- ICLR 2024
- 저자: Siyu Ren, Zhiyong Wu, Kenny Q. Zhu
- https://arxiv.org/abs/2310.04691
- https://github.com/DRSY/EMO
0. 개요
기존 언어 모델 학습의 표준 방식인 MLE, 즉 Maximum Likelihood Estimation의 근본적인 결함을 지적하고, 최적 수송 이론의 Earth Mover Distance를 활용한 새로운 학습 방법을 제안.
1. 언어 모델 학습의 기초와 MLE의 수학적 정의
데이터 분포와 모델 분포의 일치
- : 인간이 사용하는 실제 언어 데이터 분포
- : 파라미터 로 정의되는 모델이 예측하는 분포
- : 데이터 분포 에서 샘플링한 에 대한 기댓값
언어 모델링의 궁극적 목적은 실제 언어 분포 와 모델 분포 사이의 거리를 최소화하는 것임. 교차 엔트로피(Cross-Entropy)는 모델이 실제 데이터 분포를 얼마나 잘 모사하는지 측정하는 기본 척도로 널리 사용됨.
자기회귀(Auto-Regressive) 모델의 확률 계산
- : 전체 텍스트 시퀀스
- : 시퀀스의 총 토큰 수
- : 시점 에서의 토큰
- : 시점 이전의 모든 토큰들 (문맥)
- : 문맥이 주어졌을 때 다음 토큰의 조건부 확률
자기회귀 모델은 전체 시퀀스의 확률을 각 시점에서의 조건부 확률들의 곱으로 분해함. 이전 문맥 를 기반으로 다음 토큰 를 순차적으로 예측하는 방식임.
MLE 학습 목적 함수의 토큰 레벨 분해
- : 최대 우도 추정법의 손실 함수
- : 문맥이 주어졌을 때 실제 데이터의 다음 토큰 분포
- : 문맥이 주어졌을 때 모델의 다음 토큰 분포
문장 전체에 대한 MLE 손실은 각 타임스텝에서 발생하는 토큰 레벨 교차 엔트로피의 합으로 분해됨. 학습 과정에서 매 시점마다 정답 토큰의 확률을 높이는 방향으로 최적화가 진행됨.
2. MLE 학습 방식의 근본적인 결함 분석
2.1 재현율 우선주의(Recall-prioritization) 문제
- : 파라미터 에 대한 그래디언트
- : 정답 토큰 확률의 그래디언트
- : 정답 토큰에 대한 모델의 예측 확률
MLE의 그래디언트를 분석하면, 모델이 오직 정답 토큰 의 확률을 높이는 데만 집중하는 재현율 우선(Recall-prioritized) 특성을 보임. 정답이 아닌 저품질 토큰의 확률을 명시적으로 낮추는 정밀도(Precision) 최적화가 부족해짐. 이로 인해 모델이 횡설수설하거나 반복적인 문구를 생성하는 퇴화(degeneration) 현상이 발생함.
손실 함수에서도 잘 나타나는데, Cross Entrophy는 와 의 곱의 기댓값. 즉 와 의 곱이 클수록 손실이 큼. 는 실제 확률, 는 모델의 예측확률에 반비례, 즉 실제 정답 토큰에 대해서 모델이 확률이 낮다고 예측할수록 손실이 커짐. → 재현율 우선주의 문제
2.2 부정적 다양성 무시(Negative Diversity Ignorance)
- : 소프트맥스 이전의 번째 토큰에 대한 로짓(logit) 값
- : 어휘 사전의 번째 토큰
- : 정답 토큰
- : 토큰 에 대한 모델의 예측 확률
로짓에 대한 편미분 결과, 정답 토큰을 제외한 모든 토큰이 동등하게 오답으로 취급됨. 그래디언트 기반 최적화에서 국소 최솟값에 도달하려면 정답 확률은 1로, 나머지 모든 토큰의 확률은 0으로 수렴해야 함. 문맥상 정답과 유사한 유의어(예: "glad"와 "happy")도 완전히 무관한 단어와 동일하게 페널티를 받음. 이로 인해 언어의 풍부한 의미론적 관계와 다양성 학습에 한계가 생김.
2.3 학습-평가 불일치(Train-Test Mismatch)
MLE 학습 시에는 데이터 분포 에서 샘플을 추출하여 기댓값을 계산함:
그러나 평가 시에는 모델 분포 에서 샘플을 생성하고 평가 함수 로 품질을 측정함:
학습 목표와 평가 목표 사이에 근본적인 불일치가 존재함. 기존 방법들은 강화학습이나 대조학습으로 평가 함수를 학습에 통합하려 했으나, 추가 오버헤드가 발생하고 태스크별로 다른 를 사용해야 해서 범용 언어 모델링에 적용하기 어려움.
3. 최적 수송 이론을 통한 해결: Earth Mover Distance (EMD = WAS)
3.1 EMD의 기본 정의
- : 비교할 두 확률 분포
- : 과 를 주변 분포로 갖는 모든 결합 분포의 집합
- : 에서 로 이동시키는 확률 질량의 양 (수송 계획)
- : 에서 로 단위 질량을 이동시키는 비용 (운송 비용)
- : 가능한 모든 수송 계획 중 최솟값
EMD는 한 확률 분포를 다른 분포로 변환하는 데 필요한 최소 운송 비용을 의미함. 최적 수송 문제(Optimal Transport)에서 유래했으며 단순히 확률값의 수치적 차이만 계산하는 교차 엔트로피와 달리, 샘플 간의 거리를 고려하여 더 정교한 분포 비교가 가능함.
3.2 언어 모델링을 위한 EMD의 토큰 레벨 정식화
- : 언어 모델의 어휘 사전 (vocabulary)
- : 어휘 사전의 크기
- : 어휘 사전 내의 번째, 번째 토큰
- : 모델 분포의 에서 데이터 분포의 로 이동시키는 확률 질량
- : 두 토큰 사이의 의미적 거리 (운송 비용)
→ 어휘 사전 내 모든 토큰 쌍에 대해 확률 질량을 어떻게 이동시킬지 최적의 수송 계획을 찾는 것이 새로운 학습 목표가 됨.
3.3 수학적 제약 조건과 물리적 의미
제약 조건의 의미:
- 첫 번째 제약: 각 토큰 에서 나가는 총 확률 질량 = 데이터 분포에서의 확률
- 두 번째 제약: 각 토큰 에 도착하는 총 확률 질량 = 모델 분포에서의 확률
EMD를 계산하기 위해선 위와같은 제약조건을 만족 해야 함. 제약 조건은 확률의 '질량 보존'을 강제함. 출발지(데이터 분포)에서 나가는 확률의 합과 목적지(모델 분포)에 도착하는 확률의 합이 각각 원본 분포와 정확히 일치해야 함. 이 조건 내에서 총 운송 비용을 최소화하는 최적 경로를 찾음.
3.4 의미론적 운송 비용 함수 (Semantically-Informed Transport Cost)
- : 토큰 의 임베딩 벡터 (언어 모델 헤드 의 번째 열)
- : 두 임베딩 벡터의 내적
- : 각 벡터의 노름(norm)
- : 코사인 유사도
토큰 간 운송 비용은 MLE로 사전학습된 언어 모델 헤드의 임베딩 간 코사인 거리로 정의함. 학습 과정에서 는 다음 토큰이 인 모든 문맥의 표현과 가깝도록 최적화되었으므로, 코사인 거리는 토큰 간 의미적 거리의 효과적인 대리 지표가 됨. 교환 가능한 토큰(예: "glad"와 "happy")은 작은 거리를, 무관한 토큰(예: "cat"과 "galaxy")은 큰 거리를 가짐. 비용 함수 는 사전에 계산되어 학습 중 고정됨.
4. 효율적인 학습을 위한 미분 가능한 상한선 (DEMD)
4.1 계산 복잡도 문제
전통적인 EMD 솔버의 복잡도는 임. 최신 LLM의 어휘 사전은 수만 개의 토큰을 포함하므로 매우 부담됨. 또한 외부 솔버 사용 시 계산 그래프가 분리되어 그래디언트 역전파가 불가능함.
4.2 대리 운송 계획(Surrogate Transport Plan) 수립
- : 대리(surrogate) 운송 계획
- : 토큰 에 대한 모델의 예측 확률
- : 토큰 에 대한 데이터 분포의 확률
최적의 운송 계획 를 직접 계산하는 대신, 두 분포의 독립적인 곱으로 정의된 실행 가능한 운송 계획 를 사용함. 와 모두 합이 1이므로 는 제약 조건을 만족하는 유효한 계획임. 최적 해는 아니지만 학습에 사용하기 충분한 상한선을 제공함.
4.3 상한선의 유도 및 행렬 연산 최적화
코사인 거리 비용 함수를 대입하면:
- : 비용 함수의 행렬 표현
- : 모든 원소가 1인 열벡터
- : 행 방향으로 정규화된 임베딩 행렬
- : 원-핫 인코딩된 다음 토큰 분포
대리 계획을 사용한 상한선은 행렬 연산으로 단순화됨. 이 수식을 DEMD(Differentiable EMD)라 명명하며, MLE와 결합하여 자기회귀 언어 모델링에 적용함.
4.4 일반화된 형태 (임의의 P에 대해)
가 원-핫이 아닌 밀집(dense) 분포일 경우, 원래 DEMD의 최적해는 기대 운송 비용이 가장 작은 토큰에 모든 확률을 몰아주는 원-핫 분포가 됨. 이를 해결하기 위해 와 의 대리 운송 비용 간 절대 차이를 최소화하는 일반화된 형태를 사용함.
4.5 최종 학습 그래디언트
- : 토큰 의 확률에 대한 그래디언트
- : 데이터 분포 하에서 의 기대 운송 비용
DEMD의 그래디언트는 모든 토큰에 대해 데이터 분포와의 기대 운송 비용으로 가중치를 부여함. MLE와 달리 정답 토큰만이 아닌 전체 어휘에 대해 그래디언트가 계산됨. 정답과 의미적으로 먼 토큰은 큰 페널티를, 유의어는 작은 페널티를 받아 정밀도가 향상됨.
4.6 동적 가중치 적용
- : 그래디언트 계산에서 제외 (상수로 취급)
모델이 약할 때(perplexity가 높을 때) DEMD는 코사인 기반 비용의 제한된 그래디언트 스케일링으로 인해 수렴이 느릴 수 있음. 이를 해결하기 위해 MLE와 DEMD 손실의 비율로 동적 가중치를 적용함.
5. MLE 대비 EMO의 행동 차이
5.1 재현율과 정밀도의 조화 (Harmonizing Recall and Precision)
MLE는 정답 토큰에만 높은 확률을 부여하도록 유도하여 재현율에 편향됨. 결과적으로 저품질 영역에서 과신(over-confident)하는 모델이 학습됨. 반면 EMO는 각 타임스텝에서 의 정밀도도 고려함. 저품질 토큰(운송 비용이 큰 토큰)에 명시적으로 페널티를 부여하여 퇴화된 텍스트의 과대평가를 효과적으로 완화함.
5.2 부정적 다양성 인식 (Negative Diversity Awareness)
DEMD의 그래디언트(수식 참조)에서, 파라미터 업데이트는 전체 어휘에 걸친 토큰 확률의 그래디언트 합으로 구성되며, 각각 기대 운송 비용으로 가중됨. 데이터 분포에서 크게 벗어난 토큰(높은 운송 비용)은 문맥적으로 유사한 토큰보다 더 강하게 하향 조정됨. 따라서 모델 분포 는 더 정보가 풍부한 학습 신호 덕분에 MLE보다 정확하게 확률 질량을 배분함.
5.3 학습-평가 일관성 향상 (Better Train-Test Consistency)
MLE의 목표는 데이터 분포 에 대한 기댓값이지만, 평가 시에는 모델 분포 에서 샘플링함. DEMD를 로 다시 쓰면, 모델 분포 에 대한 기대 운송 비용 최적화가 명시적으로 포함됨을 알 수 있음. 따라서 DEMD는 MLE보다 학습-평가 일관성이 높음.
6. 실험 결과 및 분석
6.1 실험 설정
사전학습 모델: GPT-2, OPT-125M (디코더 전용 Transformer)
비교 대상:
- MLE: 기본 최대 우도 추정법
- TaiLr: 총 변이 거리(Total Variation Distance) 기반 방법
- MixCE: 역방향 교차 엔트로피를 결합한 방법
데이터셋: WikiText-2, WikiText-103, WebText, Penn Tree Bank, WritingPrompts, AG News (6개 도메인)
평가 지표: Mauve (생성 텍스트와 인간 텍스트 간 분포 유사도 측정, 높을수록 좋음)
학습 세부사항: 3 에폭, AdamW 옵티마이저, 학습률 5e-5, 배치 크기 32, 최대 입력 길이 256
6.2 도메인별 생성 품질 비교 (Mauve 점수 ↑)
| 모델 | 목적함수 | WikiText2 | WikiText103 | WebText | PTB | WritingPrompts | AG News |
|---|---|---|---|---|---|---|---|
| GPT-2 | MLE | 77.5 | 77.1 | 75.5 | 76.1 | 83.6 | 75.0 |
| GPT-2 | TaiLr | 79.6 | 78.0 | 76.5 | 73.8 | 84.1 | 75.8 |
| GPT-2 | MixCE | 78.3 | 77.6 | 76.3 | 76.9 | 82.7 | 76.6 |
| GPT-2 | EMO | 87.5 | 82.1 | 80.5 | 79.6 | 87.4 | 84.9 |
| OPT-125M | MLE | 77.2 | 75.8 | 74.7 | 83.6 | 84.1 | 82.1 |
| OPT-125M | TaiLr | 78.4 | 75.2 | 74.2 | 82.2 | 83.4 | 81.8 |
| OPT-125M | MixCE | 78.6 | 75.4 | 75.3 | 81.5 | 83.5 | 83.2 |
| OPT-125M | EMO | 82.9 | 81.0 | 80.7 | 86.1 | 87.9 | 84.8 |
EMO로 미세조정된 모델은 모든 도메인에서 MLE 대비 평균 6.2 포인트 높은 Mauve 점수를 기록함. TaiLr과 MixCE는 이론적 장점에도 불구하고 정규화된 MLE 형태로 퇴화되어 제한적인 개선만 보임.
6.3 Oracle Generator 분석
Oracle GPT-2-Large 모델에서 생성한 데이터로 학습하여 더 세밀한 분포 특성을 분석함.
| 방법 | PPL_test ↓ | PPL_oracle ↓ | Mauve ↑ | ROUGE-1 ↑ | ROUGE-L ↑ |
|---|---|---|---|---|---|
| MLE | 70.1 | 114.46 | 77.5 | 34.59 | 29.85 |
| TaiLr | 73.5 | 95.22 | 77.4 | 34.95 | 30.09 |
| MixCE | 74.4 | 79.46 | 78.4 | 35.31 | 30.26 |
| EMO | 74.9 | 55.85 | 83.4 | 37.37 | 31.17 |
- : 테스트 셋에서의 perplexity (재현율 지표)
- : Oracle 모델로 측정한 생성 텍스트의 perplexity (정밀도 지표)
EMO의 이 MLE 대비 절반 수준(114.46 → 55.85)으로 감소함. 모델이 저품질 토큰을 선택하는 빈도가 크게 줄어들었음을 의미함. 약간 높은 는 정답 외에 다양한 적절한 토큰에도 확률을 배분하기 때문임. 가장 높은 Mauve 점수는 EMO가 재현율과 정밀도 사이에서 최적의 균형을 달성했음을 보여줌.
6.4 LLM 다운스트림 태스크 성능
WikiText-103에서 경량 미세조정(0.1B 토큰) 후 8개 NLU 태스크에서 in-context learning으로 평가함.
| 모델 | 방법 | TE | SST-2 | TREC | Subj | CR | RT | AG | MMLU |
|---|---|---|---|---|---|---|---|---|---|
| LLaMa-7B | Pre-trained | 54.1 | 94.7 | 77.8 | 74.7 | 91.4 | 90.0 | 85.6 | 31.4 |
| LLaMa-7B | MLE | 53.5 | 94.8 | 79.0 | 74.5 | 92.0 | 91.8 | 85.5 | 31.9 |
| LLaMa-7B | TaiLr | 56.2 | 94.9 | 79.6 | 76.8 | 92.0 | 91.9 | 86.3 | 33.2 |
| LLaMa-7B | MixCE | 60.0 | 95.0 | 81.2 | 78.5 | 92.0 | 91.8 | 87.5 | 33.9 |
| LLaMa-7B | EMO | 65.6 | 95.2 | 83.4 | 79.2 | 92.0 | 92.1 | 89.4 | 34.8 |
| LLaMa-13B | Pre-trained | 58.5 | 95.6 | 81.2 | 77.4 | 91.2 | 91.0 | 84.5 | 44.5 |
| LLaMa-13B | MLE | 58.6 | 95.5 | 79.8 | 76.9 | 92.0 | 91.3 | 84.3 | 44.9 |
| LLaMa-13B | TaiLr | 61.9 | 95.5 | 81.0 | 78.5 | 92.3 | 91.4 | 85.6 | 45.9 |
| LLaMa-13B | MixCE | 65.7 | 95.6 | 82.8 | 80.6 | 92.0 | 91.3 | 85.9 | 46.7 |
| LLaMa-13B | EMO | 70.4 | 95.9 | 85.2 | 81.1 | 92.6 | 92.2 | 88.4 | 47.5 |
MLE 미세조정은 사전학습 모델 대비 미미한 개선만 보이거나 오히려 성능이 하락함. EMO는 별도의 하이퍼파라미터 튜닝 없이 모든 태스크에서 가장 큰 성능 향상을 달성함. 특히 AG News에서 4.1%p, Tweet Emotion에서 11.5%p(7B), 11.9%p(13B) 향상됨.
6.5 EMO의 스케일링 법칙
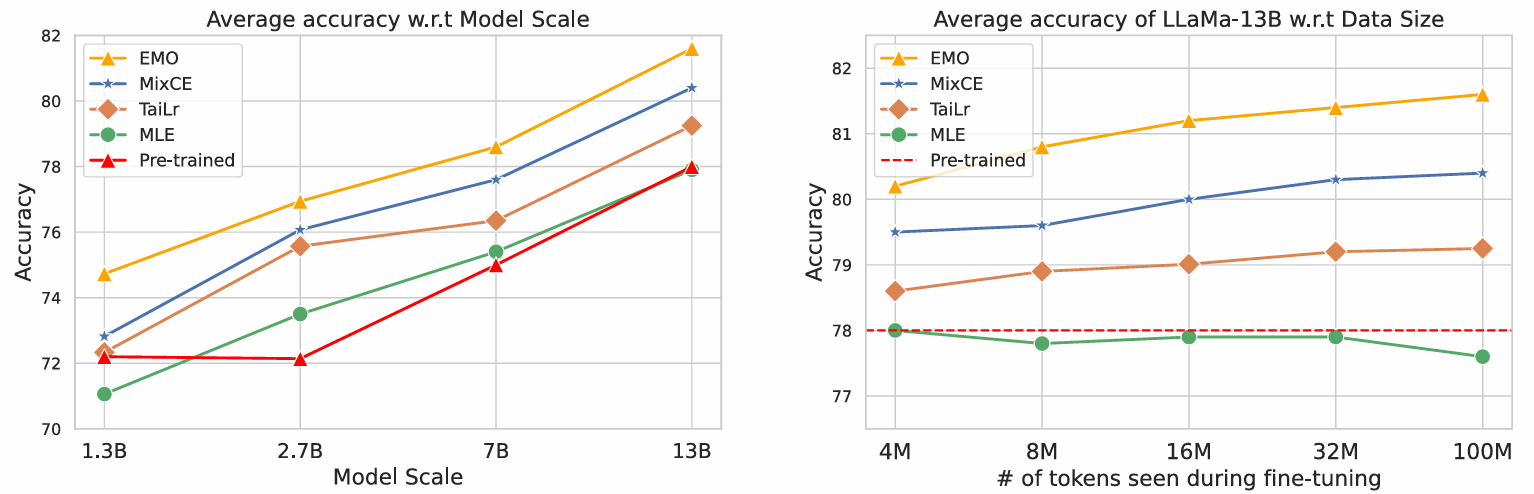
모델 스케일링: OPT-1.3B/2.7B, LLaMa-7B/13B에서 실험 결과, MLE는 사전학습 모델 대비 일관된 개선을 보이지 못함. TaiLr과 MixCE는 하이퍼파라미터 튜닝 시 긍정적 효과를 보임. EMO는 모든 모델 규모에서 안정적으로 다른 방법들을 능가함.
데이터 스케일링: LLaMa-13B로 미세조정 데이터 양을 변화시키며 실험함. MLE 모델은 미세조정이 진행될수록 정확도가 오히려 하락하는 경향을 보임 (Section 2.2의 이론적 결함 때문). EMO는 가장 큰 성능 향상을 보이며, 단 4M 토큰으로 100M 토큰 학습한 MixCE와 동등한 성능을 달성함.
8. 결론 및 향후 전망
MLE의 고질적 결함 극복
재현율 편향, 부정적 다양성 무시, 학습-평가 불일치 문제를 최적 수송 이론 기반의 EMD로 해결함. 정밀도와 재현율의 균형을 통해 더 인간다운 텍스트를 생성하는 모델 학습이 가능해짐.
압도적인 데이터 효율성
단 4M 토큰만으로 기존 방식이 100M 토큰을 사용했을 때 이상의 성능을 달성함. 사전학습된 LLM의 경량 보정(calibration) 방법으로서 높은 잠재력을 보여줌.
강력한 확장성
모델 규모(1.3B → 13B)와 데이터 양이 증가할수록 더 일관되고 뚜렷한 성능 향상을 보임. 범용 목적의 지속적 미세조정에 유리한 스케일링 특성을 제시함.
