On the Use of BERT for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation (NLP; Automated Essay Scoring)
Abstract
최근 몇 년 동안 사전 학습된 모델은 대부분의 자연어 처리(NLP) 작업에서 지배적인 위치를 차지하게 되었습니다. 그러나 자동 에세이 채점(AES) 분야에서는 BERT와 같은 사전 학습된 모델이 LSTM과 같은 다른 딥러닝 모델을 능가하는 데 적절히 사용되지 못했습니다. 본 논문에서는 BERT를 위한 새로운 다중 규모 에세이 표현 방식을 도입하여 공동 학습할 수 있도록 제안합니다. 또한, 성능을 더욱 향상시키기 위해 다중 손실을 사용하고 도메인 외부 에세이로부터 전이 학습을 수행합니다. 실험 결과, 본 접근법은 다중 규모 에세이 표현의 공동 학습으로부터 많은 이점을 얻었으며, ASAP(Automated Student Assessment Prize) 작업에서 모든 딥러닝 모델 중 거의 최첨단 성과를 달성했음을 보여줍니다. 제안된 다중 규모 에세이 표현은 CommonLit Readability Prize(CRP) 데이터 세트에도 잘 일반화되며, 이는 본 논문에서 제안한 새로운 텍스트 표현 방식이 장문 작업에 대한 효과적이고 새로운 선택지가 될 수 있음을 시사합니다.
1. Introduction
AES는 자동 평가 시스템의 발전을 촉진하고 교사가 평가 과정에서 겪는 무거운 부담을 줄이는 데 도움을 줄 수 있는 중요한 과제입니다. 최근 몇 년 동안 온라인 교육이 증가하면서, 이 분야에 대한 관심이 점점 더 높아지고 있습니다.
AES 시스템은 일반적으로 두 개의 모듈로 구성됩니다. 하나는 에세이 표현 모듈이고, 다른 하나는 에세이 채점 모듈입니다. 에세이 표현 모듈은 에세이를 나타내는 특징들을 추출하며, 에세이 채점 모듈은 추출된 특징을 바탕으로 에세이에 점수를 부여합니다.
교사가 에세이를 채점할 때, 점수는 종종 단어 수준, 문장 수준, 단락 수준 등 다양한 세부 수준에서의 여러 신호에 의해 영향을 받습니다. 예를 들어, 단어 수, 에세이 구조, 어휘의 숙련도, 구문 복잡도 등이 이러한 신호에 포함될 수 있습니다. 이러한 특징들은 에세이의 서로 다른 규모에서 비롯됩니다. 이는 에세이의 다중 수준 특성을 나타내는 다중 규모 특징을 추출하도록 우리에게 영감을 주었습니다.
대부분의 딥러닝 기반 AES 시스템은 LSTM이나 CNN을 사용합니다. 일부 연구자들(Uto et al., 2020; Rodriguez et al., 2019; Mayfield and Black, 2020)은 AES 시스템에 BERT(Devlin et al., 2019)를 적용하려고 시도했지만, 다른 딥러닝 방법(Dong et al., 2017; Tay et al., 2018)을 능가하지는 못했습니다. 우리는 BERT를 AES에 사용하는 기존 접근 방식들이 최소한 세 가지 한계점에 직면했다고 생각합니다. 첫째, 사전 학습된 모델들은 일반적으로 문장 수준에서 학습되며, 에세이에 대한 충분한 지식을 학습하지 못합니다. 둘째, AES 학습 데이터는 보통 제한적이기 때문에, 에세이 표현을 더 잘 학습하기 위한 사전 학습 모델의 직접적인 미세 조정에는 적합하지 않습니다. 마지막으로, AES 작업에서는 일반적으로 평균 제곱 오차(MSE)가 손실 함수로 사용됩니다. 그러나 샘플의 분포와 샘플 간 정렬 속성도 교사가 에세이를 평가할 때의 심리적 과정을 모방할 때 고려해야 할 중요한 문제입니다. 다양한 최적화는 최종 점수 분포에 다양성을 제공하고 앙상블 학습의 효과에 기여할 수 있습니다.
위에서 언급한 문제와 한계를 해결하기 위해, 우리는 BERT를 사용하여 다중 규모 에세이 표현의 공동 학습을 AES 작업에 도입합니다. 이를 통해 LSTM 기반의 최신 딥러닝 모델(Dong et al., 2017; Tay et al., 2018)을 능가하는 성능을 제공합니다. 우리는 다중 규모 특징을 명시적으로 모델링하고, 다수의 문장 데이터에서 학습된 지식을 활용하여 더 효과적인 표현을 추출하는 방식을 제안합니다. 학습 데이터가 제한적이기 때문에, Song et al.(2020)의 연구에 영감을 받아 도메인 외부 에세이로부터의 전이 학습도 활용합니다. 또한, 에세이 점수 분포의 다양성을 도입하기 위해 MSE와 함께 두 가지 추가 손실 함수를 결합합니다. 우리의 모델은 다중 손실과 전이 학습을 사용하여 R-Drop(Liang et al., 2021)으로 학습할 때, 모든 딥러닝 모델 중 거의 최첨단 결과를 달성합니다. Prompt 8에 대한 사전 학습된 모델을 포함한 예측 모듈의 소스 코드는 공개되어 있습니다.
요약하자면, 본 연구의 기여는 다음과 같습니다:
- 우리는 BERT를 사용하여 다중 규모 에세이 표현을 공동 학습하는 새로운 에세이 채점 접근 방식을 제안하며, 이는 기존의 사전 학습된 언어 모델을 단순히 사용하는 것에 비해 결과를 상당히 개선합니다.
- 본 방법은 장문의 작업에서 상당한 장점을 보이며, ASAP 작업에서 모든 딥러닝 모델 중 거의 최첨단 결과를 달성했습니다.
- 우리는 교사가 에세이를 평가하는 심리적 과정을 기반으로 한 두 가지 새로운 손실 함수를 도입하고, R-Drop(Liang et al., 2021)을 활용한 도메인 외부 에세이 전이 학습을 적용하여 에세이 평가 성능을 더욱 향상시켰습니다.
2. Related Work
AES의 지배적인 접근 방식은 크게 세 가지 범주로 나눌 수 있습니다:
전통적인 AES, 딥러닝 기반 AES, 사전 학습 기반 AES.
- 전통적인 AES는 복잡한 수작업 특징을 사용한 회귀 또는 순위 시스템으로 에세이를 평가합니다(Larkey, 1998; Rudner and Liang, 2002; Attali and Burstein, 2006; Yannakoudakis et al., 2011; Chen and He, 2013; Phandi et al., 2015; Cozma et al., 2018). 이러한 수작업 특징은 언어학자들의 사전 지식에 기반하므로, 데이터가 적더라도 좋은 성능을 발휘할 수 있습니다.
- 딥러닝 기반 AES는 최근 상당한 발전을 이루었으며, 전통적인 AES와 비교할 만한 성과를 달성했습니다(Taghipour and Ng, 2016; Dong and Zhang, 2016; Dong et al., 2017; Alikaniotis et al., 2016; Wang et al., 2018; Tay et al., 2018; Farag et al., 2018; Song et al. 2020; Ridley et al., 2021; Muangkammuen and Fukumoto, 2020; Mathias et al., 2020). 수작업으로 설계된 특징은 구현이 복잡하고 설계 과정에서 많은 노력이 필요하므로 재사용성이 떨어지지만, LSTM이나 CNN 같은 딥러닝 네트워크는 에세이의 복잡한 특징을 자동으로 발견하고 학습할 수 있습니다. 이는 AES를 엔드 투 엔드(end-to-end) 작업으로 만들어줍니다. 딥러닝 네트워크는 특징 설계 시간을 절약하며, 서로 다른 AES 작업 간 전이가 잘 이루어질 수 있습니다. 전통적인 접근 방식과 딥러닝 네트워크 접근 방식을 결합하면 더욱 우수한 성과를 얻을 수 있는데, 이는 두 방식의 장점을 모두 활용하기 때문입니다(Jin et al., 2018; Dasgupta et al., 2018; Uto et al., 2020). 그러나 이러한 방식에서도 여전히 수작업으로 설계된 특징이 필요하며, 이는 연구자들에게 많은 노력을 요구합니다.
- 사전 학습 기반 AES는 사전 학습된 언어 모델을 초기 에세이 표현 모듈로 사용하고, 에세이 학습 데이터 세트를 기반으로 모델을 미세 조정합니다. 비록 사전 학습된 방법이 대부분의 NLP 작업에서 최첨단 성능을 달성했지만, 많은 연구(Uto et al., 2020; Rodriguez et al., 2019; Mayfield and Black, 2020)에서 AES 작업에서는 다른 딥러닝 방법(Dong et al., 2017; Tay et al., 2018)을 능가하지 못했습니다. 우리가 아는 한, Cao et al.(2020)과 Yang et al.(2020)의 연구만이 사전 학습 접근 방식이 다른 딥러닝 방법을 초과하는 성능을 보인 사례입니다. 이들의 개선은 주로 학습 최적화에서 비롯됩니다. Cao et al.(2020)은 두 가지 자가 지도 학습 작업과 도메인 적대 학습을 사용하며, Yang et al.(2020)은 회귀와 순위를 결합하여 모델을 학습시켰습니다.
3. Approach
3.1 Task Formulation
AES 작업은 다음과 같이 정의됩니다:
단어 개로 구성된 에세이 가 주어졌을 때, 이 에세이의 수준을 측정하는 점수 를 출력해야 합니다.
연구자들은 일반적으로 AES 시스템을 평가하기 위해 두 평가자 간 채점 결과의 일치를 측정하는 지표인 QWK(Quadratic Weighted Kappa) (Cohen, 1968)를 사용합니다.
3.2 Multi-scale Essay Representation
우리는 세 가지 규모(토큰, 세그먼트, 문서)에서 다중 규모 에세이 표현을 얻습니다.
토큰 및 문서 규모 입력
하나의 사전 학습된 BERT 모델(Devlin et al., 2019)을 토큰 규모와 문서 규모의 에세이 표현을 얻는 데 사용합니다. BERT 토크나이저를 사용하여 에세이를 다음과 같은 토큰 시퀀스 로 분할합니다. 여기서 는 번째 토큰이고, 은 에세이의 토큰 수를 나타냅니다. 이 논문에서는 모든 토큰이 BERT에서 사용하는 서브워드 토크나이저 알고리즘을 통해 얻어지는 WordPiece를 의미합니다.
다음과 같은 새로운 시퀀스 를 로부터 구성합니다. 은 BERT에서 지원하는 최대 시퀀스 길이(토큰 와 를 제외한 510)로 설정됩니다.
최종 입력 표현은 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩의 합으로 구성됩니다. 자세한 설명은 BERT(Devlin et al., 2019)의 작업에서 확인할 수 있습니다.
문서 규모 표현
문서 규모 표현은 BERT 모델의 출력에서 얻습니다. 출력은 전체 시퀀스 표현을 집계하므로, 에세이 정보를 가장 전역적인 규모에서 추출하려고 시도합니다.
토큰 규모 표현
BERT 모델은 사전 학습 단계에서 Masked Language Modeling(Devlin et al., 2019)을 통해 학습되며, 시퀀스 출력은 각 토큰을 나타내는 문맥 정보를 캡처할 수 있습니다. 에세이는 일반적으로 수백 개의 토큰으로 구성되므로, 모든 토큰 정보를 결합하기 위해 RNN을 사용하는 것은 그래디언트 소실 문제 때문에 적합하지 않습니다. 대신, 우리는 모든 시퀀스 출력에 대해 최대 풀링(max-pooling) 연산을 사용하여 결합된 토큰 규모 에세이 표현을 얻습니다. 구체적으로, 최대 풀링 레이어는 -차원의 벡터 를 생성하며, 는 다음과 같이 계산됩니다:
여기서 는 BERT 모델의 히든 크기(hidden size)입니다. 우리는 사전 학습된 BERT 모델인 bert-base-uncased를 사용하며, 이 모델의 히든 크기 는 768입니다. BERT 모델의 개의 시퀀스 출력은 으로 표시되며, 각 는 -차원의 벡터 를 나타냅니다. 여기서 는 에서 -번째 요소입니다.
세그먼트 규모 표현
세그먼트 규모 값 집합을 로 가정합니다. 여기서 는 우리가 탐구하려는 세그먼트 규모의 개수를 나타내며, 는 에서 -번째 세그먼트 규모입니다. 에세이에 대한 토큰 시퀀스 가 주어졌을 때, 에 해당하는 세그먼트 규모 에세이 표현을 다음과 같이 얻습니다:
-
각 에세이 프롬프트 에 대해 최대 토큰 수를 로 정의합니다. 에세이 길이가 보다 길면 토큰 시퀀스를 토큰으로 잘라내고, 그렇지 않으면 시퀀스를 길이로 맞추기 위해 를 추가합니다.
-
토큰 시퀀스를 개의 세그먼트로 나눕니다. 각 세그먼트의 길이는 이며, 마지막 세그먼트는 약간 다를 수 있습니다(Mulyar et al., 2019의 작업과 유사).
-
각 개의 세그먼트 토큰을 BERT 모델에 입력하고, 출력을 통해 개의 세그먼트 표현 벡터를 얻습니다.
-
LSTM 모델을 사용하여 개의 세그먼트 표현 시퀀스를 처리한 후, LSTM 출력의 히든 상태에 대해 주의(attention) 풀링 연산을 수행하여 에 해당하는 세그먼트 규모 에세이 표현을 얻습니다.
LSTM 셀은 세그먼트 표현 시퀀스를 처리하며 다음과 같은 방식으로 히든 상태를 생성합니다:
여기서 는 BERT의 출력에서 얻은 -번째 세그먼트 표현이고, 는 LSTM에서 생성된 -번째 히든 상태입니다. 는 가중치 행렬이며, 는 바이어스 벡터입니다.
주의 풀링(attention pooling) 연산은 Dong et al., 2017의 작업과 유사하며, 다음과 같이 정의됩니다:
여기서 는 세그먼트 규모 에세이 표현에 해당하며, 는 히든 상태 에 대한 주의 가중치입니다. 는 가중치 행렬, 바이어스, 가중치 벡터를 나타냅니다.
3.3 Model Architecture
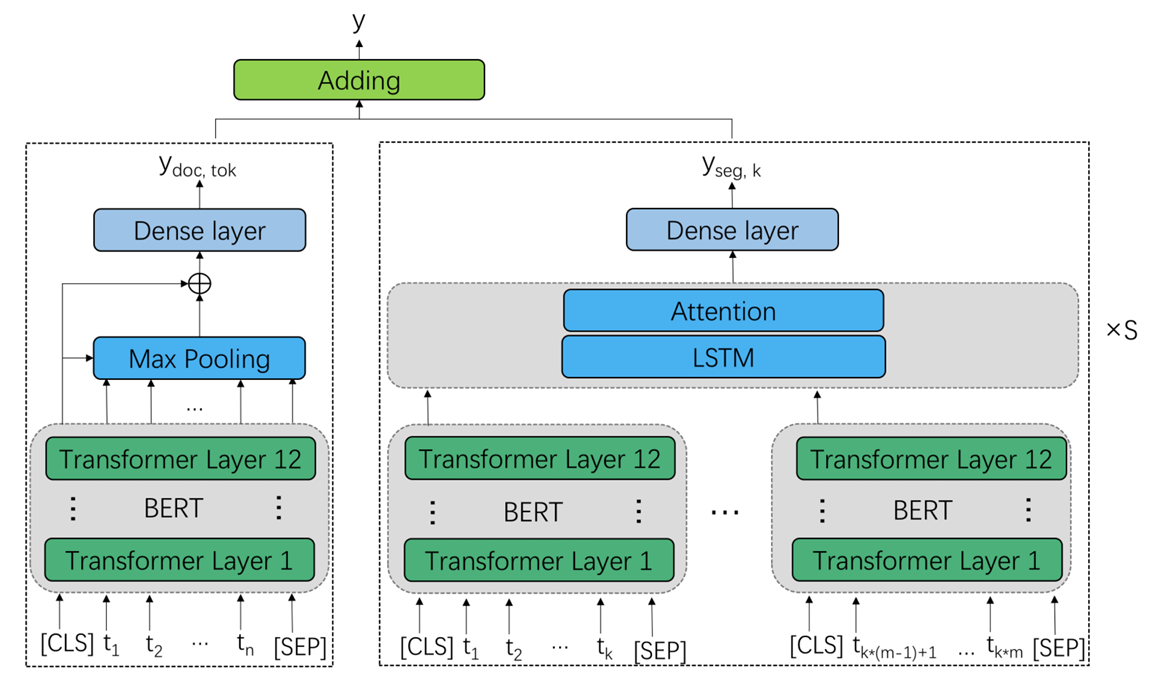 - 그림 1 : 제안된 자동 에세이 점수 매기기 아키텍처는 다중 스케일 에세이 표현을 기반으로 합니다. 왼쪽 부분은 문서 스케일 및 토큰 스케일 에세이 표현과 점수 매기기 모듈을 나타내며, 오른쪽 부분은 세그먼트 스케일 에세이 표현과 점수 매기기 모듈을 나타냅니다.
- 그림 1 : 제안된 자동 에세이 점수 매기기 아키텍처는 다중 스케일 에세이 표현을 기반으로 합니다. 왼쪽 부분은 문서 스케일 및 토큰 스케일 에세이 표현과 점수 매기기 모듈을 나타내며, 오른쪽 부분은 세그먼트 스케일 에세이 표현과 점수 매기기 모듈을 나타냅니다.
모델 아키텍처는 그림 1에 묘사되어 있습니다.
하나의 BERT 모델을 사용하여 문서 규모와 토큰 규모 에세이 표현을 얻습니다. 이 두 표현을 연결한 후, 이를 하나의 밀집 회귀 레이어(dense regression layer)에 입력하여 문서 규모와 토큰 규모에 해당하는 점수를 예측합니다. 각 세그먼트 규모 에 대해 개의 세그먼트가 존재하며, 또 다른 BERT 모델을 사용하여 각 세그먼트의 출력을 얻습니다. 그런 다음, LSTM 모델과 그 뒤에 주의(attention) 레이어를 사용하여 세그먼트 규모 표현을 얻습니다. 세그먼트 규모 표현은 또 다른 밀집 회귀 레이어에 입력되어 해당 세그먼트 규모 에 대한 점수를 예측합니다. 최종 점수는 모든 세그먼트 규모 점수의 합과 문서 및 토큰 규모 점수의 합으로 계산됩니다. 이는 다음과 같이 표현됩니다:
여기서,
- : 세그먼트 규모 에 대한 예측 점수
- : 문서 및 토큰 규모에 대한 예측 점수
- : 세그먼트 규모에 대한 가중치 행렬과 바이어스
- : 문서 및 토큰 규모에 대한 가중치 행렬과 바이어스
- : 세그먼트 규모 에 대한 에세이 표현
- : 문서 규모 에세이 표현
- : 토큰 규모 에세이 표현
- : 문서와 토큰 규모 에세이 표현의 연결(concatenation)입니다.
3.4 Loss Function
우리는 모델 학습을 위해 세 가지 손실 함수를 사용합니다.
평균 제곱 오차(MSE)
MSE는 예측 점수와 실제 라벨 간의 제곱 오차의 평균 값을 측정하며, 다음과 같이 정의됩니다:
여기서,
- : -번째 에세이에 대한 실제 점수(라벨)
- : -번째 에세이에 대한 예측 점수
- : 에세이의 총 개수.
MSE는 일반적으로 AES 작업에서 사용되며, 예측 점수와 실제 점수 간의 평균적인 차이를 최소화합니다.
유사도 손실(SIM)
SIM은 코사인 함수를 사용하여 두 벡터가 얼마나 유사하거나 다른지를 측정합니다. 교사가 에세이를 평가할 때, 전체 학생들의 점수 분포를 고려하는 경향이 있다는 직관에 따라, 우리는 AES 작업에 SIM 손실을 도입했습니다. 학습의 각 단계에서, 배치 내 에세이의 예측 점수를 벡터 로, 실제 점수(라벨)를 벡터 로 설정합니다. SIM 손실은 배치 내 에세이 간의 상관관계를 모델이 더 많이 고려하도록 장려하며, 다음과 같이 정의됩니다:
여기서,
- : 배치 내 예측 점수 벡터
- : 배치 내 실제 점수 벡터
- : 배치 내 에세이 개수.
SIM 손실은 벡터 쌍의 유사성을 높임으로써, 배치 내 에세이들 간의 점수 분포 상관성을 반영하도록 모델을 유도합니다.
마진 랭킹 손실(MR)
MR은 배치 내 각 에세이 쌍의 순위를 측정합니다. 에세이 간 정렬 속성은 점수를 매기는 데 중요한 요소이므로, 우리는 MR 손실을 직관적으로 도입했습니다. 배치 내 모든 에세이 쌍을 나열한 후, 다음과 같은 방식으로 MR 손실을 계산합니다. MR 손실은 잘못된 순서를 패널티로 부과하여 모델이 순위를 올바르게 학습하도록 합니다:
여기서,
- : -번째와 -번째 에세이의 예측 점수,
- : -번째와 -번째 에세이의 실제 점수(라벨),
- : 에세이 쌍의 개수,
- : 하이퍼파라미터로, 실험에서 0으로 설정됨,
- : 점수 관계를 나타내며, 다음과 같이 정의됨:
는 실제 점수의 관계를 나타냅니다. 예를 들어, 일 경우 여야 하며, 그렇지 않으면 만큼 손실이 증가합니다. 실제 점수가 같을 경우, 손실은 로 계산됩니다. MR 손실은 모델이 배치 내 에세이 순서를 정확히 예측하도록 유도합니다.
4. Experiment
4.1 Data and Evaluation

ASAP 데이터 세트는 AES 작업에서 널리 사용되며, 8개의 서로 다른 프롬프트를 포함합니다. 상세한 설명은 표 1에 나와 있습니다. 각 프롬프트에 대해, WordPiece 길이는 90% 이상의 에세이가 해당 WordPiece 길이보다 짧은 경우의 최소 길이를 나타냅니다. ASAP 데이터 세트에서 공식적으로 사용된 평가 지표는 QWK(Quadratic Weighted Kappa)입니다. 이전 연구를 참고하여, 우리는 60/20/20의 비율로 학습, 개발, 테스트 세트를 나누어 5회 교차 검증을 수행합니다.
CRP(CommonLit Readability Prize) 데이터 세트는 여러 시대의 텍스트 발췌문 2,834개와 -3.68에서 1.72 사이의 가독성 점수를 제공합니다. 발췌문의 평균 길이는 175이며, WordPiece 길이는 252입니다. 우리는 또한 CRP 데이터 세트에 대해 학습, 개발, 테스트 세트를 60/20/20의 비율로 나누어 5회 교차 검증을 수행합니다. CRP 대회에서 RMSE(Root Mean Square Error) 지표를 사용하므로, 우리는 가독성 점수 예측 작업에서 RMSE를 사용하여 시스템을 평가합니다.
4.2 Baselines
비교를 위해 사용된 기준 모델(baseline models)은 다음과 같이 설명됩니다.
EASE: 이 모델은 ASAP 대회에 참가하여 154명의 참가자 중 3위를 차지한 최고 성능의 공개 소스 시스템입니다. EASE는 수작업으로 생성된 특징을 사용한 회귀 기법을 채택합니다. Support Vector Regression(SVR)과 Bayesian Linear Ridge Regression(BLRR)을 사용하는 EASE의 결과는 Phandi et al.(2015)의 연구에서 보고되었습니다.
CNN+RNN: 다양한 딥러닝 기반 AES 모델이 Taghipour and Ng(2016)에 의해 연구되었습니다. 이들은 CNN 앙상블과 LSTM 앙상블을 10회 실행하여 결합한 모델을 사용하며, 실험에서 가장 우수한 결과를 얻었습니다.
Hierarchical LSTM-CNN-Attention: Dong et al.,(2017)은 계층적 문장-문서 모델을 구축했으며, 문장을 인코딩하기 위해 CNN을 사용하고 텍스트를 인코딩하기 위해 LSTM을 사용했습니다. 주의(attention) 메커니즘은 문장 표현과 텍스트 표현을 생성하는 과정에서 단어와 문장의 상대적 중요도를 자동으로 결정합니다. 이 모델은 사전 학습 없이 모든 신경망 기반 모델 중 최첨단 성과를 달성했습니다.
SKIPFLOW: Tay et al.(2018)은 LSTM의 숨겨진 표현 스냅샷 간의 관계를 모델링하기 위해 SKIPFLOW 메커니즘을 제안했습니다. Tay et al.(2018)의 연구는 사전 학습 없이 모든 신경망 기반 모델 중 최첨단 성과를 달성했습니다.
Dilated LSTM with Reinforcement Learning: Wang et al.(2018)은 강화 학습 프레임워크에서 희석된(dilated) LSTM 네트워크를 사용하는 방법을 제안했습니다. 이들은 평가 체계를 고려한 QWK(Quadratic Weighted Kappa) 지표를 직접 최적화하려고 시도했습니다.
HA-LSTM+SST+DAT와 BERT+SST+DAT: Cao et al.(2020)은 두 가지 자가 지도 학습 작업(self-supervised tasks)과 도메인 적대 학습(domain adversarial training) 기법을 사용하여 학습을 최적화하는 방법을 제안했습니다. 이는 사전 학습된 언어 모델을 사용하여 LSTM 기반 방법을 능가한 최초의 연구입니다. 이들은 계층적 LSTM 모델과 BERT를 모두 사용하여 실험을 진행했으며, 해당 모델은 각각 HA-LSTM+SST+DAT와 BERT+SST+DAT로 명명되었습니다.
BERT: Yang et al.(2020)은 회귀와 순위 모델을 결합하여 BERT 모델을 미세 조정(fine-tuning)하는 방식을 제안했습니다. 이 방법은 LSTM 기반 방법을 능가했으며, 새로운 최첨단 성능을 달성했습니다.
4.3 Settings
기준 모델과 비교하고 다중 규모 에세이 표현, 손실 함수, 전이 학습의 효과를 추가로 연구하기 위해 다음과 같은 실험을 수행했습니다.
다중 규모 모델(Multi-scale Models)
이 모델들은 MSE 손실로 최적화되었습니다.
- BERT-DOC: 문서 규모 특징으로 에세이를 표현합니다.
- BERT-TOK: 토큰 규모 특징으로 에세이를 표현합니다.
- BERT-DOC-TOK: BERT를 기반으로 문서 규모와 토큰 규모 특징을 함께 사용하여 에세이를 표현합니다.
- BERT-DOC-TOK-SEG: 문서 규모, 토큰 규모, 다중 세그먼트 규모 특징을 모두 사용하여 에세이를 표현합니다.
- Longformer: Longformer(Beltagy et al., 2020)는 시퀀스 길이에 선형적으로 확장되는 주의(attention) 메커니즘을 사용하여 긴 문서를 처리할 수 있는 트랜스포머의 확장 버전입니다. 우리는 다중 규모 특징이 Longformer에서도 잘 작동하고 긴 텍스트 작업에서 성능을 향상시킬 수 있음을 보여주기 위해 실험을 수행했습니다.
- Longformer-DOC-TOK-SEG: 문서 규모, 토큰 규모, 다중 세그먼트 규모 특징을 사용하여 에세이를 표현하지만, BERT 대신 Longformer를 기반으로 합니다.
- Longformer-DOC: 문서 규모 특징만을 사용하여 에세이를 표현하며, Longformer를 기반으로 합니다.
전이 학습을 활용한 모델(Models with Transfer Learning)
도메인 외부 에세이에서 전이 학습을 수행하기 위해, Song et al.(2020)의 연구와 유사한 사전 학습 단계(pre-training stage)를 추가로 적용했습니다. 이 단계에서는 도메인 외부 데이터의 모든 에세이 점수를 0에서 1 사이로 스케일링한 후, MSE 손실을 사용하여 모델을 사전 학습했습니다. 사전 학습 단계 이후, 도메인 내(in-domain) 에세이에서 모델을 미세 조정(fine-tuning)합니다.
- Tran-BERT-MS: BERT-DOC-TOK-SEG 모델과 동일한 구조를 가지며, 도메인 외부 데이터에서 사전 학습이 수행됩니다. MS는 다중 규모(Multi-scale) 특징을 의미합니다.
다중 손실을 활용한 모델(Models with Multiple Losses)
Tran-BERT-MS 모델을 기반으로, 여러 손실 함수를 추가하여 성능을 탐구했습니다.
- Tran-BERT-MS-ML: MR(Margin Ranking) 손실과 SIM(Similarity) 손실을 추가로 사용합니다. ML은 다중 손실(Multiple Losses)을 의미합니다.
- Tran-BERT-MS-ML-R: Tran-BERT-MS-ML 모델에 R-Drop(Liang et al., 2021) 전략을 훈련 과정에 통합한 모델입니다.
이러한 실험을 통해 다중 손실 및 R-Drop이 모델 성능에 미치는 영향을 분석합니다.
그림 1에서 제안된 모델 아키텍처를 보여줍니다. 왼쪽의 BERT 모델은 문서 규모와 토큰 규모 에세이 표현을 얻는 데 사용되며, 오른쪽의 BERT 모델은 모든 세그먼트 규모 에세이 표현을 얻는 데 사용됩니다. 우리는 12개의 트랜스포머 레이어와 히든 크기(hidden size)가 768인 bert-base-uncased를 사용합니다. 훈련 단계에서는 BERT 모델의 마지막 레이어만 미세 조정(fine-tuning)하며, 다른 레이어는 고정(freeze) 상태로 둡니다. Longformer 모델은 longformer-base-4096을 사용합니다.
MR 손실에서 는 0으로 설정됩니다. 손실 함수의 가중치인 는 개발 세트에서의 성능을 기준으로 조정됩니다. 모델 매개변수는 Adam 옵티마이저(Kingma and Ba, 2015)를 사용하여 엔드 투 엔드 방식으로 학습되며, 학습률은 , , , L2 가중치 감쇠는 0.005로 설정됩니다. R-Drop의 계수(weight) 는 9로 설정됩니다. 배치 크기는 32이며, 드롭아웃은 0.1의 비율로 적용됩니다. 모든 모델은 80 에포크 동안 학습되며, 개발 세트에서의 성능을 기준으로 최적의 모델을 선택합니다.
세그먼트 규모의 최적 조합을 찾기 위해 그리디 탐색(greedy search) 방법을 사용했으며, 자세한 내용은 부록 A에 설명되어 있습니다. 이전 연구(Cao et al. 2020)를 참고하여, 모델 성능의 유의미성 테스트를 수행했습니다.
4.4 Results
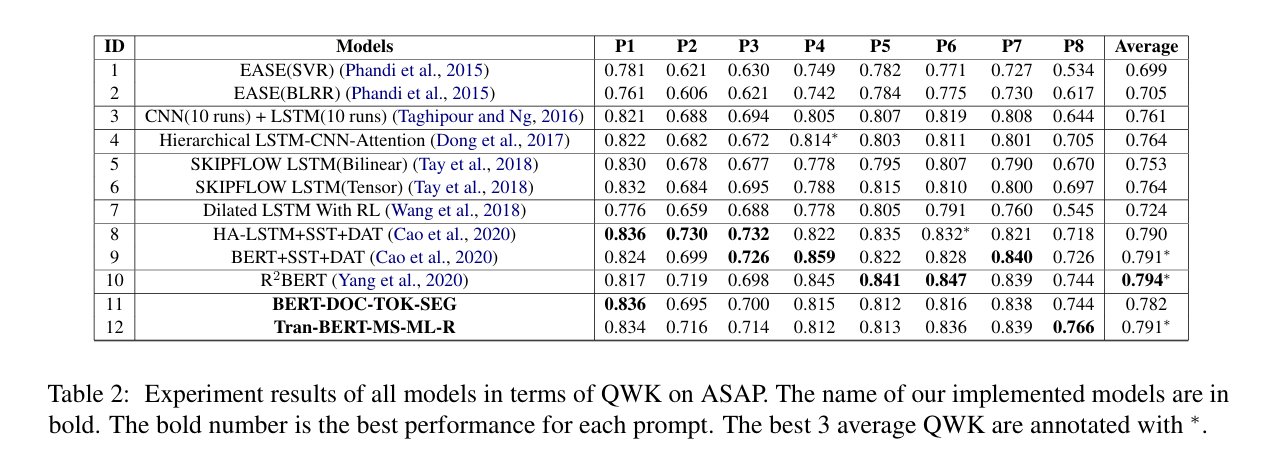

표 2는 다중 규모 에세이 표현의 공동 학습을 사용하는 제안된 모델과 기준 모델의 성능을 QWK(Quadratic Weighted Kappa) 지표를 사용하여 비교한 결과를 보여줍니다. 표 3은 WordPiece 길이가 510보다 긴 프롬프트 1, 2, 8에서 제안된 모델과 최첨단 모델의 성능을 비교한 결과를 보여줍니다. 실험 결과에서 몇 가지 중요한 발견 사항을 요약하면 다음과 같습니다.
-
제안된 모델 12는 신경망 기반 접근법 중 거의 최첨단 성과를 달성했습니다. WordPiece 길이가 510보다 긴 프롬프트 1, 2, 8의 경우, 결과가 0.761에서 0.772로 향상되었습니다. Longformer는 긴 텍스트를 인코딩하는 데 강점이 있지만, 프롬프트 1, 2, 8에서 Longformer를 직접 사용한 결과는 표 3에 제시된 방법들에 비해 성능이 낮았습니다. 이는 에세이를 인코딩하고 점수를 채점하는 데 있어 제안된 프레임워크의 효과를 보여줍니다. 우리는 또한 Yang et al.(2020)이 제안한 BERT2를 재구현했으나, 구현 결과는 원래 보고된 성능만큼 우수하지 않았습니다. Uto et al.(2020)의 연구는 더 나은 결과(QWK 0.801)를 얻었지만, 이들의 시스템에서 사용된 수작업 특징을 제외한 순수 신경망 기반 결과(QWK 0.730)와 비교했을 때, 제안된 방법이 더 나은 성능을 보였습니다. 이는 제안된 신경망 접근법의 강력한 에세이 인코딩 능력을 입증합니다.
-
모델 11과 모델 4, 6을 비교했을 때, 제안된 모델은 LSTM 기반 모델 대신 다중 규모 특징을 사용하여 에세이를 인코딩하며, 동일한 회귀 손실 함수를 사용해 모델을 최적화합니다. 제안된 모델은 단순히 표현 방식을 변경했을 뿐인데도, 성능이 0.764에서 0.782로 크게 향상되었습니다. 이는 장문 작업에서 다중 규모 표현의 강력한 인코딩 능력을 입증합니다. 이전에는 BERT를 사용하는 기존 방식이 모델 4와 6의 성능을 능가하지 못했지만, 제안된 다중 규모 접근법은 이를 뛰어넘는 성과를 보였습니다.
4.5 Further analysis


 다중 규모 표현(Multi-scale Representation)
다중 규모 표현(Multi-scale Representation)
우리는 다중 규모 에세이 표현을 공동 학습 과정에 포함시킴으로써 얻어진 효과를 추가적으로 분석했습니다. 표 4와 표 5는 각각 ASAP 데이터 세트와 CRP 데이터 세트에서 서로 다른 특징 규모를 사용하는 모델의 성능을 보여줍니다. 이 모델들은 MSE 손실로 학습되었으며, 전이 학습을 사용하지 않았습니다. 표 4와 표 5의 결과는 다음과 같은 유사한 결론을 제공합니다:
- 문서 규모와 토큰 규모의 특징을 결합한 BERT-DOC-TOK 모델은 문서 규모 특징만을 사용하는 BERT-DOC 모델이나 토큰 규모 특징만을 사용하는 BERT-TOK 모델보다 더 나은 성능을 보였습니다. 이는 두 가지 특징을 결합했을 때, 다중 규모 에세이 표현이 더 많은 이점을 제공한다는 것을 보여줍니다.
- 다중 세그먼트 규모 특징을 추가로 포함한 BERT-DOC-TOK-SEG 모델은 BERT-DOC-TOK 모델보다 훨씬 더 나은 성능을 보였습니다. 이는 제안된 다중 규모 에세이 표현 방식이 다양한 작업에서 효과적이고 일반화 가능하다는 것을 입증합니다.
Reasons for Effectiveness of Multi-scale Representation
다중 규모 표현의 효과는 실험적으로 입증되었지만, 그 이유를 더 깊이 탐구했습니다. 우리는 효과가 단순히 긴 시퀀스를 처리할 수 있는 능력 때문인지, 아니면 다중 규모 자체 때문인지 분석했습니다. Longformer는 긴 텍스트를 처리하는 데 강점을 가지고 있으므로, Longformer-DOC과 Longformer-DOC-TOK-SEG의 결과를 비교했습니다. 유의미성 테스트 결과, Longformer-DOC-TOK-SEG가 Longformer-DOC를 능가하는 향상은 대부분의 경우에서 통계적으로 유의미함()이 나타났습니다.
- Longformer-DOC은 긴 시퀀스를 인코딩할 수 있음에도 불구하고 성능이 낮았습니다. 이는 단순히 긴 시퀀스를 처리할 수 있는 능력만으로는 우수한 에세이 채점 시스템을 구성하기에 충분하지 않음을 시사합니다.
- Longformer-DOC-TOK-SEG는 Longformer-DOC보다 유의미하게 우수한 성능을 보였습니다. 이는 본 모델의 효과가 긴 텍스트를 처리하는 능력뿐만 아니라 다중 규모 특징을 사용해 에세이를 인코딩하는 데에서 비롯된 것임을 보여줍니다.
이 결과는 에세이의 다양한 수준에서 특징을 고려하여 점수를 더 정확히 예측한다는 직관과 일치합니다. 다중 규모 특징은 AES 작업의 데이터가 부족하여 사전 학습 모델에서 효과적으로 학습되지 못하는 경우, 명시적으로 모델링되어야 하며, 이를 통해 사전 학습 모델의 강력한 언어 지식과 결합할 수 있습니다.
Transfer Learning with Multiple Losses and R-Drop
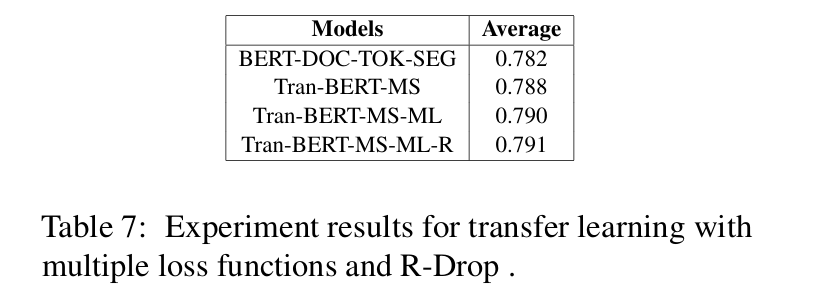
우리는 사전 학습에 다중 손실 함수를 추가하고 R-Drop을 적용한 효과를 추가적으로 탐구했습니다. 표 7에서 볼 수 있듯이, 도메인 외부 데이터를 학습하는 사전 학습 단계를 도입함으로써, Tran-BERT-MS 모델의 성능이 BERT-DOC-TOK-SEG 모델의 0.782에서 0.788로 향상되었습니다.
다중 손실 함수로 공동 학습을 수행하는 Tran-BERT-MS-ML 모델은 성능을 0.788에서 0.790으로 더욱 향상시켰습니다. 이는 MR 손실이 순위 정보를 제공하고, SIM 손실이 전체 점수 분포 정보를 고려하기 때문이라고 판단됩니다. 다양한 손실 함수는 최적화 방향에 서로 다른 긍정적인 영향을 미치며, 앙상블 효과를 냅니다.
마지막으로, Tran-BERT-MS-ML 모델에 R-Drop을 추가로 적용한 Tran-BERT-MS-ML-R 모델은 QWK를 약간 더 향상시켰습니다. 이는 R-Drop이 규제화(regularization) 역할을 수행하여 모델의 일반화 성능을 강화했기 때문입니다.
5. Conclusion and Future Work
이 논문에서는 사전 학습된 언어 모델을 기반으로 한 새로운 다중 규모 에세이 표현 방식을 제안하고, AES 작업에서 이를 위해 다중 손실 함수와 전이 학습을 활용했습니다. 우리는 신경망 기반 모델 중 거의 최첨단 성과를 달성했으며, 다중 규모 표현 방식이 긴 텍스트 작업에서 상당한 장점을 가진다는 점을 보여주었습니다.
향후 연구 방향으로는 소프트 다중 규모 표현(soft multi-scale representation)을 탐구하는 것이 포함될 수 있습니다. 보다 합리적인 세그먼트 규모를 설정하기 위해 언어학적 지식을 도입하면, 추가적인 성능 향상을 가져올 가능성이 있습니다.
