![]()
웹 크롤링이란
인터넷에 데이터가 방대해지면서 그것들을 원하는 데이터만 활용할 필요성이 높아졌고 그러한 정보들을 우리가 활용할 수 있게 데이터를 수집하는 것을 크롤링이라고 합니다.
원하는 데이터를 추출하는 스크래핑(Scarping)과 개념이 혼동되기도 합니다.
크롤링의 정확한 정의는 다양한 웹사이트의 페이지를 브라우징하는 작업을 말합니다.
하지만 정보를 수집하려면 페이지 안에 있는 데이터를 추루해서 가공하는게 대부분의 최종 목표입니다.
크롤링 이후 스크래핑의 과정으로 넘어가는 것이죠. 그래서 두 개념이 혼동되는 것 같고 해외에서는 주로 스크래핑으로 쓰는 것으로 알고 있습니다.
스타벅스 음료 페이지
파이썬(Python)을 이용해서 스타벅스의 음료 이름, 음료 이미지 링크를 크롤링하는 작업을 해보겠습니다.
- 미니콘다가 설치되어 있다고 가정하고 beautifulsoup4 및 selenium을 미리 설치합니다.
conda install beautifulsoup4
conda install selenium- 그리고 셀레니움을 사용할 때는 크롬 웹드라이버를 사용했습니다. 크롬 웹드라이버를 다운로드할 때에는 설치된 크롬 버전과 일치하는 지를 주의해주세요.
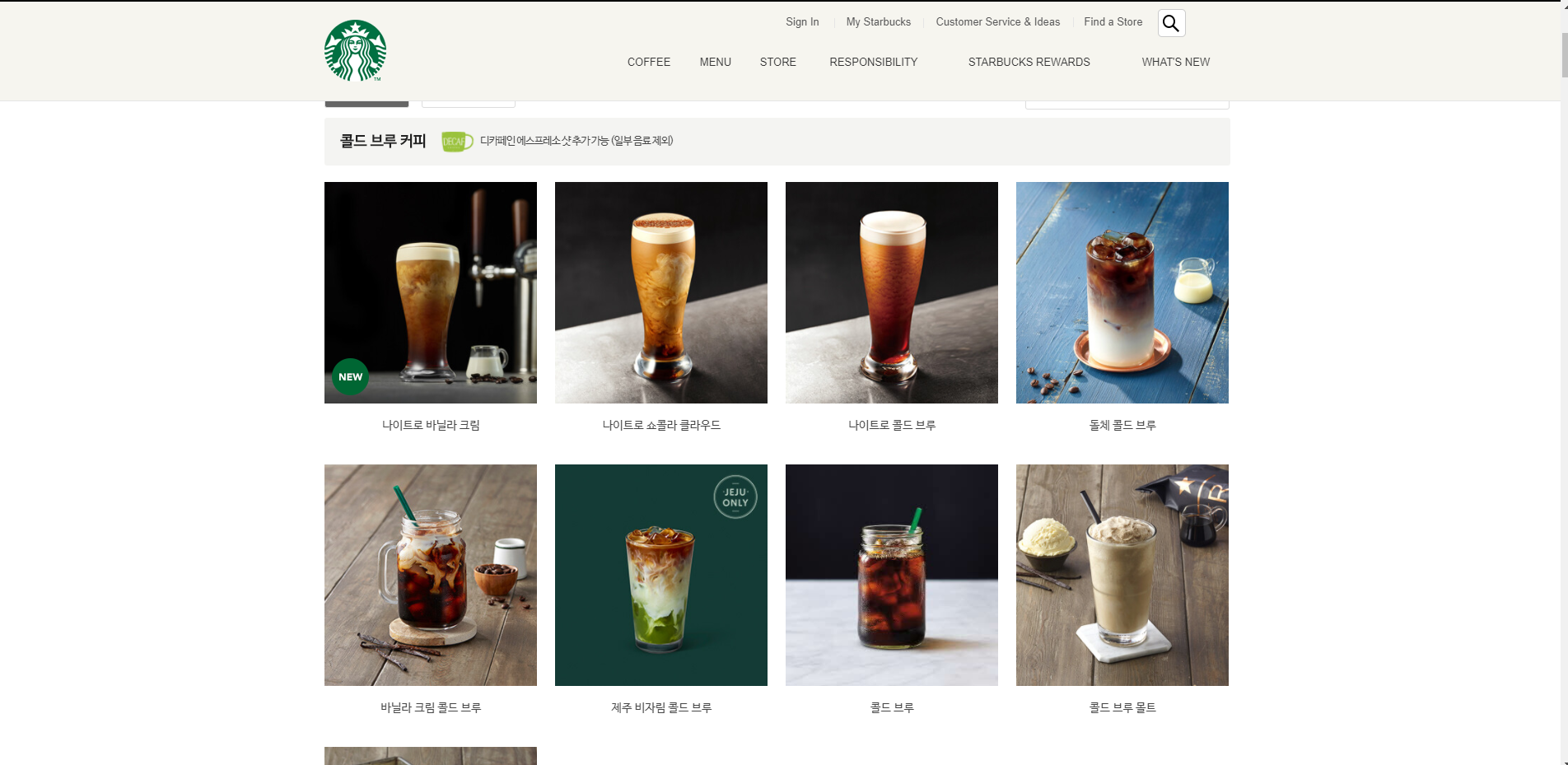
스타벅스 음료페이지에는 매장에서 판매 중인 모든 종류의 음료들과 그 음료들에 해당하는 이미지들이 있습니다.
여기에서 저는 음료 이름, 이미지 주소를 크롤링 해서 csv파일로 저장 할 예정입니다.
import csv
import time
from bs4 import BeautifulSoup
from selenium import webdrivercsv파일로 만들어야하기 때문에 csv 모듈을 그리고 time 함수를 이용하기 위해 time 모듈을 추가합니다.
이번에는 selenium과 beautifulsoup을 둘 다 이용해서 수행 할 예정입니다.
filename = "Starbucks_scraping.csv"
csv_file = open(filename, "w+", encoding="utf-8-sig")
writer = csv.writer(csv_file)
url = "https://www.starbucks.co.kr/index.do"
res = webdriver.Chrome("chromedriver가 있는 경로")
res.get(url)
time.sleep(3) # 3초간 대기csv파일을 열고 쓰기모드로 열어서 wrtier 변수에 넣었습니다.
그리고 셀레니움의 크롬 웹 드라이버를 이용해서 스타벅스 음료 페이지에 접속합니다.
브라우저에서 이미지를 모두 불러올 수 있게 3초정도 시간을 줍니다.
html = res.page_resource
soup = BeautifulSoup(html, 'html.parser')결과가 반영된 페이지 소스를 html 가져오고 beautifulsoup을 이용해서 html 파싱을 합니다.
items = soup.findAll('li', {"class":"menuDataSet"})
for item in items:
temp = item.find('img')
item_img_url = temp['src']
item_name = temp['alt']
product = (item_name, item_img_url)
writer.writerow(product)
csv_file.close()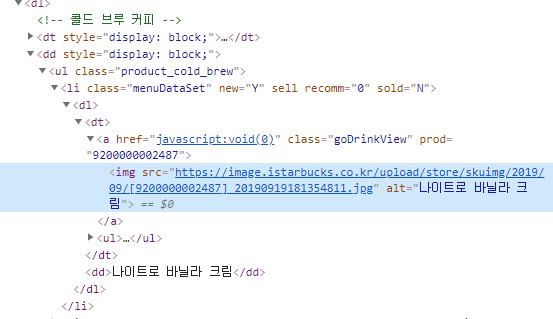
class 이름이 menuDataSet인 li 태그를 전부 찾아서 추출하면 음료의 이름과 이미지를
전부 가져올 수 있습니다.
findAll 메소드를 이용해서 음료 정보들을 가져오고 그중에서 img 태그에 있는 src, alt 속성을 가져옵니다. alt에는 음료의 이름 src에서 이미지 url을 가져옵니다.
그리고 튜플 형태로 묶어서 파일에 csv파일에 저장합니다.
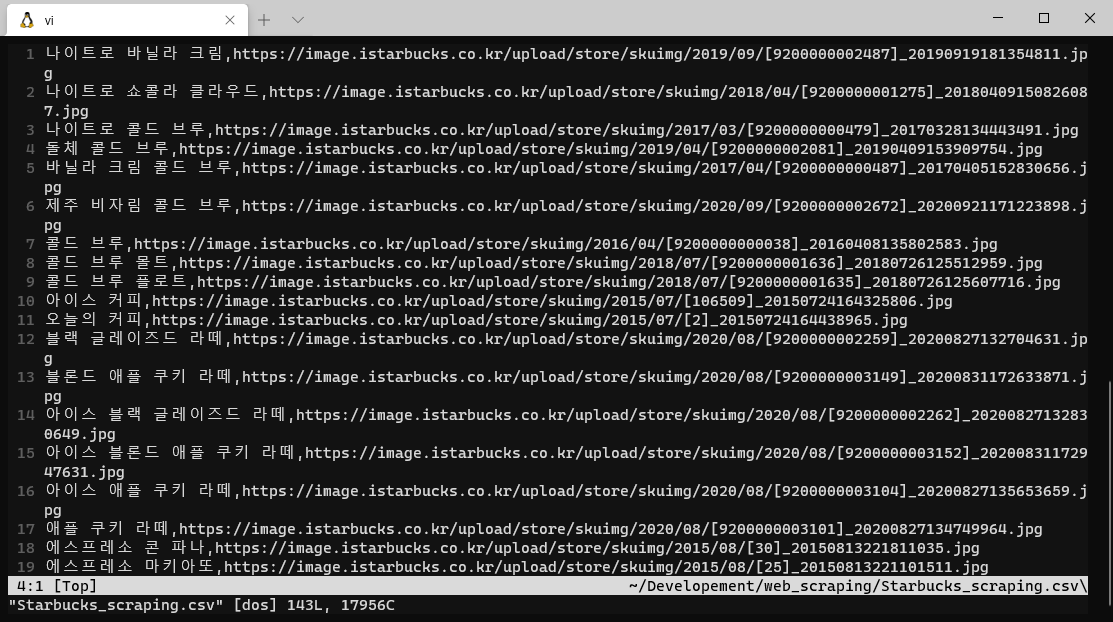
파일을 실행시켜 크롤링을 한 후 Starbucks_scraping.csv 파일을 열어 결과를 확인합니다.
음료 이름과 이미지 url이 정상적으로 입력되었습니다.
