0. Abstract
Pseudo Labels와 마찬가지로 Meta Pseudo Labels는 unlabeled 데이터에 pseudo label을 생성하여 student 네트워크를 가르치는 teacher 네트워크가 있다. 그러나 teacher가 고정되어있는 Pseudo labels와는 달리 Meta Pseudo Labels의 teacher는 labeled 데이터에 대한 student의 결과의 feedback에 따라 학습된다.
1. Introduction
Pseudo Labels는 teacher, student 네트워크의 한 쌍으로 구성되어 있다. teacher는 unlabeled 데이터에 pseudo label을 생성한다. 그 후 pseudo label이 할당된 데이터와 labeled 데이터를 합쳐 student를 학습한다. 이 때 pseudo label 데이터에 regularization을 위해 data augmentation과 같은 방법이 사용된다. 그러나 pseudo label은 정확하지 않기 때문에 student는 정확하지 않은 데이터로부터 학습이 되는 것과 같다. 그 결과 student는 teacher보다 매우 높은 성능을 가지기 힘들다.
본 논문에서는 pseudo label이 student에 어떤 영향을 끼치는지 알아본다. 특별히 student로부터 feedback을 받아 더 좋은 pseudo label을 teacher가 생성하는 방법인 Meta Pseudo Labels라는 방법을 제안하였다.
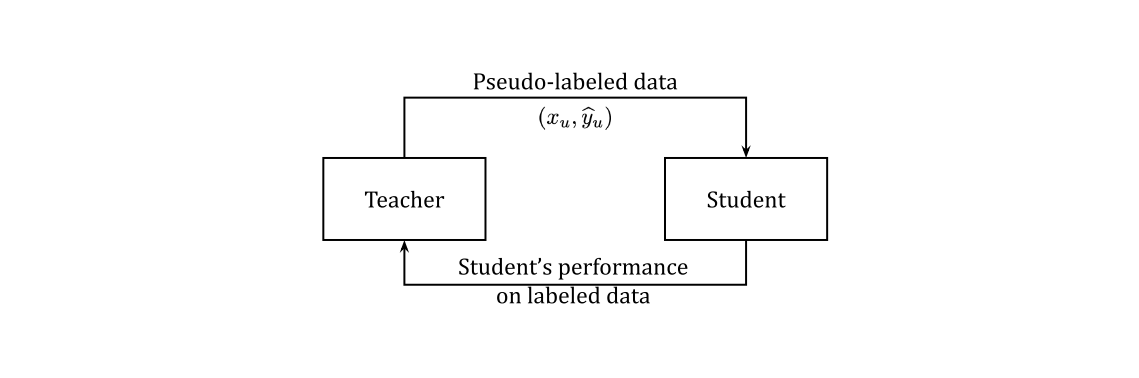
2. Meta Pseudo Labels
.png)
Meta Pseudo Labels의 가장 큰 차이점은 labeled 데이터로부터 student의 feedback을 teacher가 받는다는 것이다.
1) Notations
와 는 teacher와 student를 나타낸다. 그리고 labeled 데이터를 , unlabeled 데이터를 로 하며 의 soft prediction을 라고 한다. 동일하게 student의 prediction은 , 이다. Cross entropy loss는 로 나타낸다.
2) Pseudo Labels as an optimization problem
Meta Pseudo Labels를 설명하기 앞서 Pseudo Labels를 알아보자. Pseudo Labels는 unlabeled data로 부터 cross entropy loss를 최소화하며 학습한다.
Student의 최적의 parameter 은 항상 pseudo label인 때문에 teacher의 parameter 에 의존한다. Meta Pseudo Labels를 효과적으로 설명하기 위해 의 의존성을 설명해야 한다.
는 의 함수이며 을 의 관점에서 최적화 하는 것은 다음과 같이 나타낼 수 있다.
직관적으로 보면 labeled 데이터로부터 얻은 student의 결과에 따라 teacher를 최적화 함으로 Pseudo Labels가 student의 성능 또한 높일 수 있다. 본 논문에서는 meta level에서 teacher를 효과적으로 최적화 하기 때문에 Meta Pseudo Labels라 명명하였다.
그러나 의 에 대한 의존성은 매우 복잡하기 때문에 는 student의 전체 학습 과정을 고려해야 한다.
3) Practical approximation
Meta Pseudo Labels를 효과적으로 학습하기 위해서, 본 논문에서는 meta learning과 multi-step 를 근사화 하였다.
근사화한 식을 대입하면 다음과 같다.
위 과정에서 hard pseudo label을 사용하였다. 그 결과 약간 수정된 REINFORCE로 의 gradient를 얻었다.
Student는 또한
식에 의해 학습되기 때문에 는 일정하게 최적화 된다.
게다가 student의 parameter는 를 업데이트하는 과정에서 재 사용됨으로 자연스럽게 student와 teacher가 업데이트 된다. 과정은 다음과 같다.
4) Teacher's auxiliary losses
Meta Pseudo Labels가 이론적으로 합리적임을 확인하였다. 게다가 teacher가 auxilary objective와 함께 jointly하게 학습된다면 더 좋은 결과를 얻을 수 있다. 본 논문에서는 teacher를 학습 시 supervised learning과 semi supervised learning을 함께 수행하였다. Supervised learning에서는 labeled 데이터를 사용하였고 semi supervised learning에서는 unlabeled 데이터로 UDA objective를 적용하였다.
3. Small Scale Experiments
.png)
TwoMoon dataset에 대한 결과이다. Supervised learning과 Pseudo Labels 방법에 비해 좋은 결과를 얻을 수 있었다.
.png)
CIFAR-10-4K, SVHN-1K, ImageNet-10%에 대한 Image classification 결과이다. WideResNet-28-2을 CIFAR-10-4K, SVHN-1K에 사용하고 ResNet-50을 ImageNet-10%에 사용하여 같은 조건에서 학습 후 결과를 얻었다. 다른 방법들과 비교했을 때 좋은 결과를 보여준다.
.png)
ImageNet에서 Top-1, Top-5 accuracy를 계산한 결과이다. 300M unlabeled JFT를 사용하였음에도 labeled extra data를 사용한 방법보다 더 좋은 결과를 얻었다.
4. Conclusion
본 논문에서는 semi supervised learning 방법으로 Meta Pseudo Labels를 제안하였다. 핵심 아이디어는 unlabeled 데이터로부터 얻은 student의 feedback으로 부터 teacher가 학습을 하고 그 결과 더 정확한 pseudo label을 생성함으로 student의 학습을 돕는 것이다.
Meta Pseudo Labels의 학습 과정은 두 가지로 나뉜다. 먼저 teacher로 부터 얻은 pseudo label 데이터를 이용해 student를 업데이트 하고 그 과정 에서 student의 결과를 이용해 teacher를 업데이트 하는 것 이다.
CIFAR-10-4K, SVHN-1K, ImageNet에서 모두 기존의 semi supervised learning 방법들 보다 좋은 결과를 얻었다. 게다가 ImageNet에서는 accuracy 90.2%로 state-of-the-art를 달성했다.
