Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, Qingsong Wen
Abstract
시계열 예측은 많은 현실 세계의 동적 시스템에서 중요한 역할을 하며, 오랫동안 연구되어 왔습니다. 자연어 처리(NLP) 및 컴퓨터 비전(CV)에서는 하나의 대형 모델이 여러 작업을 수행할 수 있는 반면, 시계열 예측 모델은 주로 특정 작업과 응용 분야에 맞춰 설계되는 경우가 많습니다. 사전 훈련된 기초 모델은 NLP 및 CV 분야에서 눈부신 발전을 이루었지만, 시계열 데이터 분야에서는 데이터 부족으로 인해 발전이 제한되었습니다.
최근 연구에 따르면 대형 언어 모델(LLM)은 복잡한 토큰 시퀀스에서 강력한 패턴 인식 및 추론 능력을 보유하고 있음이 밝혀졌습니다. 그러나 이러한 능력을 활용하기 위해서는 시계열 데이터와 자연어 간의 모달리티를 효과적으로 정렬하는 것이 여전히 과제로 남아 있습니다.
본 연구에서는 TIME-LLM을 소개합니다. 이는 LLM을 일반적인 시계열 예측에 활용할 수 있도록 재구성하는 프레임워크로, 기본 언어 모델을 변경하지 않은 채 활용하는 방식입니다. 먼저, 입력 시계열 데이터를 텍스트 프로토타입으로 변환한 후, 이를 고정된 LLM에 입력하여 두 개의 모달리티를 정렬합니다.
또한, LLM의 시계열 데이터 추론 능력을 향상시키기 위해 Prompt-as-Prefix(PaP)라는 기법을 제안합니다. 이 기법은 입력 컨텍스트를 풍부하게 하여 재구성된 입력 패치의 변환을 유도하는 역할을 합니다. 이후, LLM에서 변환된 시계열 패치는 최종적으로 투영(projection) 과정을 거쳐 예측 결과를 생성합니다.
포괄적인 실험을 통해 TIME-LLM이 최첨단 시계열 예측 모델보다 뛰어난 성능을 발휘하는 강력한 시계열 학습자임을 입증하였습니다. 특히, 소량의 학습 데이터를 활용하는 few-shot 학습과 사전 학습 없이 바로 활용하는 zero-shot 학습 환경에서도 우수한 성능을 보였습니다.
코드는 다음 링크에서 확인할 수 있습니다: https://github.com/KimMeen/Time-LLM
1. Introduction
시계열 예측은 많은 현실 세계의 동적 시스템에서 중요한 능력이며(Jin et al., 2023a), 수요 계획(Leonard, 2001) 및 재고 최적화(Li et al., 2022)부터 에너지 부하 예측(Liu et al., 2023a) 및 기후 모델링(Schneider & Dickinson, 1974)에 이르기까지 다양한 응용 분야에서 활용됩니다. 각 시계열 예측 작업은 일반적으로 광범위한 도메인 전문 지식과 특정 작업에 맞춘 모델 설계를 요구합니다. 이는 GPT-3(Brown et al., 2020), GPT-4(OpenAI, 2023), Llama(Touvron et al., 2023) 등과 같은 기초 언어 모델과는 극명한 대조를 이룹니다. 이러한 모델들은 few-shot 또는 zero-shot 설정에서 다양한 NLP 작업을 효과적으로 수행할 수 있습니다.
사전 훈련된 기초 모델(Pre-trained foundation models)인 대형 언어 모델(LLM)은 컴퓨터 비전(CV)과 자연어 처리(NLP)에서 빠른 발전을 이루었습니다. 반면, 시계열 모델링은 이러한 큰 발전을 누리지 못했지만, LLM의 인상적인 능력은 시계열 예측에 대한 적용 가능성을 시사합니다(Jin et al., 2023b). 시계열 예측 기법을 발전시키기 위해 LLM을 활용하는 데 필요한 몇 가지 주요 요소는 다음과 같습니다.
-
일반화 가능성(Generalizability): LLM은 few-shot 및 zero-shot 전이 학습에서 놀라운 능력을 보여주었습니다(Brown et al., 2020). 이는 개별 작업마다 처음부터 재학습할 필요 없이 다양한 도메인에서 일반화된 예측을 수행할 가능성을 시사합니다. 반면, 현재의 예측 방법들은 종종 특정 도메인에 국한됩니다.
-
데이터 효율성(Data efficiency): 사전 학습된 지식을 활용하여 LLM은 몇 개의 예제만으로 새로운 작업을 수행할 수 있는 능력을 보여주었습니다. 이러한 데이터 효율성은 과거 데이터가 제한적인 환경에서 예측을 가능하게 할 수 있습니다. 반면, 기존 방법들은 일반적으로 풍부한 도메인 내 데이터를 필요로 합니다.
-
추론 능력(Reasoning): LLM은 복잡한 패턴 인식과 추론 능력을 갖추고 있습니다(Mirchandani et al., 2023; Wang et al., 2023; Chu et al., 2023). 이러한 능력을 활용하면 학습된 고차원 개념을 적용하여 매우 정확한 예측을 수행할 수 있습니다. 기존의 비-LLM 방법들은 주로 통계적 접근 방식에 의존하며, 내재적인 추론 능력이 부족합니다.
-
멀티모달 지식(Multimodal knowledge): LLM 아키텍처와 훈련 기법이 발전하면서, 비전, 음성 및 텍스트와 같은 다양한 모달리티에서 더 다양한 지식을 습득할 수 있습니다(Ma et al., 2023). 이러한 지식을 활용하면 다양한 데이터 유형을 융합하여 더욱 강력한 예측을 수행할 수 있습니다. 기존 도구들은 서로 다른 지식 기반을 결합하여 활용하는 방법이 부족합니다.
-
쉬운 최적화(Easy optimization): LLM은 대규모 연산을 통해 한 번 학습되면, 추가적인 학습 없이도 예측 작업에 적용될 수 있습니다. 기존의 예측 모델을 최적화하려면 아키텍처 탐색과 하이퍼파라미터 튜닝이 필수적입니다(Zhou et al., 2023b).
요약하면, LLM은 기존의 전문화된 모델링 방식보다 더 일반적이고, 효율적이며, 통합된 예측 모델링 경로를 제공합니다. 따라서 이러한 강력한 모델을 시계열 데이터에 적응시키면 상당한 미개척 잠재력을 발휘할 수 있습니다.
이러한 이점을 실현하기 위해서는 시계열 데이터와 자연어 간의 모달리티를 효과적으로 정렬하는 것이 필수적입니다. 그러나 이것은 어려운 작업입니다. LLM은 이산적인 토큰을 기반으로 작동하는 반면, 시계열 데이터는 본질적으로 연속적인 특성을 가집니다. 또한, 시계열 패턴을 해석할 수 있는 지식과 추론 능력은 LLM의 사전 훈련 과정에서 자연스럽게 학습되지 않습니다. 따라서, LLM이 정확하고, 데이터 효율적이며, 특정 작업에 종속되지 않는 방식으로 시계열 예측 능력을 활성화하는 것은 여전히 해결해야 할 개방형 문제입니다.
본 연구에서는 TIME-LLM을 제안합니다. 이는 대형 언어 모델을 시계열 예측에 적응시키는 재구성(Reprogramming) 프레임워크로, 기본 LLM을 그대로 유지하면서 활용할 수 있도록 설계되었습니다.
핵심 아이디어는 입력된 시계열 데이터를 텍스트 프로토타입(Text Prototype) 표현으로 변환하여, 이를 언어 모델이 보다 자연스럽게 처리할 수 있도록 만드는 것입니다.
또한, LLM의 시계열 개념에 대한 이해 및 추론 능력을 향상시키기 위해 Prompt-as-Prefix(PaP)라는 새로운 접근 방식을 도입합니다. 이 기법은 입력된 시계열 데이터에 추가적인 컨텍스트를 제공하고, 자연어 형식의 작업 지침(Task Instruction)을 포함하여, LLM이 적절한 변환을 수행할 수 있도록 유도합니다.
이러한 과정을 거친 후, LLM의 출력을 투영(Projection)하여 최종적인 시계열 예측을 생성합니다.
우리의 포괄적인 실험 결과에 따르면, TIME-LLM은 few-shot 및 zero-shot 학습 방식에서 매우 효과적인 시계열 학습자로 작동하며, 기존의 특화된 예측 모델을 능가하는 성능을 보여줍니다.
TIME-LLM은 LLM의 추론 능력을 활용하면서도 모델 자체를 변경하지 않는 방식으로, 언어 및 시계열 데이터를 모두 효과적으로 다룰 수 있는 멀티모달 기초 모델(multimodal foundation model)로 확장될 가능성을 제시합니다.
주요 기여(Contributions)
본 연구의 주요 기여점은 다음과 같습니다.
-
LLM을 활용한 시계열 예측 모델 재구성(Reprogramming) 개념을 새롭게 도입하였습니다. 이를 통해, 시계열 예측을 "또 하나의 언어적(Language)" 작업으로 변환하여 기존 LLM을 수정 없이 활용할 수 있음을 보여주었습니다.
-
새로운 프레임워크인 TIME-LLM을 제안하였습니다. 이 프레임워크는
- 시계열 데이터를 LLM이 이해하기 쉬운 텍스트 프로토타입(Text Prototype) 표현으로 변환하고,
- 도메인 전문가의 지식과 작업 지침을 자연어 형식의 프롬프트(Prompt)로 제공하여 LLM의 추론 능력을 강화하는 방식을 포함합니다.
이를 통해 언어 모델과 시계열 데이터를 효과적으로 통합하는 방법론을 제시하였습니다.
-
TIME-LLM은 기존의 최첨단(State-of-the-Art) 예측 모델보다 높은 성능을 발휘하며, 특히 few-shot 및 zero-shot 예측 환경에서도 우수한 결과를 보였습니다. 또한, 효율적인 모델 재구성 방식을 유지하면서 이러한 성능을 달성하였습니다.
본 연구는 LLM이 시계열뿐만 아니라, 더 넓은 범위의 시퀀스 데이터(Sequential Data)까지 학습할 수 있는 가능성을 열어가는 중요한 한 걸음이 될 것입니다.
2. Related Work
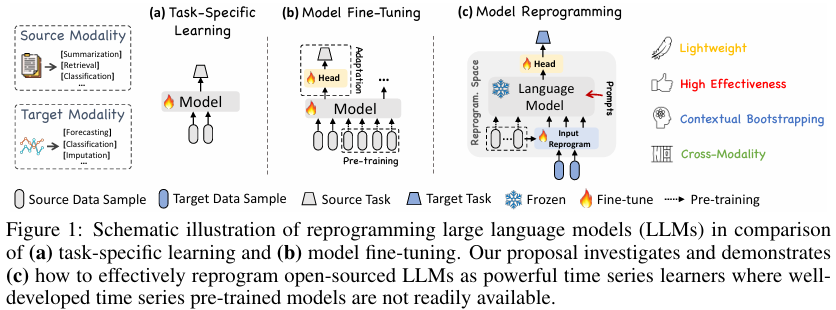
작업별 학습(Task-specific Learning)
대부분의 시계열 예측 모델은 특정 작업 및 도메인(예: 교통 예측)에 맞게 설계되며, 소규모 데이터에서 엔드 투 엔드 방식으로 학습됩니다. 그림 1(a)에 이에 대한 예시가 나와 있습니다. 예를 들어, ARIMA 모델은 단변량 시계열 예측을 위해 설계되었으며(Box et al., 2015), LSTM 네트워크는 시퀀스 모델링에 최적화되어 있습니다(Hochreiter & Schmidhuber, 1997). 또한, 시계열 컨볼루션 네트워크(Temporal Convolutional Networks, Bai et al., 2018) 및 트랜스포머(Wen et al., 2023)는 더 긴 시간 의존성을 처리하기 위해 개발되었습니다. 이러한 모델들은 특정 작업에서는 우수한 성능을 발휘하지만, 다양한 시계열 데이터에 대해 범용성과 일반화 능력이 부족합니다.
모달리티 내 적응(In-modality Adaptation)
컴퓨터 비전(CV) 및 자연어 처리(NLP) 분야의 관련 연구에서는 사전 훈련된 모델을 활용하여, 처음부터 비용이 많이 드는 훈련 없이 다양한 다운스트림 작업에 미세 조정(fine-tuning)할 수 있다는 점이 입증되었습니다(Devlin et al., 2018; Brown et al., 2020; Touvron et al., 2023). 이러한 성공 사례에 영감을 받아 최근 연구에서는 시계열 사전 훈련 모델(Time Series Pre-trained Models, TSPTMs) 개발에 초점을 맞추고 있습니다.
이들 모델의 첫 번째 단계는 지도 학습(Fawaz et al., 2018) 또는 자기 지도 학습(Zhang et al., 2022b; Deldari et al., 2022; Zhang et al., 2023)과 같은 다양한 전략을 사용하여 시계열 사전 학습을 수행하는 것입니다. 이를 통해 모델은 다양한 입력 시계열을 효과적으로 표현할 수 있도록 학습됩니다. 이후, 사전 학습된 모델은 유사한 도메인에서 특정 작업을 수행할 수 있도록 미세 조정될 수 있습니다(Tang et al., 2022). 이에 대한 예시는 그림 1(b)에 나와 있습니다.
NLP 및 CV 분야에서 사전 훈련과 미세 조정의 성공을 기반으로 한 TSPTM 개발은 데이터 희소성 문제로 인해 아직 소규모에서 제한적으로 활용되고 있습니다.
교차 모달리티 적응(Cross-modality Adaptation)
모달리티 내 적응 방식을 기반으로 최근 연구에서는 NLP 및 CV 분야의 강력한 사전 훈련된 기초 모델에서 시계열 모델링으로 지식을 전이하는 방법을 탐색하고 있습니다. 이 과정에서 다중 모달 미세 조정(multimodal fine-tuning, Yin et al., 2023) 및 모델 재구성(model reprogramming, Chen, 2022)과 같은 기술이 활용됩니다.
우리의 접근 방식은 이러한 연구들과 유사한 범주에 속하지만, 시계열 데이터에 대한 관련 연구는 아직 제한적입니다. 예를 들어, Voice2Series(Yang et al., 2021)는 음성 인식에 사용되는 음향 모델(Acoustic Model, AM)을 시계열 분류에 맞게 적응시키는 연구로, 시계열 데이터를 AM이 처리할 수 있는 형식으로 변환하는 방식을 사용합니다.
최근에는 Chang et al. (2023)이 LLM4TS를 제안하여 LLM을 활용한 시계열 예측을 수행하는 연구를 진행했습니다. 이 모델은 두 단계의 미세 조정 프로세스를 설계하였으며, 먼저 시계열 데이터를 활용한 지도 사전 훈련을 수행한 후, 작업별 미세 조정을 진행합니다. Zhou et al. (2023a)은 사전 훈련된 언어 모델을 활용하되, 자기 주의(self-attention) 및 피드포워드(feedforward) 레이어를 변경하지 않고 그대로 유지하는 방식을 채택했습니다. 이 모델은 다양한 시계열 분석 작업에 대해 미세 조정 및 평가가 수행되었으며, 자연어 사전 학습에서 얻은 지식을 활용하여 최첨단(state-of-the-art) 성능을 달성하거나 이에 근접한 결과를 보여주었습니다.
그러나, 우리의 접근 방식은 이러한 기존 방법들과 차별점을 갖습니다. 우리는 입력 시계열 데이터를 직접 편집하거나 LLM의 기본 구조를 미세 조정하지 않습니다. 대신, 그림 1(c)에 나타난 것처럼, 시계열 데이터를 원본 데이터 모달리티에서 다시 프로그래밍(reprogramming)하는 접근 방식을 사용하며, 이를 보완하기 위해 프롬프트(prompting)를 활용하여 LLM의 시계열 학습 능력을 극대화하는 방법을 제안합니다.
3. Methodology
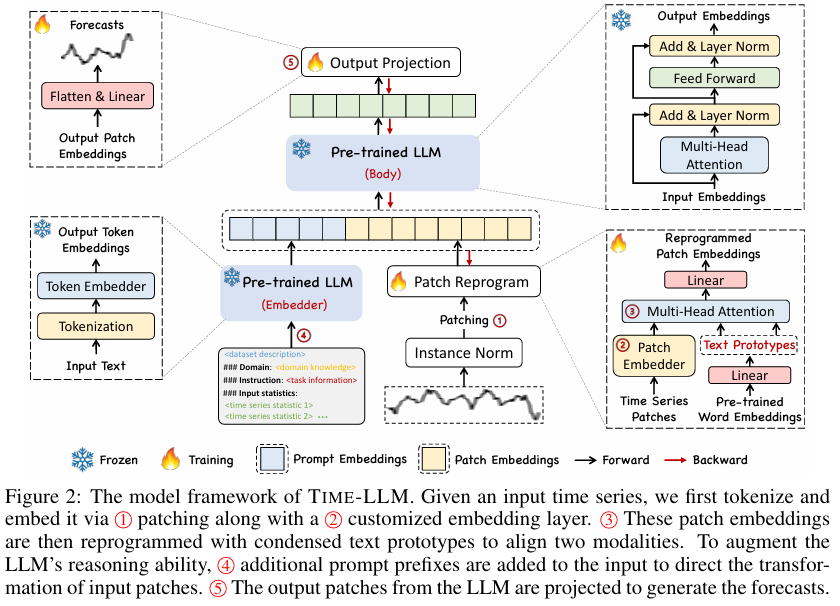
우리의 모델 아키텍처는 그림 2에 나타나 있습니다. 우리는 Llama(Touvron et al., 2023) 및 GPT-2(Radford et al., 2019)와 같은 임베딩이 노출된(embedding-visible) 언어 모델을 활용하여, 기본 모델을 미세 조정하지 않고 일반적인 시계열 예측을 수행하도록 재구성하는 방법을 연구합니다.
특히, 다음과 같은 문제를 고려합니다.
문제 정의
주어진 과거 관측값 시퀀스 가 있을 때, 여기서 은 서로 다른 1차원 변수의 개수이고, 는 시간 단계(time steps) 입니다.
우리는 대형 언어 모델 를 재구성하여, 입력된 시계열 데이터를 이해하고 향후 개의 시간 단계에 대한 예측값 을 생성하고자 합니다.
이때, 전체 목표는 다음과 같이 평균 제곱 오차(mean square error, MSE) 를 최소화하는 것입니다.
우리의 방법은 다음 세 가지 주요 요소로 구성됩니다.
- 입력 변환(Input Transformation)
- 사전 훈련된(frozen) LLM
- 출력 투영(Output Projection)
초기에 다변량 시계열(multivariate time series)은 개의 단변량 시계열로 분할되며, 각각 독립적으로 처리됩니다(Nie et al., 2023).
각 번째 시계열을 로 나타낼 수 있으며, 이는 다음과 같은 과정을 거칩니다.
- 정규화(Normalization)
- 패칭(Patching)
- 임베딩(Embedding)
이후, 우리는 학습된 텍스트 프로토타입(text prototypes) 을 사용하여 시계열 데이터를 재구성하여, 원본 데이터 모달리티와 목표 데이터 모달리티를 정렬합니다.
이후, 재구성된 패치들과 함께 LLM의 시계열 추론 능력을 증강하기 위해 프롬프트(Prompting) 를 적용합니다.
마지막으로, LLM에서 출력된 표현들을 최종 예측값 으로 변환하기 위해 투영합니다.
우리는 입력 변환 및 출력 투영 단계의 가벼운 계수들만 업데이트하며, LLM의 기본 구조는 변경하지 않습니다.
이는 기존의 비전-언어(Vision-Language) 모델 및 다중 모달 언어 모델(multimodal language models) 이 보통 교차 모달리티 데이터 쌍을 활용하여 미세 조정(fine-tuning)하는 방식과 대비됩니다.
반면, TIME-LLM은 오직 소량의 시계열 데이터 및 몇 개의 학습 에포크만으로 즉시 활용 가능하도록 설계되었습니다.
또한, 메모리 사용량(memory footprint)을 줄이기 위해 양자화(quantization)와 같은 다양한 기존 기법들을 원활하게 통합할 수 있습니다.
3.1 Model Structure
입력 임베딩 (Input Embedding)
각 입력 채널 는 먼저 Reversible Instance Normalization (RevIN) (Kim et al., 2021)을 사용하여 평균이 0이고 표준 편차가 1이 되도록 개별적으로 정규화됩니다. 이는 시계열 데이터의 분포 이동(distribution shift)을 완화하는 데 도움을 줍니다.
그런 다음, 를 길이 를 갖는 연속적인 겹치는(overlapped) 또는 겹치지 않는(non-overlapped) 패치로 분할합니다(Nie et al., 2023). 이에 따라 전체 입력 패치의 개수 는 다음과 같이 계산됩니다.
여기서, 는 가로 슬라이딩 간격(horizontal sliding stride) 을 나타냅니다.
이러한 방식의 주요 동기는 두 가지입니다.
1. 지역적 의미 정보를 더 잘 보존하기 위해, 로컬 정보를 하나의 패치로 집계(aggregating)합니다.
2. 입력 토큰의 압축된 시퀀스를 형성하는 토큰화(tokenization) 역할을 수행하여 계산 부담을 줄입니다.
주어진 패치 에 대해, 이를 패치 임베더(patch embedder)로 간단한 선형 계층(linear layer) 을 사용하여 임베딩된 표현 로 변환합니다.
여기서, 은 패치 임베딩의 차원(dimensionality)입니다.
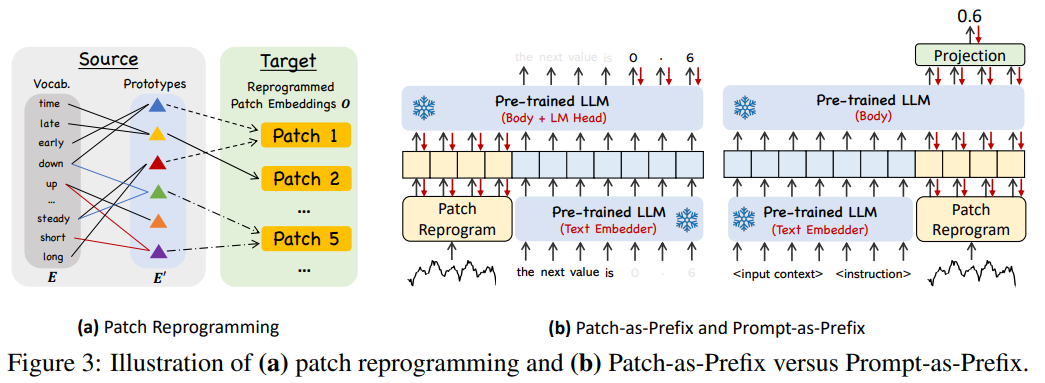
패치 재구성 (Patch Reprogramming)
여기서는 패치 임베딩(patch embeddings) 을 원본 데이터 표현 공간(source data representation space)으로 재구성하여, 시계열 데이터와 자연어 간의 모달리티 정렬을 수행합니다. 이를 통해, 백본 모델(backbone model)의 시계열 데이터 이해 및 추론 능력을 활성화할 수 있습니다.
일반적으로, "노이즈(noise)"를 학습하는 방식이 사용됩니다. 이 방법에서는 대상 입력 샘플(target input samples)에 노이즈를 적용하여, 사전 훈련된 모델이 파라미터 업데이트 없이도 원하는 출력을 생성할 수 있도록 합니다.
이러한 접근 방식은 동일하거나 유사한 데이터 모달리티 간의 연결을 구축하는 데 유용합니다. 예를 들어:
- 비전 모델(vision model) 을 다른 도메인의 이미지 처리에 재사용하는 방법 (Misra et al., 2023)
- 음향 모델(acoustic model) 을 시계열 데이터 분석에 활용하는 방법 (Yang et al., 2021)
이 두 경우 모두, 원본 데이터와 대상 데이터 사이에 명확하고 학습 가능한 변환 관계가 존재하며, 이를 통해 입력 샘플을 직접 편집할 수 있습니다.
그러나 시계열 데이터는 직접 편집할 수 없으며, 자연어로 완전하게 설명하는 것도 불가능하다는 문제가 있습니다.
따라서 리소스 집약적인 미세 조정(fine-tuning) 없이 LLM이 시계열 데이터를 이해하도록 만드는 것은 상당한 도전 과제입니다.
이러한 문제를 극복하기 위해, 우리는 사전 훈련된 단어 임베딩(word embeddings) 를 활용하여, 패치 임베딩 를 다시 프로그래밍(reprogramming)합니다.
- 여기서, 이며,
- 는 어휘 크기(vocabulary size)
- 는 백본 모델의 숨겨진 차원(hidden dimension)
그러나, 어떤 원본 토큰(source tokens)이 직접적으로 관련이 있는지 사전에 알 수 없습니다.
따라서 단순히 를 그대로 사용하는 것은 지나치게 크고 밀집된(dense) 재구성 공간을 초래할 가능성이 있습니다.
이를 해결하기 위해, 우리는 단어 임베딩 에 대해 선형 프로빙(linear probing)을 수행하여, 소수의 "텍스트 프로토타입(text prototypes)"을 유지하는 전략을 사용합니다.
- 이를 로 나타내며,
- (즉, 는 원본 어휘 크기 보다 훨씬 작은 크기를 가짐)
이 방법은 언어적 단서를 학습하여 시계열 데이터의 패치 정보를 효과적으로 표현할 수 있도록 합니다.
예를 들어,
- "short up"(빨간 선), "steady down"(파란 선) 등의 표현을 학습하여,
- 패치 5 를 설명하는 "short up then down steadily" 와 같은 표현을 구성할 수 있습니다.
이러한 방식은 언어 모델이 사전 훈련된 공간을 벗어나지 않으면서, 효과적으로 시계열 데이터를 처리하도록 하는 역할을 합니다.
또한, 이 접근 방식은 관련 소스 정보만을 선택적으로 활용하는 적응적(selection) 메커니즘을 제공합니다.
이를 실현하기 위해, 우리는 다중 헤드 교차 어텐션(Multi-head Cross-Attention Layer) 을 활용합니다.
특히, 각 어텐션 헤드 에 대해, 다음과 같이 정의합니다.
여기서,
- 는 백본 모델의 숨겨진 차원(hidden dimension)
- 는 각 헤드의 차원
각 어텐션 헤드에서, 시계열 패치 재구성(reprogramming)은 다음과 같이 수행됩니다.
각 헤드에서 얻어진 를 모두 모아 을 생성합니다.
그 후, 이를 백본 모델의 숨겨진 차원(hidden dimensions)과 정렬시키기 위해 선형 투영(linear projection) 을 수행하여 최종 재구성 출력 를 얻습니다.
Prompt-as-Prefix (PaP)
프롬프팅은 LLM의 특정 작업을 활성화하는 데 직접적이면서도 효과적인 접근 방식으로 작용합니다. 그러나 시계열을 자연어로 직접 번역하는 것은 상당한 어려움을 제시하며, 이는 지시를 따르는 데이터셋 생성과 성능 저하 없는 즉각적인(on-the-fly) 프롬프팅의 효과적인 활용을 모두 방해합니다. 최근 연구에서는 이미지와 같은 다른 데이터 모달리티가 프롬프트의 접두사(prefix)로 원활하게 통합되어 이러한 입력을 기반으로 한 효과적인 추론을 용이하게 할 수 있음을 시사합니다.
이러한 발견에 동기를 부여받고, 우리의 접근 방식을 실제 시계열에 직접 적용 가능하도록 만들기 위해, 우리는 대안적인 질문을 제시합니다: 프롬프트가 접두사로서 작용하여 입력 컨텍스트를 풍부하게 하고 재프로그래밍된 시계열 패치의 변환을 안내할 수 있을까요? 우리는 이 개념을 Prompt-as-Prefix (PaP)라고 명명하며, 이는 패치 재프로그래밍을 보완하면서 다운스트림 작업에 대한 LLM의 적응성을 크게 향상시킴을 관찰합니다 (4.5절 참조).
두 가지 프롬프팅 접근 방식에 대한 설명은 그림 3(b)에 있습니다.
-
Patch-as-Prefix: 언어 모델은 자연어로 표현된 시계열의 후속 값을 예측하도록 프롬프트됩니다. 이 접근 방식은 다음과 같은 제약에 직면합니다:
LLM은 일반적으로 외부 도구 없이 고정밀 숫자를 처리하는 데 민감도가 낮아 장기 예측 작업에 어려움을 줍니다.
LLM이 다양한 코퍼스로 사전 훈련되고 다른 토큰화 방식을 사용할 수 있으므로, 고정밀 숫자를 생성하기 위해 복잡하고 사용자 정의된 후처리가 필요합니다. 예를 들어, 소수 0.61을 표현하기 위해 ['0', '.', '6', '1']와 ['0', '.', '61'] 와 같이 다양한 자연어 형식으로 예측이 표현될 수 있습니다.

-
Prompt-as-Prefix (PaP): PaP는 이러한 제약을 교묘하게 회피합니다. 실제로, 우리는 효과적인 프롬프트를 구성하기 위한 세 가지 핵심 요소를 식별합니다:
- 데이터셋 컨텍스트 (Dataset context): LLM에 입력 시계열에 대한 필수적인 배경 정보를 제공합니다.
- 작업 지침 (Task instruction): 특정 작업을 위해 패치 임베딩의 변환에서 LLM을 위한 결정적인 가이드 역할을 합니다.
- 입력 통계 (Input statistics): 추세(trends) 및 지연(lags)과 같은 추가적인 중요한 통계를 입력 시계열로 풍부하게 하여 패턴 인식 및 추론을 용이하게 합니다.
그림 4에 프롬프트 예시가 있습니다.
출력 투영 (Output Projection)
프롬프트 및 패치 임베딩 를 패킹하고 고정된 LLM을 통해 피드포워딩한 후 (그림 2 참조), 우리는 접두사 부분(prefixal part)을 버리고 출력 표현을 얻습니다. 이어서, 우리는 이들을 평탄화(flatten)하고 선형 투영(linear project)하여 최종 예측 을 도출합니다.
4. Main Results
TIME-LLM은 특히 few-shot 및 zero-shot 시나리오에서 여러 벤치마크 및 설정에서 최첨단 예측 방법을 큰 차이로 일관되게 능가합니다. 우리는 시계열 분석을 위해 언어 모델을 미세 조정하는 최근 연구(Zhou et al., 2023a)를 포함하여 광범위한 최신 모델과 비교했습니다. 공정한 비교를 보장하기 위해, 우리는 통합된 평가 파이프라인으로 모든 기준선에 걸쳐 실험 구성을 준수합니다. 우리는 달리 명시되지 않는 한 Llama-7B를 기본 백본으로 사용합니다.
4.1 Long-term Forecasting
설정. 우리는 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, 그리고 ILI와 같이 장기 예측 모델 벤치마킹을 위해 광범위하게 채택된 데이터셋에 대해 평가합니다. 입력 시계열 길이 는 512로 설정되며, 우리는 네 가지 다른 예측 범위 를 사용합니다. 평가 지표에는 평균 제곱 오차 (MSE) 및 평균 절대 오차 (MAE)가 포함됩니다.
결과. 우리의 요약 결과는 표 1에 나와 있으며, TIME-LLM은 대부분의 경우에 모든 기준선을 능가하며 대다수에 대해 크게 능가합니다. 백본 언어 모델에 대한 미세 조정을 포함하는 GPT4TS와의 비교는 특히 주목할 만합니다. 우리는 GPT4TS 및 TimesNet에 비해 평균 성능 이득이 각각 12%와 20%임을 주목합니다. 최신 작업별 Transformer 모델인 PatchTST와 비교했을 때, 가장 작은 Llama를 재프로그래밍함으로써 TIME-LLM은 평균 1.4%의 MSE 감소를 실현합니다. DLinear과 같은 다른 모델과 비교했을 때, 우리의 개선도 12%를 초과하며 두드러집니다.
| Methods | TIME-LLM (Ours) | GPT4TS (2023a) | DLinear (2023) | PatchTST (2023) | TimesNet (2023) | FEDformer (2022) | Autoformer (2021) | Stationary (2022) | ETSformer (2022) | LightTS (2023) | Informer (2021) | Reformer (2020) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE |
| ETTh1 | 0.408 0.423 | 0.465 0.455 | 0.422 0.437 | 0.413 0.430 | 0.458 0.450 | 0.440 0.460 | 0.496 0.487 | 0.570 0.537 | 0.542 0.510 | 0.491 0.479 | 1.040 0.795 | 1.029 0.805 |
| ETTh2 | 0.334 0.383 | 0.381 0.412 | 0.431 0.446 | 0.330 0.379 | 0.414 0.427 | 0.437 0.449 | 0.450 0.459 | 0.526 0.516 | 0.439 0.452 | 0.602 0.543 | 4.431 1.729 | 6.736 2.191 |
| ETTm1 | 0.329 0.372 | 0.388 0.403 | 0.357 0.378 | 0.351 0.380 | 0.400 0.406 | 0.448 0.452 | 0.588 0.517 | 0.481 0.456 | 0.429 0.425 | 0.435 0.437 | 0.961 0.734 | 0.799 0.671 |
| ETTm2 | 0.251 0.313 | 0.284 0.339 | 0.267 0.333 | 0.255 0.315 | 0.291 0.333 | 0.305 0.349 | 0.327 0.371 | 0.306 0.347 | 0.293 0.342 | 0.409 0.436 | 1.410 0.810 | 1.479 0.915 |
| Weather | 0.225 0.257 | 0.237 0.270 | 0.248 0.300 | 0.225 0.264 | 0.259 0.287 | 0.309 0.360 | 0.338 0.382 | 0.288 0.314 | 0.271 0.334 | 0.261 0.312 | 0.634 0.548 | 0.803 0.656 |
| ECL | 0.158 0.252 | 0.167 0.263 | 0.166 0.263 | 0.161 0.252 | 0.192 0.295 | 0.214 0.327 | 0.227 0.338 | 0.193 0.296 | 0.208 0.323 | 0.229 0.329 | 0.311 0.397 | 0.338 0.422 |
| Traffic | 0.388 0.264 | 0.414 0.294 | 0.433 0.295 | 0.390 0.263 | 0.620 0.336 | 0.610 0.376 | 0.628 0.379 | 0.624 0.340 | 0.621 0.396 | 0.622 0.392 | 0.764 0.416 | 0.741 0.422 |
| ILI | 1.435 0.801 | 1.925 0.903 | 2.169 1.041 | 1.443 0.797 | 2.139 0.931 | 2.847 1.144 | 3.006 1.161 | 2.077 0.914 | 2.497 1.004 | 7.382 2.003 | 5.137 1.544 | 4.724 1.445 |
| Count | 7 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
표 1: 장기 예측 결과. 모든 결과는 네 가지 다른 예측 범위(ILI: , 기타: )에서 평균화되었습니다.
4.2 Short-term Forecasting
설정. 우리는 M4 벤치마크(Makridakis et al., 2018)를 테스트베드로 선택합니다. 예측 범위는 이며, 입력 길이는 예측 범위의 두 배입니다. 평가 지표는 대칭 평균 절대 비율 오차 (SMAPE), 평균 절대 스케일 오차 (MASE), 그리고 전체 가중 평균 (OWA)입니다.
결과. 모든 방법에 대한 우리의 요약 결과는 표 2에 있습니다. TIME-LLM은 일관되게 모든 기준선을 능가하며, GPT4TS를 8.7% 능가합니다. TIME-LLM은 MASE 및 OWA 측면에서 최신 SOTA 모델인 N-HiTS(Challu et al., 2023b)와 비교해도 경쟁력을 유지합니다.
| Methods | TIME-LLM (Ours) | GPT4TS (2023) | TimesNet (2023) | PatchTST (2023) | N-HITS (2023b) | N-BEATS (2020) | ETSformer (2022) | LightTS (2022a) | DLinear (2023) | FEDformer (2022) | Stationary (2022) | Autoformer (2021) | Informer (2021) | Reformer (2020) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average SMAPE | 11.983 | 12.69 | 12.88 | 12.059 | 12.035 | 12.25 | 14.718 | 13.525 | 13.639 | 13.16 | 12.780 | 12.909 | 14.086 | 18.200 |
| Average MASE | 1.595 | 1.808 | 1.836 | 1.623 | 1.625 | 1.698 | 2.408 | 2.111 | 2.095 | 1.775 | 1.756 | 1.771 | 2.718 | 4.223 |
| Average OWA | 0.859 | 0.94 | 0.955 | 0.869 | 0.869 | 0.896 | 1.172 | 1.051 | 1.051 | 0.949 | 0.930 | 0.939 | 1.230 | 1.775 |
표 2: M4에 대한 단기 시계열 예측 결과. 세 행은 다른 샘플링 간격에서 모든 데이터셋의 가중 평균입니다.
4.3 Few-shot Forecasting
설정. 우리는 LLM의 few-shot 학습 능력을 평가하기 위해 제한된 훈련 데이터(즉, 첫 10% 훈련 시간 단계) 시나리오에서 평가를 수행합니다.
결과. 우리의 요약된 10% 및 5% Few-shot 학습 결과는 각각 표 3과 표 4에 있습니다. TIME-LLM은 재프로그래밍된 LLM에서 성공적인 지식 활성화 덕분에 모든 기준 방법보다 현저하게 우수합니다.
- 10% Few-shot 학습: TIME-LLM은 LLM에 대한 미세 조정 없이 GPT4TS에 비해 5% MSE 감소를 실현합니다. PatchTST, DLinear, TimesNet과 비교하여, 평균 개선은 MSE 측면에서 8%, 12%, 33%를 초과합니다.
- 5% Few-shot 학습: GPT4TS에 대한 우리의 평균 발전은 5%를 초과합니다. PatchTST, DLinear, TimesNet과 비교했을 때, TIME-LLM은 20% 이상의 놀라운 평균 개선을 나타냅니다.
| Methods | TIME-LLM (Ours) | GPT4TS (2023a) | DLinear (2023) | PatchTST (2023) | TimesNet (2023) | FEDformer (2022) | Autoformer (2021) | Stationary (2022) | ETSformer (2022) | LightTS (2022) | Informer (2021) | Reformer (2020) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE |
| ETTh1 | 0.556 0.522 | 0.590 0.525 | 0.691 0.600 | 0.633 0.542 | 0.869 0.628 | 0.639 0.561 | 0.702 0.596 | 0.915 0.639 | 1.180 0.834 | 1.375 0.877 | 1.199 0.809 | 1.249 0.833 |
| ETTh2 | 0.370 0.394 | 0.397 0.421 | 0.605 0.538 | 0.415 0.431 | 0.479 0.465 | 0.466 0.475 | 0.488 0.499 | 0.462 0.455 | 0.894 0.713 | 2.655 1.160 | 3.872 1.513 | 3.485 1.486 |
| ETTm1 | 0.404 0.427 | 0.464 0.441 | 0.411 0.429 | 0.501 0.466 | 0.677 0.537 | 0.722 0.605 | 0.802 0.628 | 0.797 0.578 | 0.980 0.714 | 0.971 0.705 | 1.192 0.821 | 1.426 0.856 |
| ETTm2 | 0.277 0.323 | 0.293 0.335 | 0.316 0.368 | 0.296 0.343 | 0.320 0.353 | 0.463 0.488 | 1.342 0.930 | 0.332 0.366 | 0.447 0.487 | 0.987 0.756 | 3.370 1.440 | 3.978 1.587 |
| Weather | 0.234 0.273 | 0.238 0.275 | 0.241 0.283 | 0.242 0.279 | 0.279 0.301 | 0.284 0.324 | 0.300 0.342 | 0.318 0.323 | 0.318 0.360 | 0.289 0.322 | 0.597 0.495 | 0.546 0.469 |
| ECL | 0.175 0.270 | 0.176 0.269 | 0.180 0.280 | 0.180 0.273 | 0.323 0.392 | 0.346 0.427 | 0.431 0.478 | 0.444 0.480 | 0.660 0.617 | 0.441 0.489 | 1.195 0.891 | 0.965 0.768 |
| Traffic | 0.429 0.306 | 0.440 0.310 | 0.447 0.313 | 0.430 0.305 | 0.951 0.535 | 0.663 0.425 | 0.749 0.446 | 1.453 0.815 | 1.914 0.936 | 1.248 0.684 | 1.534 0.811 | 1.551 0.821 |
| Count | 7 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
표 3: 10% 훈련 데이터에 대한 Few-shot 학습 결과.
| Methods | TIME-LLM (Ours) | GPT4TS (2023a) | DLinear (2023) | PatchTST (2023) | TimesNet (2023) | FEDformer (2022) | Autoformer (2021) | Stationary (2022) | ETSformer (2022) | LightTS (2022) | Informer (2021) | Reformer (2020) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE |
| ETTh1 | 0.627 0.543 | 0.681 0.560 | 0.750 0.611 | 0.694 0.569 | 0.925 0.647 | 0.658 0.562 | 0.722 0.598 | 0.943 0.646 | 1.189 0.839 | 1.451 0.903 | 1.225 0.817 | 1.241 0.835 |
| ETTh2 | 0.382 0.418 | 0.400 0.433 | 0.694 0.577 | 0.827 0.615 | 0.439 0.448 | 0.463 0.454 | 0.441 0.457 | 0.470 0.489 | 0.809 0.681 | 3.206 1.268 | 3.922 1.653 | 3.527 1.472 |
| ETTm1 | 0.425 0.434 | 0.472 0.450 | 0.400 0.417 | 0.526 0.476 | 0.717 0.561 | 0.730 0.592 | 0.796 0.620 | 0.857 0.598 | 1.125 0.782 | 1.123 0.765 | 1.163 0.791 | 1.264 0.826 |
| ETTm2 | 0.274 0.323 | 0.308 0.346 | 0.399 0.426 | 0.314 0.352 | 0.344 0.372 | 0.381 0.404 | 0.388 0.433 | 0.341 0.372 | 0.534 0.547 | 1.415 0.871 | 3.658 1.489 | 3.581 1.487 |
| Weather | 0.260 0.309 | 0.263 0.301 | 0.263 0.308 | 0.269 0.303 | 0.298 0.318 | 0.309 0.353 | 0.310 0.353 | 0.327 0.328 | 0.333 0.371 | 0.305 0.345 | 0.584 0.527 | 0.447 0.453 |
| ECL | 0.179 0.268 | 0.178 0.273 | 0.176 0.275 | 0.181 0.277 | 0.402 0.453 | 0.266 0.353 | 0.346 0.404 | 0.627 0.603 | 0.800 0.685 | 0.878 0.725 | 1.281 0.929 | 1.289 0.904 |
| Traffic | 0.423 0.298 | 0.434 0.305 | 0.450 0.317 | 0.418 0.296 | 0.867 0.493 | 0.676 0.423 | 0.833 0.502 | 1.526 0.839 | 1.859 0.927 | 1.557 0.795 | 1.591 0.832 | 1.618 0.851 |
| Count | 5 | 2 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
표 4: 5% 훈련 데이터에 대한 Few-shot 학습 결과.
4.4 Zero-shot Forecasting
설정. 우리는 교차 도메인 적응 프레임워크 내에서 재프로그래밍된 LLM의 Zero-shot 학습 능력을 평가합니다. 모델은 한 데이터셋에서 최적화되고, 어떤 데이터 샘플도 접하지 않은 다른 데이터셋에서 성능을 평가합니다.
결과. 우리의 요약 결과는 표 5에 있습니다. TIME-LLM은 MSE 감소 측면에서 두 번째 최고보다 평균 14.2% 이상으로 가장 경쟁적인 기준선을 일관되게 능가합니다.
- 데이터 희소성 시나리오에서의 LLM 이점: GPT4TS에 대한 우리의 전체 오차 감소는 10% Few-shot, 5% Few-shot, Zero-shot 예측에서 각각 7.7%, 8.4%, 및 22%로 점진적으로 증가합니다. 이는 LLM 재프로그래밍이 데이터 희소성 시나리오에서 특히 효과적임을 시사합니다.
- LLMTime과의 비교: LLMTime(Gruver et al., 2023)과 비교했을 때, TIME-LLM은 75%를 초과하는 상당한 개선을 보여줍니다. 우리는 우리의 재프로그래밍 프레임워크가 LLM의 지식 전이 및 추론 능력을 자원 효율적인 방식으로 더 잘 활성화하기 때문이라고 생각합니다.
| Methods | TIME-LLM (Ours) | GPT4TS (2023a) | LLMTime (2023) | DLinear (2023) | PatchTST (2023) | TimesNet (2023) |
|---|---|---|---|---|---|---|
| Metric | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE |
| ETTh1 ETTh2 | 0.353 0.387 | 0.406 0.422 | 0.992 0.708 | 0.493 0.488 | 0.380 0.405 | 0.421 0.431 |
| ETTh1 ETTm2 | 0.273 0.340 | 0.325 0.363 | 1.867 0.869 | 0.415 0.452 | 0.314 0.360 | 0.327 0.361 |
| ETTh2 ETTh1 | 0.479 0.474 | 0.757 0.578 | 1.961 0.981 | 0.703 0.574 | 0.565 0.513 | 0.865 0.621 |
| ETTh2 ETTm2 | 0.272 0.341 | 0.335 0.370 | 1.867 0.869 | 0.328 0.386 | 0.325 0.365 | 0.342 0.376 |
| ETTm1 ETTh2 | 0.381 0.412 | 0.433 0.439 | 0.992 0.708 | 0.464 0.475 | 0.439 0.438 | 0.457 0.454 |
| ETTm1 ETTm2 | 0.268 0.320 | 0.313 0.348 | 1.867 0.869 | 0.335 0.389 | 0.296 0.334 | 0.322 0.354 |
| ETTm2 ETTh2 | 0.354 0.400 | 0.435 0.443 | 0.992 0.708 | 0.455 0.471 | 0.409 0.425 | 0.435 0.443 |
| ETTm2 ETTm1 | 0.414 0.438 | 0.769 0.567 | 1.933 0.984 | 0.649 0.537 | 0.568 0.492 | 0.769 0.567 |
표 5: Zero-shot 학습 결과.
4.5 Model Analysis
언어 모델 변형. 우리는 LLM 재프로그래밍 후에도 스케일링 법칙이 유지됨을 확인했습니다. Llama-7B는 용량 변형(A.2)보다 14.5% 뛰어났고, GPT-2(A.3)보다 평균 14.7% MSE 감소가 관찰되었습니다.
교차 모드 정렬. 패치 재프로그래밍 또는 Prompt-as-Prefix 중 하나를 제거하면 LLM 재프로그래밍의 지식 전이가 저해됩니다.
- 패치 재프로그래밍 제거 (B.1): 평균 성능 저하 9.2%가 발생하며, Few-shot 작업에서는 17%를 초과합니다.
- Prompt-as-Prefix 제거 (B.2): 표준 및 Few-shot 예측 작업에서 각각 8% 및 19% 이상의 성능 저하를 초래합니다.
프롬프트 구성 요소 중 입력 통계 제거 (C.3)가 평균 10.2% MSE 증가로 가장 큰 손해를 입혔습니다. 또한, 명확한 작업 지침 (C.2)과 입력 컨텍스트 (C.1) 제공은 각각 7.7% 및 9.6% 이상 개선에 기여했습니다.
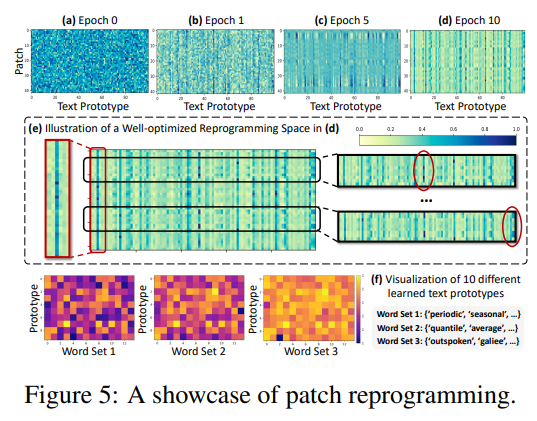
재프로그래밍 해석. ETTh1에 대한 사례 연구는 (그림 5):
1. 텍스트 프로토타입이 언어 단서를 요약하는 것을 학습하며, 소수의 프로토타입만이 로컬 시계열 패치 정보를 표현하는 데 높은 관련성을 가집니다.
2. 패치는 일반적으로 다른 기본 의미를 가지므로, 이를 표현하기 위해 다른 프로토타입이 필요합니다.
재프로그래밍 효율성. (표 7):
- 우리가 제안하는 재프로그래밍 네트워크 자체(D.3)는 660만 미만의 훈련 가능한 매개변수(Llama-7B 전체의 약 0.2%)를 가진 경량입니다.
- TIME-LLM의 전체 효율성은 활용된 백본(D.1 및 D.2)에 의해 제한됩니다. 이는 매개변수 효율적인 미세 조정(PEFT) 방법(예: QLoRA)과 비교해도 유리합니다.
| Variant | Long-term Forecasting | Few-shot Forecasting |
|---|---|---|
| ETTh1-96 | ETTh1-192 | |
| A.1 Llama (Default: 32) | 0.362 | 0.398 |
| A.2 Llama (8) | 0.389 | 0.412 |
| A.3 GPT-2 (12) | 0.385 | 0.419 |
| A.4 GPT-2 (6) | 0.394 | 0.427 |
| A.5 Llama (QLORA; 32) | 0.391 | 0.420 |
| B.1 w/o Patch Reprogramming | 0.410 | 0.412 |
| B.2 w/o Prompt-as-Prefix | 0.398 | 0.423 |
| C.1 w/o Dataset Context | 0.402 | 0.417 |
| C.2 w/o Task Instruction | 0.388 | 0.420 |
| C.3 w/o Statistical Context | 0.391 | 0.419 |
표 6: ETTh1 및 ETTm1에 대한 96 및 192 단계 예측(MSE 보고)에 대한 제거 연구.
| Length | Metric | Llama (32) | Llama (8) | w/o LLM |
|---|---|---|---|---|
| ETTh1-96 | Param. (M) | 3404.53 | 975.83 | 6.39 |
| Speed (s/iter) | 0.517 | 0.184 | 0.046 | |
| Mem. (MiB) | 32136 | 11370 | 3678 | |
| ETTh1-192 | Param. (M) | 3404.57 | 975.87 | 6.42 |
| Speed (s/iter) | 0.582 | 0.192 | 0.087 | |
| Mem. (MiB) | 33762 | 12392 | 3812 | |
| ETTh1-336 | Param. (M) | 3404.62 | 975.92 | 6.48 |
| Speed (s/iter) | 0.632 | 0.203 | 0.093 | |
| Mem. (MiB) | 37988 | 13108 | 3960 | |
| ETTh1-512 | Param. (M) | 3404.69 | 976.11 | 6.55 |
| Speed (s/iter) | 0.697 | 0.217 | 0.129 | |
| Mem. (MiB) | 39004 | 13616 | 4176 |
표 7: ETTh1에 대한 다양한 단계 예측에서 TIME-LLM의 효율성 분석.
5. Conclusion and Future Work
TIME-LLM은 시계열 데이터를 LLM에 더 자연스러운 텍스트 프로토타입으로 재프로그래밍하고, 추론을 강화하기 위해 Prompt-as-Prefix를 통해 자연어 지침을 제공함으로써 고정된 LLM을 시계열 예측에 적응시키는 데 유망함을 보여줍니다. 평가는 적응된 LLM이 전문화된 전문가 모델을 능가할 수 있음을 입증하며, 이는 효과적인 시계열 기계로서의 잠재력을 나타냅니다. 우리의 결과는 또한 시계열 예측이 TIME-LLM 프레임워크를 통해 최첨단 성능을 달성하기 위해 기성 LLM에 의해 해결될 수 있는 또 다른 "언어" 작업으로 간주될 수 있다는 새로운 통찰력을 제공합니다.
향후 연구(Future Work)는 다음과 같은 방향으로 진행되어야 합니다:
- 최적의 재프로그래밍 표현 탐색.
- 지속적인 사전 훈련을 통한 명시적 시계열 지식으로 LLM 풍부화.
- 시계열, 자연어 및 기타 양식 전반에 걸친 공동 추론을 통한 다중 모드 모델 구축.
- LLM에 더 광범위한 시계열 분석 능력 또는 기타 새로운 기능을 부여하기 위해 재프로그래밍 프레임워크를 적용.
