-
막대의 바향에 따른 분류
-
수직(vertical,
.bar()) : x축에 범주, y축에 값을 표기 -
수평(horizontal,
.barh()): y축에 범주, x축에 값을 표기(범주가 많을 때)
-
다양한 Bar Plot
Multiple Bar Plot
-
Bar Plot에서는 범주에 대해 각 값을 표현, 즉 1개의 feature에 대해서만 보여준다.
-
여러 Group을 보여주기 위해서는 다양한 방법이 필요
-
플롯을 여러 개 그리는 방법
-
한 개의 플롯에 동시에 나타내는 방법
- 쌓아서 표현하는 방법
- 겹쳐서 표현하는 방법(투명도 조정)
- 이웃에 배치하여 표현하는 방법
-
Stacked Bar Plot
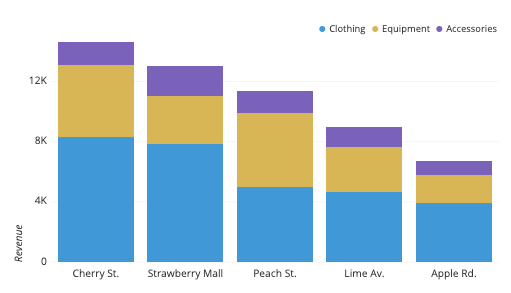
-
2개 이상의 그룹을 쌓아서 표현하는 bar plot
- 각 bar에서 나타나는 그룹의 순서는 항상 유지해야 한다.
-
맨 밑의 bar분포는 파악하기 쉽지만 그 외의 분포는 파악하기 어려움
- 2개의 그룹이 positive/negative라면 축 조정이 가능함
-
.bar()에서는 bottom 파라미터를 사용 -
.barh()에서는 left 파라미터를 사용 -
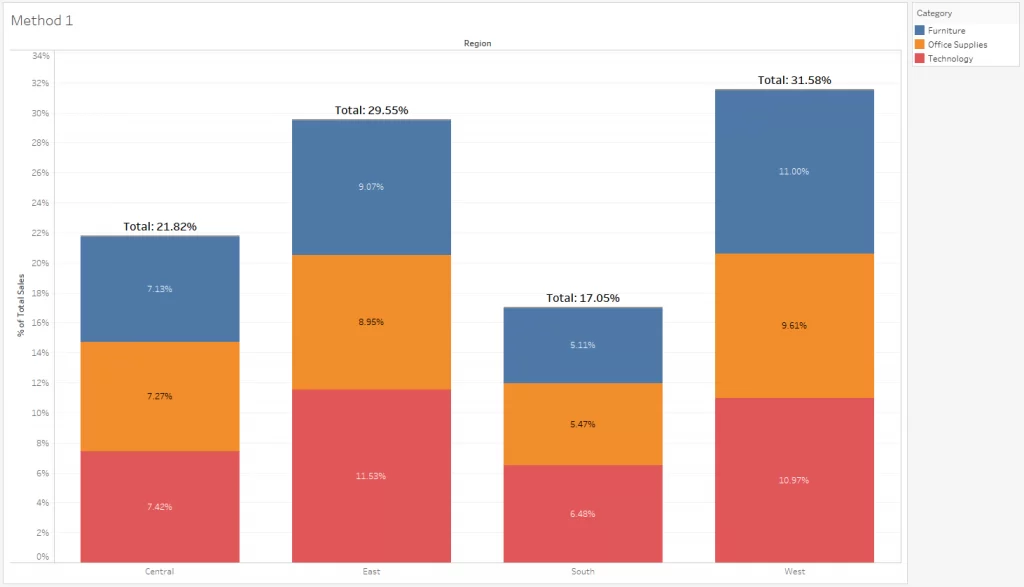
응용하여 전체에서 비율을 나타내는 Percentage Stacked Bar Chart가 있다.
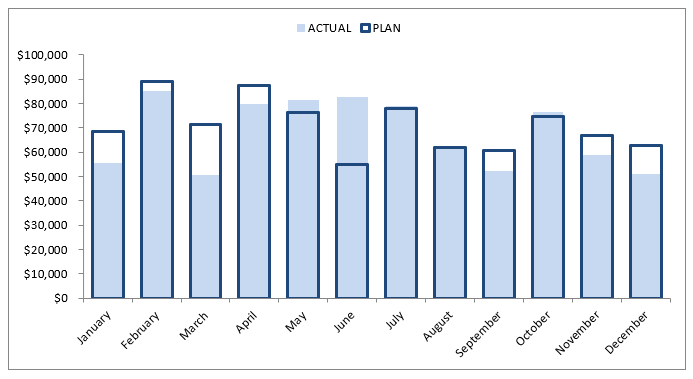
Overlapped Bar Plot
-
2개 그룹만 비교한다면 겹쳐서 만드는 것도 하나의 선택지이다.
- 3개 이상에서는 파악하기 어렵기 때문
-
같은 축을 사용하니 비교가 쉽다.
- 투명도를 조정하여 겹치는 부분을 파악(alpha)
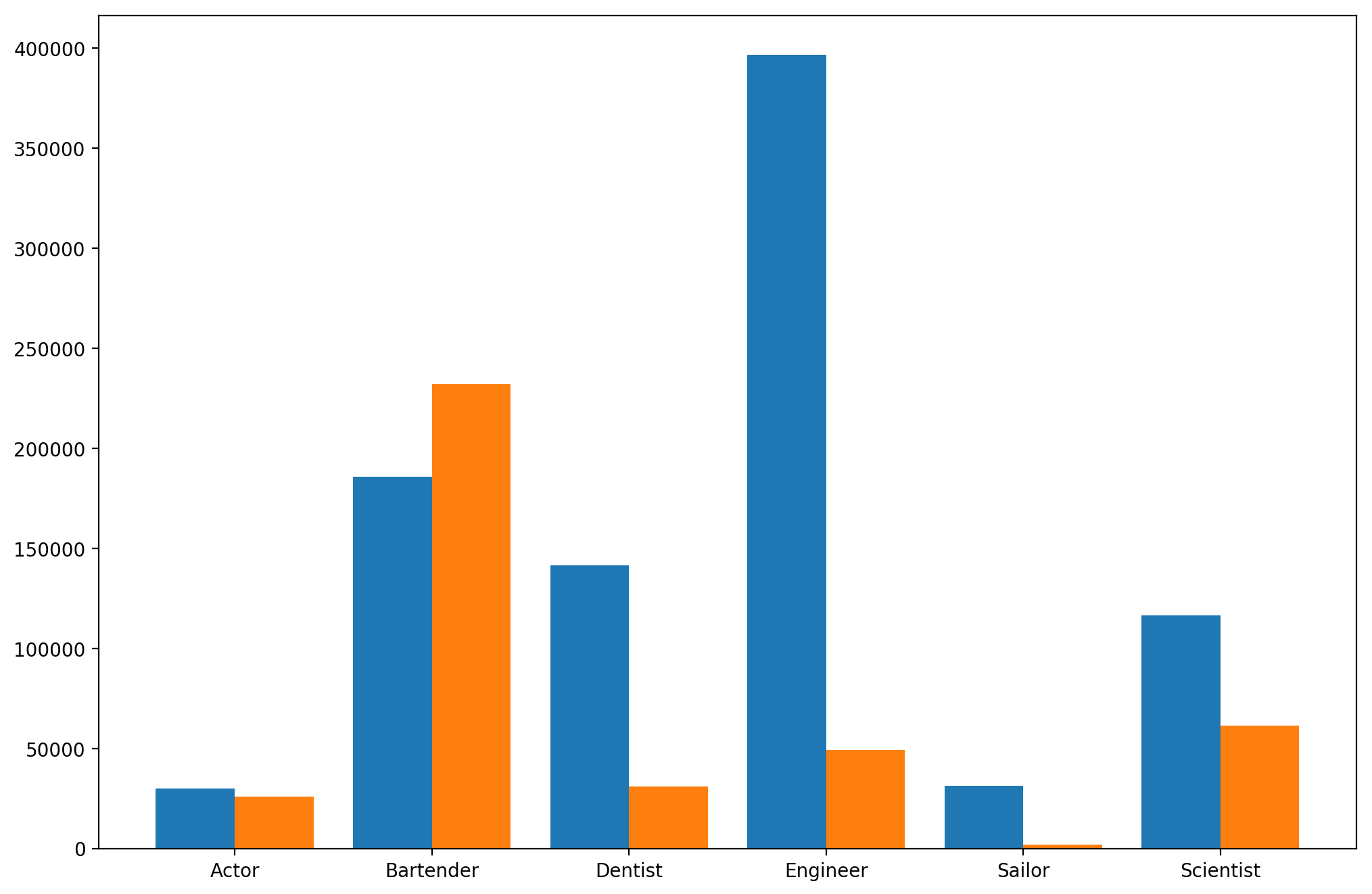
Grouped Bar Plot
-
그룹별 범주에 따른 bar를 이웃되게 배치하는 방법
-
Matplotlib으로 비교적 구현이 까다롭다.
- 적당한 테크닉(
.set_xticks(),set_sticklabels())
- 적당한 테크닉(
-
앞서 소개한 내용 모두 그룹이 5개~7개 이하일 때 효과적이다.
정확한 Bar Plot
Principle of Proportion ink
-
실제 값과 그래픽으로 표현되는 잉크 양은 비례해야 한다.
-
반드시 x축의 시작은 zero(0)여야 양의 비교가 가능하다.
-
막대 그래프에만 한정되는 원칙은 아니다.
데이터 정렬하기
-
더 정확한 정보 전달을 위해 정렬은 필수이다.
- Pandas의
sort_values(),sort_index()를 사용
- Pandas의
-
데이터의 종류에 따라 아래의 기준을 사용
- 시계열 | 시간순
- 수치형 | 크기순
- 순서형 | 범주의 순서
- 명목형 | 범주의 값에 따라 정렬
-
여러 가지 기준으로 정렬을 하여 패턴을 발견
-
대시보드에서는 Interactive로 제공하는 것이 유용하다.
적절한 공간 활용
-
여백과 공간만 조정해도 가독성이 증가한다.
-
Matplotlib의 bar plot은 ax에 꽉 차서 답답할 수 있다.
-
Matplotlib technques
- X/Y axis Limit (
.set_xlim(),.set_ylim()) - Spines (
.spines[spine].set_visible()) - Gap (
width) - Legend (
.legend()) - Margins (
.margins())
- X/Y axis Limit (
ETC
-
오차 막대를 추가하여 Uncertainty 정보를 추가 가능 (errorbar)
-
Bar 사이 Gap을 0으로 만든다면 -> 히스토그램
-
.hist()를 사용하여 가능 -
연속되 느낌을 줄 수 있음
-
-
다양한 Text 정보 활용하기
-
제목 (
.set_title()) -
라벨 (
.set_xlabel(),set_ylabel())
-
실습
.bar() vs. .barh()
fig, axes = plt.subplots(1, 2, figsize=(7, 4))
x = list('ABCDE')
y = np.array([1, 2, 3, 4, 5])
axes[0].bar(x, y)
axes[1].barh(x, y)
plt.show()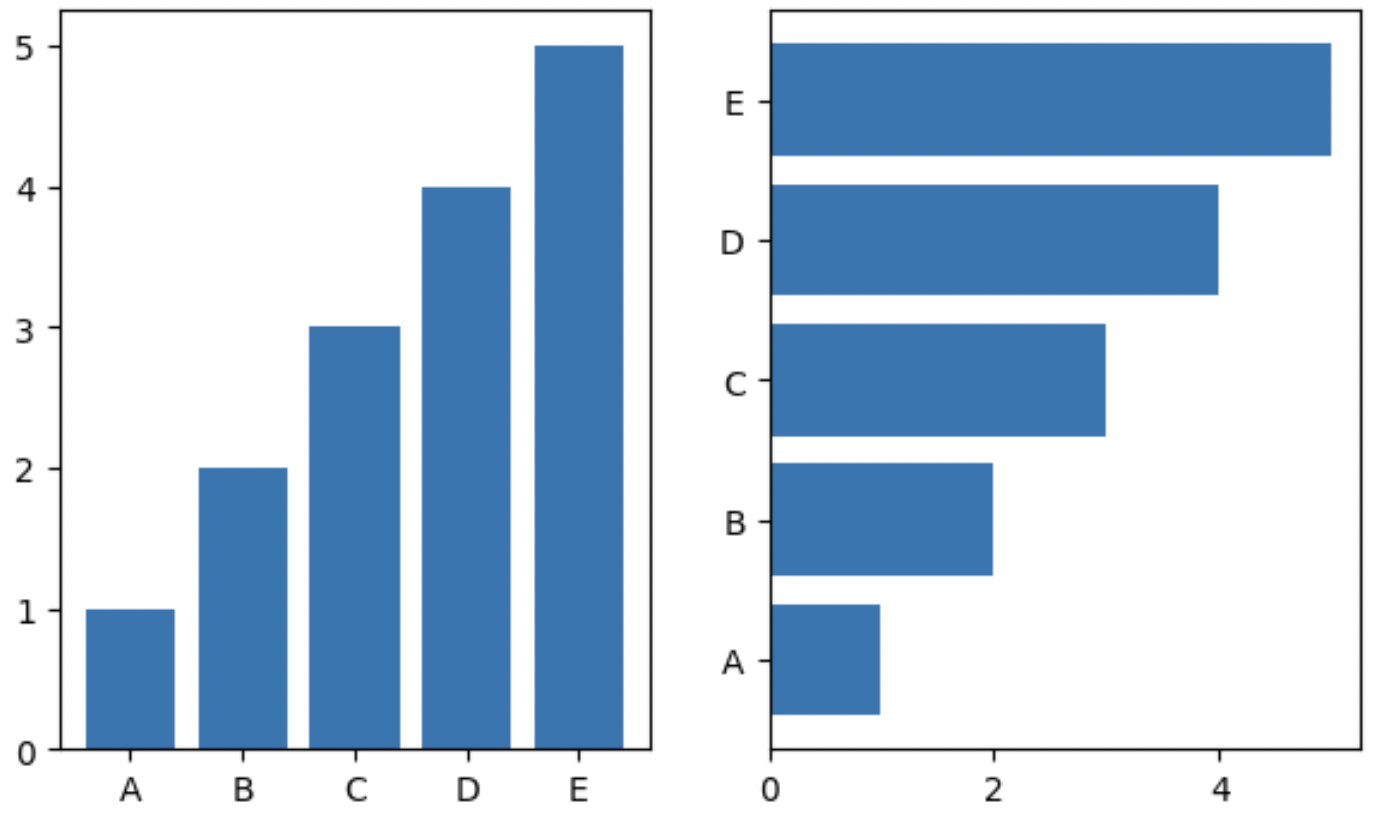
다양한 Bar Plot
Data : 1000명의 학생 데이터(Studuent Score Dataset)
feature
- 성별 : female / mael
- 인종민족 : group A, B, C, D, E
- 부모님 최종 학력 : 고등학교 졸업, 전문대, 학사, 석사, 2년제
- 점심 : standard와 free/reduced
- 시험 예습 : none과 completed
- 수학, 읽기, 쓰기 성적 : 0-100
데이터 살펴보기
DataFrame.sample(int) : int만큼의 sample을 뽑아 살펴보기
DataFrame.info() : null값이 있는지, 데이터 타입은 무엇인지 살펴볼 수 있다.
DataFrame.describe(include='all'): 미리 통계정보를 살펴볼 수 있다.
DataFrame.groupby(column): 그룹화를 통해 디테일하게 살펴보기
Bar Plot 그려보기
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], color='tomato')
plt.show()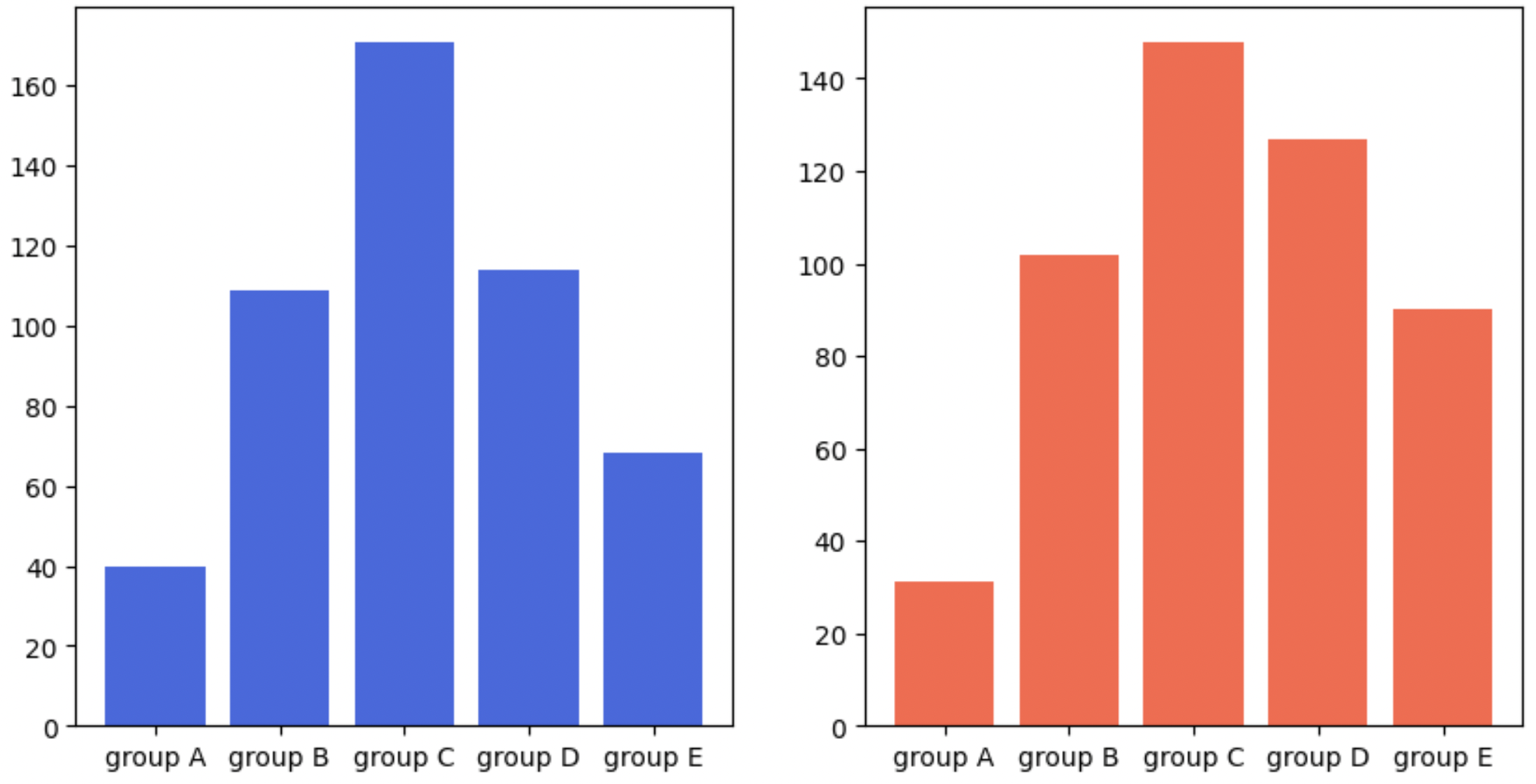
-
남성은 scale이 0~160, 여성은 0~140으로 이 scale정보를 맞춰줘야 한다.
-
.subplots의 파라미터인sharey=True로 하면 y값이 공유된다.
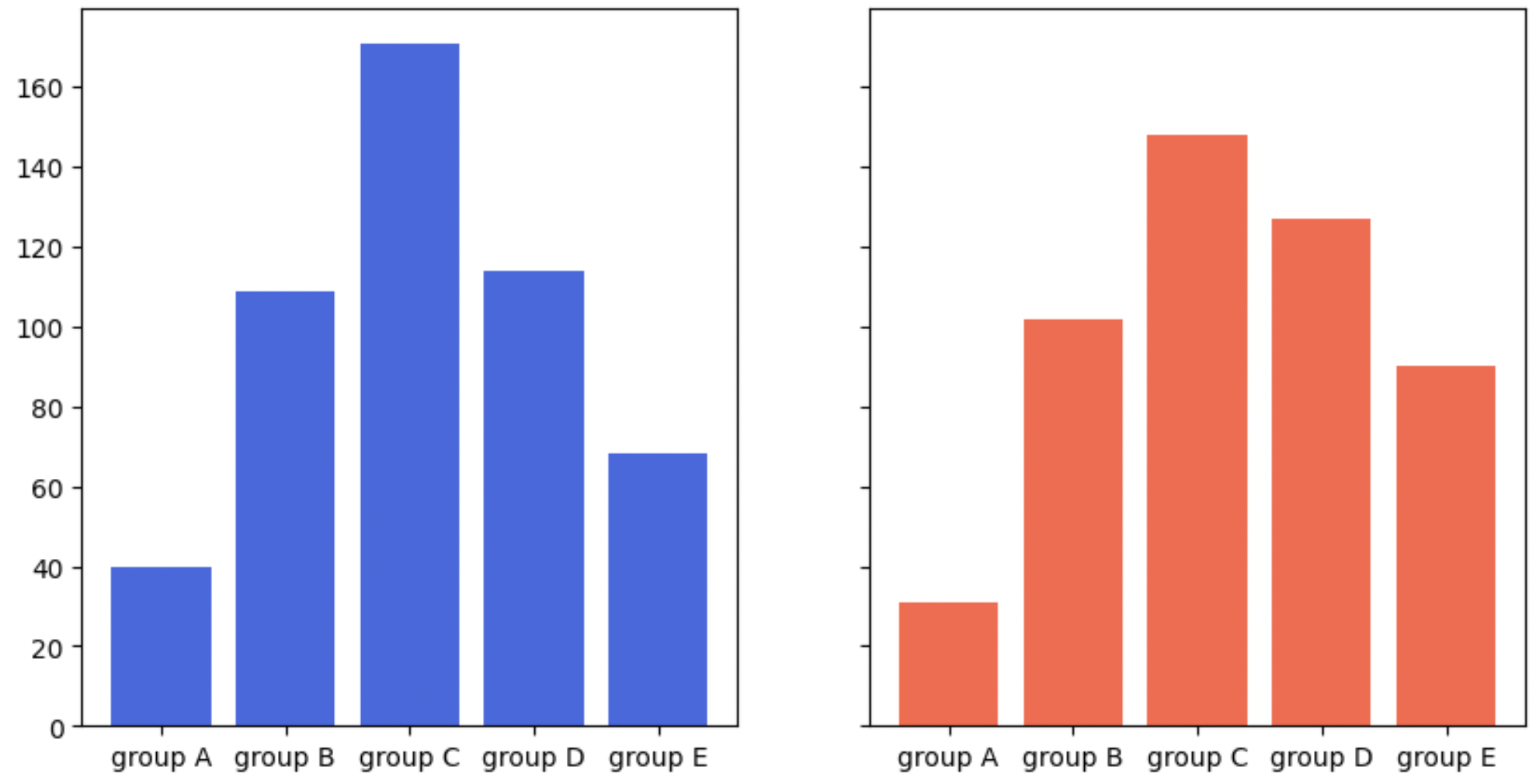
- 또는 y범위는 미리 정해줄 수 있다.
for ax in axes:
ax.set_ylim(0, 200)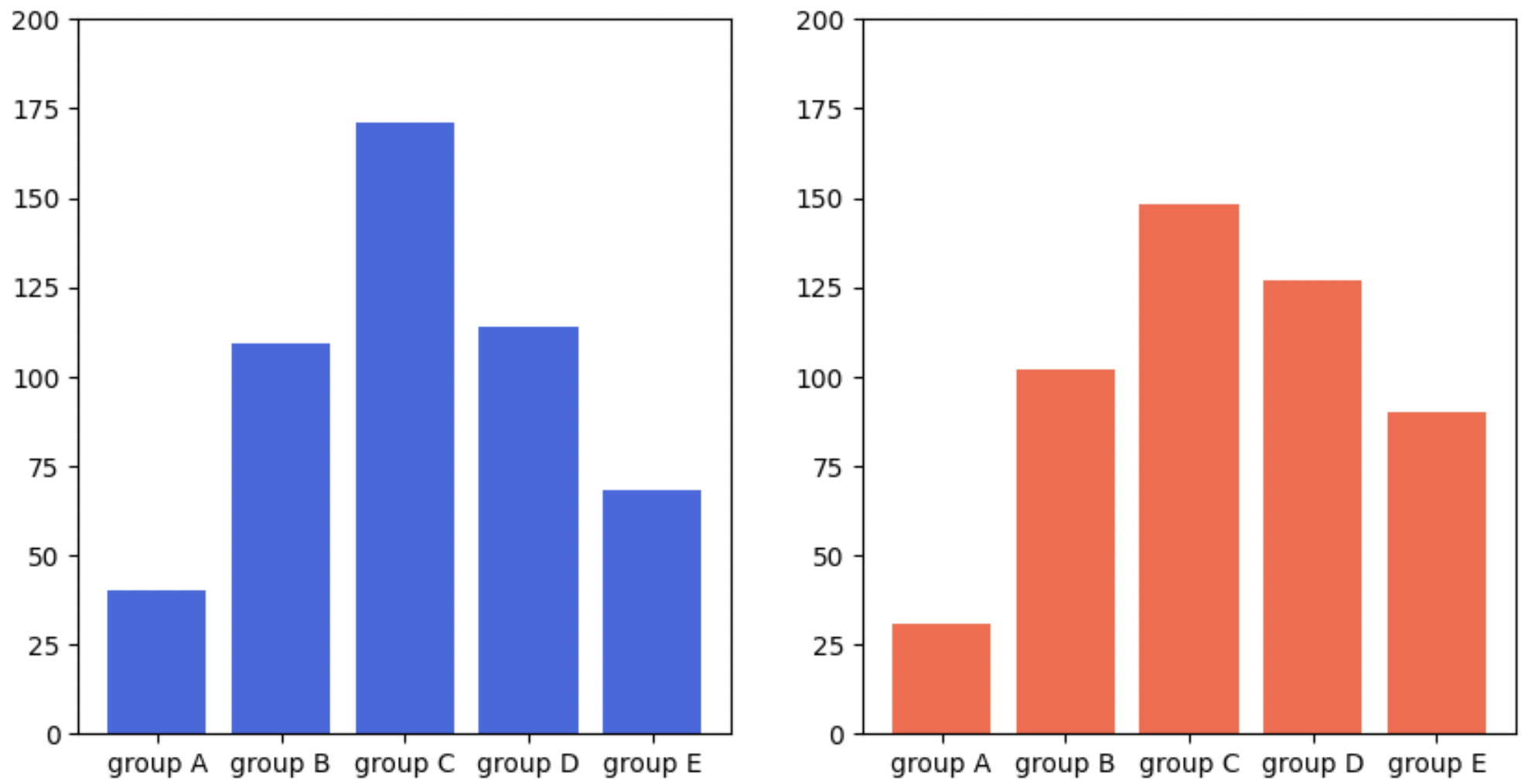
Stacked Bar Plot
- bottom 파라미터를 이용해 아래 공간을 비워둘 수 있다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
group_cnt = student['race/ethnicity'].value_counts().sort_index()
axes[0].bar(group_cnt.index, group_cnt, color='darkgray')
axes[1].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], bottom=group['male'], color='tomato')
for ax in axes:
ax.set_ylim(0, 350)
plt.show()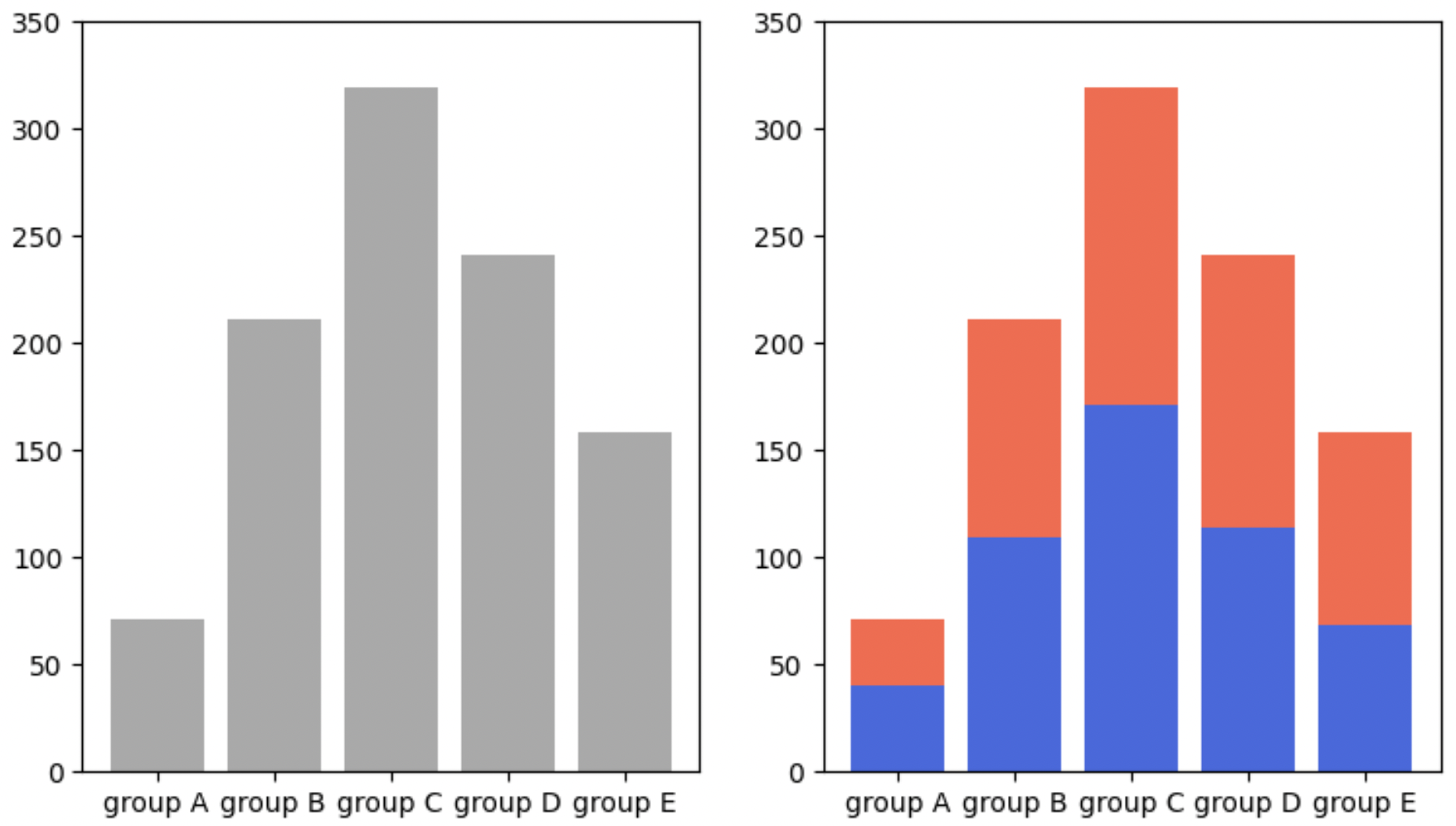
- 위쪽 데이터(여성)의 분포를 보기에 가독성이 좋지 않다.
Percentage Stacked Bar Plot
fig, ax = plt.subplots(1, 1, figsize=(7, 5))
group = group.sort_index(ascending=False) # 역순 정렬
total=group['male']+group['female'] # 각 그룹별 합
ax.barh(group['male'].index, group['male']/total,
color='royalblue')
ax.barh(group['female'].index, group['female']/total,
left=group['male']/total,
color='tomato')
ax.set_xlim(0, 1)
# 테두리 없애기
for s in ['top', 'bottom', 'left', 'right']:
ax.spines[s].set_visible(False)
plt.show()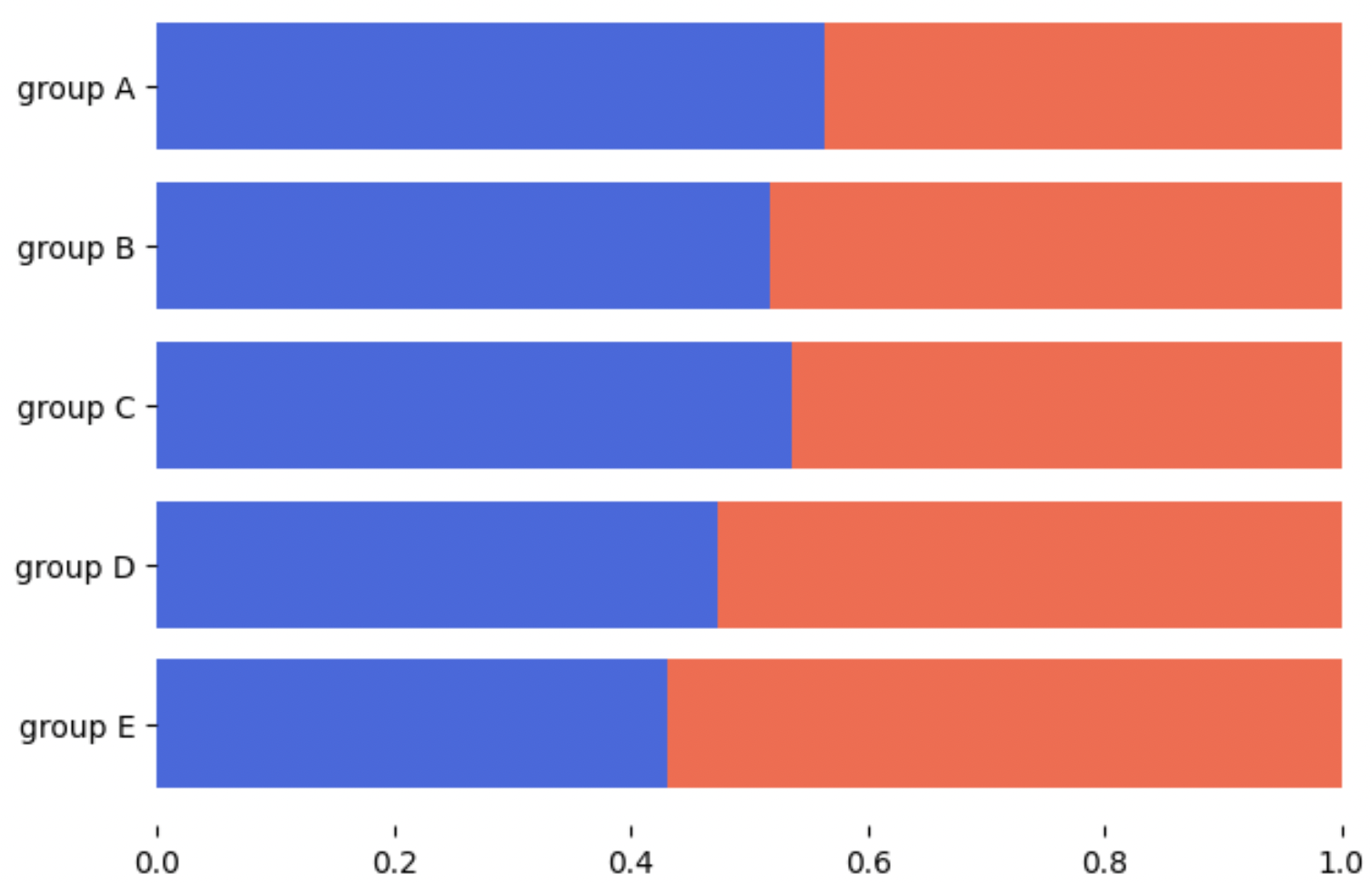
- 각 차트의 중앙에
text로 퍼센트를 적용할 수 있다.
Overlapped Bar Plot
group = group.sort_index() # 다시 정렬
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes = axes.flatten()
for idx, alpha in enumerate([1, 0.7, 0.5, 0.3]):
axes[idx].bar(group['male'].index, group['male'],
color='royalblue',
alpha=alpha)
axes[idx].bar(group['female'].index, group['female'],
color='tomato',
alpha=alpha)
axes[idx].set_title(f'Alpha = {alpha}')
for ax in axes:
ax.set_ylim(0, 200)
plt.show()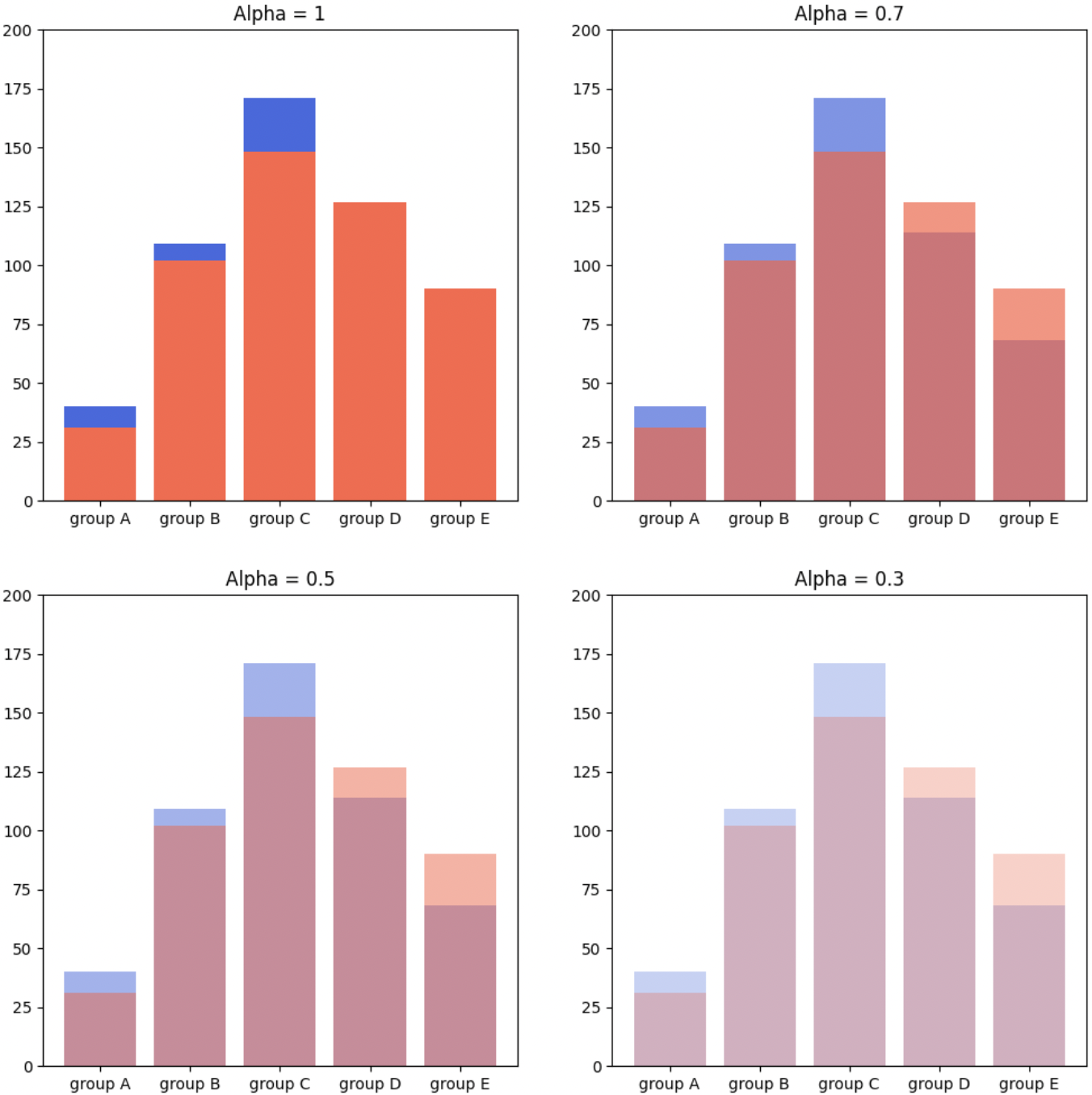
Grouped Bar Plot
-
크게 3가지 테크닉이 필요하다.
-
x축 조정
-
width조정 -
xticks,xticklabels
-
-
원래 x축이 0, 1, ,2, 3 이라면 이 값들이 차트의 중심이 된다.
-
한 그래프는 0-width/2, 1-width/2 ...
-
다른 그래프는 0+width/2, 1+width/2 ...
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
idx = np.arange(len(group['male'].index))
width=0.35
ax.bar(idx-width/2, group['male'],
color='royalblue',
width=width)
ax.bar(idx+width/2, group['female'],
color='tomato',
width=width)
ax.set_xticks(idx)
ax.set_xticklabels(group['male'].index)
plt.show()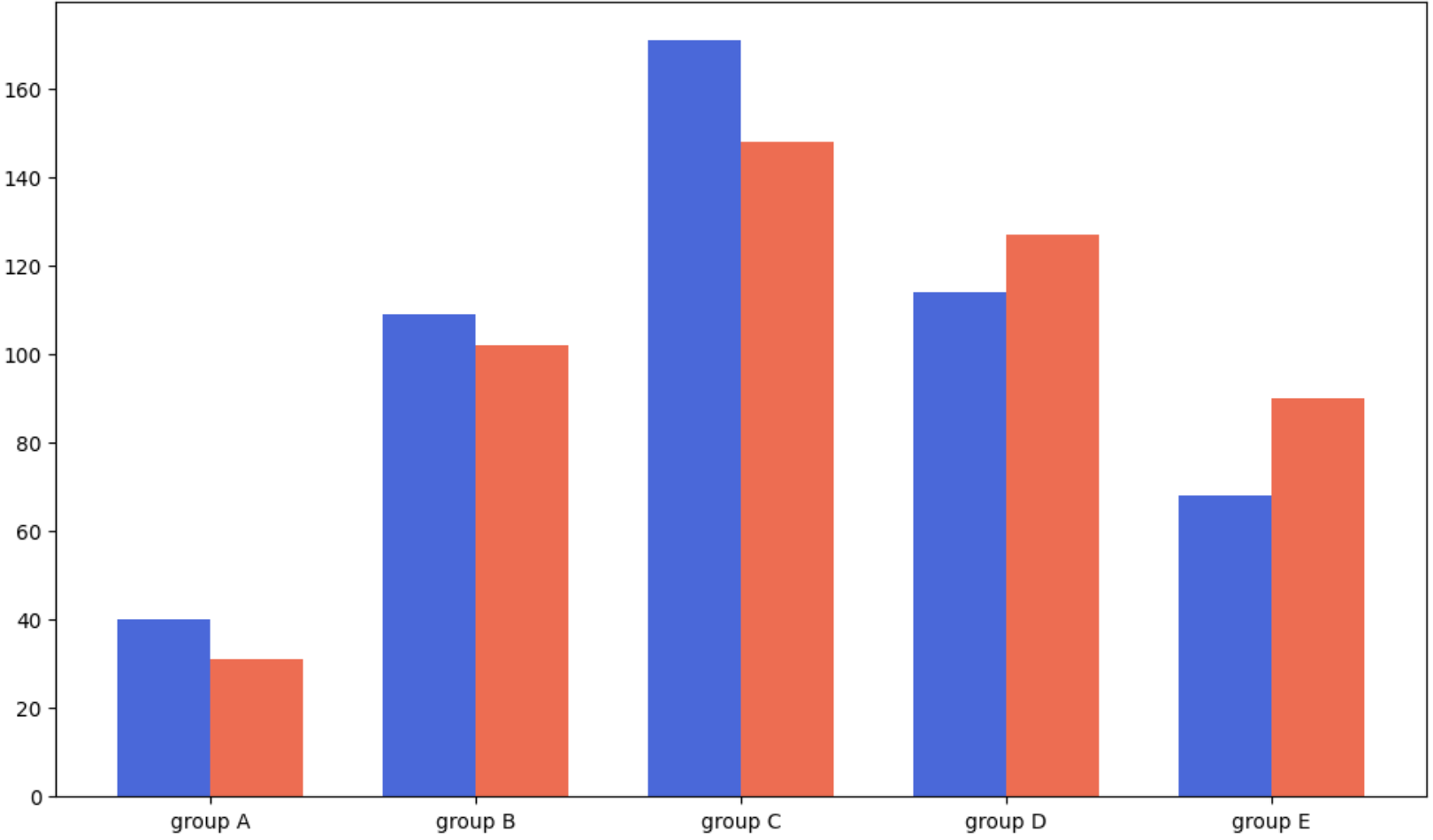
- 그룹이 n개일 경우(zero index) 로 계산할 수 있다.
fig, ax = plt.subplots(1, 1, figsize=(13, 7))
x = np.arange(len(group_list))
width=0.12
for idx, g in enumerate(edu_lv):
ax.bar(x+(-len(edu_lv)+1+2*idx)*width/2, group[g],
width=width, label=g)
ax.set_xticks(x)
ax.set_xticklabels(group_list)
ax.legend()
plt.show()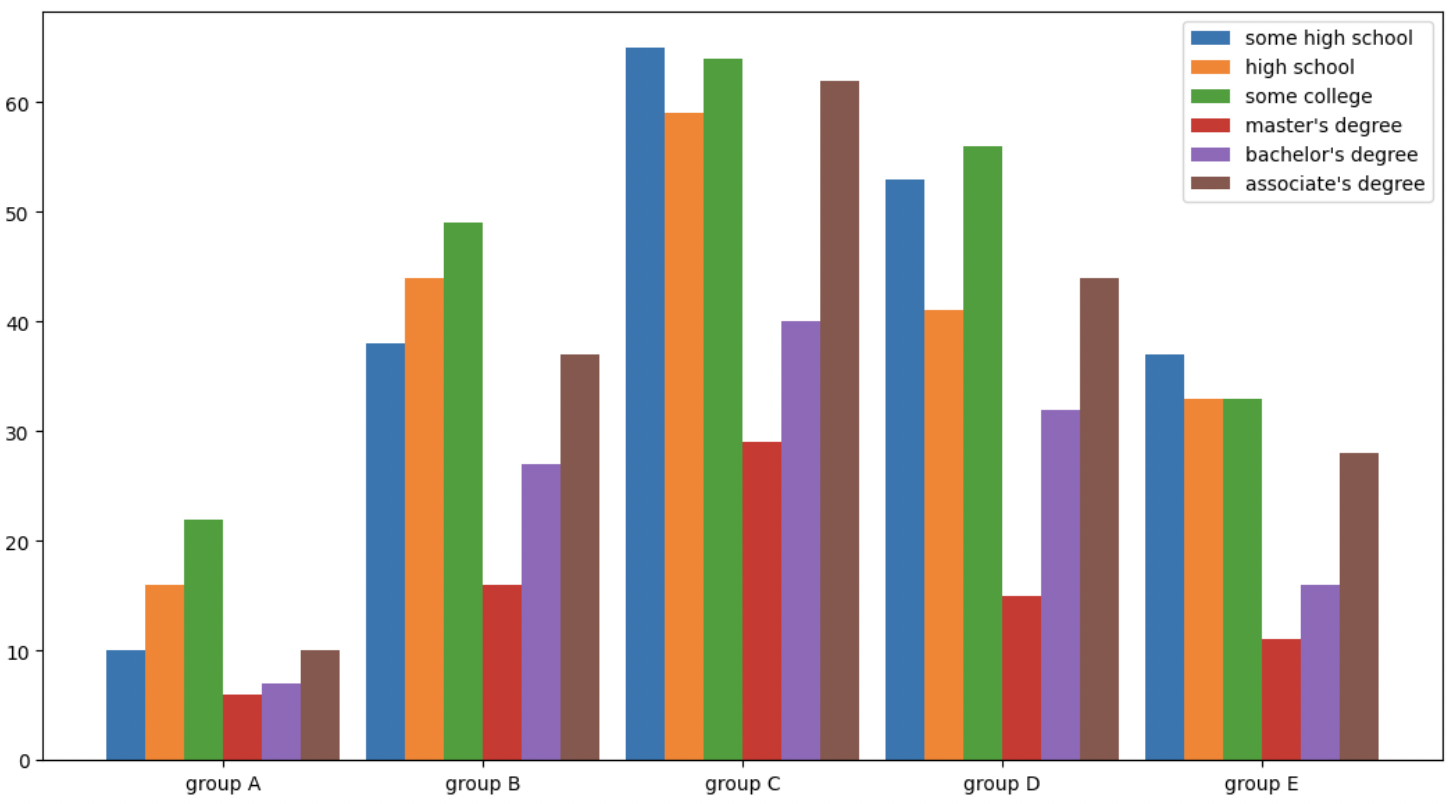
그 외
ax.margins(0.1, 0.1) : default는 0.05이며 x축과 y축의 마진을 더 사용해 가독성 증가를 기대할 수 있다.
ax.bar(width=0.7, linewidth=2): 바의 두께와 테두리 선의 두께를 조정할 수 있다.
ax.spines['top'].set_visible(False) : top, bottom, left, right를 지정하여 spine을 끌 수 있다.
ax.grid(): 격자를 표시할 수 있다.
ax.bar(yerr=var, capsize=10): 에러 표시가 가능하다.
ax.bar(label='label'), ax.legend(): 범례 표시
ax.set_xlabel('text', fontweight='bold) : 축제목 지정
