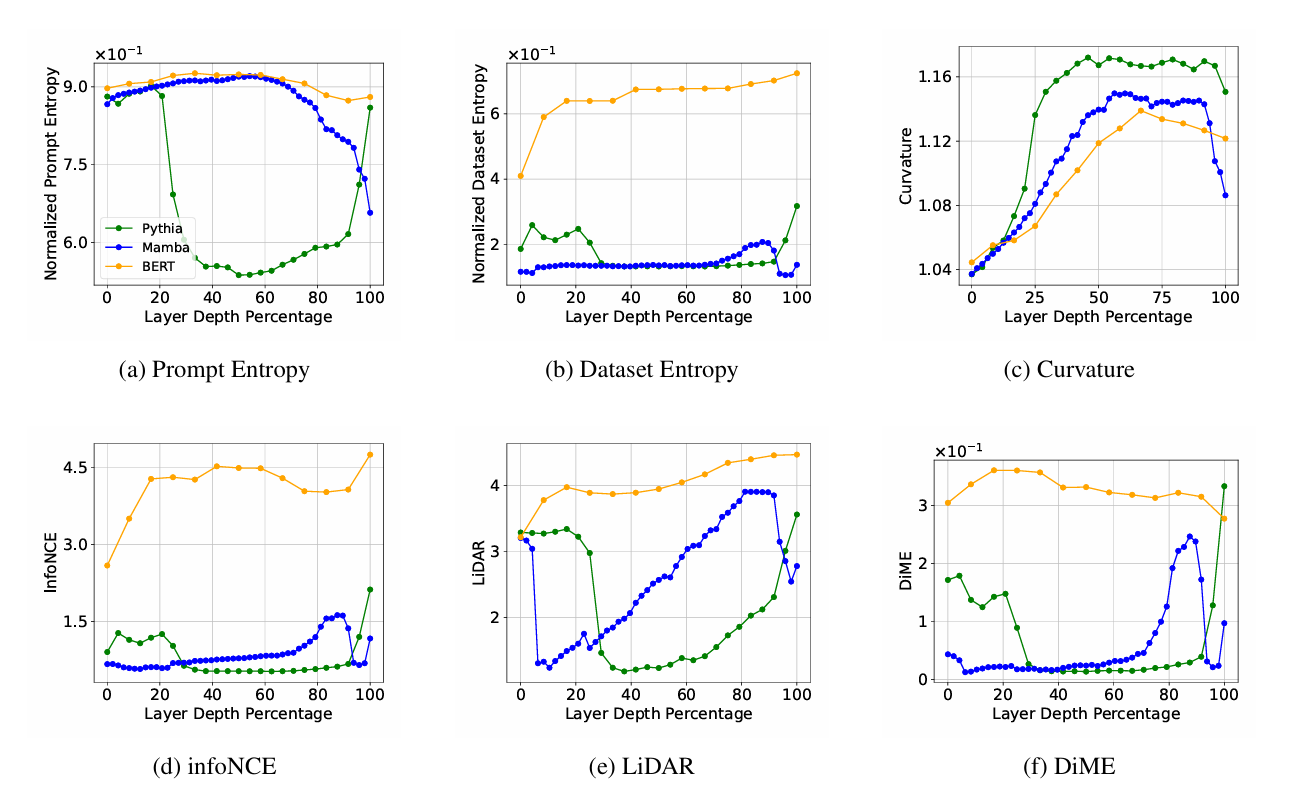
-
4.1.1 Encoder vs Decoder vs SSM: 압축 패턴의 차이
- BERT(인코더, 양방향): 전체 토큰을 한 번에 봄. 레이어 지나도 엔트로피 높게 유지됨. “버릴 게 적다”는 뜻이라 급격한 병목 없음.
- Pythia(디코더, 자기회귀): 중간 레이어에서 프롬프트 엔트로피가 확 꺼지는 딥(dip) 발생.
- 이유: 자기회귀(Autoregressive) 목표가 다음 토큰 예측에 쓸모없는 비국소(non-local) 정보를 중간에서 가지치기(prune)함.
- 결과: 스위트 스팟이 중간 깊이에 생김.
- Mamba(SSM): 변화가 평탄함. BERT(보존)와 Pythia(중간 압축) 사이의 중간 성격 곡선임.
-
4.1.2 스케일이 커질수록 “계곡”은 더 선명해짐
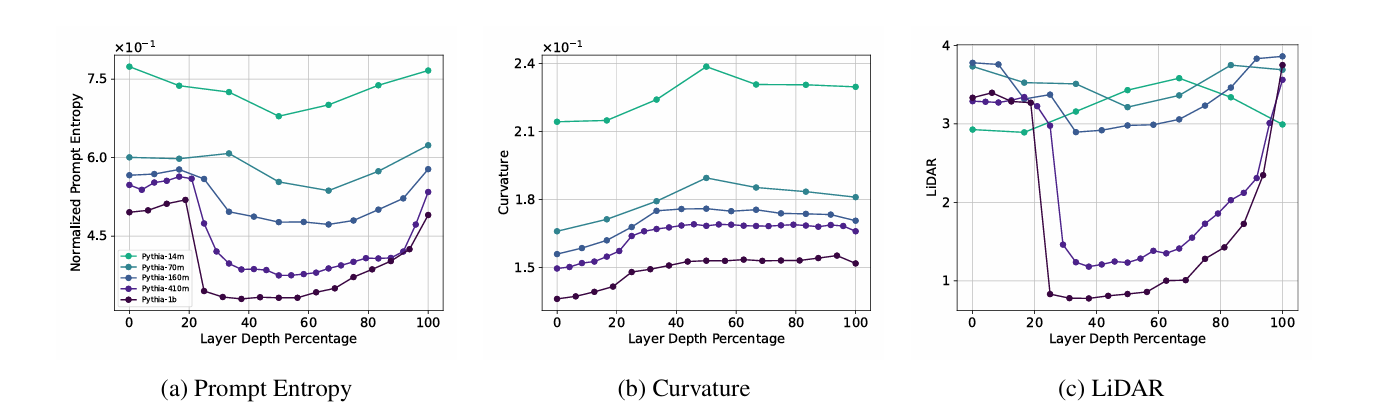
- 큰 모델은 “더 많은 용량”으로 중간 표현을 더 잘 증류(distill)함.
- 동시에 토큰 궤적은 부드러워지고(곡률↓), 증강 불변성은 강해짐(LiDAR↑).
- MBE 관점: 큰 모델일수록 Gram 행렬 고유값 분포가 중간에서 목적지향적으로 재배치됨. “필요한 축만 남기는 압축”과 “다양성 유지”가 동시에 성립함.
-
4.1.3 파인튜닝은 “불변성”을 올리고, 엔트로피 성격을 바꿈
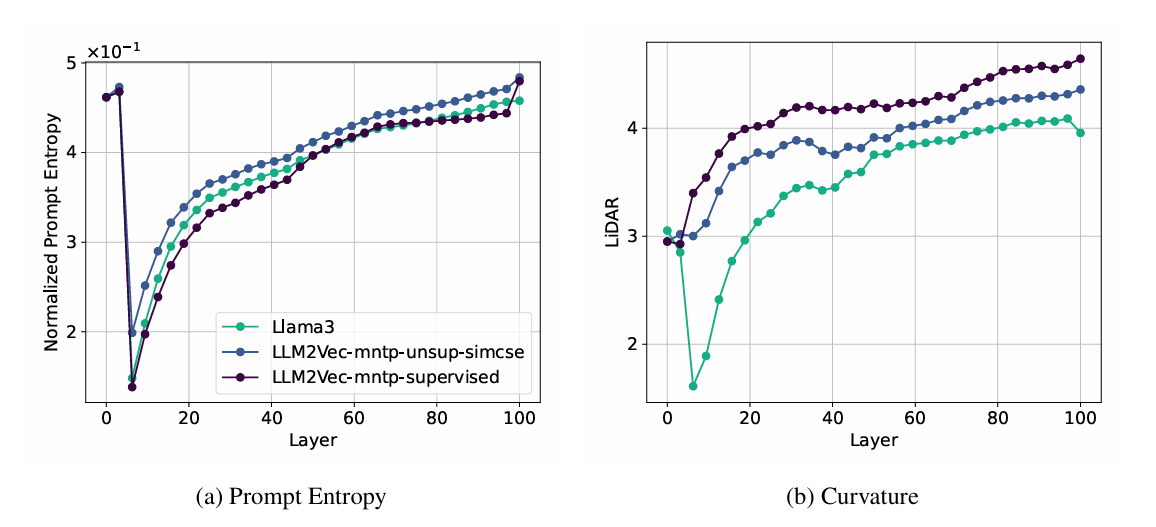
- 두 파인튜닝 모델 모두 증강 불변성(augmentation invariance)이 개선됨
- 그런데,
- 비지도(unsupervised) 모델은 Llama3보다 프롬프트 엔트로피가 더 높고
- 지도(supervised) 모델은 Llama3보다 프롬프트 엔트로피가 더 낮음
- 즉 파인튜닝은 무조건 압축/보존이 아니라, 목표에 따라 고유값 스펙트럼(압축↔보존 균형)을 재형성하는 과정임.
-
4.1.4 트랜스포머 블록 내부: “잔차(residual)가 계곡을 만듦”
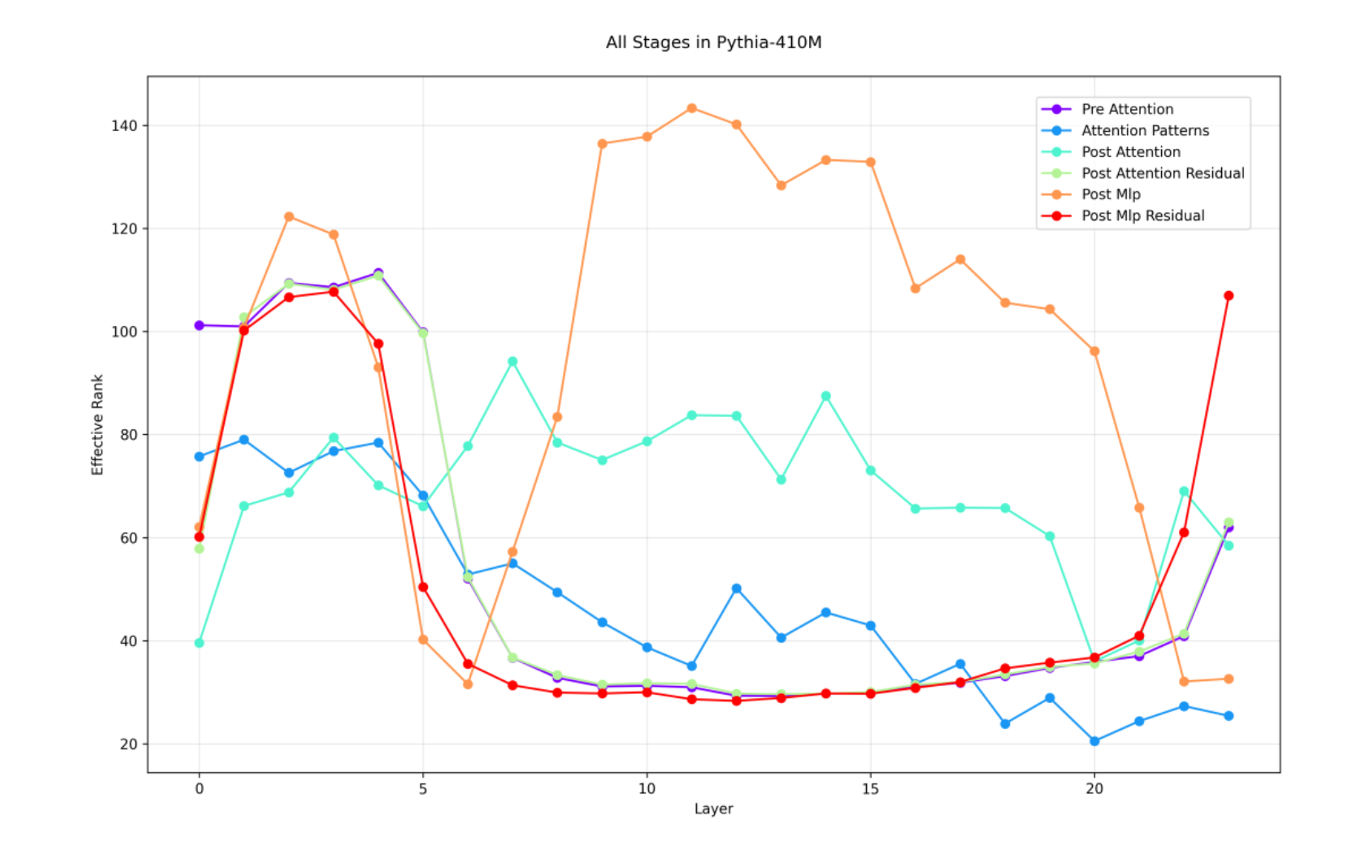
- 레이어를 더 쪼개서(정규화→어텐션→MLP→잔차) 측정해봤을 때:
- 잔차 이전 서브레이어: 압축 계곡없이 그래프가 완만. (Post Attention (청록), Post MLP (주황))
- 잔차 합쳐지는 지점: 중간지점 압축 계곡 발생하는 모습 (=강한 필터링). (Post Attention Residual(연두), Post Mlp Residual (빨강))
- 발견: 정보 압축(Rank 감소)은 MLP나 Attention 직후가 아니라, 잔차 연결(Residual Stream) 단계에서 발생함.
- 레이어를 더 쪼개서(정규화→어텐션→MLP→잔차) 측정해봤을 때:
4.2 학습 진행(Training Progression): 변화는 중간에서 일어남
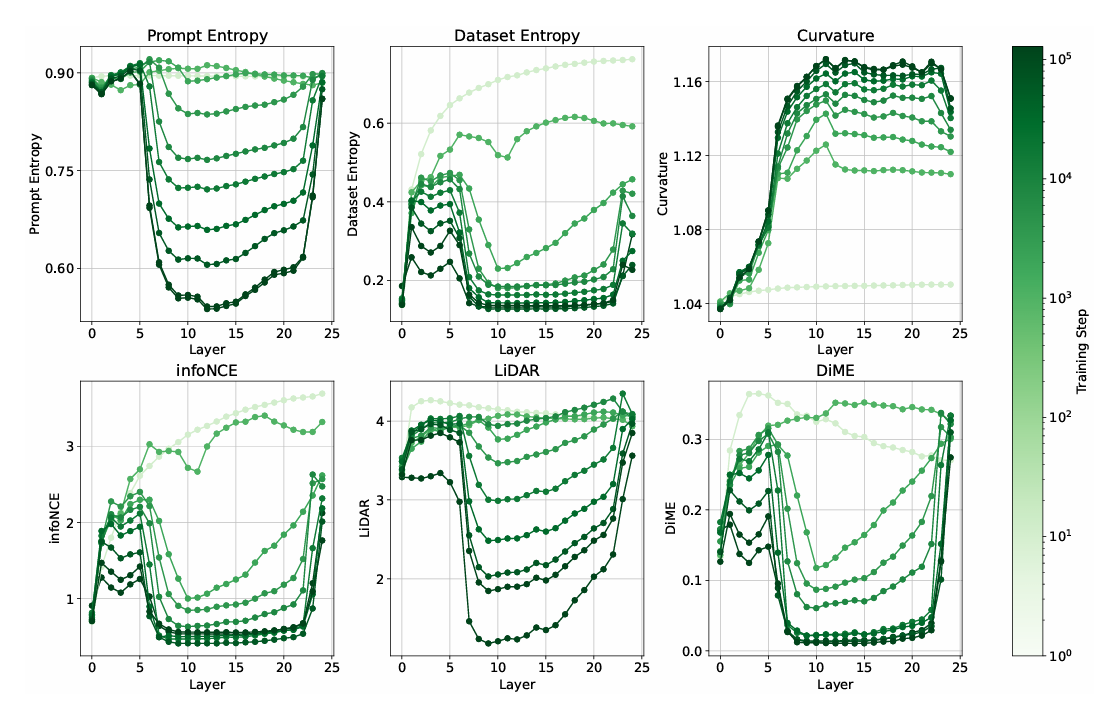
- 체크포인트 따라가며 지표를 확인함.
- 중간 레이어의 변화폭이 가장 큼: 학습 될수록 프롬프트 엔트로피 꾸준히 감소(압축/추상화), 곡률은 더욱 많이 부드러워짐(전역 패턴 학습).
결론: 중간 레이어는 (1) 정보 재구성을 가장 많이 수행하며, (2) 노이즈 제거(압축)와 의미 유지(보존)를 동시에 달성하는 구간이라 성능 피크가 생기기 쉬움
4.3 CoT (Chain-of-Thought) 파인튜닝의 영향
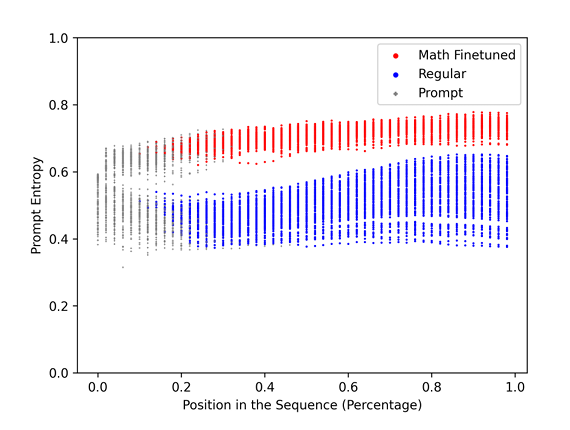
- 비교 실험: Qwen 2.5 (Base) vs Qwen 2.5-Math (CoT Finetuned)
- 발견: CoT 파인튜닝된 모델은 시퀀스가 길어져도 프롬프트 엔트로피를 높게 유지함.
- 해석: 일반 모델은 정보를 빠르게 압축하여 결론을 내리려 하지만, CoT 모델은 다단계 추론을 위해 중간/후반 레이어에서 컨텍스트 정보를 보존(Preservation)하는 능력이 강화됨.
5. 극단적 입력 조건 (Extreme Input Conditions)
- 토큰 반복 (Repetition):
- 입력에 반복 패턴이 많아질수록 중간 레이어 엔트로피 급락.
- 모델이 중복을 인지하고 불필요한 정보를 과감히 압축(Filtering)함.
- 무작위 노이즈 (Randomness):
- 랜덤 토큰 주입 시 초기 레이어 엔트로피 급증.
- 초기 레이어는 입력 변화에 민감하지만, 중간 레이어는 이미 견고함(Robustness)을 확보하여 영향을 덜 받음.
6. 비전 모델(Vision Transformers) 비교
"데이터가 아니라 '목표'가 구조를 만든다"
- 질문: 중간 레이어의 성능 피크는 텍스트 데이터만의 특성인가?
- 실험:
- AIM (Autoregressive): 텍스트 모델(LLM)과 동일하게 중간 레이어 엔트로피 계곡(Valley) 및 성능 피크 관찰됨.
- ViT/CLIP (Non-autoregressive): 레이어가 깊어질수록 성능이 선형적으로 증가 (중간 피크 없음).
- 결론: 중간 레이어의 정보 병목 현상은 자기회귀(Autoregressive) 학습 목표가 만들어내는 고유한 특성임. 미래를 예측하기 위해 과거 정보를 압축해야 하는 압력이 작용함.
7. 결론 및 요약 (Conclusion)
7.1 핵심 요약
- The Middle is Better: 대부분의 LLM, 특히 자기회귀 모델에서 중간 레이어 임베딩이 최종 레이어보다 우수함 (최대 16% 향상).
- Unified Theory: 행렬 기반 엔트로피(Matrix-based Entropy)라는 단일 프레임워크로 압축(Compression), 기하학적 매끄러움(Curvature), 불변성(Invariance)을 통합적으로 설명 가능.
- Mechanism (Sweet Spot):
- 초기 레이어: 토큰을 임베딩으로 변환(Detokenization)하는 과정에서 높은 노이즈를 포함함.
- 최종 레이어: '다음 토큰 예측'이라는 목표에 과도하게 최적화되어, 일반적인 의미 정보(Semantic Info)를 일부 소실하거나 좁은 문맥에 집중함.
- 중간 레이어: 불필요한 노이즈는 제거(Compression)하면서도, 문맥적 의미는 풍부하게 유지(Preservation)하는 최적의 균형점(Sweet Spot)을 형성함.
7.2 실무 적용 포인트 (Actionable Insights)
- 임베딩 추출 전략 (Embedding Strategy):
- 관습적으로 사용하는 마지막 레이어(
last_hidden_state)는 생성 목적에는 부합하지만, 검색(Retrieval)이나 분류(Classification) 등 다운스트림 태스크에는 최적이 아닐 수 있음. - 특히 Pythia나 Llama 같은 디코더(Decoder-only) 모델을 사용할 때는 50%~80% 깊이의 중간 레이어에서 임베딩을 추출하여 성능을 비교해 볼 것을 강력히 권장함. (예: 32레이어 모델이라면 16~24번 레이어 활용)
- 관습적으로 사용하는 마지막 레이어(
- 비지도 레이어 선택 (Unsupervised Layer Selection):
- 정답 라벨이 없는 데이터셋이라도 최적의 레이어를 찾을 수 있음.
- 보유한 데이터에 대해 DiME(엔트로피 차이)이나 InfoNCE(대조 학습 손실) 지표를 계산해 볼 것.
- 실험 결과, InfoNCE 손실이 가장 낮거나 DiME 점수가 높은 레이어가 실제 다운스트림 성능(MTEB)과 강력한 상관관계를 보였으므로, 이를 기준으로 레이어를 선택하면 별도의 파인튜닝 없이도 성능 향상이 가능함.
