The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, David Ha
인공지능의 큰 과제 중 하나는 새로운 지식을 발견하고 과학적 연구를 수행할 수 있는 에이전트를 개발하는 것입니다. 현재의 최첨단 모델들은 이미 인간 과학자의 조력자로 사용되고 있으며, 예를 들어 아이디어를 브레인스토밍하거나 코드를 작성하거나 예측 작업을 수행하는 데 사용되고 있습니다. 그러나 이러한 모델들은 여전히 과학적 과정의 일부분만 수행할 수 있습니다. 이 논문은 완전 자동화된 과학적 발견을 위한 최초의 포괄적 프레임워크를 제시하여, 첨단 대형 언어 모델(LLM)이 독립적으로 연구를 수행하고 그 결과를 전달할 수 있게 합니다.
우리는 The AI Scientist를 소개하며, 이는 새로운 연구 아이디어를 생성하고, 코드를 작성하며, 실험을 실행하고, 결과를 시각화하고, 연구 결과를 전체 과학 논문 형태로 설명하고, 이후에는 이를 평가하기 위한 시뮬레이션된 리뷰 프로세스를 실행합니다. 원칙적으로 이 프로세스는 반복될 수 있어 열린 방식으로 아이디어를 발전시키고 점점 확장되는 지식 아카이브에 추가할 수 있으며, 이는 인간 과학자 공동체와 유사하게 작동합니다.
우리는 이 접근법의 다재다능함을 보여주기 위해 기계 학습의 세 가지 하위 분야(diffusion modeling, transformer-based Language modeling, learning dynamics)에 이를 적용했습니다. 각 아이디어는 구현되어 전체 논문으로 개발되었으며, 논문 한 편당 15달러 미만의 비용이 들어가는 것을 보여주며 연구를 민주화하고 과학적 진전을 가속화할 가능성을 입증했습니다.
생성된 논문을 평가하기 위해 자동화된 리뷰어를 설계하고 검증했으며, 이 리뷰어는 논문 점수를 평가하는 데 있어서 인간에 근접한 성능을 보였습니다. The AI Scientist는 주요 기계 학습 컨퍼런스의 기준을 초과하는 논문을 작성할 수 있으며, 이는 새로운 기계 학습 과학적 발견의 시대를 열었다고 볼 수 있습니다.
1. Introduction
현대 과학적 방법론은 계몽주의 시대의 가장 위대한 성과 중 하나로 볼 수 있습니다. 전통적으로 인간 연구자는 배경 지식을 수집하고, 테스트할 가능성 있는 가설을 초안 작성하며, 평가 절차를 구성하고, 다양한 가설에 대한 증거를 수집한 뒤, 최종적으로 발견한 내용을 평가하고 전달합니다. 이후 작성된 원고는 동료 검토를 거쳐 이후의 개선 과정을 거치게 됩니다. 이 절차는 과학과 기술에서 수많은 돌파구를 가져왔으며, 인간의 삶의 질을 향상시키는 데 기여해 왔습니다.
그러나 이러한 반복적인 과정은 본질적으로 인간 연구자의 창의력, 배경 지식, 유한한 시간에 의해 제한됩니다. 일반적인 과학적 발견을 자동화하려는 시도는 최소 1970년대 초반부터 연구 커뮤니티의 오랜 목표였습니다. 예를 들어 Automated Mathematician(Lenat, 1977; Lenat and Brown, 1984)과 DENDRAL(Buchanan and Feigenbaum, 1981) 같은 컴퓨터 지원 작업이 초기 사례입니다. AI 분야에서는 AI 자체를 사용하여 AI 연구를 자동화할 가능성을 구상한 바 있습니다(Ghahramani, 2015; Schmidhuber, 1991, 2010a,b, 2012). 이는 "AI를 생성하는 알고리즘"(Clune, 2019)으로 이어졌습니다.
최근에는 기반 모델(foundation models)의 일반적인 기능이 크게 발전하였습니다(Anthropic, 2024; Google DeepMind Gemini Team, 2023; Llama Team, 2024; OpenAI, 2023). 그러나 현재까지 이러한 모델은 과학적 프로세스의 개별적인 부분(예: 과학 논문 작성(Altmäe et al., 2023; Dinu et al., 2024), 아이디어 브레인스토밍(Baek et al., 2024; Girotra et al., 2023; Wang et al., 2024b), 코딩 지원(Gauthier, 2024))을 가속화하는 데에만 사용되었습니다. 연구 프로젝트를 완전히 인간 개입 없이 실행할 수 있는 가능성은 아직 입증되지 않았습니다.
전통적인 연구 자동화 접근법은 잠재적 발견의 탐색 공간을 신중히 제한하는 데 의존해 왔습니다. 이는 탐색 범위를 크게 제한하고 상당한 인간 전문 지식과 설계를 요구합니다. 예를 들어, 재료 발견(Merchant et al., 2023; Pyzer-Knapp et al., 2022; Szymanski et al., 2023)과 합성 생물학(Hayes et al., 2024; Jumper et al., 2021)에서 중요한 발전은 잘 정의된 매개변수를 가진 영역으로 탐색을 제한함으로써 이루어졌습니다. 이는 목표 지점을 겨냥한 진전을 가능하게 했지만, 보다 광범위하고 열린 탐구를 제한하고 과학적 과정의 일부 하위 집합만 다루는 결과를 가져왔습니다. 또한 기계 학습 분야에서는 연구 자동화가 대개 초매개변수 및 구조 검색(He et al., 2021; Hutter et al., 2019; Lu et al., 2022b; Wan et al., 2021, 2022)이나 알고리즘 발견(Alet et al., 2020; Chen et al., 2024b; Kirsch et al., 2019; Lange et al., 2023a,b; Lu et al., 2022a; Metz et al., 2022) 같은 손수 설계된 탐색 공간 내에서 제한적으로 이루어졌습니다.
최근 대형 언어 모델(LLM)의 발전은 탐색 공간을 보다 일반화된 코드 수준의 솔루션으로 확장할 가능성을 보여주었습니다(Faldor et al., 2024; Lehman et al., 2022; Lu et al., 2024a; Ma et al., 2023). 그러나 이러한 접근법 역시 엄격히 정의된 탐색 공간과 목표에 의해 제약을 받으며, 발견 가능성의 폭과 깊이를 제한합니다.
이 논문에서는 최신 기반 모델의 발전을 활용하여 The AI Scientist를 소개합니다. 이는 연구의 시작부터 끝까지 논문을 생성할 수 있는 완전 자동화되고 확장 가능한 파이프라인입니다. 광범위한 연구 방향과 간단한 초기 코드베이스를 제공받으면, The AI Scientist는 아이디어 구상, 문헌 조사, 실험 계획, 실험 반복, 논문 작성 및 동료 검토를 통해 통찰력 있는 논문을 생성합니다. 더욱이, 원칙적으로 The AI Scientist는 이전 과학적 발견을 기반으로 다음 세대의 아이디어를 개선하며 무한히 반복 실행될 수 있습니다. 이는 느린 과학적 반복의 속도를 놀라울 정도로 낮은 비용(논문 한 편당 약 15달러)에 크게 가속화할 수 있으며, 21세기의 핵심 도전에 대처하는 데 필요한 과학적 돌파구를 얻기 위해 전 세계의 증가하는 컴퓨팅 자원을 활용하는 첫걸음이 됩니다. 여기에서는 기계 학습(ML) 응용 프로그램에 초점을 맞추지만, 이 접근법은 실험을 자동으로 실행할 수 있는 적절한 방법이 주어진다면 생물학이나 물리학 등 거의 모든 다른 학문 분야에도 일반적으로 적용될 수 있습니다(Arnold, 2022; Kehoe et al., 2015; Zucchelli et al., 2021).
최신 대형 언어 모델(LLM) 프레임워크에서 chain-of-thought(Wei et al., 2022)과 self-reflection(Shinn et al., 2024)과 같은 기능을 활용함으로써 The AI Scientist는 독자적으로 과학적 아이디어와 가설을 생성하고 이를 테스트하기 위한 계획을 수립할 수 있습니다. 다음으로, The AI Scientist는 첨단 코딩 보조 도구인 Aider(Gauthier, 2024)를 사용하여 실험 "템플릿"에 기반한 코드 수준의 변경을 구현하고 실험을 실행하여 계산 결과를 수집합니다. 그런 다음 이 결과를 활용하여 과학 논문을 작성합니다. The AI Scientist는 표준 기계 학습 학회의 가이드라인에 따라 논문 품질을 평가하는 자동화된 논문 검토 프로세스를 수행합니다. 마지막으로, The AI Scientist는 완성된 아이디어와 리뷰어 피드백을 과학적 발견 아카이브에 추가하며, 이 과정은 반복됩니다. 중요한 점은 The AI Scientist가 생성한 논문과 실험 산출물이 인간 과학자들이 그 결과를 사후적으로 쉽게 해석하고 판단할 수 있게 한다는 점입니다.
요약된 기여점은 다음과 같습니다:
-
우리는 최첨단 대형 언어 모델(LLM)을 활용하여 기계 학습 연구에서 완전 자동화된 과학적 발견을 위한 최초의 엔드 투 엔드 프레임워크를 소개합니다(3장 참조). 이 완전 자동화 프로세스에는 아이디어 생성, 실험 설계 및 실행, 결과 시각화와 논문 작성이 포함됩니다.
-
생성된 논문의 품질을 평가하기 위해 4장에서 설명된 foundation model 기반 리뷰 프로세스를 소개합니다. 이 프로세스는 ICLR 2022 OpenReview 데이터에서 65%와 66%의 균형 정확도(사람과 거의 동등한 성능)를 기록하며, 여러 평가 메트릭에서 인간 수준의 성능을 달성합니다. 리뷰는 The AI Scientist가 "출판"할 최고의 아이디어를 선택하고 이러한 발견을 반복적으로 구축하여 인간 과학자 공동체와 마찬가지로 발전할 수 있게 합니다.
-
The AI Scientist는 일주일 동안 수백 개의 흥미롭고 중간 수준의 품질 논문을 생성할 수 있습니다. 이 보고서에서는 확산 모델링, 언어 모델링, 및 grokking에 대한 새로운 통찰을 강조하는 논문 일부에 초점을 맞춥니다. 5장에서 선택된 논문의 심층 사례 연구를 수행하며, 6장에서 집계된 결과를 제시합니다.
-
8장과 9장에서 한계점, 윤리적 고려 사항, 접근법의 미래 전망에 대한 광범위한 논의를 통해 논문을 마무리합니다.
2. Background
대형 언어 모델(Large Language Models)
이 논문에서 우리는 대형 언어 모델(LLM, Anthropic, 2023; Google DeepMind Gemini Team, 2023; Llama Team, 2024; OpenAI, 2023; Zhu et al., 2024)을 기반으로 자동화된 과학자를 설계했습니다. 이 모델은 순차적인 토큰(단어와 유사)의 조건부 확률 을 학습하며, 테스트 시 샘플링을 통해 텍스트를 생성합니다. 방대한 데이터와 모델 스케일링 덕분에 LLM은 일관성 있는 텍스트를 생성할 뿐만 아니라 인간 수준의 능력, 즉 상식적 지식(Talmor et al., 2019), 추론(Wei et al., 2022), 그리고 코드 작성 능력(Chen et al., 2021; Xu et al., 2022)도 발휘할 수 있습니다.
LLM 에이전트 프레임워크(LLM Agent Frameworks)
LLM의 전형적인 응용은 모델을 "에이전트" 프레임워크(Wang et al., 2024a)로 내장하여 다음과 같은 구조를 포함합니다:
- Few-shot prompting(Brown et al., 2020): 언어 질의를 구조화함.
- Chain-of-thought(Wei et al., 2022): 추론 과정을 장려함.
- Self-reflection(Shinn et al., 2024): 출력물을 반복적으로 수정하도록 모델에 요청함.
이러한 기술은 언어 모델의 맥락 학습 능력(Olsson et al., 2022)을 활용하여 다양한 작업에서 성능, 견고성 및 신뢰성을 크게 향상시킬 수 있습니다.
Aider: LLM 기반 코딩 보조 도구
우리의 자동화된 과학자는 아이디어를 코드로 직접 구현하며, 최첨단 오픈 소스 코딩 보조 도구인 Aider(Gauthier, 2024)를 사용합니다. Aider는 요청된 기능을 구현하거나 버그를 수정하거나 기존 코드베이스를 리팩토링하도록 설계된 에이전트 프레임워크입니다. 이론적으로 Aider는 어떤 LLM이라도 사용할 수 있지만, 최첨단 모델과 함께 사용할 경우 GitHub의 실제 이슈로 구성된 SWE Bench(Jimenez et al., 2024) 벤치마크에서 18.9%의 성공률을 달성합니다. 이 연구에서 추가된 새로운 혁신과 결합하여, 이 수준의 신뢰성은 기계 학습 연구 프로세스를 처음으로 완전히 자동화할 수 있게 합니다.
3. The AI Scientist
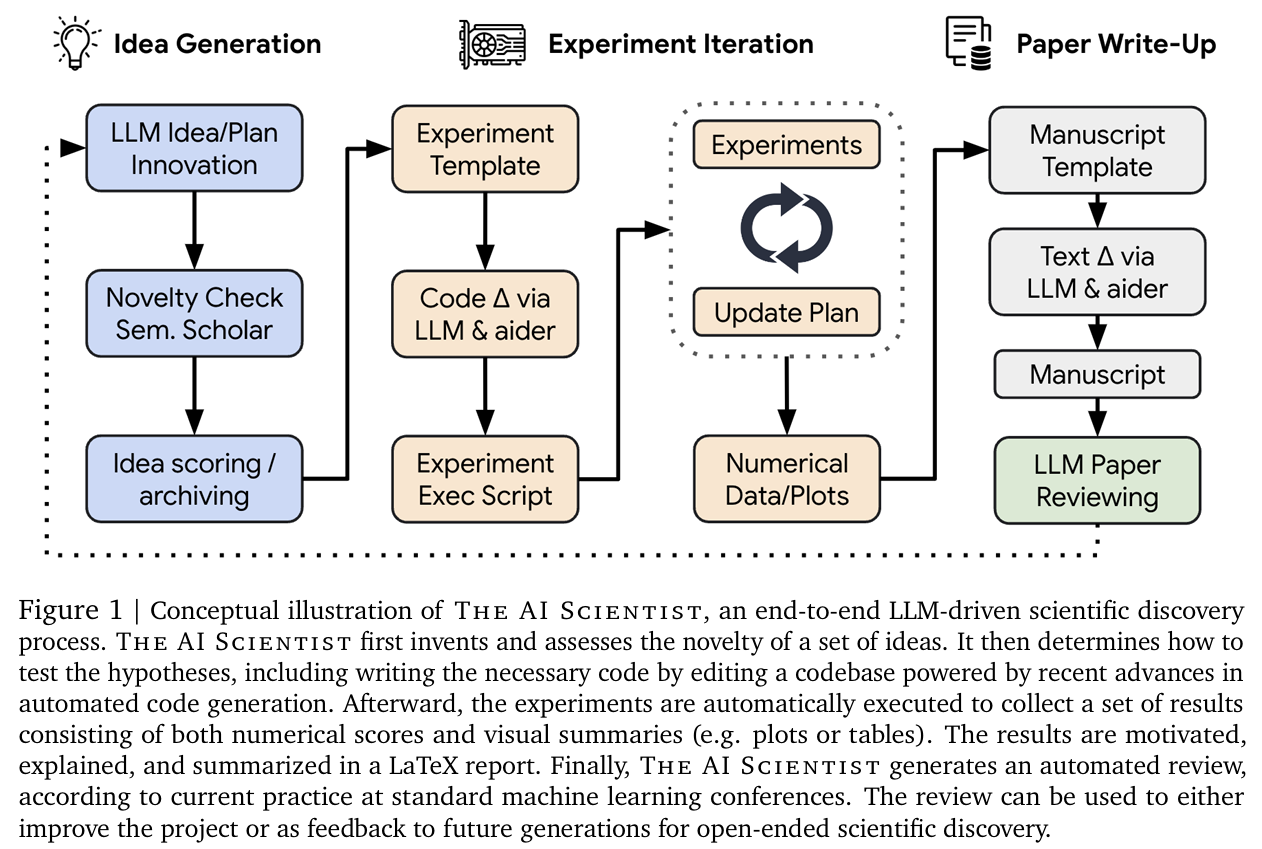
개요 (Overview)
The AI Scientist는 세 가지 주요 단계를 포함합니다(Figure 1 참조):
- 아이디어 생성 (Idea Generation)
- 실험 반복 (Experimental Iteration)
- 논문 작성 (Paper Write-up)
논문 작성 이후에는 생성된 논문의 품질을 평가하기 위해 LLM 생성 리뷰를 도입하고 검증합니다(4장 참조). The AI Scientist는 인기 있는 모델이나 벤치마크에서 간단한 기초 훈련 과정을 재현하는 경량 코드 템플릿으로 시작합니다. 예를 들어, 셰익스피어 작품에 대해 작은 트랜스포머 모델을 훈련하는 코드(Karpathy, 2022)와 같이 자연어 처리의 증명 개념 훈련 과정을 포함할 수 있습니다. The AI Scientist는 연구의 어떤 방향으로도 탐구할 자유를 가집니다. 템플릿에는 스타일 파일과 섹션 헤더가 포함된 LaTeX 폴더와 간단한 플로팅 코드도 포함됩니다. 템플릿에 대한 자세한 내용은 6장에서 제공되지만, 일반적으로 각 실행은 해당 주제와 관련된 소규모 대표 실험으로 시작됩니다. 이러한 소규모 실험은 계산 효율성과 계산 자원의 제약 때문이지, 이 방법론의 근본적인 한계는 아닙니다. 모든 단계의 프롬프트는 부록 A에 제공됩니다.
1. 아이디어 생성 (Idea Generation)
기초 템플릿이 주어지면, The AI Scientist는 먼저 다양한 새로운 연구 방향을 "브레인스토밍"합니다. 우리는 진화적 계산 및 열린 탐구(open-endedness) 연구(Brant and Stanley, 2017; Lehman et al., 2008; Stanley, 2019; Stanley et al., 2017)에서 영감을 얻어, LLM을 변형 연산자로 사용하여 아이디어 아카이브를 점진적으로 확장합니다(Faldor et al., 2024; Lehman et al., 2022; Lu et al., 2024b; Zhang et al., 2024). 각 아이디어는 설명, 실험 실행 계획, 그리고 흥미로움, 참신성, 실현 가능성에 대한 (자체 평가된) 수치 점수로 구성됩니다. 각 반복에서, 우리는 기존 아카이브(완료된 이전 아이디어의 수치 리뷰 점수를 포함할 수 있음)를 조건으로 새롭고 흥미로운 연구 방향을 생성하도록 언어 모델을 프롬프트합니다. 우리는 chain-of-thought(Wei et al., 2022)과 self-reflection(Shinn et al., 2024)을 여러 차례 실행하여 각 아이디어를 세밀히 다듭고 발전시킵니다. 아이디어 생성 이후에는 Semantic Scholar API(Fricke, 2018)와 웹 접근을 도구로 연결하여 기존 문헌과 너무 유사한 아이디어를 제거합니다(Schick et al., 2024).
2. 실험 반복 (Experiment Iteration)
아이디어와 템플릿이 주어지면, The AI Scientist는 제안된 실험을 실행하고 이후 작성 작업을 위해 결과를 시각화하는 두 번째 단계로 진행합니다. The AI Scientist는 먼저 실행할 실험 목록을 계획하고 이를 순서대로 실행하기 위해 Aider를 사용합니다. 우리는 실패하거나 시간이 초과된 경우 발생하는 오류를 Aider로 반환하여 최대 4회까지 코드를 수정하고 재시도할 수 있게 함으로써 이 프로세스를 더 견고하게 만듭니다.
각 실험이 완료된 후, Aider는 결과를 받고 실험 저널 형식으로 메모를 작성하도록 지시받습니다. 현재는 텍스트만 조건으로 사용하지만, 미래 버전에서는 데이터 시각화나 기타 모달리티도 포함될 수 있습니다. 결과에 따라 다음 실험을 재계획하고 구현합니다. 이 과정은 최대 5회 반복됩니다. 실험이 완료되면, Aider는 파이썬을 사용하여 논문용 플롯을 생성하도록 플로팅 스크립트를 편집하도록 지시받습니다. The AI Scientist는 각 플롯에 포함된 내용을 설명하는 메모를 작성하여 저장된 플롯과 실험 노트가 논문 작성에 필요한 모든 정보를 제공할 수 있도록 합니다. 모든 단계에서 Aider는 실행 이력을 확인할 수 있습니다.
3. 논문 작성 (Paper Write-up)
The AI Scientist의 세 번째 단계는 LaTeX 형식의 표준 기계 학습 학회 발표 스타일로 진행 상황을 간결하고 정보에 맞게 작성하는 것입니다. LaTeX 작성은 숙련된 인간 연구자에게도 시간이 걸릴 수 있기 때문에, 이 프로세스를 강화하기 위해 여러 단계를 거칩니다:
-
(a) 섹션별 텍스트 생성: 기록된 메모와 플롯이 Aider로 전달되어 템플릿의 빈 학회 섹션을 순서대로 채우도록 요청됩니다. 이는 도입부, 배경, 방법, 실험 설정, 결과, 결론 순으로 진행됩니다(관련 연구 제외). 언어 모델은 이전에 작성된 모든 섹션을 맥락으로 참조합니다. 각 섹션에 포함할 내용을 간략히 설명하는 팁과 가이드라인(“How to ML Paper” 가이드 기반)이 제공됩니다. 각 섹션은 작성 중에 한 차례의 self-reflection으로 초기 다듬기를 거칩니다. 이 단계에서는 인용 없이 뼈대만 작성하도록 요청하며, 관련 연구는 다음 단계에서 완료됩니다.
-
(b) 참고문헌 웹 검색: 아이디어 생성과 마찬가지로 The AI Scientist는 Semantic Scholar API를 최대 20회 호출하여 관련 연구를 탐색하고, 비교 및 대조할 논문을 선택합니다. 이 과정은 누락된 인용을 채우고, 필요한 논문을 더하는 데 사용됩니다. 선택된 논문마다 짧은 설명과 인용 위치 및 방법이 추가됩니다. 이 정보는 Aider로 전달되며, 논문의 BibTeX가 LaTeX 파일에 자동 추가되어 정확성을 보장합니다.
-
(c) 정제: 위 단계를 거친 초안은 종종 장황하거나 반복적인 경우가 많습니다. 이를 해결하기 위해 self-reflection을 섹션별로 한 차례 더 실행하여 중복 정보를 제거하고 논문의 논점을 간소화합니다.
-
(d) 컴파일: LaTeX 템플릿이 모든 결과와 함께 채워지면 LaTeX 컴파일러에 전달됩니다. LaTeX 린터(linter)를 사용하여 오류를 확인하고 Aider가 자동으로 문제를 수정하도록 합니다.
4. Automated Paper Reviewing
An LLM Reviewer Agent
효과적인 과학 공동체의 핵심 구성 요소 중 하나는 리뷰 시스템입니다. 이 시스템은 과학 논문의 품질을 평가하고 개선합니다. 대형 언어 모델을 사용하여 이러한 과정을 모방하기 위해, 우리는 Neural Information Processing Systems (NeurIPS) 학회의 리뷰 가이드라인에 기반하여 논문 리뷰를 수행할 GPT-4o 기반 에이전트(OpenAI, 2023)를 설계했습니다.
리뷰 에이전트는 PyMuPDF 파싱 라이브러리를 사용하여 PDF 원고의 원시 텍스트를 처리합니다. 출력물에는 다음 항목이 포함됩니다:
- 수치 점수(타당성, 발표, 기여도, 전반적인 평가, 신뢰도),
- 약점과 강점의 목록,
- 초기 이진 결정(수락 또는 거절).
이러한 결정은 이후 리뷰어 점수를 활용하여 임계값 설정으로 보정(post-calibration)될 수 있습니다. 우리는 이 자동화된 리뷰 프로세스를 활용하여 The AI Scientist가 생성한 논문의 초기 평가를 수행합니다. 전체 리뷰 프롬프트 템플릿은 부록 A.4에 제공됩니다.
Evaluating the Automated Reviewer
자동화된 리뷰어의 성능을 평가하기 위해, 우리는 500개의 ICLR 2022 논문에 대한 자동으로 생성된 결정과 OpenReview 데이터셋(Berto, 2024)에서 추출한 실제 데이터(ground truth)를 비교했습니다. 앞선 섹션과 유사하게, 우리는 LLM 에이전트의 최근 발전을 결합하여 의사결정 과정을 더욱 강건하게 만들었습니다. 구체적으로, 다음과 같은 방법을 활용하여 기본 LLM의 의사결정 과정을 개선했습니다:
- Self-reflection(Shinn et al., 2024),
- Few-shot 예제 제공(Wei et al., 2022),
- 응답 집합화(ensembling)(Wang et al., 2022).
GPT-4o를 활용한 The AI Scientist의 리뷰 절차는 다음을 결합하여 70%의 정확도를 달성했습니다:
- Self-reflection 5회 실행,
- 5개의 집합화된 리뷰,
- ICLR 2022 리뷰 가이드라인에서 가져온 1-shot 리뷰 예제.
그 후, 우리는 LLM 기반 메타 리뷰를 수행했습니다. 이는 에이전트가 Area Chair 역할을 하도록 프롬프트(Wang et al., 2022)합니다(전체 프롬프트는 부록 A.4에 제공됨).
이 정확도 수치는 NeurIPS 2021 일관성 실험(Beygelzimer et al., 2021)에서 인간 리뷰어가 기록한 73% 정확도보다 낮지만, 자동화된 리뷰어는 다음과 같은 성과를 보였습니다:
- F1 점수에서 인간 수준을 초월한 성능(0.57 대 0.49),
- AUC에서 인간 수준의 성능(둘 다 0.65).
결정을 6점(NeurIPS 리뷰 가이드라인에서 "Weak Accept"로 간주되는 점수)으로 임계값 설정했을 때 이러한 결과가 나타났습니다. 이 점수는 대체로 채택된 논문의 평균 점수에 해당합니다.
고려된 ICLR 2022 논문 데이터셋은 매우 클래스 불균형 상태에 있습니다. 즉, 훨씬 더 많은 수의 거절된 논문이 포함되어 있습니다. 논문에 대한 균형 잡힌 데이터셋을 고려했을 때, The AI Scientist의 리뷰 절차는 인간 수준의 정확도를 달성합니다(0.65% 대 0.66%). 게다가, False Negative Rate (FNR)은 인간 기준선보다 훨씬 낮습니다(0.39 대 0.52). 따라서, LLM 기반 리뷰 에이전트는 높은 품질의 논문을 거절하는 비율이 더 낮습니다. 반면, False Positive Rate (FPR)는 더 높습니다(0.31 대 0.17), 이는 향후 개선의 여지를 강조합니다.
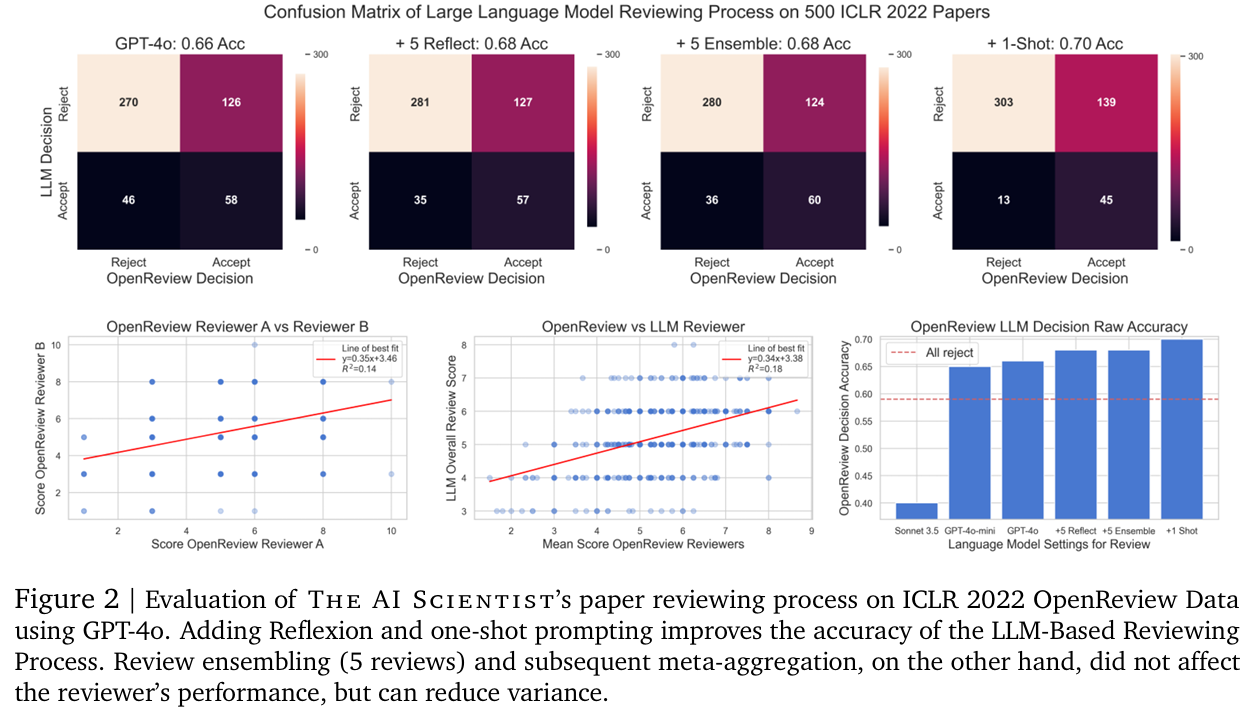 자동화된 리뷰어의 성능을 추가로 검증하기 위해, 우리는 각 논문에 대해 익명 OpenReview 리뷰어를 무작위로 샘플링하여 짝을 이루는 리뷰어 간의 전체 논문 점수의 일관성(Figure 2, bottom-left)과 모든 리뷰어의 평균 점수와 LLM 점수 간의 일관성(Figure 2, bottom-middle)을 비교했습니다. 500개의 ICLR 2022 논문 세트를 기준으로, 두 명의 인간 리뷰어 간 점수의 상관관계는 0.14로, LLM 점수와 모든 리뷰어 평균 점수 간 상관관계(0.18)보다 작음을 발견했습니다. 전반적으로, 모든 메트릭에 걸쳐 결과는 LLM 기반 리뷰가 유의미한 피드백(D’Arcy et al., 2024)을 제공할 뿐만 아니라, 개별 인간 리뷰어들 간의 일치도보다 평균 인간 리뷰어 점수와 더 잘 일치한다는 것을 시사합니다.
자동화된 리뷰어의 성능을 추가로 검증하기 위해, 우리는 각 논문에 대해 익명 OpenReview 리뷰어를 무작위로 샘플링하여 짝을 이루는 리뷰어 간의 전체 논문 점수의 일관성(Figure 2, bottom-left)과 모든 리뷰어의 평균 점수와 LLM 점수 간의 일관성(Figure 2, bottom-middle)을 비교했습니다. 500개의 ICLR 2022 논문 세트를 기준으로, 두 명의 인간 리뷰어 간 점수의 상관관계는 0.14로, LLM 점수와 모든 리뷰어 평균 점수 간 상관관계(0.18)보다 작음을 발견했습니다. 전반적으로, 모든 메트릭에 걸쳐 결과는 LLM 기반 리뷰가 유의미한 피드백(D’Arcy et al., 2024)을 제공할 뿐만 아니라, 개별 인간 리뷰어들 간의 일치도보다 평균 인간 리뷰어 점수와 더 잘 일치한다는 것을 시사합니다.
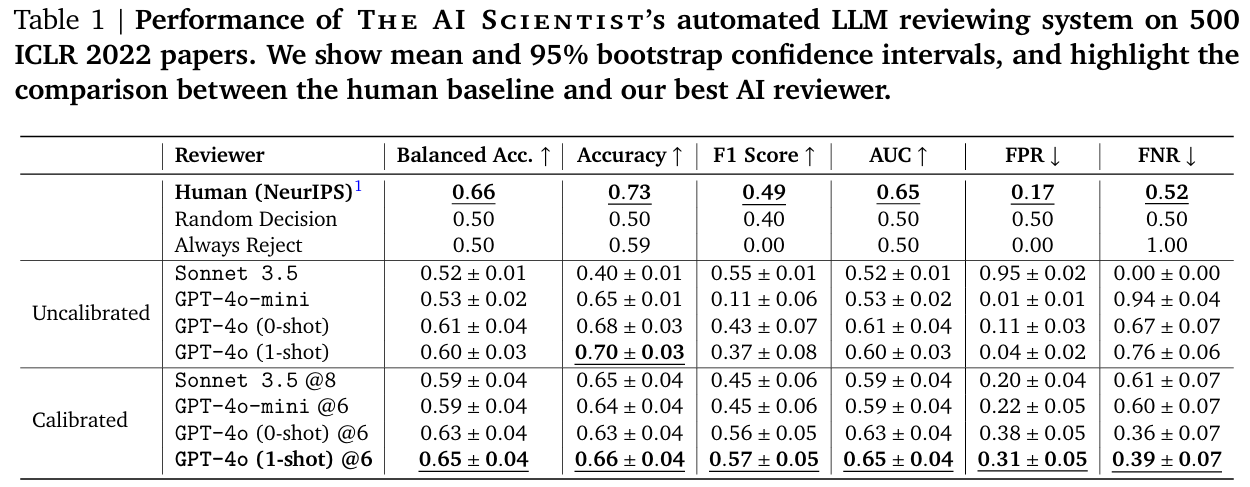 각 리뷰는 API 비용으로 $0.25에서 $0.50 사이에서 생성됩니다. 우리는 추가적으로 다양한 다른 기반 모델들의 리뷰 성능을 비교했습니다. Claude Sonnet 3.5(Anthropic, 2024)와 GPT-4o-mini는 더 비용 효율적인 접근 방식을 제공했지만, 성능은 상당히 떨어졌습니다(Table 1 참조). 게다가, Sonnet 3.5에서는 지속적인 과도한 낙관적 편향(over-optimism bias)으로 인해 점수를 8로 임계값 설정하여 보정된 결과를 얻어야 했습니다. Llama 3.1 405B(Llama Team, 2024)는 리뷰어 출력 템플릿을 일관되게 따르는 데 어려움을 겪었습니다. 우리는 커뮤니티를 위해 이 코드를 오픈소스로 제공하여 새로운 흥미로운 LLM 벤치마크를 제시합니다.
각 리뷰는 API 비용으로 $0.25에서 $0.50 사이에서 생성됩니다. 우리는 추가적으로 다양한 다른 기반 모델들의 리뷰 성능을 비교했습니다. Claude Sonnet 3.5(Anthropic, 2024)와 GPT-4o-mini는 더 비용 효율적인 접근 방식을 제공했지만, 성능은 상당히 떨어졌습니다(Table 1 참조). 게다가, Sonnet 3.5에서는 지속적인 과도한 낙관적 편향(over-optimism bias)으로 인해 점수를 8로 임계값 설정하여 보정된 결과를 얻어야 했습니다. Llama 3.1 405B(Llama Team, 2024)는 리뷰어 출력 템플릿을 일관되게 따르는 데 어려움을 겪었습니다. 우리는 커뮤니티를 위해 이 코드를 오픈소스로 제공하여 새로운 흥미로운 LLM 벤치마크를 제시합니다.
LLM Reviewer Ablations
우리는 GPT-4o에 대한 다양한 프롬프트 설정을 비교한 결과, Reflexion(+2%)과 one-shot prompting(+2%)이 리뷰 정확도를 크게 향상시키는 데 도움이 된다는 것을 발견했습니다(Figure 2, 위쪽과 오른쪽 아래 참조). 반면, review ensembling은 리뷰어의 성능을 크게 개선하지는 못했지만 분산을 줄이는 데는 기여했습니다. 이후 섹션에서는 다음과 같은 구성을 가진 최상의 리뷰어인 GPT-4o를 사용했습니다:
- Self-reflection 5회,
- 5개의 집합화된 리뷰,
- 메타 집계 단계,
- 1개의 few-shot 예제.
