CNN 네트워크
이미지, 음성인식에 자주 사용하는 신경망 구조
지금까지 봤던 신경망은 모든 뉴런과 결합되어 있는 완전 연결 계층 형식.
특히 Affine 계층을 사용해 Affine-ReLU-Affine-ReLU-…….Affine-Softmax 이런식으로 모든 계층을 연결해 구현한다.
하지만 CNN구조는 Conv-ReLU-Pooling-Conv-ReLU-Pooling-Conv-ReLU-Pooling…..-Affine-Softmax
이런 형태 지금까지의 Affine-ReLU 형태에서 Conv-ReLU-Pooling 형태로 바뀐 모습이 CNN 신경망 구조이다. 이때 Conv는 합성곱 계층을 의미하며, Pooling 계층을 의미. 이에대한 자세한 설명은 뒤에 나온다.
왜 CNN 구조를 사용하게 되었을까? -
기존의 완전 연결 계층에서는 데이터의 형상이 무시된다는 단점이 존재했다.
예를들어, 이미지는 가로-세로-색상으로 구성된 3차원 데이터임에도 불구하고 완결연결 계층에서는 3차원 데이터를 1차원으로 평탄화하는 과정을 거쳐야한다. 이렇게 되면 이미지의 픽셀이 늘어날 수록 히든 층의 뉴런수와 매개변수도 기하급수적으로 늘어나게 된다. 또한 이 CNN구조를 사용할 경우, 이미지의 형상 정보를 그대로 가져갈 수 있기 때문에 편리하다.
1. 합성곱 계층 - Conv (합성곱 연산)
합성곱 계층에서는 합성곱 연산을 처리.
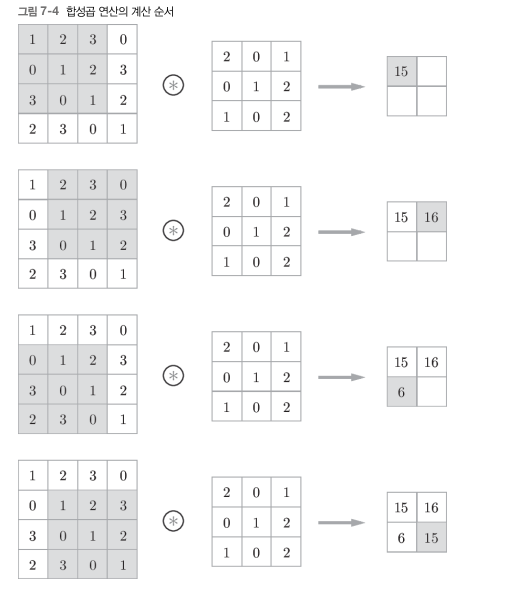
첫번째 MATRIX가 입력 데이터, 두번째 MATRIX가 필터라는 것이고. 세번째 MATRIX가 출력 결과이다. 합성곱 연산은 입력데이터에 필터를 적용해 연산하는 것을 의미.
필터의 윈도우를 일정 간격으로 이동해가며 입력데이터에 적용한다. 이때 윈도우는 그림에서 회색부분을 의미한다.
첫번째 출력 결과가 15인 이유는 1*2+0*2+3*1+0*0+1*1+2*2+3*1+0*0+1*2 = 15이기 때문.
두번째 역시 똑같은 방식으로 계산한다.
여기서 짐작되듯이, CNN에서 필터는 앞선 완전연결신경망에서의 가중치와 같은 역할을 한다는 것을 알 수 있다.
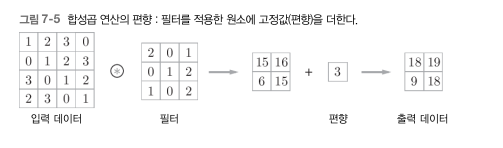
추가로 편향도 역시 더해준다.
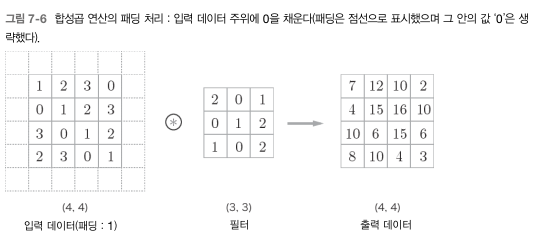
1.1 패딩
합성곱 연산을 수행하기 전에는 입력 데이터 주변을 특정 값으로 채우기도 한다. 이를 패딩이라고 하며, 이 패딩에 따라서 출력데이터의 형상이 달라질 수 있다.
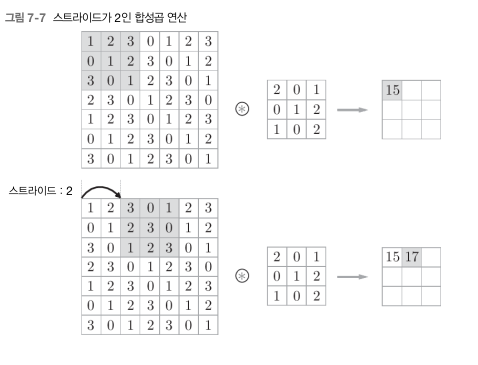
1.2 스트라이드
필터를 적용하는 위치의 간격을 의미. 지금까지는 1이었지만 만약 2로할 경우 필터를 적용하는 윈도우가 두칸씩 이동.
1.3 출력 크기 계산하기
입력 크기를 (H,W), 필터크기를 (FH,FW), 패딩을 P, 스트라이드를 S라 할 때 출력 크기 (OH,OW)는 다음과 같이 계산 할 수 있다.
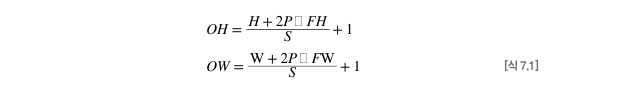
1.4 3차원 데이터의 합성곱 연산
지금까지는 2차원 형상의 합성곱. 실제 이미지 데이터는 사실 3차원 데이터이다. (세로, 가로, 채널(색상)) 과정은 다음과 같다.
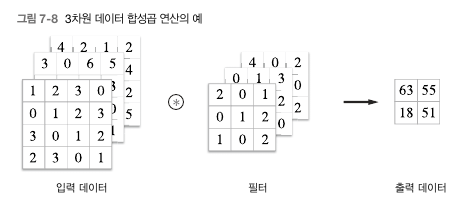
여기서 주의할점은 입력데이터의 채널수가 필터의 채널수와 같아야 한다는점.
이때 출력의 채널갯수는 1개가 된다. 출력의 채널수를 늘리기 위해서는 필터의 갯수를 늘려야함. 따라서 최종적인 합성곱 연산의 처리 흐름은 다음과 같다.
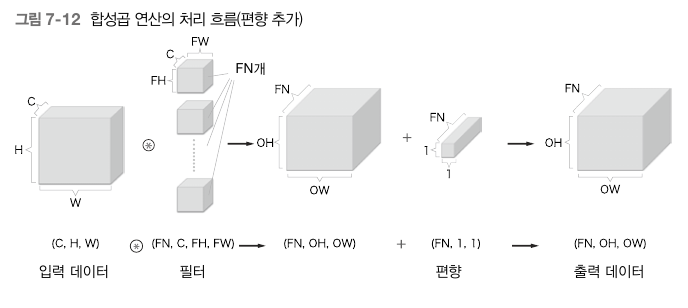
1.5 배치처리
지금까지의 과정은 입력데이터 한개에 대한 합성곱 연산의 과정을 나타낸 것이며, 합성곱 신경망은 앞선 완전연결 신경망과 같이 여러 데이터에대한 배치처리가 가능하다.
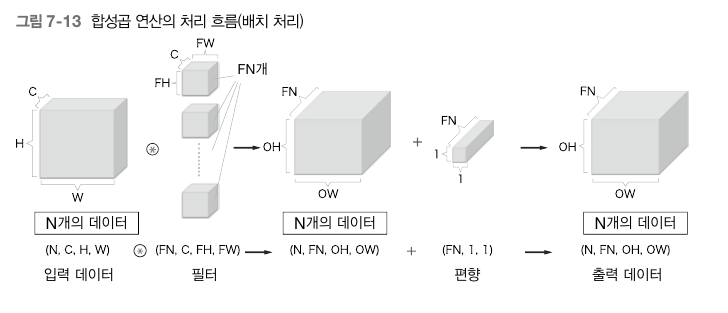
배치처리를 할경우 편향을 제외한 모든 데이터의 형상은 4차원이되는 것을 알 수 있다.
2. 풀링 계층
풀링 : 세로, 가로방향의 공간을 줄이는 연산
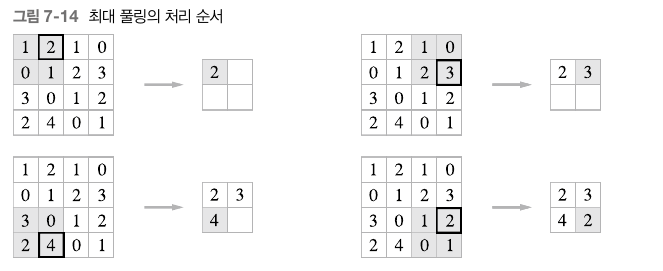
풀링의 윈도우와 스트라이드는 같은값으로 처리한다. (window = 2*2이면, 스트라이드 = 2)
위의 풀링은 최대 풀링의 예이고, 최대 풀링 이외에도 평균 풀링 등이 있다.
2.1 풀링계층의 특징
- 학습해야 할 매개변수가 없음.
- 채널 수가 변하지 않음
- 입력의 변화에 영향을 적게받음
