- NeurIPS 2025
- 저자: Adam Zweiger, Jyothish Pari, et al. (MIT)
- ArXiv:
arXiv:2506.10943v2
1. 연구 배경 및 핵심 질문
1.1 문제 제기: 정적인(Static) LLM
대형 언어 모델(LLM)은 뛰어난 성능을 보이지만, 본질적으로 '정적'입니다. 즉, 사전 훈련이 완료된 후에는 새로운 작업, 새로운 지식, 또는 새로운 예시에 대응하여 모델의 가중치(파라미터)를 동적으로 조정하는 메커니즘이 부족합니다.
1.2 핵심 가설 (Hypothesis)
연구진은 다음과 같은 핵심 질문을 던집니다: "LLM이 스스로 훈련 데이터와 학습 절차를 변형하거나 생성함으로써 자기 적응(self-adapt)할 수 있을까?"
1.3 비유: 학생의 학습 방식
- 기계 학습 기말고사를 준비하는 학생을 생각해 봅시다.
- 이 학생은 강의 내용이나 교과서 원본을 '있는 그대로' 소비하지 않습니다. 대신, 정보를 자신의 노트에 '재작성'하고, 요약하며, 핵심을 추출합니다.
- 이러한 '정보를 재구성하는 행위' 자체가 학생들이 내용을 더 깊이 이해하고 시험 문제에 더 잘 답할 수 있도록 돕습니다.
- 사람마다 노트를 작성하는 방식(정보를 동화하는 방식)이 다릅니다.
1.4 현재 LLM의 한계
- 현재 LLM은 미세조정(fine-tuning)이나 인-컨텍스트 학습(in-context learning)을 통해 새로운 데이터를 '있는 그대로' 소비합니다.
- 하지만 이 원본 데이터는 모델이 학습하기에 최적의 형식이 아닐 수 있습니다.
- 현재 방식은 모델이 훈련 데이터로부터 최상의 학습 방법을 스스로 개발하도록 지원하지 않습니다.
2. 제안 방법: SEAL (Self-Adapting LLMs)
2.1 핵심 아이디어
SEAL은 LLM이 자체적으로 미세조정 데이터와 업데이트 지시문을 생성함으로써, 스스로를 새로운 상황에 적응시킬 수 있게 하는 프레임워크입니다.
2.2 '자기 편집 (Self-Edits)'
- 새로운 입력(논문에서는 '컨텍스트'라고 부름)이 주어지면, 모델은 '자기 편집(Self-Edit, SE)'이라는 자연어 지시문을 생성합니다.
- 이 'SE'은 모델의 가중치를 업데이트하는 데 사용될 훈련 데이터 그 자체이거나, 훈련 방법을 명시하는 지침입니다.
- 'SE'의 예시:
- 정보 재구성 (합성 데이터): 원본 텍스트의 '함의'를 생성하거나, "질문-답변" 쌍으로 변환합니다.
- 최적화 하이퍼파라미터 지정: "학습률은 0.001로 설정", "훈련 에포크는 3으로 설정"과 같이 최적화 방법을 지정합니다.
- 도구 호출: 데이터 증강(예: '이미지 회전')이나 특정 그래디언트 업데이트 방식을 위한 함수를 호출합니다.
2.3 학습 프로세스 (두 개의 중첩된 루프)
SEAL은 두 개의 루프가 중첩된 구조로 작동합니다.
A. 내부 업데이트 루프 (Internal Loop)
- 생성: 현재 LLM 모델(가중치: '파라미터-초기')이 주어진 '컨텍스트(C)'를 보고 후보 '자기 편집(SE)'을 생성합니다.
- 적용: 이 생성된 'SE'을 훈련 데이터 또는 지침으로 사용하여 지도식 미세조정(SFT)을 수행합니다.
- 업데이트: 모델의 가중치가 '파라미터-초기'에서 '파라미터-업데이트됨' 상태로 변경됩니다.
B. 외부 RL 루프 (Outer Loop)
- 평가: '파라미터-업데이트됨' 상태의 모델을 사용하여, 미리 정의된 '다운스트림 평가 작업(T)'을 수행합니다. (예: SQUAD 질문에 답하기)
- 보상 계산: 이 평가 작업의 성능 향상 정도(예: 정확도)를 '보상(r)' 신호로 계산합니다.
- 정책 강화: 이 '보상'을 사용하여, "더 높은 보상을 가져오는 'SE'을 더 잘 생성하도록" 모델의 'SE' 생성 능력(정책) 자체를 강화 학습(RL)으로 훈련시킵니다.
→ RL 루프는 SE 생성을 최적화하고, 업데이트 루프는 생성된 SE를 사용하여 gradient descent를 통해 모델을 업데이트.
3. 방법론 상세 (Methods)
3.1 일반 프레임워크
- 목표: 강화 학습의 목표는 '강화 학습 목적 함수'(논문의 수식 1)를 최대화하는 것입니다.
-
수식 (1)의 의미: 이 목적 함수는, 어떤 '컨텍스트(C)'와 '평가 작업(T)'의 분포가 주어졌을 때, 모델이 생성한 '자기 편집(SE)'을 적용했을 때 얻게 되는 '보상(r)'의 '기대값'을 최대화하는 것을 목표로 합니다.
-
가장 큰 어려움 (Non-Differentiability):
- '보상' 값은 'SE'가 적용된 '업데이트된 모델'의 성능에 따라 결정됩니다.
- 즉, 보상 값은 모델의 '현재 파라미터'에 의존합니다.
- 하지만 '모델을 SFT로 업데이트하고 → 그 모델로 평가를 수행하는' 이 전체 과정은 미분이 불가능합니다.
- 따라서 표준적인 역전파(backpropagation) 방식으로는 '그래디언트'(기울기)를 계산하여 'SE' 생성 정책을 최적화할 수 없습니다.
- PPO와 같은 복잡한 온-폴리시(on-policy) RL 알고리즘은 훈련이 불안정했습니다.
-
해결책: (Rejection Sampling + SFT) 알고리즘

-
대신, 더 간단하고 안정적인 '필터링된 행동 복제(filtered behavior cloning)' 방식인 (rejection sampling + SFT)을 채택했습니다.
-
보상 단순화 (수식 2): 보상을 이진(binary)으로 단순화합니다. 'SE'를 적용했을 때 성능이 향상되면 '보상 = 1', 아니면 '보상 = 0'입니다.
-
r에 stop-gradient를 적용해 보상을 θt에 대해 상수처럼 취급함으로써, 미분(최적화) 가능. (수식 3, 4)
-
알고리즘 상세 (수식 3, 4의 의미):

- (E-단계: 샘플링) 현재 모델로 N개의 '컨텍스트'에 대해 각각 M개의 후보 'SE'를 샘플링합니다.
- (M-단계: 필터링 및 업데이트) 샘플링된 'SE' 중 '보상이 1'인 (즉, 성능을 향상시킨) 것들만 골라냅니다.
- 이 '좋은 SE'들만 모아서 SFT(지도식 미세조정)를 수행합니다.
-
작동 원리: 이 방식은 '보상 항'에는 그래디언트가 흐르지 않는다고 가정(stop-gradient)함으로써, 미분 불가능 문제를 영리하게 우회합니다. 결과적으로 '좋은 SE'를 생성하는 방향으로만 모델의 생성 정책이 업데이트됩니다.
-
3.2 도메인별 구현 (두 가지 시나리오)
SEAL 프레임워크를 두 가지 상이한 도메인에서 테스트했습니다.
A. 지식 통합 (Knowledge Incorporation)

- 목표: 새로운 사실 정보(예: SQUAD의 백과사전 구절)를 모델의 가중치에 영구적으로 통합(암기)하는 능력.
- 컨텍스트(C): SQUAD 데이터셋의 개별 구절(passage) 텍스트.
- '자기 편집'(SE): 모델에게 원본 구절을 주며 "이 내용에서 파생된 여러 함의(implications)를 나열하세요"라고 프롬프트합니다. 모델은 원본 텍스트를 재진술하거나, 추론하거나, 논리적 귀결을 텍스트로 생성해냅니다.
- 업데이트: 원본 구절 텍스트 + 모델이 생성한 '함의(SE)' 텍스트를 훈련 데이터로 사용하여 LoRA(저계급 어댑터)로 효율적 미세조정을 수행합니다.
- 평가(T): '문맥 없음(no-passage-in-context)' 설정에서 평가합니다. 즉, 원본 구절을 다시 보여주지 않고, 해당 구절에 대한 질문에 모델이 얼마나 정확하게 답변하는지(얼마나 잘 '암기'했는지) 측정합니다.
B. 퓨샷 학습 (Few-Shot Learning)

- 목표: 아주 적은 수의 예시(퓨샷 시연)만 보고 새로운 추상적 추론 작업(ARC 벤치마크)을 일반화하는 능력.
- 컨텍스트(C): ARC 작업의 퓨샷 시연 (입력-출력 예시 몇 개).
- '자기 편집'(SE): '도구(tools)' 사용법을 명시하는 텍스트입니다. 모델은 어떤 도구를 어떤 순서로, 어떤 파라미터로 호출할지 지정하는 코멘트 형식의 'SE'을 생성합니다. (논문 그림 3 참조)
- 사용 도구:
- 데이터 증강: 회전, 뒤집기, 반사, 크기 조정 등.
- 최적화 파라미터: 학습률, 훈련 에포크 수, 손실 계산 방식(모든 토큰 vs. 출력 토큰만) 지정.
- 업데이트: 'SE'의 명세대로 퓨샷 데이터를 증강하고, 지정된 하이퍼파라미터로 LoRA 미세조정(이를 '테스트 시점 훈련, TTT'라고 부름)을 수행합니다.
- 평가(T): 홀드아웃(held-out) 테스트 입력에 대한 정답을 예측합니다.
→ 지식통합 테스트: 원본 지식을 가장 효과적인 학습용 데이터(SE)로 스스로 합성 해낼 수 있는 지 테스트
→ 퓨샷 학습 테스트: 모델이 낯선 문제를 보고, 그 문제를 풀기에 가장 효과적인 적응 전략(SE)을 스스로 생성해낼 수 있는지를 테스트
4. 주요 실험 결과 (Results)
4.1 퓨샷 학습 (ARC 추상적 추론)
- 모델: Llama-3.2-1B-Instruct (ARC에 대해 사전 훈련되지 않음).
- 데이터: ARC 훈련/평가 세트 중, 기본 모델이 TTT로 풀 수 있음이 보장된 일부 하위 집합 (훈련 11개, 평가 8개 작업).
- Success Rate : 적응 성공률
- 결과 (표 1):
Method Success Rate (%) 설명 ICL 0 기본 모델은 예시만 보고는 풀지못함 TTT + Self-Edit (w/o prior RL) 20 RL 훈련 전에 모델이 생성한 설정값을 사용해 훈련 SEAL 72.5 RL 훈련 이후 모델이 생성한 설정값을 사용해 훈련 Oracle TTT (Human-tuned) 100 사람이 직접 설정한 최적의 설정값을 사용해 훈련 - 결론: RL 훈련을 통해, 모델이 효과적인 ‘SE'(즉, 올바른 도구와 하이퍼파라미터 조합)를 생성하도록 성공적으로 학습했습니다.
4.2 지식 통합 (SQUAD '문맥 없음')
- 모델: Qwen2.5-7B
- 베이스라인 상세:
- Base Model: 적응 없이 기본 모델로 질문에 답하기.
- Train on Passage: 원본 구절로만 SFT.
- Train on Passage + Synthetic (w/o RL): RL 훈련 전의 모델이 생성한 '함의'와 원본 구절로 SFT (SEAL의 0-shot 버전).
- Train on Passage + GPT-4.1 Synthetic: 더 크고 강력한 모델(GPT-4.1)에게 '함의'를 생성해달라고 요청하고, 그것으로 훈련.
- 결과 (표 2):
Method 단일 구절 (n=1; LORA) 지속적 사전훈련 (n=200; full-FT) Base model 32.7% 32.7% Train on Passage 33.5% 36.0% Train on Passage + Synthetic (w/o RL) 39.7% 50.6% Train on Passage + GPT-4.1 Synthetic 46.3% 59.4% SEAL 47.0% 58.2% - 결론 (단일 구절):
- SEAL(47.0%)이 GPT-4.1(46.3%)을 능가했습니다.
- 이는 더 작은 모델(Qwen2.5-7B)일지라도, RL을 통해 "자신에게 더 학습이 잘 되는" 맞춤형 합성 데이터를 생성하는 법을 학습했기 때문입니다.
- RL 훈련 전(39.7%) 대비 성능 향상(47.0%)이 뚜렷하여 RL 훈련의 효과를 입증했습니다.
- 결론 (지속적 사전훈련, CPT):
- 모델이 많은 구절(n=200)을 한 번에 학습하는 시나리오에서도, SEAL(58.2%)은 GPT-4.1(59.4%)과 거의 대등한 성능을 보였습니다.
- 이는 단일 구절 업데이트를 위해 훈련된 '자기 편집' 생성 정책이, 더 큰 규모의 CPT 설정에서도 잘 일반화됨을 시사합니다.
- 정성적 분석 (그림 4, 5):
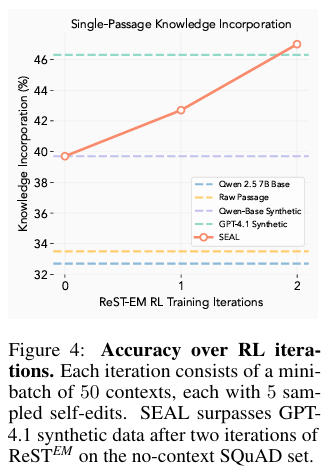

- RL 훈련이 반복될수록(그림 4), 모델은 더 길고, 더 상세하며, 학습에 용이한 원자적 사실(atomic facts) 형태로 'SE'을 생성하는 경향을 보였습니다 (그림 5).
5. 한계점 (Limitations)
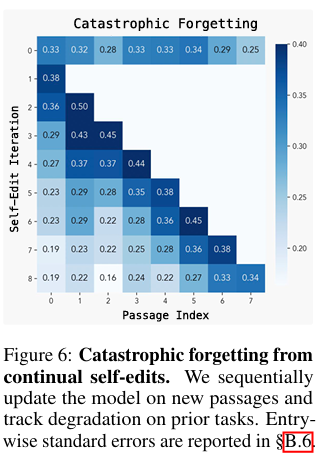
5.1 파국적 망각 (Catastrophic Forgetting)
- 실험: 모델을 새로운 구절(Task 1, 2, 3...)에 대해 순차적으로 'SE'하며 업데이트했습니다. 업데이트할 때마다 이전에 학습한 작업(예: Task 1)의 성능을 다시 측정했습니다.
- 결과 (그림 6): 새로운 'SE'가 적용될수록(편집 횟수 증가), 이전에 학습한 작업에 대한 성능이 점진적으로 감소했습니다.
- 원인: 현재의 RL 보상 함수가 '새로운 지식 통합'만 최적화하고, '이전 지식 보존'은 명시적으로 고려하지 않기 때문입니다.
5.2 계산 오버헤드 (Computational Overhead)
- TTT 보상 루프(내부 루프)는 계산 비용이 매우 큽니다.
- RL 훈련 중, 샘플링된 'SE' 후보 각각에 대해 SFT(미세조정)와 평가(순전파)를 모두 수행해야 '보상'을 계산할 수 있습니다.
- 논문에 따르면 'SE' 1개를 평가하는 데 약 30-45초가 소요되며, 이는 RL 훈련 시 막대한 계산 자원을 요구합니다.
5.3 문맥 의존적 평가 (Context-dependent Evaluation)
- 현재 RL 훈련은 ('컨텍스트 C', '평가 작업 T') 쌍, 즉 레이블이 있는 데이터를 요구합니다 (SQUAD의 QA쌍, ARC의 테스트 입출력 쌍).
- 이 때문에 레이블이 없는 대규모 텍스트 코퍼스로는 SEAL의 RL 훈련을 확장하기 어렵습니다.
- 잠재적 해결책: 모델이 'SE'뿐만 아니라 '자체 평가 질문(QA)'까지 생성하게 하여 스스로 보상 신호를 만들게 하는 방식.
6. 토론 및 결론 (Discussion and Conclusion)
- 핵심 의의: SEAL은 LLM이 정적일 필요가 없음을 보여줍니다. 모델이 스스로 'SE' 데이터를 생성하고, 이를 경량의 가중치 업데이트(LoRA 등)를 통해 적용함으로써 자율적으로 적응할 수 있는 프레임워크를 제시했습니다.
- "데이터 장벽" 문제: 2028년까지 공개된 모든 인간 생성 텍스트가 LLM 훈련에 소진될 것이라는 예측(Villalobos 등)이 있습니다.
- SEAL의 역할: 이 "데이터 장벽"이 도래하면, 모델 스스로가 고효율 훈련 신호(합성 데이터)를 생성하는 능력이 미래 LLM 발전의 핵심이 될 것입니다. SEAL은 그 가능성을 열었습니다.
